深度干货|轻量级统计预测算法模型原理解析
前言
本期我们有幸邀请了云智慧算法实习生、北京科技大学硕士在读生朱同学,为我们简要介绍几类轻量级的统计预测算法模型,其中包括 ARMA 模型及其衍生模型、ARCH 模型及其衍生模型、HoltWinters 模型、facebook 提出的 prophet 模型以及树模型。 下面让我们一起来学习吧~
一、ARMA 模型及其衍生模型
-
ARMA 模型
ARMA(自回归滑动平均)模型是在 AR 模型和 MA 模型的基础上发展而来的,其基本思想是自回归,即当前点的值由前面几个临近点的值回归而来。其中 AR 模型是对数值进行回归,MA 模型是对随机扰动进行回归。纵观整个 ARMA 模型体系,所有的模型都是基于差分和自回归。 下面详细介绍之。
AR 模型可定义为
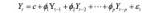
MA 模型可定义为
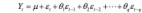
AR 模型是对临近点的一个回归,而 MA 模型认为整个序列的均值是不变的,但是会受到随机扰动的影响,并且随机扰动的影响是可以往后传递的,所以 MA 模型中就对随机扰动做了自回归。
Box and Jenkins 将 AR 模型和 MA 模型相结合提出了 ARMA 模型。表示如下
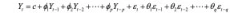
引入延迟算子
AR 模型可表示为:
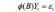
其中

同理 MA 模型可以表示为:
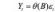
则 ARMA 模型可简化地表示为:
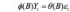
基于差分方程的理论,ARMA 模型的性质被研究得十分清楚,还可以从多个视角被理解,这也是该模型得到广泛应用的原因。基于 ARMA 模型的性质,ARMA 模型只能拟合平稳的数据,对于非平稳的数据需要处理为平稳数据后才能进拟合 ARMA 模型。
-
ARMA 衍生模型:ARIMA 模型
对于一些非平稳的序列可以先通过差分使其平稳再拟合 ARMA 模型,加入了差分后的 ARMA 模型即为 ARIMA 模型,ARIMA 模型可表示为:

其中 d 是差分的阶数,一般取正整数。
此外有些数据不仅有像趋势这种不平稳的成分,还会有周期性的变化。为了解决这个问题季节 ARIMA 模型被提出。此模型在 ARIMA 模型的基础上引入了周期差分和周期自回归。 周期差分的公式表达为:xt−xt−s。周期回归即用临近周期中相同位置的点来回归当前位置的点。因此通过调整周期差分的参数可以拟合不同的类型的周期形态。不同周期差分的效果如下图所示。

-
ARMA 衍生模型:X-13-ARIMA 模型
X-13-ARIMA 模型是美国人口统计局提出的基于 ARIMA 的复杂预测模型,在此之前美国人口统计局曾提出过 X-11-ARIMA, X-12-ARIMA 模型,X-13-ARIMA 是其增强版,也是 ARIMA 模型的集大成之作。目前该软件开源,可免费下载。
X-13-ARIMA 模型的内置模型为 regARIMA:
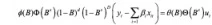
可以看出,对模型拟合季节 ARIMA 模型前,先对yt做了一个关于其他变量的多元回归,所以该模型是支持多对一预测的。 并且在 X-13-ARIMA 模型的程序中还集成了数据预处理,数据转换,异常过滤,周期提取等功能,是一个强大的预测工具。
-
ARMA 衍生模型:ARFIMA 模型
ARIMA 模型提出后,由于其方差是无限的,饱受经济学家诟病。后来,Granger and Joyeux 提出了 ARFIMA 模型。该模型将 ARIMA 模型中的整数阶差分替换为分数阶差分。分数阶差分定义为:
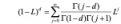
ARFIMA 模型可表示为:
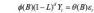
其中的差分算子定义为分数阶差分。并且当-0.5<d<0.5 时,ARFIMA 模型的方差是有限的。分数阶差分的引入不仅解决了方差无限的问题,而且为模型提供了捕捉长记忆性的能力。由于长记忆性广泛存在于金融,经济数据中,因此 ARFIMA 模型在经济金融数据中得到了广泛应用。
-
ARMA 衍生模型:VARMA 模型
以上模型均是一维模型,而在实际应用中也会遇到多维的情况,将 ARMA 模型扩展到多维既是目前应用最广泛的 VARMA 模型。
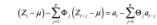
其中at为白噪声向量,Φt,Θt均为 k x k 的矩阵,μ为序列Zt的均值向量。
而在实际的应用中,最常用的是 VAR 模型,定义为:
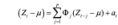
令
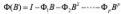
VAR 模型可简洁表示为:

在我们定义多维的 ARMA 模型之前,需要讨论多维序列的平稳性。 以及建立模型之后的参数估计等问题,可参考相关文献。
二、ARCH 模型及其衍生模型
-
ARCH 模型
ARCH(自回归条件异方差)模型[6]为异方差模型,在许多场景下,我们不仅需要对均值进行预测,而且需要对方差进行预测。而在 ARCH 模型提出之前,通常认为方差是恒定的。ARCH 模型也是获得 2003 年诺贝尔经济学奖的计量经济学成果之一。
ARCH 模型认为随机序列可分解为两个序列的乘积,即
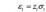
其中E(zt)=0,Var(zt)=1。σt为一个正数列,那么σt2即为εt的方差。其中σt2看作是εt2的一个回归,即
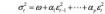
用延迟算子多项式可表示为:
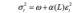
其中
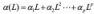
-
ARCH 衍生模型-GARCH 模型
类似于从 MA 模型扩展到 ARMA 模型的过程,GARCH 模型在 ARCH 模型的基础上加入了对σt2的自回归,即:
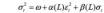
其中
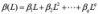
在文献中,对比了 ARCH 模型和 GARCH(1, 1)模型的延迟阶数的系数。如下图:

可见加入自回归项之后,GARCH 模型相比于 ARCH 模型能更合理的描述延迟影响并且使用了更少的参数。在实际数据的实验中,GARCH 模型的表现也相对于 ARCH 模型有较大的提升,因此 GARCH 的应用十分广泛。
而后学界根据不同的应用的场景对 GARCH 模型进行了各种改进,有学者统计,和 GARCH 相关的模型大概有 2000 多种。这里简要介绍两种比较经典的改进模型。
在现实世界中的很多数据的变化和自身的规模有关系,例如一个国家出生的人口和一个国家的人口规模有很大关系。为了在建模中抵消掉这种自身规模的影响,我们一般对其取对数而后进行建模。 EGARCH 模型中,把对 GARCH 模型中对σt2的回归替换为对ln(σt2)的回归,即:
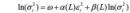
文献中给出来 EGARCH 模型的另一种表达:

其目的在于给与模型更好的可解释性。
下面介绍 GARCH 模型的另一种改进模型。TGARCH (Threhold GARCH) 模型在 GARCH 模型中又加入了一项以增加正误差项对当前值的影响, 可写为:
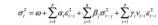
其中:
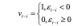
式中我们看到,TGARCH 模型用vt−i控制是否对εt−i2进行额外的回归,如果εt−i大于 0 就进行回归,否则就忽略。通过这种阈值调节模式,我们就可以完成对正负样本的不同调节。
我们针对不同的问题可以对模型进行适当的改进以适应我们真实数据的需要。
类似于 ARFIMA 模型引入了分数阶差分,也可以将分数阶差分引入 GARCH 中,从而得到了 FIGARCH 模型。 其表达如下:

其中

分数阶差分(1−L)d和 ARFIMA 模型中的分数阶定义相同,即:

由于分数阶的引入,使得 FIGARCH 模型具有了捕捉长记忆性的能力,在金融数据中表现良好。但是由于模型的估计相对复杂,目前应用最广泛的为 FIGARCH(1,d,1)模型。
ARCH 模型提出以后,学界同样将其扩展至多维,并且衍生出多个多维版本,比如 VECH 模型,DVECH 模型,BEKK 模型,CCC 模型,DCC 模型。这里简要介绍一下 VECH 模型。其表达式如下:

rt是 N x 1 的向量,Ht是 N x N 的协方差矩阵,εt是 N 元白噪序列。由于Ht是对称矩阵。所以其下三角部分可反映其全部信息,vech(⋅)函数就是将Ht的下三角部分张成一个向量,其维数是N(N+1)/2。所以在第二个式子中,C 是N(N+1)/2 维的向量,A, B都是N(N+1)/2 阶方阵。通过上面的式子可知,MGARCH 模型中,每个分量都是相互有联系的,并非独立。
三、Holtwinters 模型
Holtwinters 模型有加法模型和乘法模型两个不同表示,加法和乘法是针对周期影响而言的。 为了方便理解,下面着重介绍加法模型的建立过程。在最后会给出乘法模型的表示形式。该模型中用到的基本方法就是用指数平均的想法处理趋势和周期信息。
在时间序列预测中,我们很自然的可以想到使用平均值作为其预测值。例如在股票市场中,我们有 5 日均线,30 日均线等指标。但是这些均值并不是通过简单的滑动窗口平均得到的。因为简单的窗口平均存在一是初始值的处理麻烦,二是窗口内的每一点都赋予了相同的权重。,三是上一步计算的平均值无法迭代到下一步的问题。为此在实际的应用中我们往往使用指数平均的方法。
指数平滑有如下递推关系:

其中si就是第i 时刻的滑动平均值。上式中α控制着当前值在均值中的权重,取值范围为 (0, 1)。如果把上式继续迭代展开就可以得到:

可见距离当前点越远,对当前的平均值影响越小,并且以指数速度衰减。
当 时间 序列带有趋势,如果只用一次滑动平均就不能精确预测。为此需要在模型中考虑趋势的影响。这里引入了二次指数移动平均。 引入的方法为将序列的增量看做一个变量进行滑动平均,而后将增量加入到原来序列的滑动平均中。具体表达式如下:
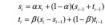
由上式可见si−si−1表示其增量,对其进行移动平均,而后加入到si的移动平均之中。
有许多 时间 序列存在周期性,因此我们需要将周期也要考虑进去。 同理,我们使用滑动平均的方法处理周期。若周期为 k,那么对于当前点,k时刻前的那个点与当前点处于周期的同一个位置。因此只需每隔个点进行滑动平均以捕捉其周期信息。
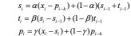
可见在对周期的预测中用xi−si表示当前点与均值的偏离程度,如果序列呈现出周期性,那么这种偏离程度也是具有周期性的。在最后向后的预测中,可以使用如下公式:
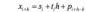
类似的可以得到乘法模型:
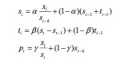
四、Prophet 模型
Prophet 模型是由 facebook 公司数据团队开发出来的时间序列预测模型。在 ARIMA 模型和 HoltWinters 模型中,最近的点占有比较大的权重。而 prophet 模型更多的是从全局考虑时序中规律,本质上是一种回归模型。基于时序分解的思想,prophet 模型把时间序列分成三部分,趋势,周期,节假日以及其随机成分。 用公式表示为:
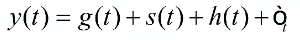
其中 g(t) 表示趋势,s(t) 表示假期,h(t) 表示节假日影响。Ot表示不可控因素当做随机因素处理。
在 g(t) 的建模中,prophet 在其最新的程序中给出了三种模式,分别是线性模式,饱和增长模式,还有一个常数模式。具体可参见其代码,不在此赘述。
s(t) 是用傅里叶级数的方式进行建模,并且支持多周期建模功能。但是程序中不具备自动检测周期的功能,需要提前知道序列的周期,具体式子如下:
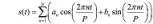
h(t) 为假节日影响,但是在程序中只能将其影响精确到天粒度,如果要精确到更细的粒度需要借助于外部回归项。总得来说 prophet 模型是一个十分有效的预测框架,尤其是对周期性数据,表现尤佳。
五、其他模型
时序预测问题通常被认为是一个回归问题,所以基于树的模型一般是回归树模型,这里简要介绍一下回归树模型。
树模型会根据一定的规则将特征空间划成若干子空间,在每个子空间上给出相应的回归值,一般为该子空间点的平均值。 在划分特征空间时,不会按照下图中左上子图的放式划分,如果这样任意划分的话,会造成每个子空间的数学表达十分复杂。通常会通过迭代的二分把特征空间划为若干子空间,如下图中的右上子图。其划分规则可表达为形如下图中左下子图的树形结构,我们在每个子空间取平均值作为回归值,如下图右下子图。
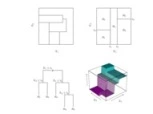
如果树的生成不受限制的话,会生长出一个十分复杂的树,就容易引起过拟合等问题。如果强制其停止生长的话,又会降低其预测精度,所以普遍采用先任由树任意生长而后剪枝的方法训练树。 此外基于优化算法中梯度下降的思想,梯度提升树的思想被提出,得到广泛应用的有 GBDT,XGBoost,LightGB。
六、总结
在智能运维的实际业务中往往面临着,高并发,低延时,数据量大等挑战。基于统计学习的预测算法具有模型结构简单,运算速度快,鲁棒性强等特点。 因此它在实际预测业务中的应用越来越得到广大运维工程师的重视。
开源福利
云智慧已开源数据可视化编排平台 FlyFish 。通过配置数据模型为用户提供上百种可视化图形组件,零编码即可实现符合自己业务需求的炫酷可视化大屏。 同时,飞鱼也提供了灵活的拓展能力,支持组件开发、自定义函数与全局事件等配置, 面向复杂需求场景能够保证高效开发与交付。
点击下方地址链接,欢迎大家给 FlyFish 点赞送 Star。参与组件开发,更有万元现金等你来拿。
GitHub 地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee 地址:https://gitee.com/CloudWise/fly-fish
万元现金活动: http://bbs.aiops.cloudwise.com/t/Activity
微信扫描识别下方二维码,备注【飞鱼】加入AIOps社区飞鱼开发者交流群,与 FlyFish 项目 PMC 面对面交流~

|








- 上一条: 实至名归 | OpenSCA成为开源中国GVP-Gitee最有价值开源项目 2022-06-09
- 下一条: 想做钢铁侠?听说很多大佬都是用它入门的 2022-06-10
- 深度解析 Lucene 轻量级全文索引实现原理 2021-08-01
- AIOps场景下,指标预测算法基础知识全面总结 2022-05-16
- 0基础都能看懂的算法图解 2021-07-19
- 顶会VLDB'22论文解读:多元时序预测算法METRO 2021-10-25
- Promise.race() 原理解析及使用指南 2021-09-08


