运维领域告警智能定级原理探索(含详细实验报告)

引言
很多大规模复杂在线服务系统,比如Google、Amazon、Microsoft和大型商业银行,包含数以千计的分布式组件,并同时支持大量用户使用。为了保障高质量服务和良好的用户体验,这些公司引入监控系统,智能收集服务组件的监控数据,比如指标/KPI、日志和事件等。通常工程师会根据经验设定一些规则用来检验监控数据,确保在服务异常时产生告警。这也带来一个问题,大型服务系统通常会不间断地被捕捉到大量告警消息,远远超出预算范围内配备的工程师人员所能处理的上限。为了解决这一难题,通常运维人员会设定一些规则,将这些告警消息按照严重程度的轻重进行分级,确保有限的工程师资源优先解决那些严重等级较高的消息,以此在系统告警应对效率和工程师资源中取得最佳平衡。本文将对告警智能定级进行相关探索与实验。
一、现状调研
1、告警智能定级相关因子
a. 文本特征
告警消息的语义信息可反映它的主题,根据经验知识将该主题的告警级别进行定性,从而可得到该告警消息的告警级别。比如,如果告警消息符合某种特殊的日志异常特征,可根据该异常日志的重要程度对告警消息进行定级。
b. 时空特征
(1)出现频率:一般频率越低,越有可能属于严重告警;
(2)周期性:周期性越强,告警级别越低;
(3)数量:短时间内大量爆发的告警应该予以重视;严重程度也应该考虑在内。
(4)间隔时间:如果告警警报是在系统运行一段时间后突然产生的,告警级别可能很高,应该重视。
c. 其他特征
(1)基于规则的告警级别:原始的告警级别
(2)告警时间:业务繁忙时出现的告警严重级别更高;
(3)告警类型:比如应用、操作系统、网络、内存、中间件等,应用层面的告警级别更高,因为与服务稳定性和用户使用体验相关。
2、告警智能定级方法调研
2.1 拓扑熵定级
利用发出告警消息的节点重要性对该告警消息进行定级,这是一种间接的告警定级方法。目前关于香农熵在节点重要性评估方面有大量相关研究,总体可以分为以下两个方面: (1)间接法。计算删除一个节点后和删除节点前网络图的熵差,熵差越大,说明节点对网络的影响越大。将熵差作为该节点的熵值,熵越高,节点重要性越大。(2)直接法。包括degree、neighbor degree、strength、the weight of edges、betweenness、closeness centrality等计算指标来计算节点熵,熵值越高,节点重要性越大。
2.2 特征定级
利用告警消息的文本特征、时空特征、其他特征中的一种或者几种,依据先验知识或者某种规则,对告警消息定级。
2.3 基于机器学习的特征定级
机器学习方法进行告警智能定级是一种综合性的定级手段,该方法通过从告警消息中提取相应的特征,包括文本特征、时空特征以及其他特征,形成特征向量,将该特征向量与自定义的定级级别组成数据与标签,在机器学习框架里进行训练,从而得到定级模型,方便对以后的告警消息进行智能定级。这种方法综合考虑了多种特征,缺点在于实现比较复杂,评价标准不统一,需要大量的实验与验证。
二、实践
1、基于拓扑熵的告警定级实验
1.1 实验原理
香农熵的信息方程为
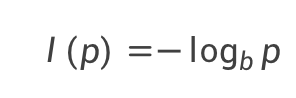
p表示事件发生可能性的概率,b是对数底数,信息理论里通常取值2。
熵:事件信息量的平均值。
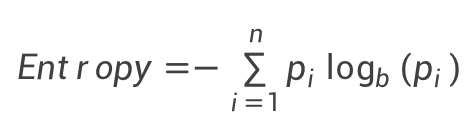
对于图G(V,E),V表示顶点,E表示边; 节点度:与节点相连的边的数目,ki表示顶点vi的度; E :图中存在的连接边总数。节点熵衡量的是——local ‘information’ that a given vertex carries about the global structure of the graph——关于整个网络节点携带的局部结构信息含量,节点熵越高,表明节点信息含量越大,说明节点重要性越高。当节点熵计算所基于的概率(p,衡量节点在网络结构中携带信息的概率)定义不同时,计算熵的方法也不同。
表1 节点熵计算方法表
| 序号 | 相关定义 | 节点熵计算方法 |
|---|---|---|
| 1 | 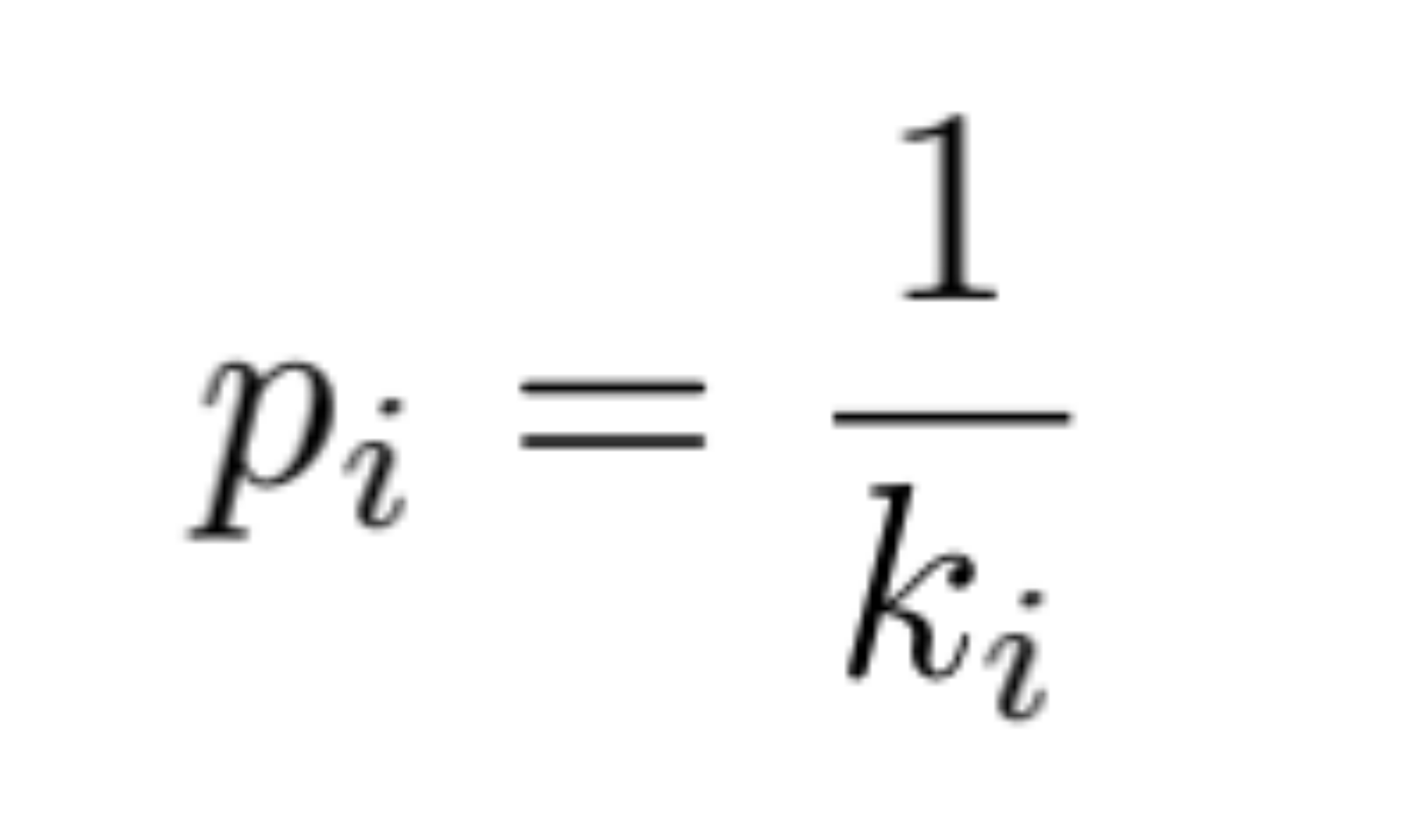 |  |
| 2 | 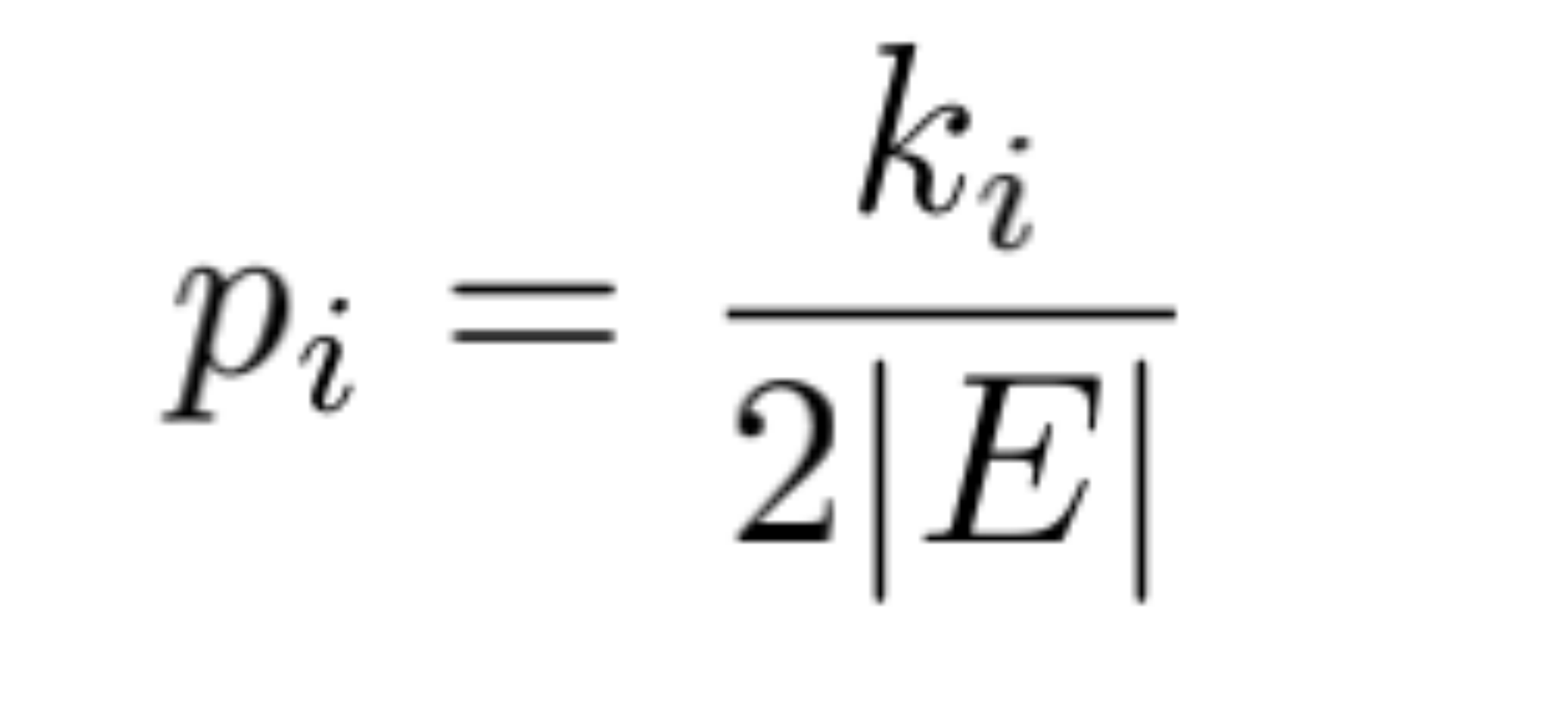 | 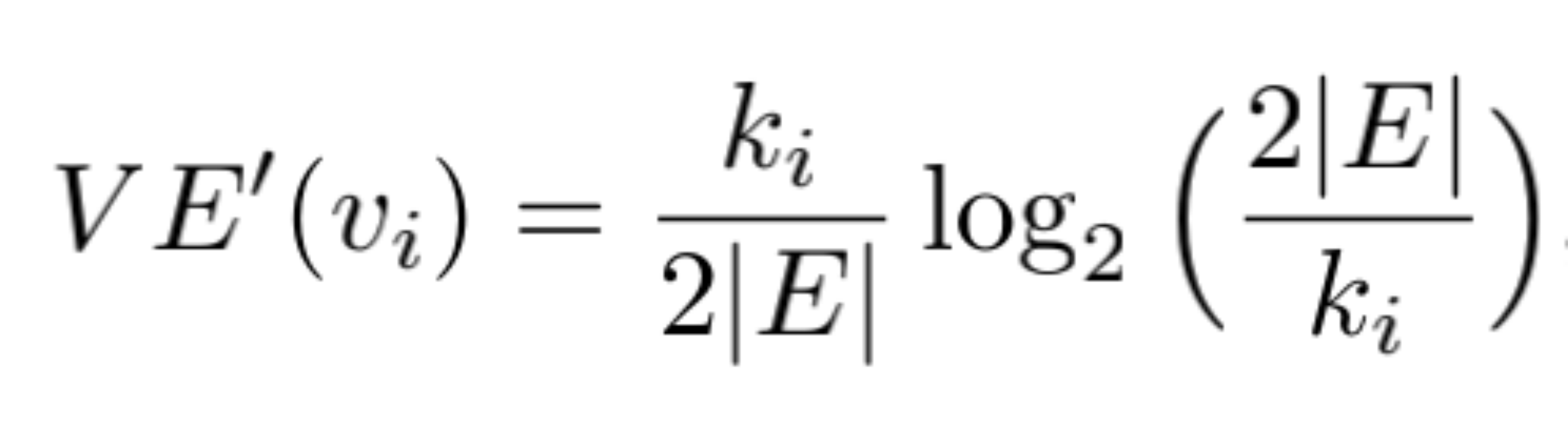 |
| 3 | 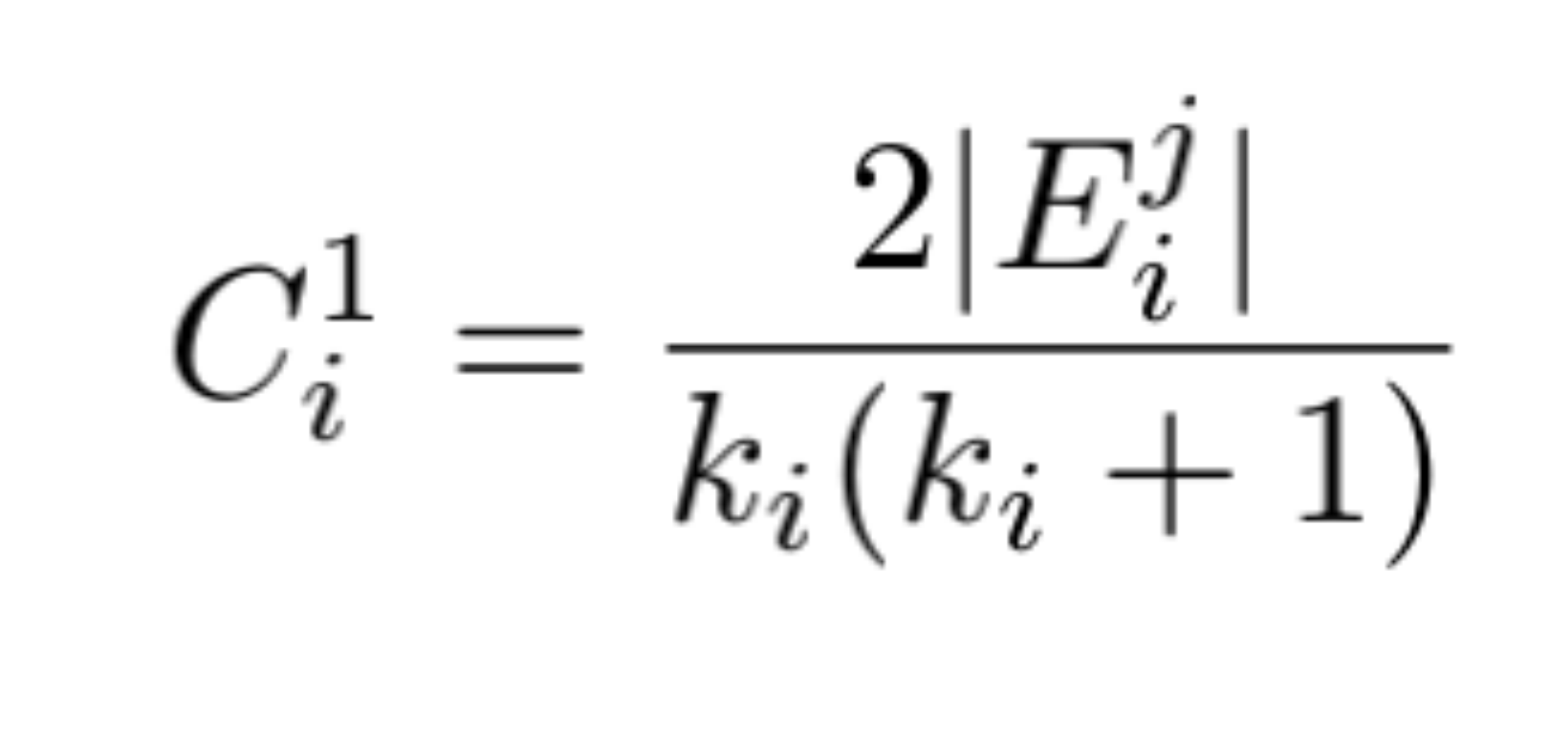 |  |
| 4 | 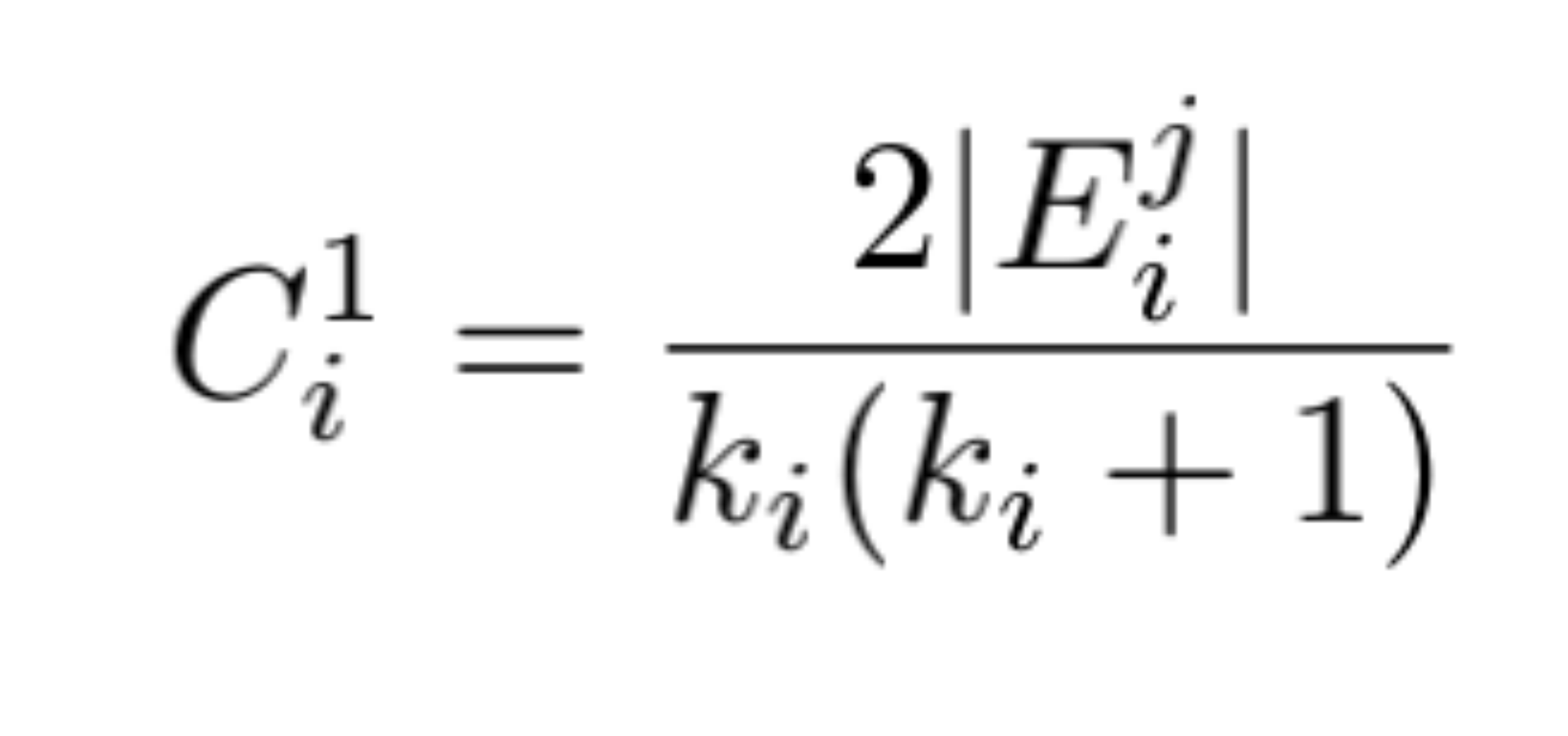 | 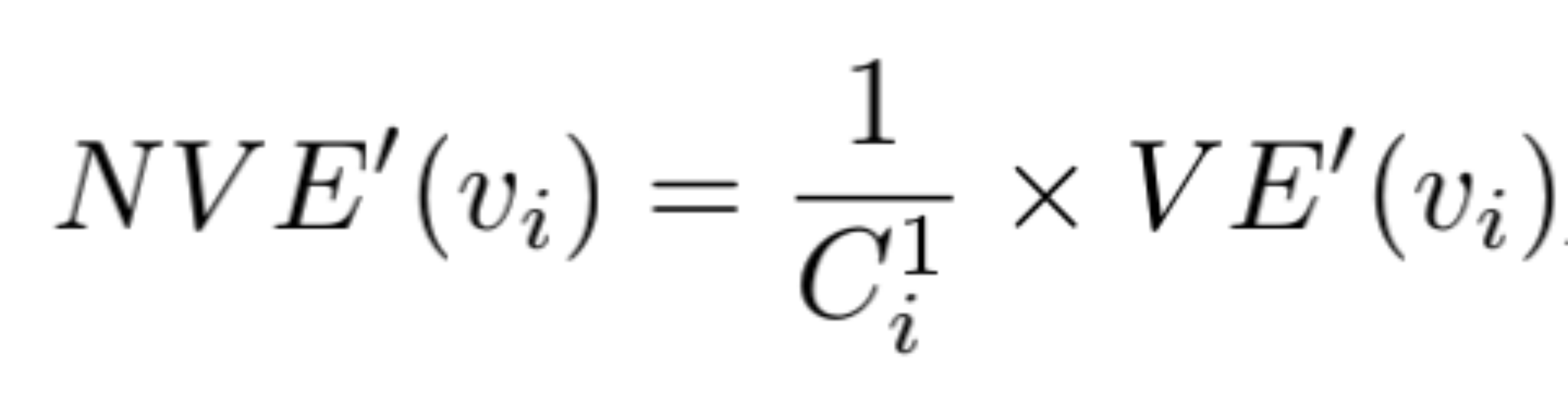 |
| 5 | 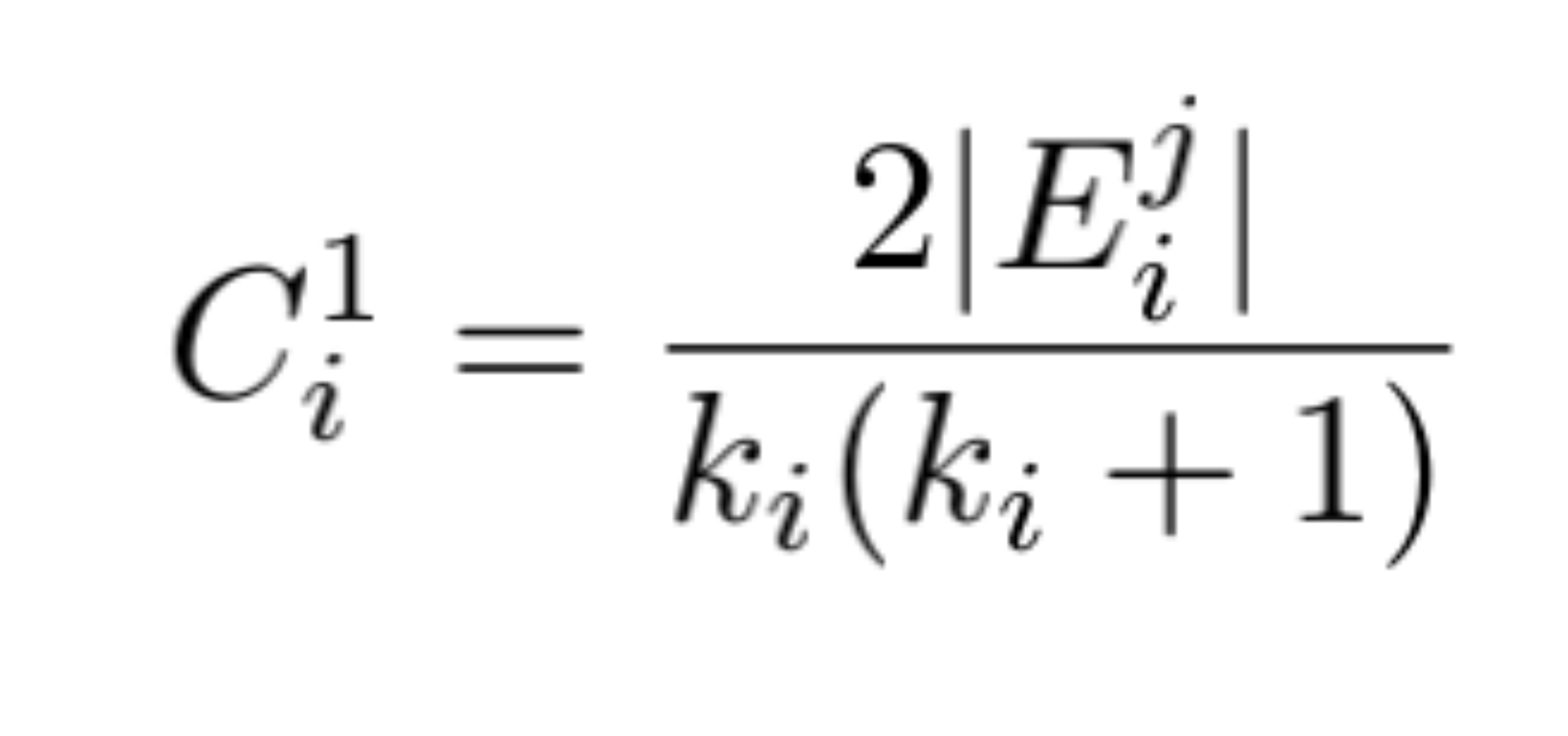 | $$$$C_i^1log_2(\frac{1}{C_i^1}) $$$$ |
| 6 | 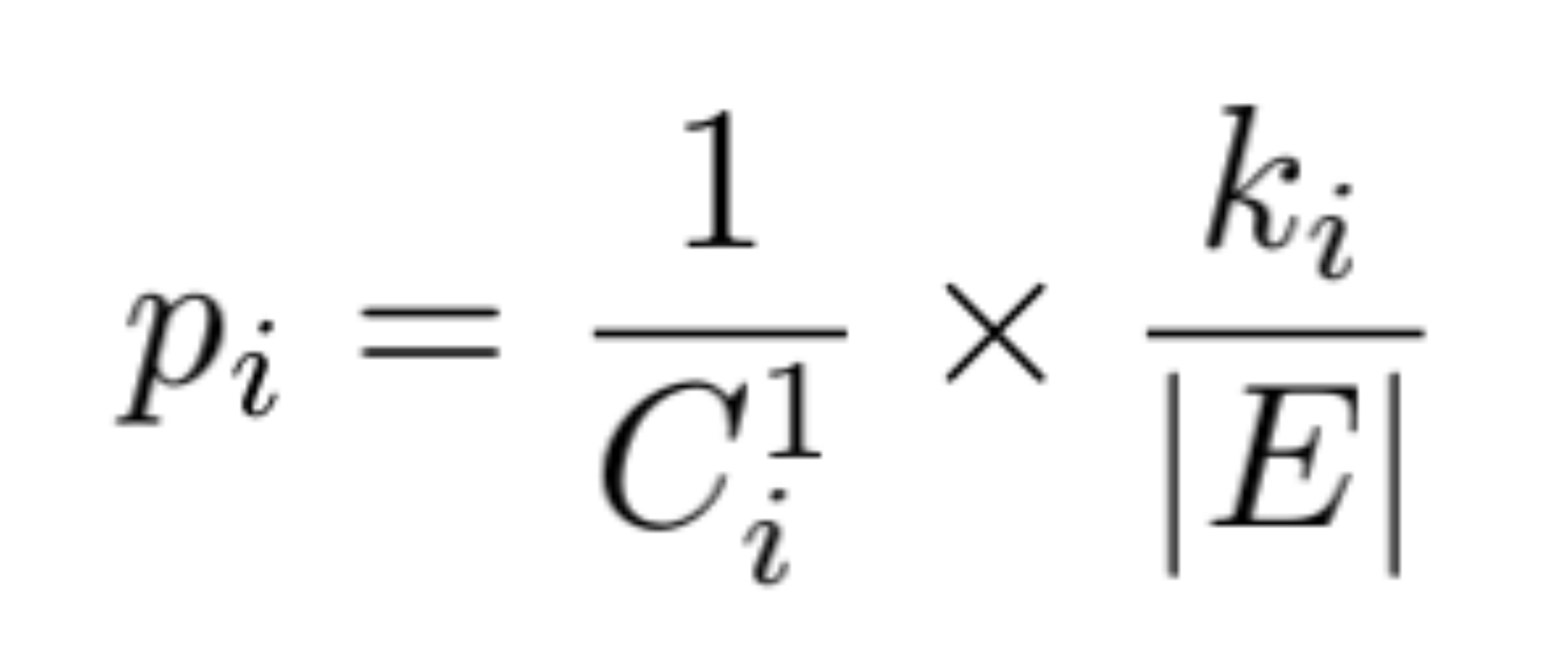 | 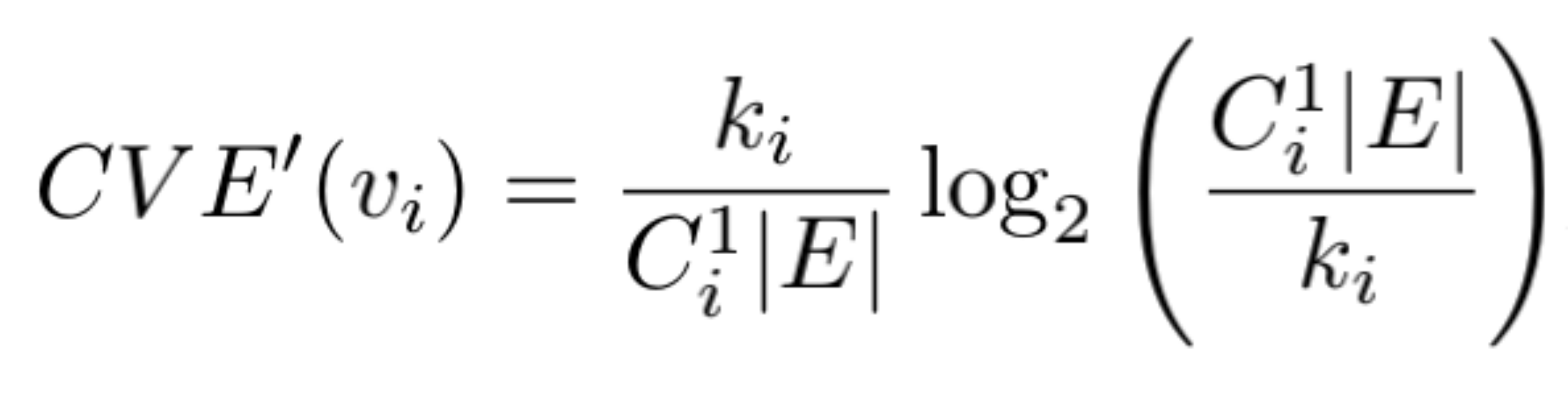 |
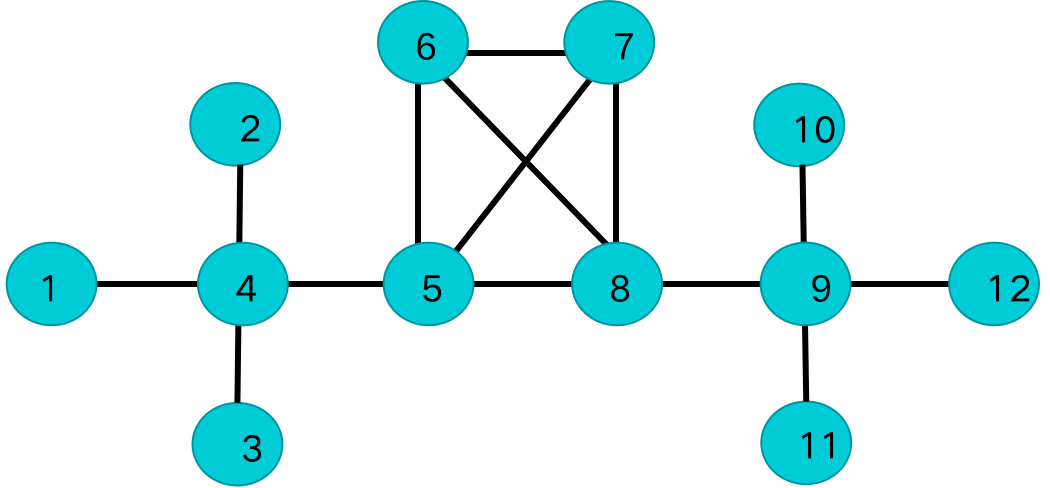
1.2 实验数据
目标网络拓扑如下图所示:
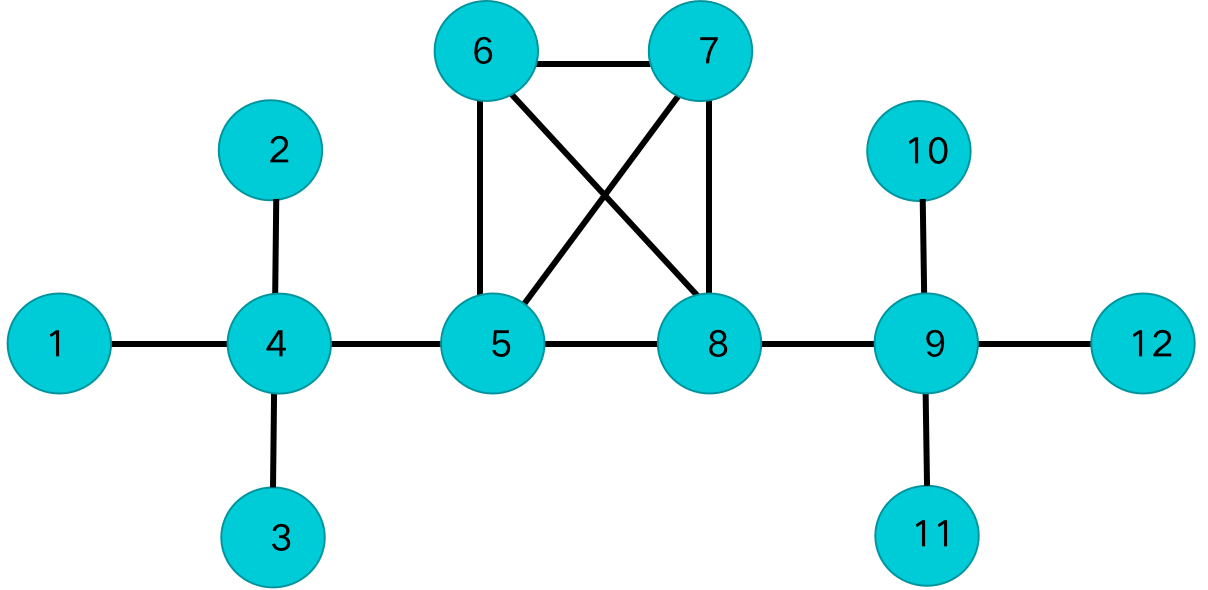
1.3 实验结果
利用表1中的计算方法,对上述实验数据进行节点熵计算,结果如下:
| 序号 | 拓扑熵计算结果 | 序号 | 拓扑熵计算结果 |
|---|---|---|---|
| 1 |  | 2 | 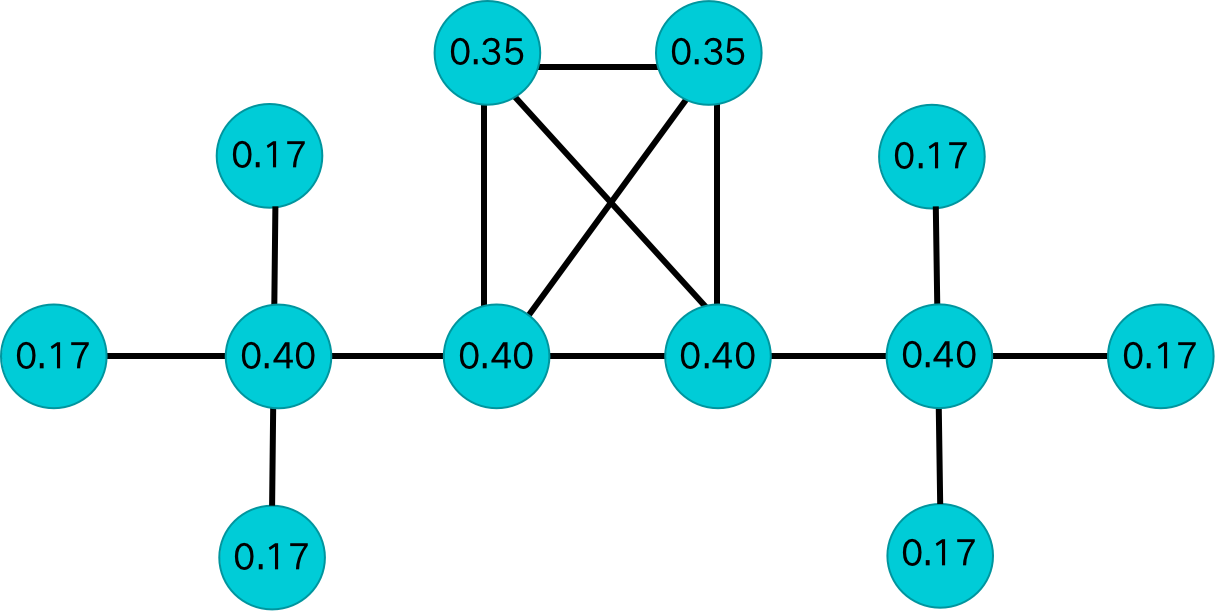 |
| 3 |  | 4 | 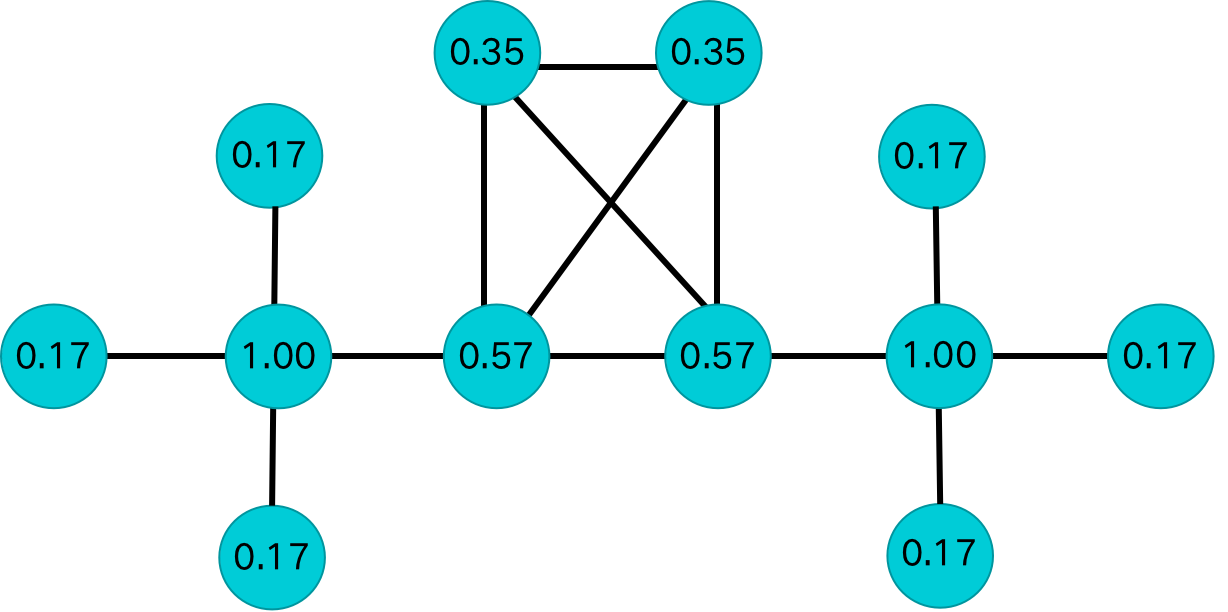 |
| 5 | 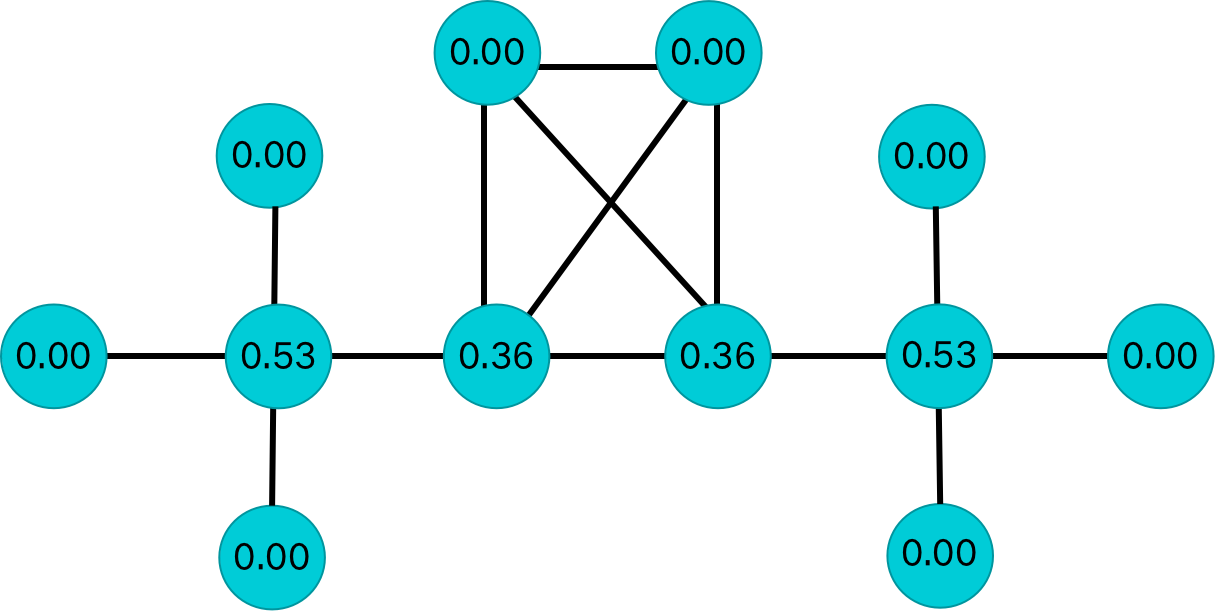 | 6 |  |
1.4 实验结论
根据拓扑熵的计算方法得出的节点重要性排序如下表所示,根据经验,4、5、8、9在该网络中应重要性靠前,6、7相比于1、2、3、10、11、12应重要性较大,在这个网络结构下,NVE和NVE'的排序结果更符合实际情况。在其他网络结构下,可能需要进一步具体问题具体分析。
| 对象 | 结论 |
|---|---|
 | 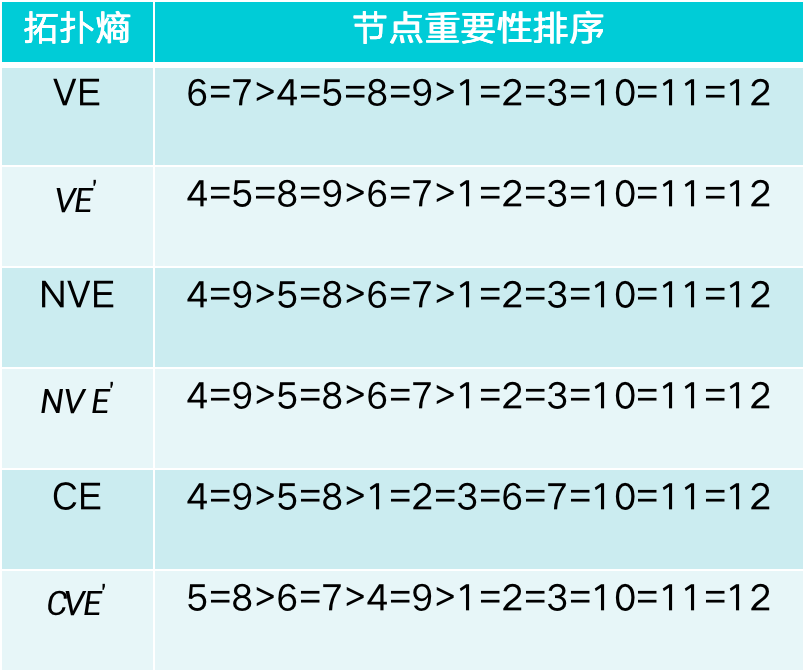 |
2、基于告警文本特征的告警定级实验
2.1 实验方法
主要分为以下三个步骤:
(1)告警数据预处理
分词(Tokenization):首先过滤掉符号,将剩余文本分成词语;然后去除停用词,因为停用词在识别严重告警时没有用处。
(2)提取文本熵
IDF(Inverse Document Frequency):词语出现的频率越高,IDF越小
对每一个词:
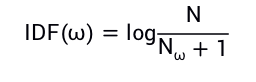
N是警报的总数量,Nw是包含词语w的告警数量
每个告警警报的熵计算方法如下:

#w是该告警警报中词语的数量。
(3)根据文本熵进行告警定级: 文本熵越高,告警级别越高
2.2 实验数据
以下以自定义的一组告警消息(17条)和停用词,展开实验。停用词是指在处理自然语言数据(或文本)之前自动过滤掉某些字或词,以避免无意义的单词影响文本熵的计算结果,这些字或词即被称为Stop Words(停用词)。本实验中由于实验文本数据样本较小,所以只是针对性地引入了一些停用词。
2.3 实验结果
| 说明 | 结果 |
|---|---|
| 有效词语及其统计词频、IDF | 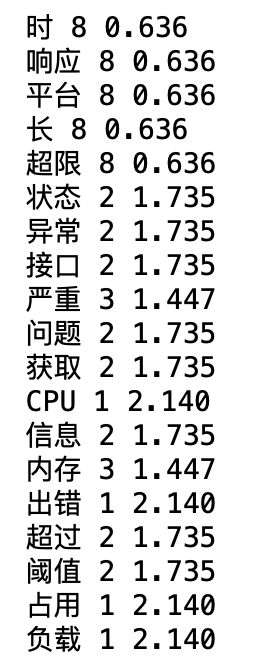 |
| 每条消息分词和去除停用词后的结果及计算出的熵值 | 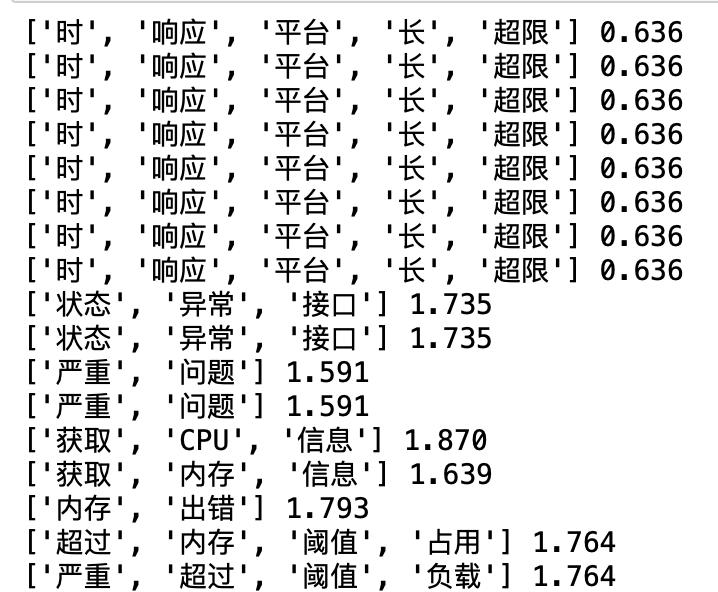 |
| 熵值从大到小排序(前50%的消息) |  |
2.4 实验结论
我们知道熵越高,告警级别越高。从运算结果可以看出:告警频率越低,熵值越高,因而级别越高。因此,告警频率越低,告警级别一般更高。
三、总结与展望
告警定级给出了一种合理判断哪些告警消息需要优先处理的思路,有利于在有限的人员资源情况下提高运维效率。基于拓扑熵的告警定级和基于告警文本特征的告警定级是两种不同的定级思路,不同的节点出现同一故障可能出现相似的告警文本,相同的节点出现不同的故障可能导致出现完全不同的告警文本,以上两种告警定级方法在相同的场景下可能定级结果完全不同,但是它们没有绝对的优劣。总的来说,任一种告警定级方法都不能完美适用所有定级场景,需要具体问题具体分析,未来运维场景里更有可能是综合运用不同的定级方法。
参考文献:
[1] Omar Y M, Plapper P. A survey of information entropy metrics for complex networks[J]. Entropy, 2020, 22(12): 1417.
[2] Tee P, Parisis G, Wakeman I. Vertex entropy as a critical node measure in network monitoring[J]. IEEE Transactions on Network and Service Management, 2017, 14(3): 646-660.
[3] Zhao N , Jin P , Wang L , et al. Automatically and Adaptively Identifying Severe Alerts for Online Service Systems[C]// IEEE INFOCOM 2020 - IEEE Conference on Computer Communications. IEEE, 2020.
开源福利
现如今,云智慧已开源数据可视化编排平台 FlyFish 。通过配置数据模型为用户提供上百种可视化图形组件,零编码即可实现符合自己业务需求的炫酷可视化大屏。 同时, FlyFish也提供了灵活的拓展能力,支持组件开发、自定义函数与全局事件等配置, 面向复杂需求场景能够保证高效开发与交付。
点击下方地址链接,欢迎大家给 FlyFish 点赞送 Star。参与组件开发,更有万元现金等你来拿。
GitHub 地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee 地址:https://gitee.com/CloudWise/fly-fish
万元现金福利: http://bbs.aiops.cloudwise.com/t/Activity
微信扫描识别下方二维码,备注【飞鱼】加入AIOps社区飞鱼开发者交流群,与 FlyFish 项目 PMC 面对面交流~

|








- 上一条: C/C++ 单元自动化测试解决方案实践 2022-06-05
- 下一条: 深度操作系统20.6正式发布! 2022-06-05
- 深度解析智能运维下告警关联频繁项集挖掘算法原理 2022-06-09
- 告警风暴来袭,智能运维应如何化解? 2022-05-06
- 值得一看的智能运维AIOps关键核心技术概览! 2022-07-18
- 智能运维 VS 传统运维|AIOps服务管理解决方案全面梳理 2022-05-06
- 运维工程师必备利器|一招实现运维智能化! 2022-01-07


