“炫技”还是“真硬核”,OpenPPL 实测阿里「倚天 710」芯片
本文将以深度学习模型推理应用为出发点,对「倚天 710」这款 ARM Server 芯片进行性能方面的实测。
OpenPPL 自开源以来,便密切关注着业界的进展,致力于优化模型推理的全链条。完善对国产化芯片的支持,是 OpenPPL 团队的一个重点方向。
2021 年,阿里平头哥团队推出了全球首个 5nm 制程的 ARM Server 芯片 ——「倚天 710」。该芯片是基于 ARM 最新的 Neoverse N2 核心,自研的面向云数据中心服务器的高性能 CPU 芯片。
相比于市面上现有的 ARM Server 芯片,「倚天 710」在指令集、工艺、核心数、频率等多个指标上有着较为明显的优势:
| 鲲鹏 920 | Amazon Graviton2 | Altra | 倚天 710 | |
|---|---|---|---|---|
| 上市时间 | 2019 Q1 | 2019 Q4 | 2020 Q1 | 2021 Q4 |
| 指令集 ISA | ARMv8.2 | ARMv8.2 | ARMv8.2 | ARMv9 |
| 工艺 | 7nm | 7nm | 7nm | 5nm |
| 核心数 | 64 | 64 | 80 | 128 |
| 频率 | 最高 2.6GHz | 2.5GHz | 2.8GHz | 最高 3.2GHz |
| 接口 | PCIe 4.0 | PCIe 4.0 | PCIe 4.0 | PCIe 5.0 |
| 存储 | DDR4 | DDR4 | DDR4 | DDR5 |
前段时间,阿里云推出了基于该芯片的全新 ECS g8m 系列实例。OpenPPL 团队第一时间申请到了试用实例,对大家期待已久的「倚天 710」进行了性能实测。
此次评测将以「Amazon Graviton2」作为对比芯片,评测的内容包括:
- 基础信息测试
- 指令集支持情况
- 核心算力测试
- 访存系统测试
- 软件性能实测
- 通用矩阵乘实测性能
- 深度学习模型实测性能
基础信息测试
指令集支持情况
自 ARMv8 以来,ARM 推出了多种高性能计算指令扩展,其中对机器学习领域最有帮助的有:
- fp16: IEEE 754 标准 16-bit 浮点数指令集扩展
- bf16: bfloat16 浮点数指令集扩展
- i8mm: int8/uint8 矩阵指令集扩展
- sve/sve2: 可变长向量指令集扩展
- sme: 可变长矩阵指令集扩展
下表是「倚天 710」与「鲲鹏 920」「Amazon Graviton2」对这些指令集扩展支持情况的对比。可以看到,相比于竞品,「倚天 710」额外支持了多个高性能指令扩展:
| 指令集扩展 | 鲲鹏 920 | Amazon Graviton2 | 倚天 710 |
|---|---|---|---|
| fp16 | ✓ | ✓ | ✓ |
| bf16 | ✓ | ||
| i8mm | ✓ | ||
| sve | ✓ | ||
| sve2 | ✓ | ||
| sme |
值得强调的是,bf16/i8mm 中的矩阵乘指令(bfmmla、smmla、ummla、usmmla)在「倚天 710」上得到了支持。 这些指令能够单条指令直接算出矩阵乘的结果,峰值算力较传统的向量指令有明显的提升:
| 指令集 | 指令 | 类型 | 乘加数 (单指令) |
|---|---|---|---|
| ARMv8 base | fp32 fmla | 向量 | 4 |
| + fp16 | fp16 fmla | 向量 | 8 |
| + bf16 | bfmmla | 矩阵 | 16 |
| + i8mm | smmla/ummla/usmmla | 矩阵 | 32 |
高性能微架构能够将这些矩阵指令的 IPC,保持在跟向量指令一样的水平上。因此,将向量指令更换成矩阵指令将大大提升计算的速度。这也是「倚天 710」选用最新 ARM Neoverse N2 内核所取得的后发优势。
CPU 核心算力峰值
这里我们对「倚天 710」和「Amazon Graviton2」的算力峰值进行了对比测试。
测试时,「Amazon Graviton2」的频率是 2.5GHz。「倚天 710」虽然最高频率可达 3.2GHz,但阿里云提供的试用实例频率被限制到了 2.75GHz。
本文的所有数据都是在 2.75GHz 这个频率上测出的,没有真正挖掘出这款芯片的全部潜力。也非常期待阿里云后续正式发布的 ECS 能够提供解除频率限制的选项。
下表是我们实测的单核峰值性能:
| 数据精度 | 指令 | 「Amazon Graviton2」单核峰值算力 (2.5GHz) | 「倚天 710」单核峰值算力 (2.75GHz) |
|---|---|---|---|
| fp32 | fmla | 39.95 GOPS | 43.88 GOPS |
| fp16 | fmla | 79.90 GOPS | 87.75 GOPS |
| bf16 | bfmmla | 不支持 | 175.51 GOPS |
| int8/uint8 | smmla/ummla/usmmla | 不支持 | 351.02 GOPS |
由于「倚天 710」频率相比「Amazon Graviton2」提升了 10%,其 fp16/fp32 fmla 指令的算力比后者高 10%,这个结果符合预期。
但凭借着对新矩阵乘指令的支持,「倚天 710」的单核浮点算力最高可达 175.51 GOPS (BF16),单核定点算力最高可达 351.02 GOPS (INT8/UINT8)。这相对于「Amazon Graviton2」是一个巨大的提升。
另外值得强调的是,上述数据仅为单核心的算力。考虑到「倚天 710」的单颗芯片核心数是「Amazon Graviton2」的两倍(128 vs 64),因此芯片整体算力方面,倚天 710 要远高于 AWS Graviton2:
| 数据精度 | 指令 | 「Amazon Graviton2」单芯片估计算力 (2.5GHz x 64 cores) | 「倚天 710」单芯片估计算力 (2.75GHz x 128 cores) |
|---|---|---|---|
| fp32 | fmla | 2.56 TOPS | 5.62 TOPS |
| fp16 | fmla | 5.11 TOPS | 11.23 TOPS |
| bf16 | bfmmla | 不支持 | 22.47 TOPS |
| int8/uint8 | smmla/ummla/usmmla | 不支持 | 44.93 TOPS |
(上述数据为单核 x 核心数估算出来,非实测数据)
当然,考虑到阿里云尚未对该系列 ECS 定价,我们没法对两者单位成本算力进行一个准确的比较。期待阿里云尽快推出正式版的「倚天 710」实例。
我们在测峰值的同时,也对这些指令的延迟做了一下测试:
| 数据精度 | 指令 | 「Amazon Graviton2」指令延迟 | 「倚天 710」指令延迟 |
|---|---|---|---|
| fp32 | fmla | 2 cycle | 2 cycle |
| fp16 | fmla | 2 cycle | 2 cycle |
| bf16 | bfmmla | 不支持 | 3 cycle |
| int8/uint8 | smmla/ummla/usmmla | 不支持 | 1 cycle |
(上述延迟均为 Dst to Dst 延迟)
可以看到,fp16/fp32 fmla 指令延迟两者一致。 bfmmla 指令在算力大幅提升的情况下,延迟仅仅上升了 1 个 cycle。 而整型 mmla 指令的延迟仅有 1 cycle,非常利于优化。
访存系统
「倚天 710」同「Amazon Graviton2」一样,有 64KB 的 L1 ICache、64KB 的 L1 DCache、1MB 的 L2 Cache,这些 Cache 都是每个核心独享的。下表是我们实测的读延迟与带宽:
| 访存层级 | 数据范围 | 「Amazon Graviton2」load 延迟 (cycle) | 「倚天 710」load 延迟 (cycle) |
|---|---|---|---|
| L1 DCache | 0 ~ 64KB | 4 | 4 |
| L2 Cache | 64KB ~ 1MB | 12 ~ 17 | 12 ~ 14 |
| 访存层级 | 数据范围 | 「Amazon Graviton2」带宽 (GB/s) | 「倚天 710」load 带宽 (GB/s) |
|---|---|---|---|
| L1 DCache | 0 ~ 64KB | 73 | 90 ~ 100 |
| L2 Cache | 64KB ~ 1MB | 33 ~ 44 | 50 ~ 54 |
可以看到,「倚天 710」的 L1 DCache 读带宽、L2 Cache 读延迟与带宽均明显优于「Amazon Graviton2」,这对于各类程序的性能会很有帮助。
另外,「倚天 710」的 unified L3 Cache 高达 128 MB,远高于「Amazon Graviton2」的 32 MB。这将大大提升倚天 710 在多核心协作下的性能。
但鉴于阿里云提供的试用 ECS 只有 4 个核心,因此本文并没有对 L3 Cache 及以下的访存系统进行测试。
软件性能实测
通用矩阵乘性能实测
我们首先用通用矩阵乘 (GEMM) 来看下「倚天 710」在实际程序上的性能表现。
测试时,在「倚天 710」和「Amazon Graviton2」上使用相同的二进制文件,所用 ECS 操作系统也都保持相同 (Ubuntu 20.04)。
测试矩阵尺寸为 M x N x K = 1024 x 1152 x 1024,测试计算精度为 fp32、fp16、bf16 (输入输出格式为 fp16)。测试单核性能。
测试结果如下:
| 计算精度 | 「Amazon Graviton2」速度 | 「Amazon Graviton2」算力利用率 | 「倚天 710」速度 | 「倚天 710」算力利用率 |
|---|---|---|---|---|
| fp32 | 36.64GOPS | 91.59% | 41.75GOPS | 94.90% |
| fp16 | 74.39GOPS | 92.99% | 83.56GOPS | 94.96% |
| bf16 | 不支持 | 不支持 | 165.11GOPS | 93.81% |
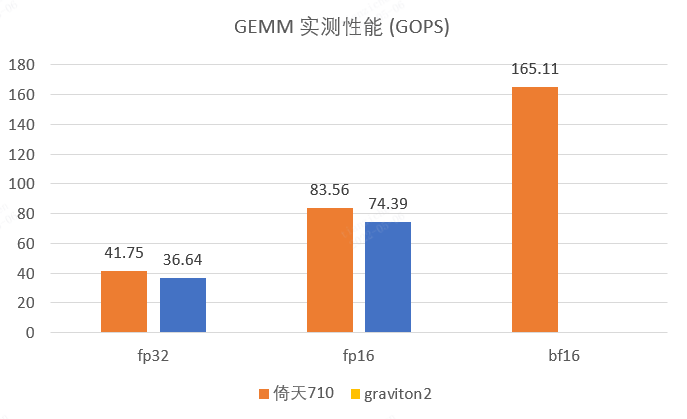
可以看到对于 GEMM 任务来说,「倚天 710」在相同计算精度上所能达到的实际计算速度要明显高于「Amazon Graviton2」。 而当使用了 bf16 矩阵乘指令后,「倚天 710」的 GEMM 实际计算速度超过了「Amazon Graviton2」fp16 的两倍。 如果进一步使用 i8mm 指令,算力差距将更加明显。当然随之而来的量化精度问题,需要在实际应用中进行调整与斟酌。

另外,「倚天 710」相对于「Amazon Graviton2」的性能提升不仅是因为主频高。同样的程序,在「倚天 710」上算力利用率会高 2 ~ 3 个百分点。简单优化的 GEMM 程序算力利用率就能达到 94 ~ 95% 左右,这使得「倚天 710」能够更好的发挥其硬件的性能。
深度学习模型性能实测
最后,我们用一些经典的开源网络,来测试一下「倚天 710」在深度学习模型推理任务上的实际表现(测试时,推理框架使用我们自己的 OpenPPL)。
OpenPPL 已于今年 1 月份支持了 ARM Server 架构,能够支持大部分 OpenMMLab、PyTorch Model Zoo 网络,并针对 ARM Server 架构的特点进行了针对性的优化。
测试时,我们保持「倚天 710」和「Amazon Graviton2」两者所使用的软件代码与模型文件相同,分别在两款芯片上进行了单核的性能测试,结果如下:
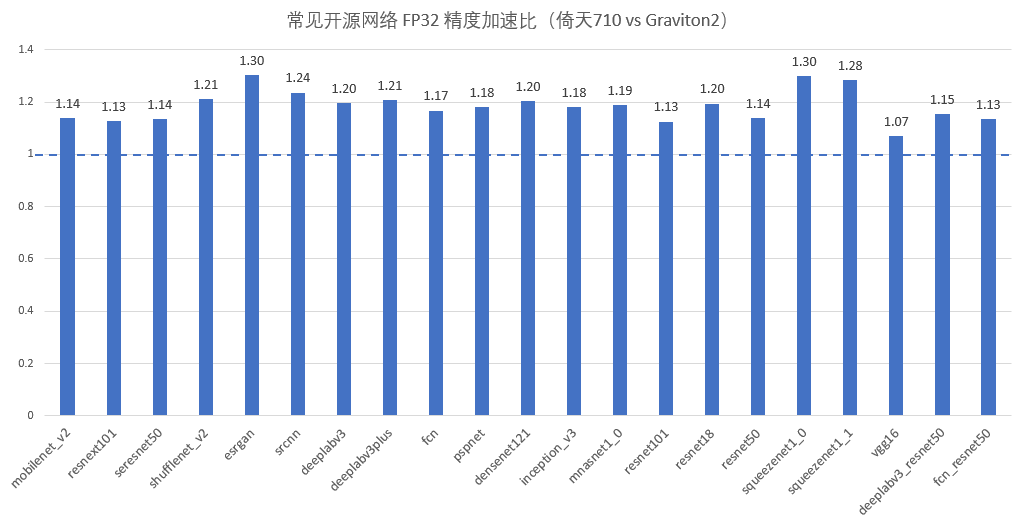
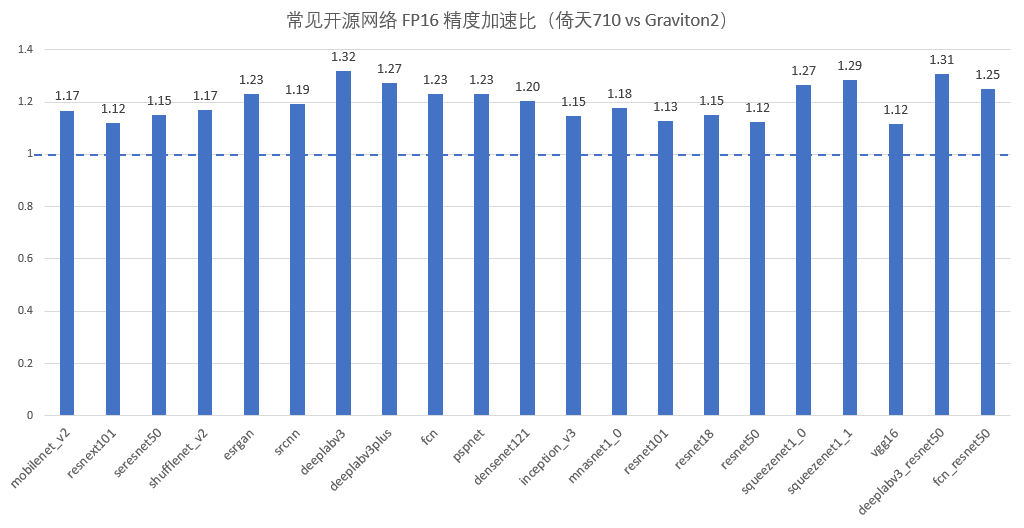
可以看到,无论是 FP16 还是 FP32 精度的推理,「倚天 710」在大部分模型上都能比「Amazon Graviton2」快 10% ~ 30%。
相同计算精度下,这个提升幅度要高于上文的 GEMM。倚天 710 在更复杂的计算任务上,能够跟「Amazon Graviton2」拉开更明显的差距。
这些提升一部分来自于芯片本身主频的提升 (10%),另外一部分来自于访存系统容量、延迟与带宽的改善,以及微架构方面的改进 (分支预测、指令发射等)。这些改进实打实的加快了神经网络推理的速度。相信对于其他计算任务,「倚天 710」同样能取得不俗的成绩。
总结
通过测试我们可以看到,「倚天 710」相对于目前市面上的 ARM Server 芯片而言,在多个方面有着较为明显的优势:
- 更高的主频、更高的核心数
- 更新更全的指令集支持
- 更高的峰值浮点、定点算力
- 更好的访存系统性能
这些优势将使得「倚天 710」在实际计算任务上取得不俗的性能表现。
经我们实测,在通用矩阵乘和深度学习模型推理这两个计算任务上,「倚天 710」相比于「Amazon Graviton2」均能取得明显的性能提升。
这对于国产芯片而言是一个非常难能可贵的成绩。
后记
在与参与国产芯片研发的朋友们交流中,我们能深深感受到国产芯片自研的不易:除开或自研或采购的计算核心外,芯片时序功耗面积的收敛、硬件单元测试与功能测试、片上互联网络配置与调试、加工与封装,以及软件工具链的开发与优化,这些工作都需要投入大量的人力与时间,解决无数个问题才能不断完善。
因此「倚天 710」芯片是十分值得称赞的。
当然,我们仅仅对一小部分指标进行了测试,后续我们会对更多细节进行更深入的探索,也期待阿里云能够尽快开放正式版 ECS 实例,吸引更多用户使用,从不同应用、不同角度对这款芯片进行评价,足够的反馈可以帮助芯片厂商明确改进目标,给国产化芯片提供更多的支持。
我们也注意到,「倚天 710」支持了最新的 PCIe 5.0,在带宽、功耗等多个方面均优于 PCIe 4.0,能够更好地适配 GPU、NPU、FPGA 等各类异构加速外设。我们期望看到,国产自研 CPU,搭配上国产自研的加速外设,跑上 OpenPPL 这样的全自研高性能推理引擎,国产商用高性能计算体系将日趋完善,为各类人工智能的应用提供更大价值。
OpenPPL 团队一直跟进着国产芯片的最新进展。
- 在 x86 后端上,已经完成对 SSE 指令的支持,并在近期内重点支持 VNNI 指令集,使最新的 x86 处理器增加定点量化能力;
- ARM Server 也是 OpenPPL 支持的一个特色后端,除了支持更多的网络模型和算子,今年也将重点支持 Int 8 数据精度推理和 ARM v9 特性;
- 我们目前已支持 RISC-V 后端,后续将兼容 RVV 0.7.1 和 RVV 1.0 标准版本,并添加可变长 VLEN 的支持。
OpenPPL 的目标是在各类 CPU、GPU、NPU 架构上都能提供高效便捷的深度学习模型推理部署的支持。我们期待有更多的同学能够试用和反馈意见,让 OpenPPL 在性能、平台支持和易用性等多个方面不断进步。
|








- 上一条: 【大规模训练】大规模训练的技术挑战 2022-05-10
- 下一条: 根因分析思路方法总结|保障IT系统及其稳定性 2022-05-10
- 聊一聊物联网嵌入式芯片的内容结构 2021-10-11
- 芯片设计“花招”已耍完?无指令集架构颠覆旧套路 2022-04-01
- 云原生爱好者周刊:M1 芯片 Mac 可以成功运行 Linux 2022-03-22
- OpenPPL 中的卷积优化技巧 2022-02-24
- 阿里巴巴如何提升构建的效率 | 阿里巴巴DevOps实践指南 2022-01-25


