工程师如何对待开源---一个老工程师的肺腑之言

工程师如何对待开源
本文是笔者作为一个在知名科技企业内从事开源相关工作超过20年的工程师,亲身经历或者亲眼目睹很多工程师对待开源软件的优秀实践,也看到了很多Bad Cases,所以想把自己的一些心得体会写在这里,供工程师进行参考,希望能帮助工程师更好的成长。
概述
作为一个在科技企业内部进行技术工作的工程师,工作任务就是用技术手段支持和实现公司所关注的商业目标。 实际工作过程中,需要主动或者被动的使用和维护大量的开源软件。 据统计,每个工程师在企业内部进行研发和运维等工作的时候,每年会接触到上千款开源软件, 如果是以Java或JavaSciprt为主要程序开发语言的工程师,则接触到的开源软件数量更多,在万级别甚至十万级别。 (数据来源:《2020 State of the Software Supply Chain》由Sonatype发布)
那么如何选择开源软件? 这么多开源软件中,如何根据个人需求和业务需要来选择合适的开源项目来进行投入,是需要综合考虑的。
选择了开源软件之后又如何进行定制和长期维护? 这也是一个很大的问题。因为在企业内部开发软件,跟个人开发软件不一样的是,维护一个计算机软件系统的成本远远大于开发该系统或软件的成本。选择开源软件之后,如何从长期的视角进行定制和修改,后续的长期维护如何进行,才能做到高效和节省成本,业内有很多很好的经验,也有不少不太成功的案例成为教训。
最后回到个人,工程师的成长是在不断的学习和实践中进行的。如何来利用开源来提升自己能力,扩大自己的眼界,提高自己技术口碑和业内影响力,对于工程师本人也是非常重要的。
本文将从如下三个部分来分别阐述:
- 工程师如何选择开源软件
- 工程师如何定制和维护开源软件
- 工程师个人成长如何利用开源
1. 如何选择开源软件
首先要明确对开源软件的态度,在现阶段是不可能离开对开源软件的使用的。 使用开源软件有各种各样的风险,包括开源合规、安全、效率的问题。 简化为一句:在企业内部使用开源软件,需要遵守该企业对开源软件的内部规定,包括如何引入和如何维护,以便达到高效、安全、合规的使用。
回到具体如何选择特定的开源软件的问题上,有如下几个纬度可以进行参考。
- 根据需求
- 根据技术发展趋势
- 根据软件采纳周期的不同阶段
- 根据开源软件的成熟度情况
- 根据项目的质量指标
- 根据项目的治理模式
1.1 根据需求来选择开源软件
选择开源软件,首先要明确需求,即选择这个开源软件的目的究竟是什么。 工程师选择一个开源软件,究竟是它用来做什么的,是用来进行个人学习的; 还是用来满足ToB客户的需求的;还是用来满足内部服务开发的需求的。 这三个不同的目的下,选择开源软件的导向完全不一样。 (注意:后两个场景是需要先考虑企业开源合规的需求的,参见第三章)
先说说选择开源软件来进行个人学习,那么需要看看个人学习的具体目的究竟是什么。 是想学习一种比较流行的技术来完善个人的技术知识结构扩大个人技术视野;还是想看看相应的开源技术项目的具体实现,来作为内部项目技术开发的参考;还是想为了下一份工作进行有针对性的技术准备。不同的目的会导致不同的选择。针对前者,显然是什么技术最流行选什么,自己缺什么选什么;针对第二种目的,一般是对该技术领域的知名开源软件或者创新性软件进行有针对性的选择,即某个特性是我当前需要的,或者是我当前项目实现不好的,我需要看看别人是如何实现的。最后一种,显然是按照下一份工作的职位需要和技术栈要求进行准备,并根据技术栈要求的门槛高低进行选择。但是注意,从个人需求出发选择开源软件,一般都需要写个小项目练练手,比如一个Demo程序或者一个测试服务,因为不用考虑后续的长期维护,所以尽可以按照个人的想法和个人研发习惯进行各种练习,不用遵循企业内部的开发流程和质量要求,也不用考虑该开源软件的稳定性和社区成熟度等情况,只需要尽情的学习和参考代码就好了。
然后看下一个需求,选择开源软件进行研发的软件是需要提供给客户的,往往可能还是以私有云的方式进行交付。基于此类需求来选择开源软件,注意作好平衡,即客户的需求和企业自身技术规划或产品的长期规划需要。以私有云方式进入客户的IDC环境,是需要跟客户开发和运行环境的上下游项目进行集成的。这时候要看客户的需要,可能某些客户对开源软件有特定的要求,例如要求使用HDFS而且是某个特定版本。对这类指定软件名字和指定版本的要求,有可能是因为客户当前比较熟悉这个版本,也有可能是因为之前其他软硬件供应商提供的软件和版本,指定的目的是方便集成和后续的使用与维护。如果这种需求是符合企业项目或者产品的长期发展需求的,则是可以完全满足的。如果甲方非常强势,除了满足他的要求之外没有别的办法,那就选择客户所指定的软件和版本好了。但是如果跟自身项目或产品的长期发展需求不一致,而且具体项目或者版本是可以跟甲方进行协商的,那么需要跟客户协商出一个双方都能接受的结果出来,即选择特定的开源软件和版本既要做到客户满意并买单,又要做到自身的交付成本可控,还要做到符合自身项目或者产品的长期发展需要。例如客户使用Java的某个老版本,但是企业的toB交付的软件要求使用Java的较高版本。那么需要跟客户协商,要么切换到企业希望的版本上,还需要帮助客户完成已有系统的升级工作;要么只能降低自身软件的Java版本需求,可能还需要对某些自身代码进行修改,还可能对软件中的某些依赖组件进行修改。这个场景下是带有很多客观约束条件下的选择,是需要跟客户,自身的产品经理和架构师一起协商的。
最后,如果场景是为了满足内部服务的需求,即选择开源软件来搭建的服务是给内部业务或者最终用户来使用的,常见于国内各大互联网公司的互联网服务系统和各种手机上的App。这时候项目的开发和维护方有较大的自主权,跟toB的交付业务完全不一样。此时选择开源软件,就一定要综合考虑开发和维护成本,还要考虑使用该服务的业务所处的阶段。
(1)如果提供的服务是给创新业务使用的,创新业务一般都是试错业务,随时需要根据市场情况的变化和当前执行的状态进行调整,很可能三个月后这个项目没了,即被取消了。这种情况下“糙快猛”的开发方式是比较合适的,不用太多考虑系统的可维护性和可扩展性,就用研发团队最熟悉的软件技术栈,然后用底层技术支撑团队比如基础架构团队提供的成熟而且经过验证后的底层基础技术平台就可以,最重要是尽快把系统搭建出来,然后随着产品进行快速的迭代。这个时候需要尽量降低现有研发运维团队的学习成本和开发成本,不用太多考虑可维护成本,因为需要糙快猛的把系统堆出来,验证产品需求和商业模式是最重要的,时间最重要。如果发现有市场机会,就快速跟进,站稳脚跟之后可以采用省时间但是费资源的方式(俗称“堆机器”)来进行扩展,或者采用“边开飞机边换引擎”的模式进行重写都是比较划算的。对于处于创业阶段的企业或者项目来说,速度胜过一切。
(2)但是如果选择开源软件搭建出来的计算机软件系统或者服务,是需要长期维护的,比如是给公司内成熟业务使用的,或者是针对公司内成熟平台的缺点进行系统升级并要替代原有产品的,那么在满足业务需求的前提下,考虑系统的可维护性变成最重要的事情。选择对应的开源软件,它是否成熟,是否稳定;二次开发是否友好;运维成本是否比较合算即比较省机器和带宽;运维操作是否方便,例如常见的扩容和缩容操作是否可以高效、自动、无损的完成;Upstream到上游开源社区是否容易等等,这些都成为需要重点考虑的事情。这种情况下,开发一个系统的成本,可能只占整个系统生命周期内的成本的1/10不到。所以在满足需求的前提下,重点考虑可维护性。
1.2 根据技术发展趋势来选择开源软件
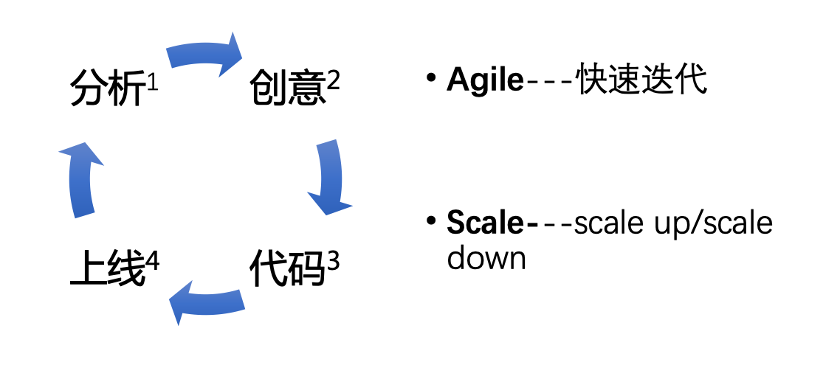
如上图所示,现代计算机软件或者服务的研发,是一个不断运行的循环和迭代过程。从市场分析开始,然后进入到创意阶段,再到编码阶段,最后到上线阶段完成应用的部署和生效,上线之后根据得到的数据反馈,继续进行分析。这个循环迭代的过程,显然对于一个身处竞争激烈的行业的企业来说,迭代的速度越快越好,同时也需要具备快速弹性、低成本伸缩的能力,即产品方向对了,那么赶紧进行系统扩容,承接快速增长的流量,做到快速增长;如果产品方向不对,需要赶紧缩容,把相关硬件和人力资源节省出来,投入到新的试错方向上去。身处同一个行业内的企业,如果企业A能以更低的成本,更快的速度的进行各种产品和策略的迭代,显然它是能比迭代速度慢,成本高的企业B是有更好的竞争优势的。
现在的开源软件数量非常多,几乎每一个分类下面都有很多的开源项目。针对某一个具体的需求,如何进行选择?一个建议是根据技术趋势进行选择。即现在的计算机系统迭代的方式是Agile(敏捷) + Scale(扩展)。显然,能够支持计算机系统进行快速迭代,并能够很方便进行低成本弹性伸缩的开源软件是值得进行长期投入的。而对一个新的开源软件的学习和使用,学习者是希望该软件的学习门槛越低越好。一个流行的开源软件,内部实现可以尽可能的复杂,但是对于用户来说一定是需要用户友好的。不然即使创新度再好,易用性不好,只有极客才能学习和掌握,创新的鸿沟是很难跨越的。
例如Docker的出现之后,以极快的速度风靡全球,非常多的工程师喜欢上了Docker。就是因为Docker的特性,在传统的容器系统之上增加了新特性,包括把应用程序和底层依赖库封装为一个容器镜像,容器镜像有版本,而且可以通过集中的镜像仓库进行存储和大批量分发。Docker首先解决了长期困扰工程师的开发、测试、上线环境标准化的问题,能够支持开发者进行快速的迭代。同时使用了统一的镜像仓库来进行镜像的分发,而且底层采用了轻量级虚拟机即容器的技术,可以非常快的被拉起,所以采用Docker的系统可以很方便的进行弹性扩展。同时,因为把应用App封装在一个镜像里面,可以在逻辑上根据Domain Model的设计原则进行更好的抽象和复用。显然,这样的技术是值得每一个开发计算机系统的工程师学习和掌握的。因为他能带来极大的方便。相反,在Docker产生之前,虽然Control Group(简称cgroup) + Namespace的技术早就已经出现,并早就集成在Linux内核中,Google的borg相关的论文早就已经发表,但是一般的技术研发团队不是很容易就能驾驭容器并把容器系统在公司内部大规模进行部署的。印象中borg论文出现后,国内只有BAT级别的互联网公司,才有一小撮精英研发团队来研发和使用容器管理系统,例如百度负责Matrix系统研发的团队,阿里负责Pounch系统研发的团队,腾讯也有一个小团队负责容器系统的研究。但是除了那一小部分团队,更多的工程师因为相对较难的学习难度而没有把容器大批的用起来。而Docker这种技术,就是非常好的顺应了敏捷和弹性扩展的技术趋势,而且提供了非常好的用户易用性,然后一出场就被非常多的工程师迅速使用上了,而且成为市场的默认标准。
这些顺应潮流的开源软件是值得选择和投入的。
另外一个例子是Spark,Spark的出现解决了MapReduce在分布式计算过程中因为需要频繁进行IO操作导致的性能比较低下的问题,同时在易用性上有较大的提升,所以才取代了MapReduce在分布式计算领域内的主流地位。
1.3 根据开源软件采纳周期的不同阶段进行选择
软件作为智力活动的产物,他有他的生命周期,一般用软件的技术采纳曲线表示。
开源软件也是软件的一种,也都是遵循软件的技术采纳规律的。如下图所示:

一个开源软件从创建到衰亡一般会经过5个阶段。 从创新期(Innovators,占比2.5%),到早期采纳期(Early Adopters,占比13.5%),然后跨越鸿沟(chasm),进入到早期大众期(Early Majority,占比34%),再进入后期大众期(Late Majority,占比34%),最后进入衰退期(Laggards,占比16%)。绝大部分的开源创新项目,没有能成功的跨域鸿沟,即从早期采纳阶段进入到早期大众阶段,就消亡掉了。 所以,如果是选择一个需要长期使用并维护的开源项目,选择处于早期大众或者后期大众状态的项目是比较理智和科学的。
当然如果只是个人想学习一个新的东西,可以看看处于创新者状态的开源项目,或者看看处于“早期采纳者”状态的项目。
注意不管是从长期研发系统的角度,还是从个人学习的角度,都不要再去看处于衰退期(Laggards)的项目了。 例如现阶段即2022年,是不用再去选择Mesos,Docker Swarm之类的项目了。自从Kubernetes成为容器调度技术分类的默认标准,这两个项目就已经处于衰退期,他们的母公司都已经放弃了。这个阶段如果还投入较多精力来开发和维护,除非真的是非常强势的甲方要求,把钱砸在工程师面前逼的不得不用才会选择。
同学们可能会问,从哪里可以看到这些技术采纳度曲线?
InfoQ,gartner,thoughtworks每年都会更新他们各自的技术采纳度曲线并公布出来, 大家可以在网上搜索一下,看看他们各自的技术采纳图是什么,然后结合一些业内的经验,得出自己的判断。
例如 https://con.infoq.cn/conference/technology-selection?tab=bigdata
从这里能看到2022年InfoQ对BigData领域各种流行技术的判断。

从上图可以看出,Hudi、Clickhouse、Delta Lake等开源软件还处于创新者的阶段,即在工业界采纳还比较少,对于想学习新项目的同学是可以重点关注的。但是现在这些开源软件还不适合应用在需要长期维护的成熟应用场景里面。
注意这些知名科技媒体的技术采纳曲线是每年都在更新的,在进行参考的时候别忘了注意一下发表的时间。
1.4 根据开源软件的成熟度情况选择开源软件
还有一点,即根据开源软件本身的成熟度来选择开源。 即从这个开源软件是否定期发布,是否处于一个多方维护的状态(即使一个公司的战略发生了变化不再继续维护了,还有其他的公司在长期支持),是否文档比较齐全等多个维度来进行成熟度的评估。
对于开源软件的成熟度模型,开源社区有很多度量开源项目的成熟度模型,其中Apache开源软件基金会的项目成熟度模型是比较有名的。
可以参考这里: https://community.apache.org/apache-way/apache-project-maturity-model.html
按照这个Apache开源软件基金会制定的开源项目成熟度模型,他把一个开源项目的评估纬度,分为7个维度:
- Code(代码)
- License and Copyright(软件许可证和版权)
- Release(发布)
- Quality(质量)
- Community(社区)
- Consensus Building(共识共建)
- Independence(独立性)
每个纬度又有几个考察项。例如针对Independence(独立性),又有两个考察项,其一是看这个项目是否独立于任何公司或者组织的影响,其二是看贡献者在社区内活动是代表他们个人,还是作为公司或者组织的代表出现在社区并进行活动的。
Apache基金会Top Level的项目即顶级项目,在毕业阶段都会从这些维度进行综合的判断。只有各方面都达标的项目,才会被允许从Apache基金会的孵化状态中毕业而成为成为Top Level的项目。这也是逼着个人比较喜欢Apache顶级项目的原因。
另外,OpenSSF项目的Criticality评分(参见https://github.com/ossf/criticality_score)也是一个不错的参考指标,它会度量一个项目的社区贡献者数量、提交频度、发版频度、被依赖的数量等指标,来判断一个开源软件在开源生态中的重要程度。这里就不详细展开了,有兴趣的同学可以参考它的资料,个人认为是一个值得参考的方向,但是这个评分还处于早期阶段,距离理想状态还比较远。
1.5 根据项目的质量指标来进行选择
很明显,有些开源软件的代码质量是比其他开源软件的质量好。 有的时候需要从项目的质量情况来选择开源软件。
这个时候,我们需要查看一些被业内广泛证明比较有效的指标。
其中MTTU是被知名开源供应链软件供应商SonaType所推荐的指标。 它在它著名的供应链年度报告里面提到MTTU。 参见https://www.sonatype.com/resources/state-of-the-software-supply-chain-2021
MTTU(Mean Time to Update):即开源软件更新它依赖库的版本的平均时间。举个例子来说,某开源软件A依赖于开源库B,假设A的当前版本是1.0,依赖B的版本是1.1。某天开源库B的版本从1.1升级到了1.2,然后一段时间之后,开源软件A也发布了新版本1.1,其中把对B的依赖版本从1.1升级到了1.2。这个时间间隔,即从开源版本B的版本升级到1.2的时间点距离开源软件A的新版本1.1的发布时间,称之为Time to Update,反映出来的是开源软件A的研发团队,根据依赖库的更新周期,同步更新它的依赖版本的能力。Mean Time to Update是指这个软件的平均升级时间。数值越低表明质量越好,表明该软件的负责人在很快速的升级各种依赖库的版本,在及时修复各种依赖库引起的安全漏洞问题。
据SonaType的统计,业内开源软件的更新升级时间MTTU越来越短。 据它的统计,在Maven中心仓库上的Java类开源软件,2011年平均的MTTU为371天,2014年平均的MTTU为302天,2018年平均的MTTU是158天,而2021年平均的MTTU时间是28天。能看出来,随着开源软件库更新频率的加快,使用它们的软件也随着加快了更新版本的速度,MTTU相对10年前,时间缩短到原来的10/1以下。
当然MTTU只有项目质量的一个间接纬度。 历史上是否爆出重要高危安全漏洞,修复响应是否快速及时,等等也是作为开源项目质量评价的重要维度。
某些大厂的安全部门,会不断评估开源软件的安全情况,把某些屡屡发生高危安全漏洞,但是修复不及时的开源软件设定为不安全软件,列入到内部的开源软件黑名单中对内公示,并要求各个业务研发团队不再使用这些软件,实在因为研发和人力问题不能迁移到新的软件系统的情况也需要把这些老服务迁移到一个相对封闭的网络环境中,减少风险可能造成的损失。这个时候,显然应该需要遵守公司的安全规定,不再使用黑名单上的开源软件。
1.6 从开源软件所属于的开源社区治理模式角度来考虑。
还有一个维度,即从这个开源项目的社区治理模式来考虑,适用于需要长期进行开发和维护的项目。
社区治理模式(Governance Model)主要是指该项目或者社区是如何做决定的以及由谁来做决定。 具体表现为: 是所有人都可以做贡献吗还是少数几个? 决定是通过投票的方式产生的,还是通过权威?计划和讨论是否可见?
常见的开源社区和开源项目的治理模式有如下三种:
- 单一公司主导:特点是软件的设计、开发和发布都由一个公司来控制,也不接受外部贡献。开发计划和版本计划不对外公开,相关讨论也不对外公开,版本发布时候才对外公开源码。例如Google的Android系统。
- 独裁者主导(有个专有名词“Benevolent Dictatorship”,翻译为“仁慈的独裁者”):特点是由一个人来控制项目的发展,他有强大的影响力和领导力,一般都是该项目的创始人。例如Linux Kernel由Linus Torvalds来负责,Python之前由Guido Van Rossum来主导。
- 董事会主导:特点是有一拨人构成项目的董事会来决定项目的重大事项。例如Apache软件基金会的项目由该项目的PMC决定,CNCF的基金会的决策是CNCF董事会来负责(很多技术决定授权给了CNCF董事会下的技术监督委员会)。
个人意见和经验,根据该开源软件背后的开源社区的治理方式来进行选择优先级的排序如下:
- 优先选择Apache毕业项目(因为这些项目的知识产权情况清晰,而且至少有三方在长期维护)
- 次优选择Linux基金会等其他开源基金会的重点项目(因为Linux基金会的运营能力很强,每个重点项目后面往往都有一个或者多个大公司在支持)
- 小心选择一个公司主导的开源项目(因为该企业的开源战略随时可能会调整,很有可能不再持续支持该项目,例如Facebook就是一个弃坑很多的公司)
- 尽量不选择个人开源的项目(个人开源更加随意,风险尤其高,但是不排除某些已经有很高知名度,并且跑出长期维护模式的项目,例如知名开源作者尤雨溪(Evan You)所负责的Vue.js开源软件)。
这是个人推荐的选择同类开源软件项目的优先级顺序,仅仅代表个人观点,欢迎讨论。
2. 如何定制和维护
把一个开源软件引入到企业内部后并用来进行开发和长期维护,就出现了如何定制和维护的问题了。 首先要明确,开源软件引入到企业内部之后是需要定制的。 因为如下几个理由:
- 开源软件往往都是适用于通用场景,考虑的情况比较多,需要支持各种各样的使用场景。但是引入到企业内部之后,往往只需要针对企业特定的场景。所以针对这些特定场景进行优化,例如对全部功能进行剪裁,去掉跟本场景无关的特性,针对特定场景进行性能调优和参数优化等,往往能取得更好的性能,例如抗更多的流浪,节省机器成本的效果是惊人的。这也是常见的定制方法。
- 开源软件进入企业内部要经过开发并长期运营,是需要满足该企业的各种内部的服务运维规范的。例如业务上线,是需要有完整的日志和监控,比如需要提供服务健康检查接口,还需要有流量调度等容错处理。这些都是需要进行定制修改的。
- 开源软件还需要对接企业内部的上下游系统,例如如果该软件的正确运行需要依赖底层的分布式存储和分布式计算系统来完成基本功能,是需要对接企业内部已有的存储系统或者计算系统的;企业内部的底层虚拟机系统或者容器调度系统,往往有部分修改和优化,对接起来也是需要进行修改的;所以这个时候需要进行定制修改。
- 特殊场景下的需求定制,在企业应用场景下使用该开源软件往往会遇到特定的问题,可能会碰到Bug,这些都需要Bugfix和新增特性来支持。
2.1 如何对开源软件进行定制和修改?
对此,笔者建议有几个基本原则: 不动开源软件的核心代码,尽量使用该开源软件已有的插件机制;或者在外围改;定期升级到开源社区的稳定版本。
很多开源软件在设计之初,就留下了不少扩展机制,方便后续开发者进行功能扩展和特性增加。例如几个最著名的开源软件Visual Studio Code,Firefox Browser就提供了Extension机制,很多开发者根据自身需求开发对应的插件,并把插件提交到官方支持的插件市场里面。普通用户在安装完成主要程序后,还可以浏览插件市场,寻找和选择自己需要的插件进行安装。 另外像Kubernetes,也在多个地方提供了扩展机制,例如核心调度器哪里提供了定制化的scheduler,可供开发个性化的调度策略;底层的存储和网络都提供了很多的插件机制;最值得称道的是它提供了CRD(Custom Resource Definition)的机制,允许开发者定义新的资源类型,并复用Kubernetes成熟的声明式API和调度机制,进行很方便的操作和运维。 所以,尽量使用该开源项目已有的插件或扩展机制来增加特性。
针对某些开源软件的修改和定制,并不太适合使用它的扩展机制,或者它本身没有提供可用的扩展机制。这个时候的修改,尽量在源码核心的外围进行修改,而不要去动它的核心代码。因为开源软件是随着开源社区的进展不停的迭代的,开源社区的发展会不断带来更多更好的特性。如果对核心代码进行了修改,而当需要升级到比较新的开源版本的时候,就会非常的痛苦。因为有大量的内部Patch需要进行合并,而且需要各种测试,会导致升级成本过高而无法跟社区的主要版本进行同步,最后因为部分核心工程师的离职或者转岗,那部分的修改没人能持续维护下去,导致整个系统无法维护和升级,最后导致整个系统被废弃或者被推倒重来,这会导致大量的人力成本。笔者在多家互联网大厂工作过很多年,看到了太多这种项目,太多本来针对开源项目的修改,是非常有必要的,但是因为改动了核心代码,导致想升级到开源社区的较新版本成本太高,最后导致系统无人能维护,只好推倒重来的例子了。
举个例子吧,笔者在某大厂内部看到有两个技术团队在维护Redis集群,当时使用的版本都是Redis 2.x版本。因为没有太多集群功能,对大规模的业务支持不好,所以这两个团队都对Redis的2.X版本进行了修改。其中团队A的改法是在外围改,即在Redis之上封装了一层,用来进行流量调度,Failover处理等功能;团队B就改的狠一些,直接改Redis的核心代码,把集群功能相关的代码直接加了进去,甚至在某些局部测试场景下,性能更好一下。短时间内,两个团队都能满足业务线的需求。但是Redis开源社区在不停的迭代,不断加入更多更好的需求,当Redis出到3.x的时候,两个团队都想升级到比较新的版本,因为使用Redis的业务方也希望使用3.x的版本。但是升级成本明显不同,团队A很快把相关功能移植到了3.x之上,很快把Redis版本升级了上去;团队B呢,因为对核心的改动太大,移植成本和测试成本都太高,所以迟迟不能对2.x版本的服务进行升级。等到社区4.x版本出来,团队B的核心工程师离职之后,该Redis集群已经没有人能够持续维护并满足客户的新版本需求,只好推倒重来,从社区的4.X版本直接建集群,自身的系统迁移化了很长时间,也给客户带来了很多成本。
所以,对开源软件源码的修改,都建议以Local Patch(本地补丁)的方式存在,一来便于进行维护和升级,二来也方便管理和统计。这种模式下,内部项目的编译脚本,一般都是把该开源软件的某个源码包解开,然后通过patch命令把这些Local Patch一一打进去,之后再一起进行编译和测试。而不是把Patch直接打到业务源码里面,虽然在CI阶段省了几分钟,但是后续的维护、升级、管理却增加了相当的麻烦。
2.2 回馈社区,Upstream(回馈)到上游开源社区,减少维护成本
工程师在企业内部针对某个开源软件的某个版本,进行功能特性的增加或者Bugfix之后,一般会以Local Patch(本地补丁)的方式存在在代码库中。笔者建议工程师在解决完业务问题之后,尽量把这些Local Patch提交到该开源软件所属的上游开源社区里面去,完成Upstream的过程。
Upstream有如下几个好处:
- 能获得更好的代码
在企业内部针对某开源软件增加特性尤其是Bugfix的补丁,往往因为时间紧急,更多采用的是“Hack”的方式,即为了快速上线解决问题,补丁修复的地方不一定很合理,代码补丁的逻辑可能会有漏洞,代码补丁可能对更多异常条件的处理不够完善等等。这个时候,如果把这个Local Patch提回到该开源项目所属的开源社区里面,跟该开源社区的资深工程师(Module Reviewer/模块负责人)等进行深入的沟通交流之后,往往会根据他们的反馈,对代码补丁进行更好的完善,从而能得到更好的代码。
- 能减轻维护成本
内部保留的Local Patch,在每次升级到开源软件较新版本的时候,这些Patch都是需要进行评估,部分需要和入并测试的。当然希望这些Local Patch的数量越少越少。最好的办法就是当该开源社区发布新版本的时候就已经包含了这些Patch。包含的数量越多,企业内部需要评估、需要合并和测试的Local patch数量就越少,升级起来成本就越低。记得Fedora的发布版本里面,每个版本都保留了不少针对内核和其他组件的Local Patch,红帽的工程师也在不断的把这些Local Patch贡献并和入到上游开源项目社区里面,这样才能保持Fedora内部的local patch数量在一个比较低的水平,也保证了升级版本时候的成本是比较可控的。
- 建立团队技术品牌和雇主品牌,方便招聘,并提升工程师自豪感,
向上游开源技术社区贡献代码,Upstream这些Local patch,是可以获得更好的社区口碑的。向这些技术社区表明该公司不仅只是开源软件的消费者,同时也是贡献者。
同时可以建立起较强的团队技术品牌,表明该公司不仅仅业务比较不错,技术团队也是很有实力的,这样方便对外招聘。
Upstream到上游开源社区,同时也有利于提升团队的工程师自豪感和满意度。
举个例子, 小米公司在大量使用Apache HBase项目的时候,负责的研发工程师坚决执行Upstream的策略,不断的把小米内部验证过的Patch贡献回到HBase社区,并和Hbase社区的同学们一起进行某些特性的讨论和研发。小米同学在HBase社区的影响力越来越大,不断产生了Committer和PMC,最后小米工程师张铎成为该项目的PMC负责人即项目的PMC Chair。小米公司在大数据、云计算等领域的技术品牌,很大程度上来源于此项目相关的研发团队。
3. 个人成长如何利用开源
工程师的成长,跟他从事的日常工作密切相关,也跟他的日常学习密切相关。 在这个过程中,如何利用开源软件,来更好的帮助工程师进行成长,帮助工程师实现他们的职业理想或者技术理想, 这里有一些建议。
3.1 开放和共享,眼界和心态
站住巨人的肩膀上才能站的更高。 开源世界里面有的是各种各样的软件,面向各种场景,解决各种问题。 所以一定要保持一个开放的心态,即在做什么技术相关的事情之前,先看看别人是怎么做的。 要知道世界这么大,工程师遇到的问题99.99%以上都是别人已经遇到的问题,别人是如何解决的,有什么经验可以学习, 尤其是可以看看别人开源出来的项目,看看他们的设计文档,看看他们是如何思考的;看看他们的源码,看看他们是如何实现的。 如果感兴趣,还可以进一步跟他们直接交流。 一来可以少走很多弯路,避免很多不必要的重复工作,避免重复踩坑。 二来不用重复造轮子,可以把有限的时间放在更有价值的工作上去。 千万不要坐井观天,老子天下第一,多看看工业界和开源界,刚毕业去大厂的同学尤其需要注意。
另外还需要共享的心态,学到了最好能共享出来, 让别人也能参考,吸取经验和教训,从而达到共同提高的目的。
3.2 学习开源软件的推荐步骤和方法—费曼学习法
学习开源软件有各种学习方法。 针对不同的学习目的,也需要根据自身情况(即对该领域的熟悉程度以及对相关开源项目的了解程度)等采用不同的更适合自身的学习方法。
笔者在这里给大家推荐一个适合工程师学习一门全新的开源技术项目的方法:
- 先尽快入门,把这个开源软件的Quick Start(快速入门)和Tutorial(入门教程)跑起来,先了解它的主要场景和关键特性。
- 然后看文档,注意系统的主要架构图,了解整个系统的大致架构,建立起一个比较大的整体框架图出来。
- 最后再结合自身的实际应用场景看相关细节,包括某个细节的文档和代码。
比如,如果想学习Kubernetes,先上它的官网,把它官网上提供的教程快速运行一遍 (https://kubernetes.io/docs/tutorials/kubernetes-basics/create-cluster/cluster-interactive/), 了解如何创建pod,如何访问,如何更新,如何进行流量调度等等。 然后看它的架构图,了解它的设计原则即声明式编程,包括几个核心组件Kube-apiserver,kube-scheduler,kube-controller-manager, kubelet等的功能以及这些组件都是如何交互的; 最后再根据自身的业务场景需要,看看具体哪部分还需要更深入的了解。 例如需要加入自己的存储方式,那么看看相关的代码,参考其他友商的存储方式的实现。
不建议一上来先捧着源码看,这么看是没有头绪的,而且效率很低。 况且现在不少开源项目都Too Big了,而且迭代速度很快,很难有人能了解全部代码,而且从个人精力来说做不到,更别说也没有必要。
注意学习一定要和应用结合起来,即要动手。“纸上得来终觉浅,绝知此事要躬行。”古人云,诚不我欺,对于工程师来说尤其如此。 如果是想比较深入的了解一门新的技术,甚至有打算切换技术路线和职业赛道,那么一定要更多的动手,要把这个开源软件用起来,或者写一点程序跑个Demo并运行在实验环境里面,最好解决一些身边的实际问题。千万别眼高手低,觉得一切都很简单,但是真的要跑起来,用起来就千难万难了。可以尝试参加技术企业内的一些创新活动,例如hackthlon(黑客松)活动,把新学的技术用起来;或者写一点点小工具,让他跑起来,解决一点点实际问题。例如,如果要练习Python,写一个爬虫,每天去爬天气预报网站上的数据,然后做一个简单的查询,可以获得当前的天气预报情况。在用中学,学以致用。
还有一个非常好用的学习方法就是费曼学习法。费曼学习法被认为是最有效、最强大的学习方法之一,亲测管用。 步骤也很简单,我把它简化为如下三步。
- 先学习一门技术
- 把它讲给普通人,让他听懂
- 如果听众没有听懂,回到第一步
通过这种方法,只有自己讲解该项技术的用法和架构,并能让普通工程师听懂这个技术,才算是真的掌握了。
费曼学习法来源于诺贝尔物理奖获得者理查德·费曼(Richard Feynman)。他是一位知名的理论物理学家,量子电动力学创始人之一,纳米科技之父,因其对量子电动物理学的贡献1965年获得诺贝尔物理学奖。他所提倡的学习方法,被称之为“费曼学习法”。步骤虽然非常简单,但是能把复杂的技术进行简化,并让普通工程师能听懂的方式讲出来,这需要对这门技术有深入的理解和掌握,还需要对一些专有名词和概念进行类比、联想来进行简化。一般能做到这样,就说明对这门技术已经达到了入门的程度,可以继续进行后续的更深入的学习了。
另外参加业内一些著名课程的考试或者认证也是一种比较好的方式。例如对云原生不熟悉的工程师,当他通过CKA(Certificated Kubernetes Adminitrator)认证Kubernetes管理员考试之后,这个认证可以验证他具备一定的水平,已经建立起对Kubernetes常见操作和系统架构比较全面的了解了。
3.3 融入开源社区,终身个人口碑
最后一点,对于工程师来说,参与和融入到开源社区里面积极贡献,将会获得终身的口碑,并能结交到终身的朋友,是十分有利于工程师的长期发展的。 在此,鼓励工程师,可以选择自己感兴趣的开源项目和社区,并通过交流和贡献,不断在社区里面成长。即使以后因为工作关系或者其他种种原因,不继续在这个开源项目和社区中活跃了,但是他的贡献将一直被承认。Apache开源软件基金会有一句很有名的座右铭:“Merit never expires”(参见http://theapacheway.com/merit-never-expires/),就是说工程师在Apache开源软件基金会项目和社区做贡献获得的认可,是永远不会过时的。曾经是提交者,永远是提交者。
在开源社区里进行协作,也是工程师进行社交的一种方式。在这里,能认识终身的朋友,能和他们一起工作和交流,对于工程师的成长也是非常有效的。很多开源社区的大牛,在社区里面也是非常友善的,尤其对待新人,对待比较junior但是贡献欲望比较强烈的工程师,更是愿意手把手的教的。在这些大牛工程师的帮助和指引下,新人的成长是非常快的,而且没有企业/部门/工作项目等带来的天花板。即新人可以在自己感兴趣的开源项目和社区里面,凭借虚心的态度和贡献欲望,不断和社区内的资深工程师进行交流和学习,可以带来技术能力的飞速发展的。
另外,对于现在的工程师来说,很难有终身雇佣的企业,工程师在企业里面也就是工作一段时间,然后随着各种主动或者被动的变化,岗位或者就职企业也会发生变化。但是在开源社区贡献所获的认可,和建立起来的个人品牌和技术口碑,是永远随着个人的,不会因为公司或企业的情况而发生变动。能看到很多一直活跃在开源社区的人,虽然职业发生了很多变动,但是他们在开源社区的认可和品牌一直存在。这也是很多工程师突破职业内卷,突破平台限制的一种好办法。
在开源社区长期做贡献,是利人利己的好事,鼓励每一位有想法,有行动的工程师,都能找到自己喜欢并投入的开源项目和社区,并且融入进去。
3.4 如何在开源社区做贡献
在开源社区,尤其是哪些尊重精英治理的社区(例如Apache基金会的项目),做贡献越多,得到的认可越多。 但是很多时候,作为一个新人,要去开源社区做贡献,并不是抬抬手就能做的,是需要先了解一些社区规则,然后遵守规则才能够慢慢融入的。
1. 贡献什么?
在做贡献之前,我们需要了解,对开源社区的贡献并不是仅仅局限于代码贡献,写代码增加功能或者Bugfix是贡献,完善文档和测试用例是贡献,报告使用问题是贡献,写博客介绍项目和推荐项目也都是贡献,这些都是在开源社区内被广泛认可的贡献。
很多社区的技术大牛,进入开源社区做贡献是从提交测试报告开始的。比如当年Mozilla社区最年轻的架构师Blake Ross(17岁就成为Mozilla社区最高技术决策层之一,并和另外一位架构师创立了Firefox项目),他最初进入Mozilla社区,是作为实习生,从测试开始的。
“Scratch your own itch!” 这是在开源社区流行很广的一句话,意思是说在开源社区做贡献,是需要解决自己的问题的。即在实际工作中遇到了问题,然后尝试去解决,最后把解决的结果以社区接受的方式贡献到社区。一般的情况是有个Bug或者问题影响用户的实际应用,或者想增加一个新的功能来满足企业的自身场景,或者就是想学习一些新的技术。这种解决自身需求的贡献,是比较长久的。而为了一些蝇头小利,参与社区运营的一些活动获取奖励,对工程师来说只是for fun,这种贡献也不是长久的。
所以,对于一个新人,进入到开源社区里面,贡献可以从一些简单的问题开始,从解决自身的需要开始。 一个最简单的例子,先看新手入门文档,照着文档描述的步骤一步步走下去,看看能否走通;如果走不通,可以报一个Bug出来;或者亲身体验需要增加一些额外的步骤才能走通,可以给这个新手入门文档提一个Patch,把这些补充步骤描述出来,这也是社区很欢迎的贡献。
有些社区把一些简单的Bug设定为“Good First Issue”,贡献者可以挑选这些Issue来进行贡献,来熟悉贡献流程,并融入到社区里面。
2. 了解现有社区情况,尊重社区的惯例和习惯
给开源社区做贡献的第一步是先了解社区。
可以通过社区的网站、邮件列表、Wiki、github代码仓库中的文档等资料,了解该开源社区的一些基本情况。
通过查看关键文档(Contributing.md),了解这些项目的贡献流程和推荐方法。
注意每个开源社区都有自己的惯例,比如他们有自己的Issue管理系统(有的可能用github的Issue,有的使用Bugzilla,有的使用Jira),然后提交Patch的流程和要求也不一样。
例如历史非常悠久的Apache HTTP Server项目,它对贡献者的要求如下:
- Patch需要符合他们的Code Style
- 对代码质量也有一些例如线程安全的要求
- Patch需要针对当前的开发版本 –2.5.X来做比较
- Patch的格式使用diff -u file-old.c file.c 来生成
- 提交Patch的入口在bz.apache.org/bugzilla,建议加上“PatchAvailable”关键字
- 可以在mail list中发邮件来讨论,邮件的title需要为[PATCH ]
注意他们采用的方式并不是github上流行的Fork/Pull Request模式,而是更古老的Bugzilla+Diff Patch的模式, 请尊重他们的工作习惯,使用他们要求的模式。(说句老实话,笔者20年前在Mozilla社区做贡献的时候,工作方式也是采用Bugzilla + Diff Patch的方式。二十多年过去了,Apache的HTTP Server项目的工作模式并没有发生大的变化。不过工作方式不影响贡献,熟悉并习惯就好。)
有的开源社区,会提供一种游戏化的贡献流程,即让开发者通过一系列简单的新手任务来熟悉项目和贡献流程。这种方式是对新人更加友好的,也是经过该社区的社区经理精心设计的。那么对于贡献者来说,别辜负了他们的良苦用心,走一遍自己觉得必要的任务,熟悉自己希望熟悉的任务和流程就好。
3. 态度需要“Be Polite and Respectful”,尊重社区的多样性
开源社区里面是充满多样性的。
开源社区内大部分的资深工程师对新人非常友好的,他们会很有耐心的教导新人,熟悉文档,熟悉贡献流程等等(注意一般只有一次,别辜负了)。日常交流中,包括在邮件列表中,在IRC或者Slack频道中,在Issue comments中,都比较nice。跟他们的沟通和协作比较容易。
但是注意,也有部分人相对态度不是特别好,如果遇上了,注意不用发生正面冲突。建议可以向社区更资深的一些工程师来求得帮助,而不用正面硬刚。不可能改变任何人,也不可能让所有人都喜欢,完成必要的工作就好。
4. 如何快速找到负责代码Review的Module Owner,完成贡献
有的时候,按照社区贡献流程的文档走下去,不管是提Issue或者报Bugs,发现模块负责人反馈很慢的时候,这个时候有一些技巧。
可以加入他们的IRC或者Slack频道,找到对应的模块负责人,然后跟模块负责人进行礼貌和有建设性的对话。
跟他们建立良好的关系,并通过实际的贡献,逐步建立起他们的信任。
注意,开源社区的运作是以信任为基础的。能获得模块负责人的信任,是非常有利于之后的工作开展的。
5. 提交大Patch需要注意步骤
可能有的工程师反馈,我给某某开源社区提交一个非常好的特性,在我的公司内部工作环境内测试并验证,效果非常好,性能表现非常出色。但是我把代码提交到上游开源社区的时候,发现社区并不看重这个特性,反而对我的Patch指指点点,挑出各种毛病。太麻烦了,太心累了,干脆不贡献了。
需要将心比心的想象一下,如果一个陌生人给你的项目提交一个很大的Patch,代码Review实施起来就很费劲,因为Patch比较大。虽然贡献者说这个Patch很有用,实现了一股很厉害的功能,而且经过了他的验证,但是他是否可靠,他是否能在社区里面长期存在,他是否能够及时修复他所提交的代码产生的问题,这些都是问号。所以在没有建立起基本的信任之前(即提交了几个小Patch并得到了和入),提交大的Patch是很费劲的。
另外,提交这个Patch的工程师往往并不了解这个开源社区的历史,也许这个功能很早就在社区被讨论过了,也许讨论的结论是不需要做或者在别的地方来做。所以,不要盲目自信于自己的Patch,而是应该先跟社区的工程师先沟通这个场景和问题。
笔者建议贡献的步骤如下:
- 如果判断这个Patch比较大,那么先在社区内讨论问题,让社区认可这个问题,同时也能获得社区对这个问题的一些历史信息(如果有的话)
- 如果社区认可该问题,觉得现在应该要修复了,继续讨论解决思路
- 问题和思路已经被认可之后,并完成一点点设计之后,再讨论具体的代码Patch
- Patch需要遵守社区的规范(CodeStyle、组件调用规范、测试规范、文档规范等)
- 做好心理准备,Patch可能需要反复修改若干次才能最后被和入,可能需要把一个大的Patch拆成若干个小Patch,分批提交和入。必要的时候需要一定的妥协。
贡献一个大的Patch,实现一个重要的功能,步骤虽然多,时间周期虽然长,但是完成之后,能得到社区的高度认可,往往是成为更高层级贡献者的基础。而且对于贡献者个人来说,内心的满足感和成就感也是非常足的。
6. 注意不要做以下的事情
- 提出一个Idea,希望别人来完成。
尤其是刚刚加入一个社区的时候,就提出社区需要做某些事情,但是自己不做,希望社区里面的其他人来完成,这些意见往往是会被忽略的。“有许多人,‘下车伊始’,就哇喇哇喇地发议论,提意见,这也批评,那也指责,其实这种人十个有十个要失败。”这种人更是不受社区欢迎的。
提出一个问题,同时提供一个有建设性的解决办法,而且自己要参加,可以邀请社区其他人来一起。这是比较推荐的做法。
- 过于急切,缺乏耐心,而忽略了社区的惯例。
宁可速度慢一点,尤其是在社区对新人的信任感建立起来之前,要有耐心。笔者曾经见过一个刚进入开源社区的工程师,技术能力很强,但就是只想快点把他的Patch和入进去。跟模块负责人的沟通的时候,态度虽然礼貌,但是对负责人给出的改进意见反应很敷衍。折腾过几次之后,该贡献者在该社区的口碑已经被损失殆尽,他相关的Bugfix和新功能开发进展很慢,他后来也黯然离开了该项目。
- 不要碰红线(即社区的行为规范所禁止的一些恶劣行为)
基本每个成熟的开源社区都有自己的行为规范(Code of Conduct),一般都会在该社区网站或者代码仓库的显著位置展示此文件。
规范内容列举出若干社区不欢迎的举动,包括性别、种族、宗教等方面的歧视和冒犯。
注意不要有这些行为,可能有的行为在中国开源社区里面并不被认为是大问题,但是在国际社区不一定是小事。
7. 在企业内部对上游社区做贡献要注意合规问题
在企业内部给上游社区做贡献,因为是把公司内部研发的结果公开出去,所以需要满足公司内部的开源贡献管理办法。
每个公司对此的规定不太一致。例如谷歌鼓励工程师贡献到开源社区,但是要求工程师应该以google.com的邮件地址来进行贡献,100行以下的贡献不需要通过内部流程审批,但前提是项目没有采用Google禁止的许可证(例如AGPL,Public Domain,CC-BY-NC-*),此外还有一些硬性条件,参见Google OSPO的官网链接https://opensource.google/documentation/reference/patching。 国内百度公司也是鼓励工程师贡献到开源社区,无论Patch大小都需要经过内部的电子流程,由该部门的技术总监进行审批,并交由百度的开源管理办公室(OSPO)进行备案,以便后续开源办公室的数据统计和对工程师的贡献激励提供数据支持等。
在企业内部给上游社区做贡献的时候,往往会碰到该社区要求工程师签署CLA(Contribution License Agreement,即贡献许可协议)或者DCO(Developer Certificate of Origin,开发者原创申明)的事情。其中CLA又分为ICLA(Individual Contributor License Agreement)和CCLA(Coperation Contribution License Agreement,即企业级贡献许可协议),其中ICLA是针对个人的,CCLA是针对整个企业的,即如果该企业签署了CCLA之后,该企业内部的工程师再做贡献就不用单独签署ICLA了。不签署CLA的话,则不能提交Patch。CLA条款的内容是贡献者把自己的贡献授权给社区来进行使用。此时请遵守公司内部的规定,相关的CLA条款可能需要经过公司内部的法务来进行Review。不过好在一些著名项目的CLA条款,例如Apache开源软件基金会的项目都使用统一的CLA文件,CNCF基金会的项目也是类似。这些著名项目的CLA条款,法务确认之后就没有问题了。如果不是法务已经确认过的CLA,需要跟公司负责的法务进行咨询,避免碰上一些对企业不利的CLA。
总结
本文比较长,凝聚本人的很多心得和体会。
一直认为工程师是非常务实,非常努力的一帮人,是一群深深相信“我们可以用代码来改变世界”的人,是一群认为“Talk is cheap,Show me the code”、“日拱一卒,功不唐捐”的人。我一直认为“开放、协作、务实”是当代工程师最好的特性之一。
在开源世界里学习、工作、分享,是工程师改变世界最好的途径之一。
|








- 上一条: Rust 开发者看过来!CNCF LFX Mentorship 远程带薪实习机会来啦 2022-05-13
- 下一条: Hyperledger Fabric 核心概念 2022-05-16
- 公司新来了一个质量工程师,说团队要保证 0 error,0 warning 2021-08-26
- 后端工程师的「跨域」之旅 2022-01-04
- 工程师什么时机最合适选择跳槽? 2021-09-30
- 我,机器学习工程师,决定跑路了 2022-04-15
- 运维工程师必备利器|一招实现运维智能化! 2022-01-07


