新作!分布式系统韧性架构压舱石OpenChaos
摘要:本文首先以现今分布式系统的复杂性和稳定性的需求引出混沌工程概念,并阐述了OpenChaos在传统混沌工程上的优化与创新。
背景
随着Serverless,微服务(含服务网格)与越来越多的容器化架构应用的出现,我们构建、交付与运维系统的方式变的越发复杂。这种复杂性增加了系统状态可观测性的难度。在已有的生产环境中,我们有不同的方式来获取信息,增强系统的可观测性。起始的时候,可能是非常简单的给定一个特定的条件,产生一个特定的指标输出。进一步的,使用结构化和关联日志,或进行分布式跟踪,引入事件总线如Apache EventMesh、EventGrid等。随着Codeless组合式应用快速发展,Serverless设计理念也在不断被一些分布式系统设计者逐步接受。免运维,按需付费,极致弹性,多租共池等等无不在逼迫我们重新审视老式架构的合理性,催生新架构的不断演进。融合架构是这几年被提的最多的一个词,以往支撑在线/离线系统的复杂架构不断被融合,通过可分可合的设计与部署方式去适配各种业务场景。在这样的背景下,我们开始认真审视并思考,是否有一种更为现代化的工具,能够帮助发现并应对分布式云这种底座对架构设计以及上层应用带来的诸如可靠,安全,弹性等一系列韧性架构的挑战。
混沌工程思想给我们带来了一定程度的启发。Netflix最初为了搬迁基础设施上云创建了 Chaos Monkey,由此拉开了混沌工程学的序幕。再到后来,CNCF成立了专门的兴趣小组,希望能够推动这一领域的标准诞生。OpenChaos创始团队早期也和这些社区的先行者进行过多轮交流。可惜的是,2019年随着该兴趣组并入App Delivery SIG后再无太大动静。这几年国家政策大力引导下,企业的数字化升级不断加快,越来越多的CIO、CTO甚至包括CEO开始重视并投入到混沌工程实践中。国内由中国信通院牵头的混沌工程实验室也在如火如荼地推动该领域的飞速发展,从全链路压测,混沌故障引入到催生未来架构变革的多云多活参考架构的制定。这些无不昭示着这一产业在飞速发展。根据国内外科技媒体调研统计,到2025年,80%的组织将实施混沌工程实践。通过全链路压测,混沌故障,以及多云多活架构等策略的整体导入,可以将意外停机时间减少50%,实现真正意义上的秒级RTO/RPO。让应用、业务创新更加专注。
良药虽好,但也有局限
混沌工程的最基本流程是在生产环境小规模定期自动化执行试验,为系统随机的注入故障,来观察 “系统边界”。它主要关注系统面对故障所展现出的容错能力,可靠性。目前市面上绝大部分混沌工程工具,倾向于构造以黑盒随机为主的故障类型,对底层基础设施(硬件,操作系统,数据库与中间件)理解与洞察较少。缺少统一的框架标准、成熟的specific度量指标。同时,分析反馈较弱,无法给出全面彻底的诊断建议,尤其通过强化学习,生成式AI等能力可以进一步解决目前随机故障注入,进行自愈风险分析与优化建议。
面向有更多复杂特性的分布式系统,仅通过观察系统应对故障的表现是有局限的,并且依赖于观察是极其主观的,很难形成统一的评测标准,也较难针对表现分析系统缺陷。系统的可观测性,不仅需要模型的全面覆盖,还需要完备的监测系统,并提供全面的结果报告,甚至智能预测,来指导架构提升自身的韧性能力。分布式领域资深技术专家,开源顶级项目Apache RocketMQ,OpenMessaging最初的创始人冯嘉曾表示“云原生分布式架构的演进正在朝着组装式架构,韧性架构进一步发展”。在这样的背景下,他提出并带领团队创造了OpenChaos这一新兴项目。
OpenChaos 需要解决的本质问题
韧性架构,覆盖高靠性、安全、弹性、不可变基础设施等特性。实现真正的韧性架构毫无疑问是现代分布式系统的演进方向。针对分布式系统韧性能力,OpenChaos借助混沌工程思想,对其定义进行延伸扩展。针对一些分布式系统特有属性,如Pub/Sub系统的投递语义与推送效率,调度编排系统的精准调度、弹性伸缩与冷启效率,streaming系统的流批实时性、反压效率,检索系统的查全率与查准率,分布式系统共识组件的一致性等,设置专用的检测模型。OpenChaos 内置可扩展的模型支持,以便验证在大规模数据请求以及各种故障冲击下的韧性表现,并为架构演进提供进一步优化建议。
架构与案例分析
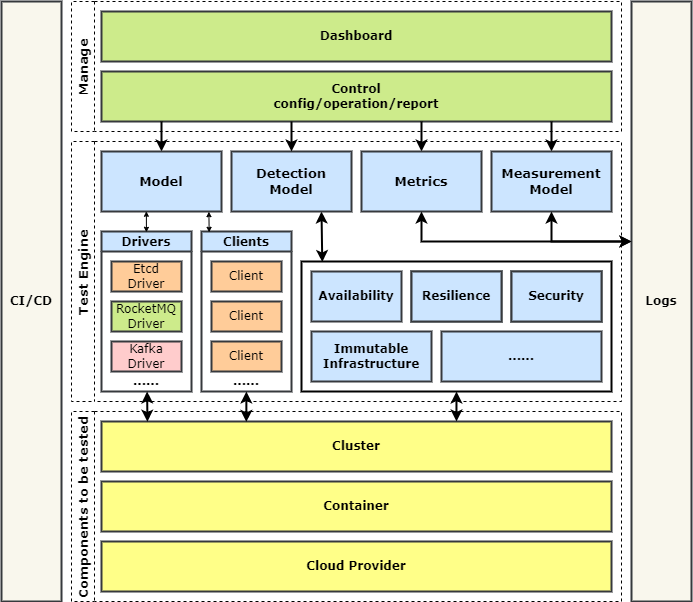
图1
整体架构
OpenChaos的工作原理是这样的:控制面对整个流程进行控制,负责使集群节点组成一个待测试的分布式集群。并会根据需要测试的分布式基础设施找到对应的Driver组件并载入,根据设置的并发数建立相应个数的客户端。控制节点根据 Model 组件定义的执行流程控制客户端对集群进行操作。演练过程中,Detection Model 会对集群节点根据不同的观测特性引入对应的事件。Metrics 模块会在实验中监测被测集群的表现。演练结束后,Checker组件会对实验中的业务和非业务数据进行自动化分析,得出测试结果并输出可视化图表。
如图1所示,OpenChaos的整体架构可以分为管理层,执行层与被测组件层。
最上层为管理层,它包含了用户界面和控制器(Control),控制器负责调度引擎层的组件进行工作。最下层为被测组件,它可以是自部署的分布式系统集群,也可以是容器或者云厂商承载的分布式系统。
中间层是执行层,也是OpenChaos强大能力的秘密所在。模型(Model)是执行的流程的基本单元,它定义了对分布式系统进行操作的基本形式。控制器在模型中载入需要测试的分布式系统的驱动(Driver),并根据配置的并发数创建相应的客户端(Client),最终使用客户端对分布式系统执行操作。检测模型(Detection Model)会根据用户关注的不同观测特性引入对应的事件,比如引入故障或者系统的扩缩容。Metrics 模块会在实验中监测被测集群的表现。演练结束后,度量模型(Measurement Model)组件会对实验中的业务和非业务数据进行自动化分析,得出测试结果并输出可视化图表。
检测模型与度量模型
检测模型
传统混沌工程主要关注系统的稳定性,它们的普遍实现是通过黑盒的故障注入来模拟一些常见的通用故障。OpenChaos中的检测模型关注更高维度的属性——韧性,它包含可靠性,还包含如弹性、安全性等特性的检测模型。相较于传统混沌工程,OpenChaos不仅支持普遍的黑盒故障注入,还可恶意针对分布式基础软件如消息或缓存等的主备倒换,网络分区导致的脑裂等问题做定制检测,以观察他们在这种情况下的表现。
度量模型
由于分布式系统的复杂性,对于分布式系统韧性的观测更需要一个简单直观的分析报告,来让人更方便地发现分布式系统可能存在的缺陷和不足。度量模型会对系统的表现进行分析,以统一的标准化计算输出结果与图表,方便使用者进行对比分析。以消息系统的稳定性评估为例,度量模型会根据实验中故障注入情况与系统表现,计算出系统的 RPO(Recovery Point Objective)和 RTO(Recovery Time Objective)。输出集群的处理语义情况,如是否符合 at least once 或 exactly once;故障恢复情况,故障期间是否出现系统不可用,及不可用的恢复时间;故障下是否满足预期的分区顺序性;系统在整个实验过程中的响应时间等。
可靠性案例分析
我们使用OpenChaos对ETCD集群进行可靠性测试,发现在主节点网络断开,单独成为一个分区的场景下,ETCD客户端视角下,集群缺乏自动恢复能力。
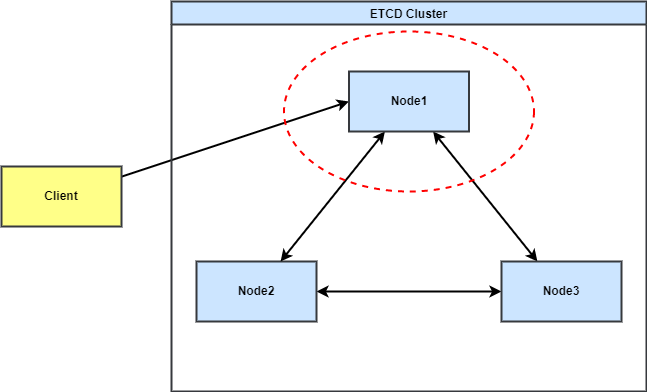
图2
下面是利用 OpenChaos执行的一个实验结果示例,是一个3节点 ETCD 集群在主节点与从节点网络断开,单独成为一个分区时的表现,模拟的业务流量速率为1000 tps。
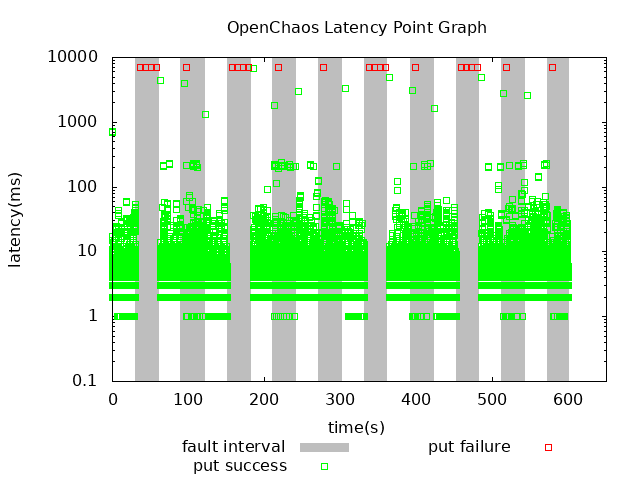
图3
从图中可以看出实验持续10分钟,共注入十次主节点网络分区故障,间隔为30秒,故障期间集群表现不一致。下图为更详细的实验结果。
在第1/3/6/8次故障期间,集群无法自行恢复;其他故障期间花费7秒会恢复集群为可用状态,但整个实验中没有出现数据丢失。
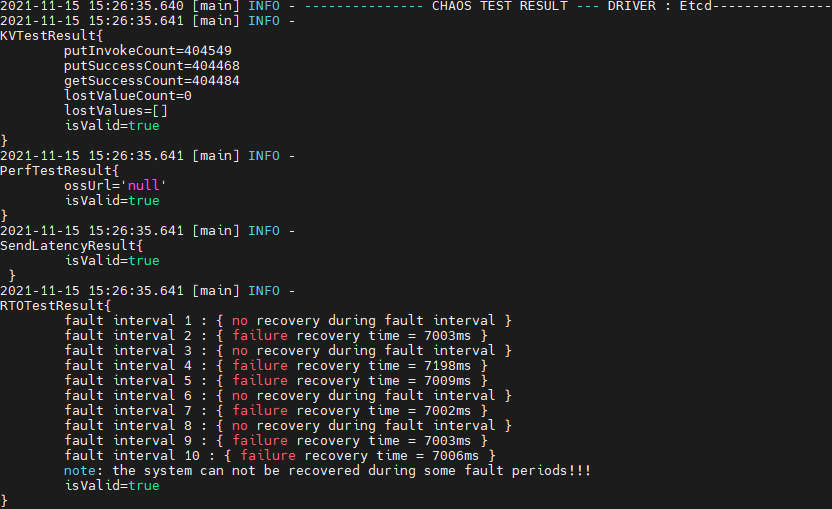
图4
通过查看实验过程信息,发现每次主节点被分区时,集群均可在故障期间自行转移主节点。通过分析源码 ,ETCD 客户端在面对ETCD内部错误时,不会进行重试连接其他节点。导致在客户端优先连接的节点为主节点,并发生不可用时,即便主节点已经成功转移,整体集群恢复为可用,业务仍处于未恢复状态。该问题我们也已经report给ETCD社区,等待进一步修复。
弹性案例分析
弹性也是分布式系统需要重点关注的能力,除可靠性外,OpenChaos支持对系统扩缩容能力的度量与评测。与可靠性不同,分布式系统的弹性能力不能通过编排固定频率的事件以触发检测。OpenChaos可以根据用户设置的操作系统指标或业务指标阈值来触发扩缩容。
例如,你可以指定集群CPU平均占用的预期值为 40%,或系统响应的预期时间为100ms。弹性检测模型会根据指定的预期值与当前系统表现,根据OpenChaos内置的算法来计算出要弹到的目标规模,来触发扩缩容动作。实验结束后,度量模型会计算出集群的“加速比效率”,与“扩缩代价”和对应规模下集群的性能。
注:“加速比效率”和“扩缩代价”为OpenChaos中度量分布式系统弹性能力的指标,前者表示分布式系统并行化的性能和效果,后者表示系统伸缩的速率。
弹性的含义不仅包括实例节点的伸缩能力,同样也包含具体业务(应用)单元的伸缩能力。为了探索Kafka分区的最佳使用实践,我们设计了实验以探索单个topic分区的扩容能力。在实验中我们还会统计在不同分区个数下消息收发的吞吐量,以了解分区数量对消息吞吐量的影响和达到最大吞吐量的最优分区数数量。
图5为三节点集群上的一个 topic 的分区从 1 扩到 9000 时的 tps 和延迟情况。
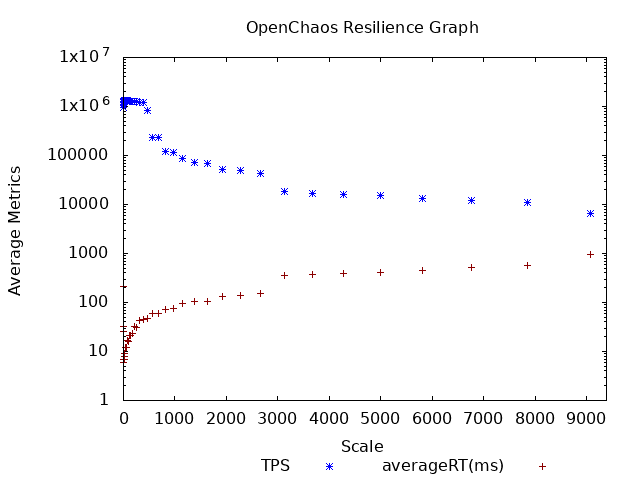
图5
图6为各指标随着实验时间的变化情况。

图6
图7是具体的弹性评测结果部分截图,展示了在不同规模下,系统表现出的性能以及弹性变更的花销与效率。其中changeCost 和 resilienceEfficienty 为上文描述的扩缩代价与加速比效率结果。
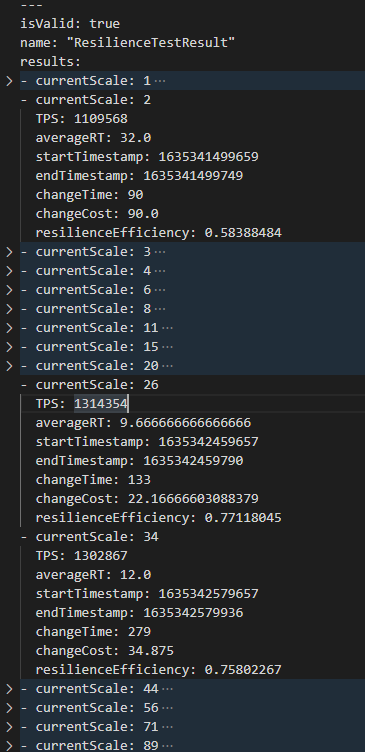
图7
从上述结果能够看出,此实验规格下的 Kafka 集群,新增1个分区的平均时间约20ms。在分区数量达到 26 的时候性能达到最优,该情况下吞吐量达到130万,此时CPU 总体利用率达到 93%。在分区数达到450+时,性能明显下降。当分区数达到 1992 时,吞吐量降到 3.8万,CPU总体利用率达到 97%。
未来规划
目前 OpenChaos已支持接入大多数分布式系统,如Apache Kafka、Apache RocketMQ、DLedger、 Redis、ETCD等。随着开源之夏2022活动[1]的召开,我们开放了更多分布式系统接入的工作,供广大学生选择与参与。
与此同时,华为云与混沌工程实验室紧密合作,助力中国信通院发布了国内首个《分布式消息队列稳定性评估标准》,是该项标准的主要贡献者。另外,华为云中间件消息产品家族是唯一一个全面通过验收标准的应用服务。
面向未来,OpenChaos将推出更多通用的韧性标准和智能预测功能,以期不仅能评测出架构已有的能力,还能够基于系统的观测做出预测,避免出现超出系统本身韧性能力的异常发生。百尺竿头更进一步,我们会持续打磨该项目,通过生态合作方式集成更多分布式系统,努力将OpenChaos打造成分布式系统韧性架构的压舱石,从而推动云原生架构不断演进,关键时候方能“任凭风浪起,稳坐钓鱼船”。
[1] 开源之夏2022活动:https://summer-ospp.ac.cn/#/org/prodetail/221bf0008
|








- 上一条: 用一个性能提升了666倍的小案例说明在TiDB中正确使用索引的重要性 2022-05-10
- 下一条: 如何使用Tomcat实现WebSocket即时通讯服务服务端 2022-05-10
- 每一个程序员,都渴望成为一名分布式系统架构师 2021-07-11
- OpenHarmony HarmonyOS-面向全场景的分布式操作系统 2021-06-27
- 分布式事务的十大神坑 2021-07-18
- 灵活运用分布式锁解决数据重复插入问题 2021-07-27
- 怎么提高自己的系统架构水平 2021-07-21


