【深度学习编译器】ANSOR 技术分享

文 @ 不愿透露姓名的小 P 同学
前言
大家好,本次分享的主题是业界知名的 AI 编译框架 TVM 的一个子模块——ANSOR。ANSOR 可以对 AI 模型做自动优化,解决代码生成中的自动调度问题。
近几年,AI 算法和硬件领域都了获得巨大的发展,深度学习网络中的新算子和用于运行深度学习网络的新硬件层出不穷。在传统的深度学习框架中,如果需要支持一个新算子,首先需要将算子对接到硬件厂商提供的计算库,如果计算库不支持这个算子,则需要通过手写算子来实现算子支持,而对于不同的硬件设备,往往需要分别手写对应硬件设备的算子来完成支持,这就会导致深度学习框架的算子支持工作量巨大。
另一方面,以算子为粒度的深度学习框架也不利于深度学习网络的优化,一个典型的例子是算子融合。在深度学习框架中,算子融合优化需要提供融合算子的模板(如[CONV, BN, RELU]),然后根据模板将匹配到的算子替换为一个手写的融合算子。然而,算子的融合策略往往是不可数的,所以,这种方式不但实现起来复杂,而且很难遍历到所有的优化空间。
TVM 作为深度学习编译器,首先将深度学习网络转换为其内部的 IR,这个 IR 可以对深度学习网络中的算子进行概括;接着通过 TVM 提供的指令生成模块,可以将 IR 转化为硬件可运行的指令或代码。实现一个新算子仅需将该算子转化为其提供的 IR 即可,与 IR 相关的优化和指令生成均不需要做任何的改动。
TVM 也提供了调度原语,大多数常见的优化方式,如线程绑定、算子融合、读写数据缓存、计算分窗等,都可以通过调度原语实现。这极大地提升了深度学习网络优化的效率以及优化空间。
虽然通过 TVM 可以简化优化难度,降低多设备支持的成本,扩大优化空间,但同时也存在一个“最后一公里”问题:我们往往希望编译过程可以自动、无干预的进行,这就需要 TVM 可以对深度学习网络进行自动优化——无需手动指定优化方式,就可以自动地将调度原语应用到给定的深度学习网络中,生成高性能的代码。本文将要展开介绍的 ANSOR 提供了一种解决上述问题的方法。
本次分享我们将从以下三个方面展开介绍:
- ANSOR 产生的背景
- ANSOR Pipeline
- 总结
背景
近几年来,基于深度学习的 AI 技术取得了巨大的进步,越来越多的 AI 应用已经或者正在落地,如人脸识别、语义分割、语音识别等。这些 AI 应用往往有一个共性,就是 AI 模型的精度总是和模型的规模成正比。因此,如果想要获得更精准的图像识别,就需要加大模型的深度,但是这会导致运行时间的增加。
在实际应用场景中,算力和带宽通常是给定的,在这种情况下,为了缩短模型的运行时间,就需要提高模型的运行效率。TVM 将表示和优化分离,分别抽象成 Tensor Expression 和 Schedule,从而极大地提高了模型调优的效率。如果对 Schedule 相关的内容感兴趣,可以参考 TVM Schedule 详细举例。
虽然将表示和优化分离可以显著提高模型的调优效率,但是 Schedule 要么需要手写,要么依赖于 模板,这对于包含复杂计算的深度学习网络来说是很困难的。以深度学习模型中常见的计算图 MatMul + Add + Relu 为例,TVM 的代码生成需要以下三个步骤:

- TVM 以一个计算图作为输入,将其转换成其领域特定语言 Tensor Expression,如上图中间黄色的部分;
- 编程人员需要采用手动或者半手动的方式指定 Schedule,如上图中间灰色的部分;
- 然后再通过 TVM 的代码生成 Pipeline 进行代码生成,得到一系列嵌套的 for 循环,如上图右部所示。
但是通过手写或采用模板的优化方式可能会陷入局部最优。同时,要写出好的优化策略,编程人员需要对硬件有较好的理解,这个过程也是十分枯燥的,并且需要耗费大量不必要的时间开销。
为了解决上述问题,TVM 在其 Pipeline 中加入了 ANSOR,如下图所示:

这样编程人员仅需提供模型,ANSOR 就会自动选择出一套调度策略,再通过 TVM 的代码生成,用户就可以得到优化后的代码。
ANSOR Pipeline
这里对 ANSOR 的 pipeline 展开详细介绍。
ANSOR Pipeline 如下图所示:
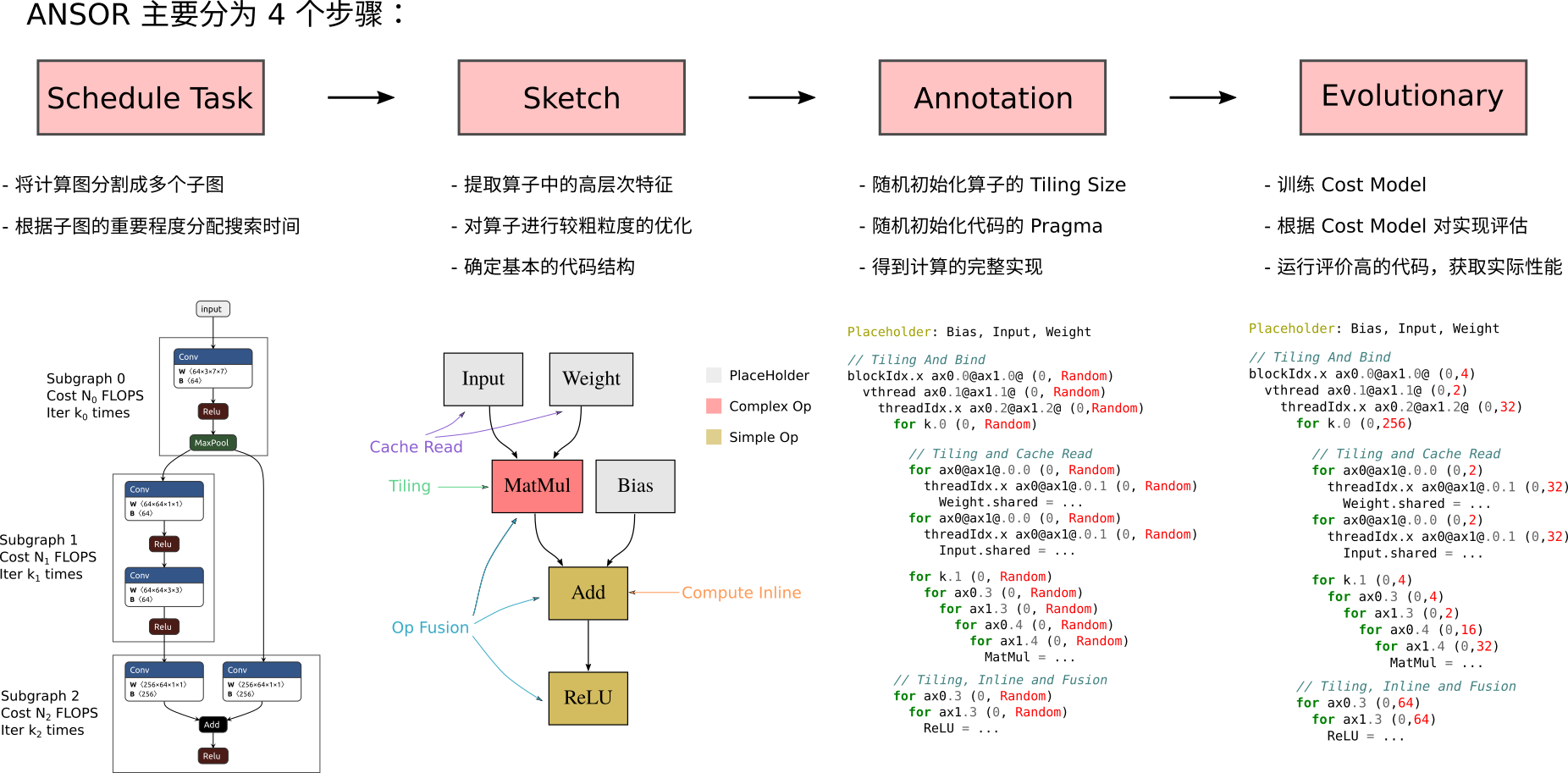
ANSOR 的 Pipeline 可以分为如下几个步骤:
- Schedule Task: 将完整的计算图划分成多个子图,对热点的子图进行重点优化;
- Sketch: 提取算子中的高层次特征,对算子进行较粗粒度的优化,确定代码的基本结构;
- Annotation: 随机初始化 Tilling Size 和一些 for 循环的策略,获得计算图的完整表示;
- Evolutionary: 训练 Cost Model,根据 Cost Model 对代码的性能进行评估,选取评估中取得高分数的一组实现,再通过运行时模块,获取 ground truth 和实际性能,选取实际性能最优的实现作为 ANSOR 的输出。
其中 Schedule Task 用来对深度学习网络进行子图划分,确定各个子图的优化次数, Sketch 用来搭建代码的整体框架,Annotation 填充细节,Evaluation 训练一个模型来对生成的代码进行评价和更新,获得最后的代码生成结果。
下面分别对这几个部分进行介绍:
Schedule Task
ANSOR 首先会将计算图切分成多个子图并对这些子图分别进行优化。深度学习网络的总优化次数由 ANSOR 的使用者给定,然后由 Schedule Task 模块来确定如何将这些优化次数分配到不同的子图优化任务上。
为了保证对热点代码的重点优化,ANSOR 会尽量选择优化效果明显的子图进行优化。比如最小化一个 DNN 网络的时延,我们首先给出优化的目标函数:
\( \arg\min f = \sum_{i=1}^{n} w_i \times g_i(\mathbf{t}) \)
其中:
\(n\) 为子图的个数, \(w_i\) 为子图 \(i\) 在 DNN 中出现的次数; \(\mathbf{t} = [t_1, t_2, \dots, t_i, \dots, t_n]\) 为每个子图的优化次数构成的向量,即 \(t_i\) 表示第 \(i\) 个子图的优化次数; \(g_i(\mathbf{t})\) 为给定优化次数构成的向量下,第 \(i\) 个子图的运行时延, \(w_i\) 为子图 \(i\) 在 DNN 中出现的次数。
ANSOR 采用梯度下降的方法获得 \(\mathbf{t}\) 。根据链导法则, \(f\) 相对于 \(t_i\) 的梯度可以用如下公式表示:
\( \frac{{\partial}{f}}{{\partial}{t_i}} \approx \frac{\partial f}{\partial g_i} \frac{\partial g_i}{\partial t_i} \approx \frac{\partial f}{\partial g_i}(\alpha (\frac{g_i(t_i) - g_i(t_i - \Delta t)}{\Delta t}) + (1 - \alpha) \frac{g_i(t_i + \Delta t) - g_i(t_i)}{\Delta t}) \)
\(g_i(t_i-\Delta t)\) 可以通过历史记录获得, \(g_i(t_i + \Delta t)\) 可以通过加入如下两个参考进行预测:
假设再经过 \(t_i\) 的时间, \(g_i\) 可以优化至 0。 子图 \(i\) 可以达到与其相似的子图持平的性能。
带入上述两个参考即可以得到如下的公式,
\( \frac{\partial f}{\partial t_i} \approx \frac{\partial f}{\partial g_i}(\alpha (\frac{g_i(t_i) - g_i(t_i - \Delta t)}{\Delta t}) + (1 - \alpha)(min(-\frac{g_i(t_i)}{t_i}, \beta \frac{C_i}{max_{k\in N(i)}V_k} - g_i(t_i)))) \)
其中, \(g_i(t_i)\) 和 \(g_i(t_i - \Delta t)\) 根据历史记录获得; \(N(i)\) 是相似子图构成的集合; \(C_i\) 是当前子图的浮点运算数量; \(V_k\) 是与 \(i\) 相似的子图 \(k\) 的浮点运算数量; \(\alpha\) 和 \(\beta\) 是预测值的信任度。
实际 ANSOR 运行的过程中,会选择\(\frac{\partial f}{\partial t_i}\) 值最小的(该值为负数)子图作为待优化的子图。
Sketch
Sketch 对每个计算子图进行优化,可以分为以下三个步骤:
- 拓扑排序
- 静态分析
- 调度策略的选择
首先,拓扑排序主要是将 TE 描述的计算图转化成计算队列,获得算子的执行顺序,如下面所示:

ANSOR 采用深度优先搜索的方式将计算图转化为计算队列,方便后续的静态分析和调度策略的选择。
接着,静态分析用来提取算子的特征,这一步非常关键,也是 ANSOR 的一个创新点。ANSOR 不会重点对某一个算子类型做处理,而是提取算子的特征。
一个典型的特征就是这个算子是否对输入数据做了复用。例如 Vector Add 算子,其 Tensor Expression 的表达和伪代码如下所示:

它输出的 axis 和输入的 axis 相同,均为 i,因此没有数据的复用。
而 Matmul 算子,其 Tensor Expression 的表达和伪代码如下所示:

输入 A 和输入 B 产生输出 C,C 的 axis 为 i, j;A 的 axis 为 i, k;B 的axis 为 k, j。说明在计算 C[i, *] 的过程中,A[i, k] 被重复使用了 Range(j) = 1024 次,B[k, j] 也被重复使用了 Range(i) = 1024 次。如果我们在实际代码生成的过程中,将 A 和 B 的一部分数据进行缓存,可以显著降低带宽,从而减少运行时间。
ANSOR 根据静态分析提取了如下算子特征:
| 特征 | 说明 |
|---|---|
| IsStrictInlinable | 输入和输出的维度是否是一一对应的,且语句中不含有 if-then-else 等特殊的表达式 |
| HasDataReuse | 在计算输出数据时,输入的数据是否被重复使用 |
| HasFusibleConsumer | 后面的算子是否可以和该算子融合 |
| HasMoreReductionParallel | 该算子主要为 reduce 操作,这种情况是否需要用 rfactor 调度原语 |
在静态分析获取算子特征后,下一步为派生策略的选择,从后向前遍历拓扑排序生成的计算队列,根据算子的特征为算子选择调度策略。
ANSOR 提供了如下调度策略:

根据静态分析的结果可以派生调度策略,可以简单地用如下几个派生条件表达:
- 如果是数据复用算子,其输入需要做计算分窗和输入的 Cache Read (Multi-level Tilling,Add Cache Stage)。
- 如果算子的输出需要多次累加获得,则需要做 Cache Write (Add Cache Stage)。
- 非数据复用算子可以进行 compute inline 操作 (Always Inline)。
- 非数据复用算子可以 compute at 到数据复用算子 (Multi level with Fusion)。
- 对于 Reduce 算子,可以采用 rfactor 进行优化 (Reduction Factorization)。
我们可以用一个表格来描述派生规则和 Schedule 的关系,表格的第一列为派生规则的名字,表格的第二列为派生规则触发的条件,表格第三列是派生规则所调用的 Schedule 策略:
| 派生规则 | 触发条件 | Schedule 策略 |
|---|---|---|
| Skip | \ | \ |
| Always Inline | 无数据复用的简单算子 | compute_inline |
| Multi-level Tiling | 有数据复用的算子 | fuse, split |
| Multi-level Tiling with Fusion | 数据复用算子和简单算子融合 | fuse, split, compute_at |
| Add Cache Stage | 数据复用算子的输入、输出 | cache_read, cache_write |
| Reduction Factorization | 存在 Reduce 操作,且算子的 Spatial axis 迭代次数较少 | rfactor |
同样以一个 Matmul + ReLU + Add 为例,选取后端设备为 GPU,Sketch 的输入为计算子图,输出为应用 Schedule 后产生的代码模板,如下面图所示:

其中 Add 算子和 Relu 算子为 Simple Op,可以对 Add 算子做 compute inline,产生蓝色部分的代码,可以对 Matmul 算子做分窗,产生红色部分代码,可以对 Input 和 Weight 做 cache_read 产生灰色部分代码。
Annotation
Sketch 虽然生成了代码的结构,但是一些细节还没有确定,如:
- GPU thread bind
- for 循环的 unroll、vectorize、parallize
- Split 的 factor
Annotation 会随机确定上述内容,生成完整的代码。Annotation 只负责随机生成代码,并不会考虑性能,性能由 Evolutionary Search 来保证。
Evolutionary Search
待优化的计算有可能十分复杂,遍历所有的 Annotation 来获取最优实现是不现实的。ANSOR 训练了一个 XGBoost Tree 来对代码的性能进行评估,相比直接跑 Runtime 获取 ground truth,训练获得的 XGBoost Tree 可以大致确定代码的好坏,并且花费的时间更少。为了评定 Annotation 生成的代码的性能,ANSOR 对每个算子的实现提取了如下特征来训练模型,这些特征可以通过遍历 TVM 的 tir 来获取:
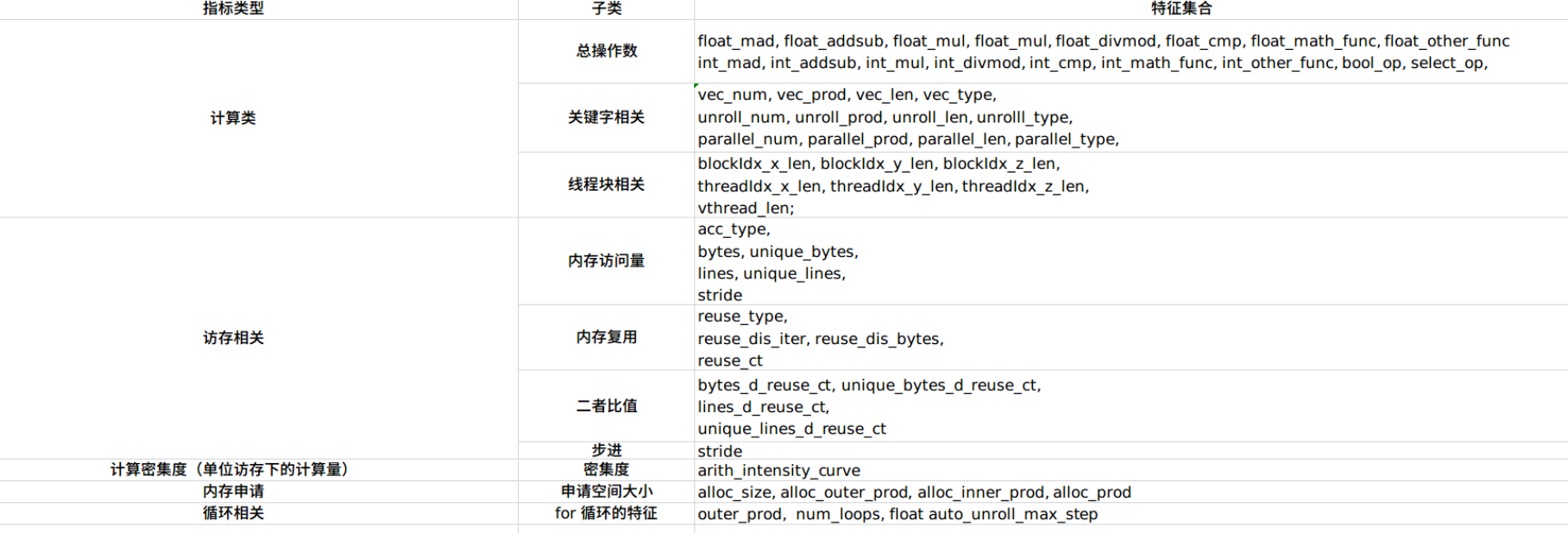
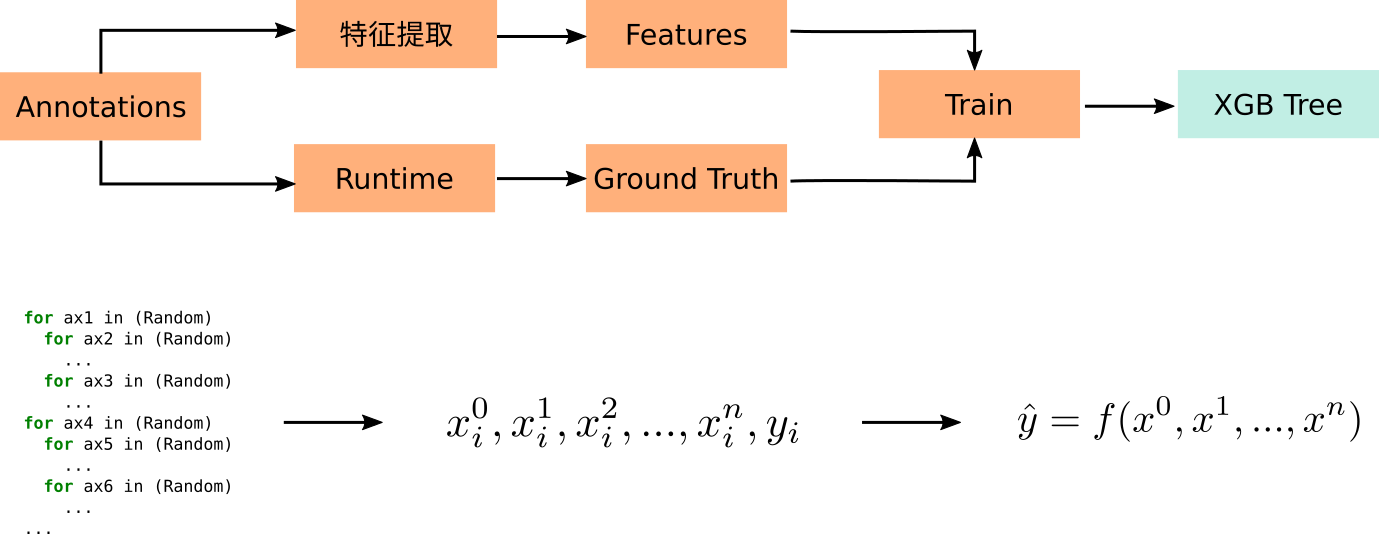
根据 Annotation 获取的样本,提取上述特征,再通过 Runtime 获取样本的 ground truth,就可以训练一棵 XGBoost Tree:
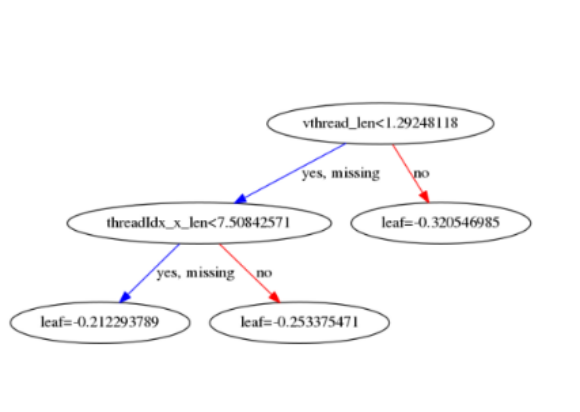
通过 XGBoost 库提供的接口可以对 XGBoost Tree 可视化,一个 Matmul + ReLU + Add 的 Annotation 样本训练出的 XGBoost Tree 如下图所示,对于矩阵乘法来说,XGBoost Tree 的特征向量是比较稀疏的,起决定性的特征主要有 vthread_len、threadIdx_x_len、blockIdx_x_len 等。
ANSOR 应用 Evolutionary Search,使得优化能更快的收敛,减少遍历的时间。整个 Evolutionary Search 的流程如下图所示:
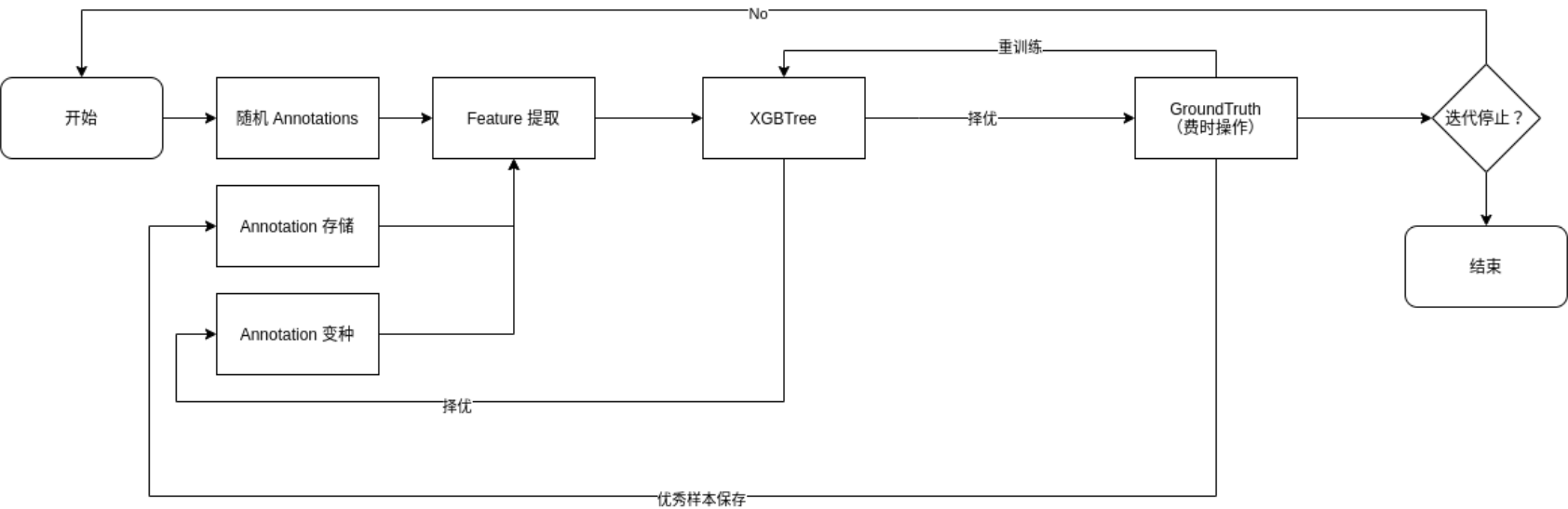
可以看到特征提取的输入有三个来源:
- 随机的 Annotation,保证了样本的丰富性。
- 之前迭代中获取的 Annotation 优秀样本,有助于训练得到更准确的 XGBTree 。
- 优秀样本的变种,根据进化算法,好的样本的 "突变" 往往会更容易获得好的样本,因此可以采用对好的 Annotation 的参数进行微调的方式扩充样本集。
提取的特征会用来训练 XGBoost Tree,XGBoost Tree 又能对 Annotation 样本进行一次初筛选,将评分高的 Annotation 通过 TVM Runtime 获得 Ground Truth。根据 Ground Truth 就可以选择出优秀的代码实现,也就是 ANSOR Pipeline 的输出,算法至此就运行完毕了。
ANSOR 的输出可以无缝的转化成 Schedule,省去了手写 Schedule 的烦恼,直接使用 TVM CodeGen Pipeline 即可进行代码的生成。
总结
TVM 借鉴 Halide 计算和调度分离的思想,引入了领域特定语言,简化了编码,提高了调优的效率。但是 TVM 始终还存在着“最后一公里”的问题,即计算要么需要手写,要么需要借助模板,这样不仅不能实现全自动优化,而且局限了搜索空间,使得优化不彻底。
ANSOR 通过梯度下降算法选择热点子图,对热点子图进行重点优化。通过引入 Sketch,根据算子的特征选择相应的优化策略,省去了手写模板的烦恼,同时也使得算子之间可以融合,扩大了搜索空间。
ANSOR 引入了更新算法,训练 XGBoost Tree 使得迭代收敛得更快。
实验结果显示,应用了 ANSOR,在某些场景下达到甚至超过了 CUDNN、TensorRT 的性能。同时 ANSOR 对体系结构的敏感程度较低,CPU 和 GPU 的 Auto Schedule 基本不需要做太多的修改,这有利于对新的硬件的支持。
在 ANSOR 的第 9 章,Limitations and Future Work 中介绍了 ANSOR 尚未解决的问题,包括:
- 尚不能支持可变形状,Annotation 需要将形状作为输出,否则搜索空间将会无限大导致 AutoSchedule 无法进行。在 Evolutionary Search 阶段也无法获取可参考的 ground truth;
- 尚不能支持 sparse operators;
- ANSOR 主要关注于高层次的优化,低层次的优化交给 LLVM、NVCC 等后端编译器;
- ANSOR 尚不支持特殊指令,如 Intel VNNI、NVIDIA Tensor Core、ARM Dot ……
在实际使用 ANSOR 的过程中,发现其编译时间还是较长的,在我的电脑上运行 ResNet 50 1 x 3 x 224 x 224,需要数小时才能超过 TensorRT 的性能。个人觉得如果 ANSOR 能进一步缩短编译的时间,那么 ANSOR 将会变得更有竞争力。
感谢阅读,欢迎在评论区留言讨论哦~
P.S. 如果喜欢本篇文章,请多多 点赞,让更多的人看见我们 :D
关注 公众号「SenseParrots」,获取人工智能框架前沿业界动态与技术思考。
|








- 上一条: FastDFS 海量小文件存储解决之道 2022-04-27
- 下一条: 游戏出海浪潮下,这些技术难点该如何攻克 2022-04-27
- ☕【Java技术指南】「编译器专题」重塑认识Java编译器的执行过程(常量优化机制)! 2021-08-24
- 写给小白的开源编译器 2022-05-18
- 【深度学习编译】多面体模型编译:以优化简单的两层循环代码为例 2022-05-18
- 技术分享丨集成学习之Bagging思想 2021-08-20
- Java异常处理:如何写出“正确”但被编译器认为有语法错误的程序 2022-02-10


