多场景下时序序列分类算法基础知识全面总结
云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
前言
本期我们有幸邀请到中国矿业大学(北京)博士、云智慧智能研究院算法工程师徐同学,从时序序列分类的概念、研究意义、基本框架及算法总结四个方面带来对时间序列分类算法的总结概述,下面就让我们一起来学习吧~
一、什么是时间序列分类
-
分类任务
分类任务是一个机器学习领域的任务,目的是让算法通过学习为未知样本分配标签。典型案例是将一封邮件分类为垃圾邮件和非垃圾邮件。
分类任务又可细分为以下四类:
-
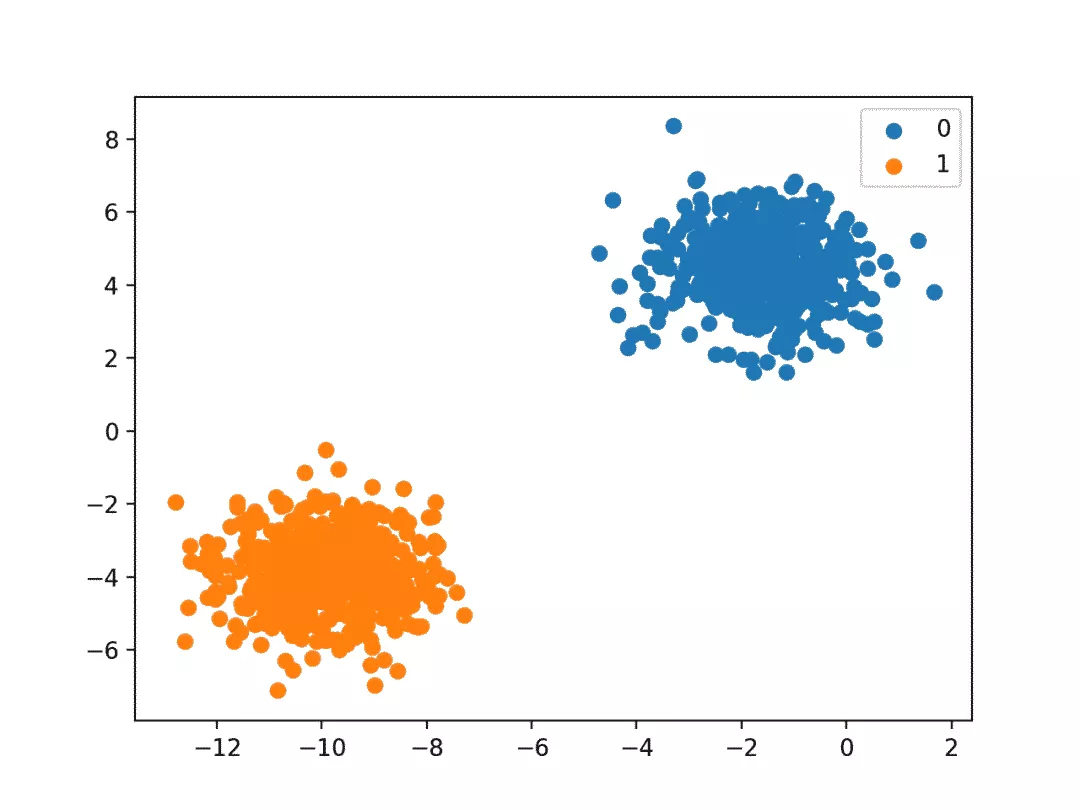
二分类问题:将样本分为两类,如图1所示;
-
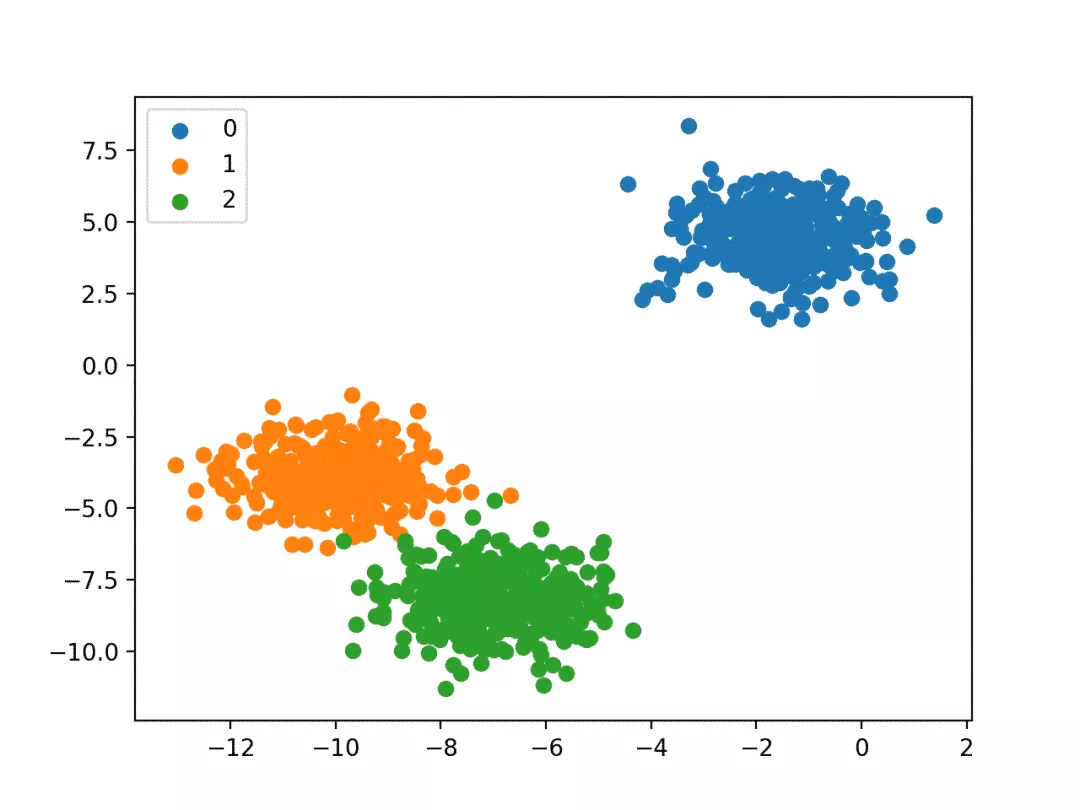
多分类问题:将样本分为多类,如图2所示;
-
多标签分类:同一样本被赋予多个标签;
-
不平衡分类:正负样本数量比例悬殊。
-
时间序列分类
时间序列分类是一项在多个领域均得到应用的通用任务,目的是利用标记好的训练数据,确定一个时间序列属于预先定义的哪一个类别。时间序列分类不同于常规分类,因为时序数据是具有顺序属性的序列。如下图所示的心电图信号样本,它表示一个心跳活动。根据信号特征的不同可以加以区分,左边表示正常心跳,而右边表示心肌梗死。

时间序列分类任务需要对样本进行学习,进而进行分类,因此这个任务有监督学习的作用。该任务可细分为两类:单指标时间序列分类和多指标时间序列分类。本文的算法阐述聚焦在单指标时间序列分类问题。
二、为什么要研究时间序列分类
时间序列分类可以在以下场景发挥作用:
- 预测算法与数据的匹配,辅助算法选型,提升预测准确性;
- 异常检测算法与数据匹配,辅助选型,提升检测准确性,减少计算量;
- 预测算法的预处理,例如检测数据周期性并剔除,以进行正常历史数据的学习;
- 异常检测算法的预处理,例如银行跑批任务需将周期数据剔除,再进行异常检测;
- 时间序列数据分析,不同类型数据占比、不同类型数据重要程度。
三、时间序列分类问题基本框架
-
基本框架
时间序列分类问题可以粗略划分为两个主要步骤:特征提取和分类器分类,如下图所示。

特征提取指从原始时间序列数据中提取能够较好表示原序列的特征。分类器将提取的特征作为输入,输出原序列的类别标签。
-
KNN分类器
KNN(k-nearest neighbors)分类器是一类基础分类器,其中最常用的是1-NN分类器。KNN分类器分为训练和分类两个阶段。在训练阶段,只需把训练样本以及样本标签存储起来;在分类阶段,首先设定近邻样本数量常数K,然后计算与待分类样本最接近的K个训练样本,最后采用多数表决的方式判定类别,即出现最多类别作为待分类样本类别。
例如第一章节心电图的例子,有若干心电图信号序列,根据每个序列是否正常,分别赋予0和1的标签。然后,用1-NN算法进行训练,即存储所有样本序列;当新样本到来,需要计算新样本与所有训练样本的距离,比如欧式距离,找出距离最近的样本对应的类别,即为新样本的类别。
-
算法评价与UCR数据集
算法效果的好坏需要一个客观的评价机制,这就离不开开源数据集。开源数据集为算法的公平比较以及沟通交流提供了平台,为算法研究领域的快速发展打下了基础。在时间序列分类领域,UCR(全称)开源数据集扮演了这样一个角色。
如上图所示,UCR是一个时间序列分类领域的数据仓库,包含多种不同类型的数据集,按照不同的应用领域和具体业务类型划分,例如上文的心电图数据集。

在评价一个算法时,需要在所有数据集上测试算法效果,最终按照评价机制给出综合评分,如上图所示。上图展示了14种算法的评价结果,对应评分越靠近1代表算法综合评分越高,被黑色横线覆盖的算法代表效果无显著差异。
四、时间序列分类算法总结与典型算法介绍
-
时间序列分类算法归类
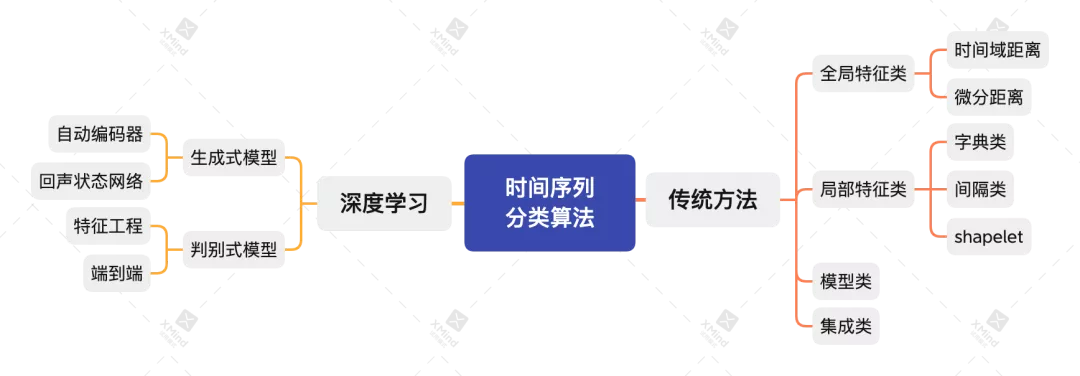
主讲人通过阅读大量时间序列分类文献,将时间序列分类算法总结为两个大类,11个小类,如下图所示。这里将时间序列分类算法分为传统方法和深度学习方法两大类,传统方法包括全局特征类、局部特征类、模型类和集成类,深度学习方法又分为生成式模型和判别式模型。
-
典型算法介绍
-
全局特征
全局特征分类算法将完整时间序列作为特征,计算时间序列间的相似性来进行分类,通常采用距离度量函数与1-NN相结合的方式。该类方法的研究方向为用于度量完整时间序列相似性的距离度量函数。
- 典型全局特征算法-dtw
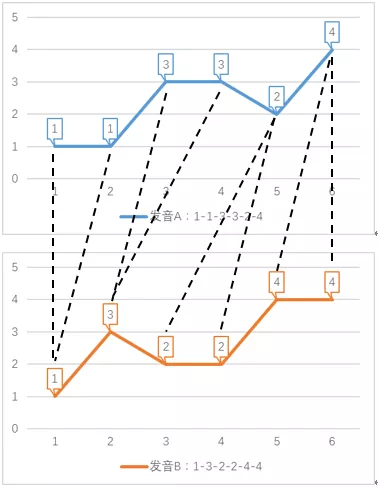
如果我们允许序列的点与另一序列的多个连续的点相对应(相当于把这个点所代表的音调发音时间延长),然后再计算对应点之间的距离之和,这就是dtw算法。dtw算法允许序列某个时刻的点与另一序列多个连续时刻的点相对应,称为时间规整(Time Warping),如下图所示。
- 典型全局特征算法-差分距离法
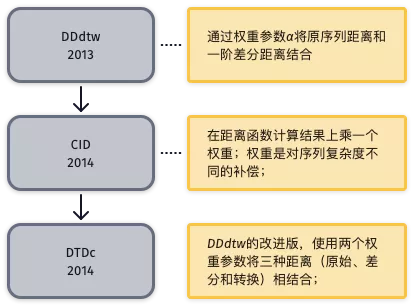
差分距离法计算原始时间序列的一阶微分,然后度量两个时间序列的微分序列的距离,即微分距离。差分法将微分距离作为原始序列距离的补充,是最终距离计算函数的重要组成部分。
差分距离法将位于时间域的原时间序列和位于差分域的一阶差分序列相结合,提升分类效果。研究方向主要是如何将原序列和差分序列合理结合,差分距离法的演进过程下图9所示。
-
局部特征
局部特征类分类算法,将时间序列中的一部分子序列作为特征用于时间序列分类。该类算法的关键在于寻找能够区分类别的局部特征。由于子序列更短,因此构建的分类器速度更快,但需要一定的时间来寻找局部特征。
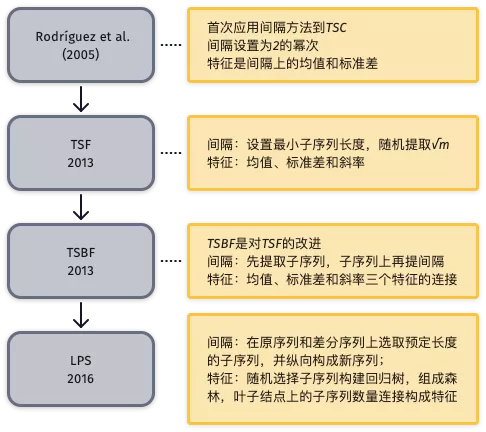
- 典型局部特征算法-间隔(interval)
局部特征类中的间隔法将时间序列划分为几个间隔区间(interval),从每个区间中提取特征。该类方法适用于长序列中带有相位依赖并具有区分度的子序列,以及噪声。基于间隔的时间序列分类算法发展历程下图所示。
- 典型局部特征算法-shapelet
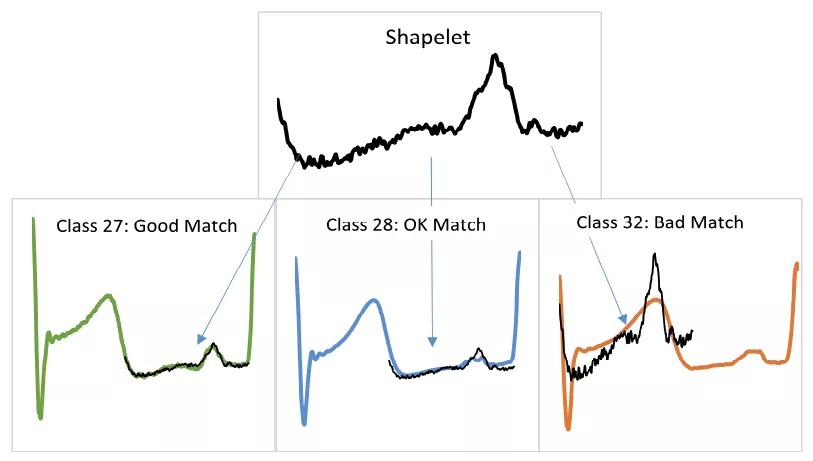
shapelet分类算法通过在序列中查找最具辨别性的子序列用于分类,其中shapelet指一个与位置无关的最佳匹配子序列。该类算法适用于可以通过序列中的一种模式定义一个类,但是与模式的位置无关的分类问题。例如前面的心电图异常案例,异常可能发生在任何位置,通过序列的异常点序列段可以进行分类。
shapelet算法的特点是可解释性强,如下图所示,通过Class27、Class28、Class32三条序列的匹配结果,可以清楚地了解匹配结果的原因。
- 典型局部特征算法-字典类
shapelet分类算法由于需要花费大量时间搜索子序列,因此更适用于短序列。对于长序列中一种模式反复出现的时间序列,更适用于一种叫做dict字典类的分类算法。该类算法以序列中子序列的重复频率作为特征进行分类。首先对序列进行降维和符号化表示,形成单词序列,然后根据单词序列中的单词分布情况进行分类。字典类分类算法的演进过程如下图所示。

开源福利
云智慧已开源数据可视化编排平台 FlyFish 。通过配置数据模型为用户提供上百种可视化图形组件,零编码即可实现符合自己业务需求的炫酷可视化大屏。 同时,飞鱼也提供了灵活的拓展能力,支持组件开发、自定义函数与全局事件等配置, 面向复杂需求场景能够保证高效开发与交付。
点击下方地址链接,欢迎大家给 FlyFish 点赞送 Star。参与组件开发,更有万元现金等你来拿。
GitHub 地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee 地址:https://gitee.com/CloudWise/fly-fish
万元现金福利: http://bbs.aiops.cloudwise.com/t/Activity
微信扫描识别下方二维码,备注【飞鱼】加入AIOps社区飞鱼开发者交流群,与 FlyFish 项目 PMC 面对面交流~

|








- 上一条: 游戏版号恢复发放后,还有一个好消息…… 2022-05-09
- 下一条: 系列开篇|云原生时代下微服务架构进阶之路 2022-05-09
- AIOps场景下,指标预测算法基础知识全面总结 2022-05-16
- 0基础都能看懂的算法图解 2021-07-19
- 第1章 计算机系统的基础知识 ·1.4 运算基础 2021-07-07
- 值得关注的HTML基础知识 2021-08-20
- 面试官:您能说说序列化和反序列化吗?是怎么实现的?什么场景下需要它? 2021-09-27


