智能运维(AIOps)实践|日志语义异常检测全面解读
云智慧 AIOps 社区是由云智慧发起,针对运维业务场景,提供算法、算力、数据集整体的服务体系及智能运维业务场景的解决方案交流社区。该社区致力于传播 AIOps 技术,旨在与各行业客户、用户、研究者和开发者们共同解决智能运维行业技术难题,推动 AIOps 技术在企业中落地,建设健康共赢的AIOps 开发者生态。
云智慧智能研究院着眼于运维人员在日志分析方面所面临的问题与实际需求,以日志语义异常检测为切入点,进行了相关的分析与实验。对在智能运维中如何进行日志分析,给出了基于日志语义异常检测的答案。
一、背景
日志在IT运维中扮演着重要角色。日志记录了软件系统运行时的详细信息,蕴含着丰富的系统信息。 系统开发人员与运维人员可以根据日志监控系统剖析系统的异常行为与错误。因此,如何进行日志的异常检测也成为智能运维领域亟待解决的问题,日志异常检测可以分为语义异常(执行结果)、执行异常(执行日志序列)与性能异常(执行 时间 ) 。本文针对日志语义异常检测进行了分析与实验。
二、问题与挑战
-
日志异常类型
日志记录着系统在某个 时间 点执行了某些操作以及相应操作的结果。 因此,当某些错误发生导致系统异常时,日志中也会有相应异常记录。日志中记录的异常信息可以帮助系统开发人员与运维人员监控系统,并剖析系统的异常和错误,从而快速定位异常、修复异常,以维护系统的稳定性。因此,如何自动判断错误日志中包含的异常类型成为亟待解决的问题。
实际上,虽然IT系统/服务出现异常的场景众多、情况复杂,但是仍然可以对异常类型进行大致分类,如网络异常、数据库异常、硬件异常、I/O异常、操作系统异常等。 每一个类型又可以进行细分,以硬件异常为例,可能存在CPU异常、磁盘空间不足、磁盘损坏等硬件上的异常。因此,自动判断日志异常类型的前提在于,制定统一的日志异常类型说明标准、各类别中的细分类与特征,并标注一批标准的数据集进行学习。
-
日志与自然语言文本的区别
与其他NLP任务类似,基于语义异常的日志分析方法需要首先对日志进行向量化表示。但是日志与自然语言文本有所不同:
- 日志为半结构化文本,日志通常包括日志头与日志描述信息,日志头中经常包含时间戳、来源、日志等级等字段;而日志描述信息中则包含对当前操作与对应结果的描述,包含丰富的语义信息;
- 日志中存在大量重复,在日志描述信息中包含常量信息与变量值,往往将变量值作为参数符号化后,大量日志可以压缩为一个日志模板;
- 日志中包含大量驼峰格式的连写字符串,这与不同编程语言的函数、类等命名格式有关,如android系统日志中,常见SendBroadcastPermission、DisplayPowerController、KeyguardViewMediator等字符串形式。
- 越成熟的系统,其日志格式与描述越统一,因此成熟的系统/中间件的日志数据中包含的词汇量较小。
-
日志的向量化
基于日志文本的特殊性,对于日志的向量化表示需要考虑以下问题:
- 日志向量化之前需要提取日志描述字段,对日志描述字段进行初始化;
- 日志中的变量值通常为无意义的数值或者不同的ip、url、path等,若将原始参数值进行向量化,则会导致词汇量巨大且影响后续计算,因此需要首先进行命名实体识别,对变量值进行识别与替换;
- 日志特殊的写法需要制定新的规则对日志进行分词,而不能仅采用通常的英文符号分词方式;
- 日志重复量越大且越成熟的系统,其日志格式与描述越统一会导致日志有效词汇量少,后续应用中会出现OOV问题,因此需要结合日志数据与通用数据进行向量化训练。
三、基于语义异常的日志分析
本文提出了一种基于语义异常的日志分析方法,如下图所示:
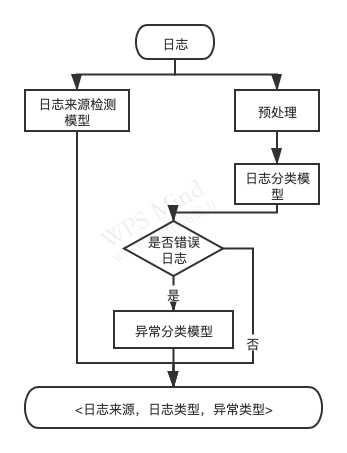
-
数据预处理
数据预处理旨在将原始日志数据处理为算法要求的标准输入数据,整体流程包括:命名实体识别、分词、过滤、大小写转换、向量化等。其中,命名实体识别需要对timestamp,url,ip,file,path,number,email等日志中经常出现的实体进行识别;分词需要考虑日志中常见的驼峰表达式;在日志向量化过程中,利用通用语料(wikidata)+系统/中间件日志语料+业务日志语料训练词向量,最终,词向量维度为200维,词库大小为583511。
-
日志来源检测
如前文所说,越成熟的系统/中间件/服务,其日志格式与描述越统一。因此,可针对不同来源的日志进行分析,总结其日志格式,并提取正则表达式,为每一个来源的日志构建日志格式,根据日志格式检测日志来源。 我们从logpai的loghub以及本公司业务系统中获取到包括linux、mac、android、apache、arangodb、clickhouse、hadoop、ignite、kafka、nacos、ntpd、openstack、proxifier、redis、spark、ssh、tengine、zookeeper等18个系统/中间件在内的日志,并提取日志格式,如下:

基于规则的日志来源检测方法,针对不同来源组件的日志进行测试,每个组件日志各选择10000条日志进行测试,准确率达99.94% 。因此,针对成熟的系统/中间组件,构建规则进行来源检测可以达到极高的准确率。
-
日志分类模型
通常可以利用日志中包含的日志等级字段,如debug,info,warning,error等,对日志进行分类,但是实际中这种日志分类方式通常会存在两个问题:
- 有些系统/业务日志中并不包含日志等级字段,如linux、mac、ntpd、proxifier、redis等,无法用日志等级字段进行分类;
- 有些系统/业务日志中,日志等级字段标注不准确, 或者将异常情况发生时的相关状态或情况标注为“error”等,实际上这类日志语义上并不包含错误信息。
- 因此,我们首先对错误日志与异常日志进行区分:
- 异常日志:发生异常时打印的日志,可能仅为异常发生时的某个状态或情况说明,本身并不包含错误信息;
- 错误日志:语义中包含错误信息的日志。
本文中,将日志分为正常日志与错误日志,即根据日志的语义信息将日志进行分类。首先构造数据集:采集系统/中间件日志、业务日志,提取日志模式并进行去重,采用人工标注的方式标注数据集,抽取正常日志8926条,错误日志4051条进行实验。利用传统机器学习中的二分类算法如 svm ,集成学习算法随机森林,深度学习的 bert 分别进行实验,结果如下:

-
异常分类模型
<!---->
- 异常类型分类
首先,对日志中包含的异常类型进行分析与总结,我们将日志中包含的异常类型分为:文件/文件夹操作异常、网络异常、数据库异常、硬件异常、系统异常和其他异常6类。每一类中分别包含多个细分类异常,如文件/文件夹操作异常中包含文件或目录不存在、文件或目录无访问权限、读/写文件失败、其他IO异常等。具体异常类型及ID如下所示。

- 实验数据集
在数据采集过程中发现,上述异常类型及中异常的细分类数据集存在类别不平衡且某些细分类中没有数据的情况,因此采用粗分类进行异常类型分类实验,将日志异常类型分为6类:文件/文件夹操作异常、网络异常、数据库异常、硬件异常、系统异常、其他异常。各分类数据量如下:

后续实验中发现,由于4:硬件异常数据量少会导致实验结果较差;而硬件异常可以认为是系统异常的一种,因此将4,5进行合并,最终数据集如下:

- 算法及实验结果分析
利用随机森林进行多分类实验,实验结果如下:

单个类别结果如下:

四、总结
在本文中,我们提出了一种基于语义异常的日志分析方法,并结合日志来源形成了输入一条原始日志,输出为<日志来源,日志类型,异常类型>的算法流程,以此提取出日志中蕴含的丰富的语义异常信息,从而为系统开发人员与运维人员监控系统剖析异常行为和错误提供了有力支撑。
五、开源福利
云智慧已开源数据可视化编排平台 FlyFish 。通过配置数据模型为用户提供上百种可视化图形组件,零编码即可实现符合自己业务需求的炫酷可视化大屏。 同时,飞鱼也提供了灵活的拓展能力,支持组件开发、自定义函数与全局事件等配置, 面向复杂需求场景能够保证高效开发与交付。
点击下方地址链接,欢迎大家给 FlyFish 点赞送 Star。参与组件开发,更有万元现金等你来拿~
GitHub 地址: https://github.com/CloudWise-OpenSource/FlyFish
Gitee 地址: https://gitee.com/CloudWise/fly-fish
万元现金活动: http://bbs.aiops.cloudwise.com/t/Activity
微信扫描识别下方二维码,备注【飞鱼】加入AIOps社区飞鱼开发者交流群,与 FlyFish 项目 PMC 面对面交流~

|








- 上一条: JuiceFS 在数据湖存储架构上的探索 2022-05-05
- 下一条: 使用 Nocalhost 与 KubeVela 端云联调,一键完成多集群混合云环境部署 2022-05-05
- 仅有 0.1M 可训参数,AIOps 日志异常检测新范式 2022-06-07
- 智能运维 VS 传统运维|AIOps服务管理解决方案全面梳理 2022-05-06
- 如何在智能运维中进行指标异常检测与分类? 2022-04-11
- 深度学习下运维日志分析的趋势解读与应用实践 2022-03-18
- AIOps(智能运维)中的指标算法场景分享 | 内附视频&ppt资料 2022-04-02


