深度学习框架中的自动微分及高阶导数

撰文 | 大缺弦
1
高阶导数是怎么样的
先看一个 Stackoverflow 上关于如何用 PyTorch 计算高阶导数的最高票回答( https://stackoverflow.com/questions/50322833/higher-order-gradients-in-pytorch ):
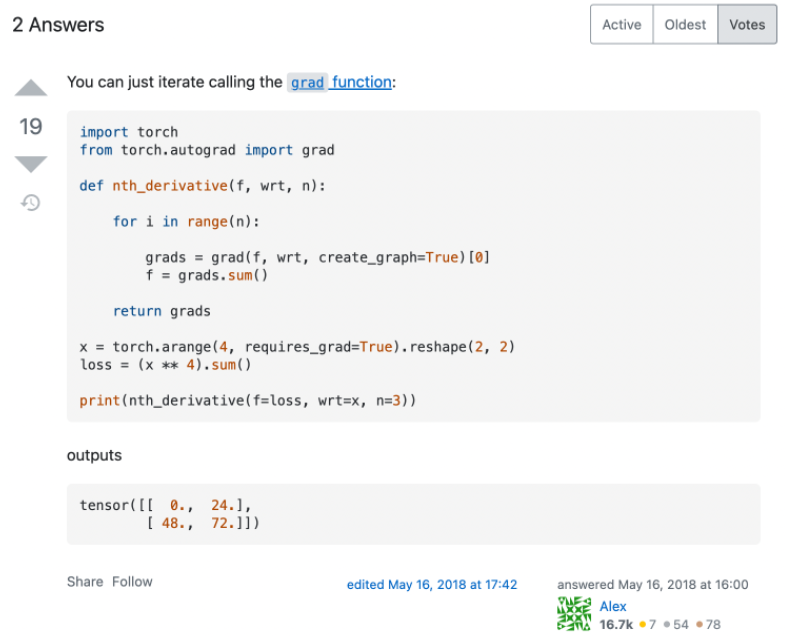
代码很简洁,结果看起来也是对的,然而实际上这个做法是有很大问题的,只是对于作者所测试的这类函数碰巧适用而已。 那高阶导数实际上又该怎么计算呢?
这个问题的标准答案可能是:要看想计算的高阶导数是什么样的。平常的神经网络训练中, 我们想让 loss 下降,也就是将 loss 作为损失函数”, 所以求出一阶导数
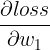 、
、
 ......也就是 w1_grad、w2_grad......,并用它来更新 w1、w2......如果我们现在有一个需求:想通过更新 w1、w2......来让反向传播得到的 w1_grad 尽可能低,也就是将 w1_grad 作为损失函数(在训练一些 GAN 网络时,不希望梯度的绝对值太大,就会有类似的需求),所以要计算
......也就是 w1_grad、w2_grad......,并用它来更新 w1、w2......如果我们现在有一个需求:想通过更新 w1、w2......来让反向传播得到的 w1_grad 尽可能低,也就是将 w1_grad 作为损失函数(在训练一些 GAN 网络时,不希望梯度的绝对值太大,就会有类似的需求),所以要计算
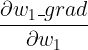 、
、
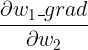 ......也就是二阶导数
......也就是二阶导数
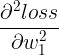 、
、
 ......
这可以用下面的 PyTorch 代码来简单的实现:
......
这可以用下面的 PyTorch 代码来简单的实现:
不过,在大部分场景中想计算的二阶导数是另一种形式:import torchx = ...loss = model(x)w1_grad = torch.autograd.grad(outputs=loss, inputs=model.w1, create_graph=True)w1_grad.backward()

这个矩阵叫做 Hessian 矩阵。它是正儿八经的 “函数 loss = f(W) 的二阶导数”,即将神经网络看作一个输入为所有权重、输出为 loss 的多输入、单输出的函数 f (注意这里的输入不包括训练数据,因为训练数据实际上是固定的,是整个训练集,神经网络的训练就是通过改变 W 使在给定的训练集下的 loss 最低),对该函数 f 求导、再求导得到的结果。 它可以用来判断某个 W 有没有让 loss 处于极小值点、极大值点或鞍点,它也是对 f(W) 做泰勒展开后二次项的系数的两倍,所以当我们想用一个二次函数来模拟神经网络,并根据二次函数的性质来更新 W、优化 loss 的时候(这个叫作牛顿法),也是一个绕不开的概念。在很多场景,例如常用的优化方法共轭梯度法之中,这个矩阵还会和一个向量相乘,被称为 HVP(Hessian-Vector Product)。 那么这个 Hessian 矩阵以及 HVP 该怎么求?一个容易想到的方法是:考虑到在上面那个希望
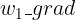 尽可能低的场景里,我们求出的
尽可能低的场景里,我们求出的  、
、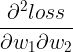 ......是这个矩阵的第一行,那只要对 N 个
......是这个矩阵的第一行,那只要对 N 个 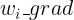 都进行一次同样的过程,就能得到完整的 Hessian 矩阵了。再把这个矩阵乘以一个向量,就得到了 HVP。
这样是可行的,但是并不高效。特别是,如果只需要计算 HVP 而不是 Hessian 矩阵本身,其实是不用先把 Hessian 矩阵算出来,再计算和向量的乘积的,而是只需要进行两次反向传播,或者一次反向传播和一次“前向自动微分”就可以。
具体的做法和原理,需要从反向传播背后的自动微分讲起。
都进行一次同样的过程,就能得到完整的 Hessian 矩阵了。再把这个矩阵乘以一个向量,就得到了 HVP。
这样是可行的,但是并不高效。特别是,如果只需要计算 HVP 而不是 Hessian 矩阵本身,其实是不用先把 Hessian 矩阵算出来,再计算和向量的乘积的,而是只需要进行两次反向传播,或者一次反向传播和一次“前向自动微分”就可以。
具体的做法和原理,需要从反向传播背后的自动微分讲起。
2
自动微分
Reverse Mode(反向自动微分/反向传播)
自动微分分两种,reverse mode 和 forward mode。Reverse mode 就是大家熟悉的反向传播,在 PyTorch 中调用
loss.backward()
就可以执行,不过它的背后有一个大部分小伙伴都不了解的机制。
先来看这个 PyTorch 代码:
import torch
x = torch.ones(2).requires_grad_()
y = x * 2
y.backward()
它会报错RuntimeError: grad can be implicitly created only for scalar outputs,即 y 不是一个标量。
如果我们给y.backward()传入任意一个形状和 y 相同的 tensor 作为gradient参数,如y.backward(gradient=torch.tensor([2, 3])),这份代码就可以正常运行。
这背后的原因是,反向传播只能应用于一个单输出(即输出为标量)的函数。当我们设置# 省略了定义 x 和 y 的代码> y.backward(gradient=torch.tensor([2, 3]))> x.gradtensor([4., 6.])
gradient
为 [2, 3] 时,PyTorch 会将 gradient 和 y 做内积,得到一个标量
t = 2 * y[0] + 3 * y[1]
, 将标量 t 当作函数的输出并运行反向传播,因此 x.grad 的值是
dt/dx
,根据标量对矩阵的导数的定义容易得到dt/dy = [dt/d(y[0]), dt/d(y[1])] = [2, 3],根据链式法则,dt/dx = dt/dy * dy/dx = [2, 3] * 2 = [4, 6],所以 x.grad 的值会是 [4, 6]。
也就是说,对于任意一个 N 输出 M 输入的函数Y = f(X)(Y 是一个长度为 N 的向量),我们可以将 Y 和 v 做内积,得到一个标量 t 和一个单输出、M 输入的函数 g 满足t = g(X) = v * Y = v * f(X)
,再通过反向传播求出函数 g 的梯度。
根据链式法则,函数 g 的梯度dt/dX等于dt/dY * dY/dX,而显然dt/dY就是向量 v,也就是 loss.backward() 函数中的 gradient 参数,dY/dX是函数f的导数(形状为 N*M 的 Jacobian 矩阵)。也就是说,以一个长度为 N 的向量 v 和一个 N 输出 M 输入的函数 f 为对象运行反向传播,可以求出向量 v 和函数 f 的导数的乘积,也就是 Vector-Jacobian Product,简称为 VJP。如果想用反向传播求出整个 Jacobian 矩阵,那么可以将 v 设置为第 i 个元素为 1,其它元素均为 0 的向量,这样就可以求出 Jacobian 矩阵的第 i 行,重复 N 次就可以求出整个矩阵。
Forward Mode(前向自动微分)
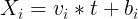 , 也就是设定
, 也就是设定
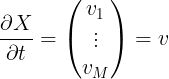 ,
得到一个 N 输出、单输入的函数 g 满足Y = s(t) = f(h(t))。那么当执行某个 op a = u(b)时,就可以同时算出da/dt = da/db * db/dt, 当整个函数Y = f(h(t))执行完成时,每一个输出相对于标量 t 的导数也都被计算出来了。
,
得到一个 N 输出、单输入的函数 g 满足Y = s(t) = f(h(t))。那么当执行某个 op a = u(b)时,就可以同时算出da/dt = da/db * db/dt, 当整个函数Y = f(h(t))执行完成时,每一个输出相对于标量 t 的导数也都被计算出来了。
同样根据链式法则,dY/dt = dY/dX * dX/dt,dY/dX是 f 的导数(Jacobian 矩阵) ,dX/dt就是向量 v。因此,以一个长度为 M 的向量 v 和一个 N 输出M 输入的函数 f 为对象运行前向自动微分,可以求出函数 f 的导数和向量 v 的乘积,这个积可以被简称为 JVP(Jacobian-Vector Product)。
类似地,如果想用前向自动微分求出整个 Jacobian 矩阵,也是可以将 v 设置为第 i 个元素为 1,其它元素均为 0 的向量来求出 Jacobian 矩阵的第 i 列,重复 M 次就可以求出整个矩阵。
由此可见,如果是想求出整个 Jacobian 矩阵,理论上来说,对于 M > N,也就是输入数量大于输出数量的函数,使用反向传播会更高效,否则使用前向自动微分会更高效。 不过,在实际中,因为前向自动微分是根据输入以及输入的导数一次性算出输出和输出的导数,对 cache 更友好,所以即使输入数量和输出数量相等,前向自动微分的速度也会比反向传播更快。 PyTorch 里也已经有了实验性的 Forward Mode 自动微分的 API,https://pytorch.org/docs/master/autograd.html#forward-mode-automatic-differentiation 。3
Hessian 以及 HVP
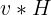 (VHP)和
(VHP)和  (HVP) 其实是一样的(只是形状上差一个转置)。
在上面我们已经提到过,对于输入和输出数量相等的函数,一次前向微分的时间和一次后向微分相比的速度会更快。而 f' 正是一个输入和输出数量相等的函数,所以,既然 HVP 和 VHP 一样,那么求函数 f 的 HVP(或者 VHP)的最佳方法是,先对 f 进行一次后向微分,得到 f',再对 f' 进行一次前向微分。
jax 的教程(
https://jax.readthedocs.io/en/latest/notebooks/autodiff_cookbook.html#hessian-vector-products-using-both-forward-and-reverse-mode
)里对几种不同的求 HVP 的方法做了测速,也可以看出 “Forward over reverse”,也就是先进行反向微分,再进行前向微分是速度最快的(“Reverse over forward” 是先进行前向微分再进行反向微分,它速度慢的原因 jax 的教程里有提到,这里就不再重复)。
(HVP) 其实是一样的(只是形状上差一个转置)。
在上面我们已经提到过,对于输入和输出数量相等的函数,一次前向微分的时间和一次后向微分相比的速度会更快。而 f' 正是一个输入和输出数量相等的函数,所以,既然 HVP 和 VHP 一样,那么求函数 f 的 HVP(或者 VHP)的最佳方法是,先对 f 进行一次后向微分,得到 f',再对 f' 进行一次前向微分。
jax 的教程(
https://jax.readthedocs.io/en/latest/notebooks/autodiff_cookbook.html#hessian-vector-products-using-both-forward-and-reverse-mode
)里对几种不同的求 HVP 的方法做了测速,也可以看出 “Forward over reverse”,也就是先进行反向微分,再进行前向微分是速度最快的(“Reverse over forward” 是先进行前向微分再进行反向微分,它速度慢的原因 jax 的教程里有提到,这里就不再重复)。
Forward over reverse
3.66 ms ± 89.7 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)
Reverse over forward
7.43 ms ± 4.22 ms per loop (mean ± std. dev. of 3 runs, 10 loops each)
Reverse over reverse
11.1 ms ± 6.9 ms per loop (mean ± std. dev. of 3 runs, 10 loops each)
Naive full Hessian materialization
55 ms ± 476 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)
自动微分的经典书籍 《Evaluating Derivatives》里甚至总结了这样一条规则:不要做超过一次反向微分。
再回过头来看文章最初的 Stackoverflow 回答,我们现在已有的知识已经可以分析出它到底是在求什么东西了。它在每一次调用grad函数后,将结果grads进行了求和,再对求和结果进行下一次后向微分,相当于通过乘以一个全 1 的向量,将多输出的函数变成了单输出,再进行后向微分。
因此 n=2 时它求的是 v 为全 1 向量时的 HVP,n=3 时是以全 1 向量和 n=2 的结果为对象求 VJP,依次类推。这些东西可能在某些场景下也有用,但显然不能说是 general 的 “高阶导数”。
让我们验证一下我们的分析:
import torch
from torch.autograd import grad
# 注:这个代码是反例,不要直接拿去用
def nth_derivative(f, wrt, n):
for i in range(n):
grads = grad(f, wrt, create_graph=True)[0]
f = grads.sum()
return grads
x = torch.arange(1, 3, dtype=torch.float, requires_grad=True)
x = x.reshape(2, 1)
x = torch.cat((x[0] + x[1], x[1]), 0)
y = x ** 4
loss = y.sum()
print(nth_derivative(f=loss, wrt=x0, n=2))
这样一段代码,求的是 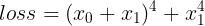 当 x0=1, x1=2 时的 2 阶“导数”,通过手算很容易得到 loss 的 Hessian 矩阵是
当 x0=1, x1=2 时的 2 阶“导数”,通过手算很容易得到 loss 的 Hessian 矩阵是 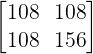 ,然而这段代码打印的结果是 [216., 264.] ,和上述的分析一致。
目前我们已经知道了 HVP 的求法,那么和求完整 Jacobian 矩阵时一样,用不同的 v 去计算 HVP,重复多次之后就可以得到完整的 Hessian 矩阵。但实际应用中,Hessian 矩阵的大小很可能非常非常大,例如对神经网络训练来说,Hessian 矩阵的大小是 N*N,N 是神经网络中的所有权重的元素数量之和,在 10^9 量级,要完整求出这么大的矩阵是不现实的。
所以通常都会想办法绕过 Hessian 矩阵的计算,例如用性质类似的矩阵代替 Hessian 矩阵,或者通过变换用 HVP 代替 Hessian 矩阵的功能(拟牛顿法、共轭梯度法)。
,然而这段代码打印的结果是 [216., 264.] ,和上述的分析一致。
目前我们已经知道了 HVP 的求法,那么和求完整 Jacobian 矩阵时一样,用不同的 v 去计算 HVP,重复多次之后就可以得到完整的 Hessian 矩阵。但实际应用中,Hessian 矩阵的大小很可能非常非常大,例如对神经网络训练来说,Hessian 矩阵的大小是 N*N,N 是神经网络中的所有权重的元素数量之和,在 10^9 量级,要完整求出这么大的矩阵是不现实的。
所以通常都会想办法绕过 Hessian 矩阵的计算,例如用性质类似的矩阵代替 Hessian 矩阵,或者通过变换用 HVP 代替 Hessian 矩阵的功能(拟牛顿法、共轭梯度法)。
Taylor Mode 求高阶导数
 的高阶导数,
的高阶导数,
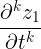 ,
,
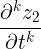 ......
单输入、N 输出的函数正好是前向自动微分的适用范围。
因此有一个 naive 的方法是,对 f(t) 进行一次前向微分,得到单输入、N 输出的函数 f'(t),再对 f'(t) 进行一次前向微分,得到单输入、N 输出的函数 f''(t),重复 k 次之后,就能得到 k 阶导数。没有了解过的人可能以为 k 阶导数也像一阶导数一样有简单的如
......
单输入、N 输出的函数正好是前向自动微分的适用范围。
因此有一个 naive 的方法是,对 f(t) 进行一次前向微分,得到单输入、N 输出的函数 f'(t),再对 f'(t) 进行一次前向微分,得到单输入、N 输出的函数 f''(t),重复 k 次之后,就能得到 k 阶导数。没有了解过的人可能以为 k 阶导数也像一阶导数一样有简单的如 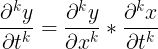 一样的链式法则,其实并不是这样。
以
一样的链式法则,其实并不是这样。
以  为例,根据链式法则,y 的一阶导数是
为例,根据链式法则,y 的一阶导数是 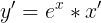 ,对一阶导数再求导,得到二阶导数
,对一阶导数再求导,得到二阶导数 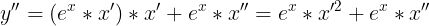 ,到这里其实就可以看出从二阶导数的链式法则没有那么简单了,如果再继续求导,会更加复杂,三阶导数是
,到这里其实就可以看出从二阶导数的链式法则没有那么简单了,如果再继续求导,会更加复杂,三阶导数是
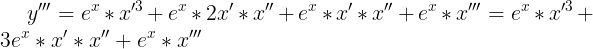 ,
四阶导数是
,
四阶导数是
 。
可以证明,k 阶导数的表达式中的项数在
。
可以证明,k 阶导数的表达式中的项数在 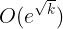 的量级,也就是说按照这种 naive 的逐次求导的方式计算 k 阶导数的
时间复杂度是
的量级,也就是说按照这种 naive 的逐次求导的方式计算 k 阶导数的
时间复杂度是
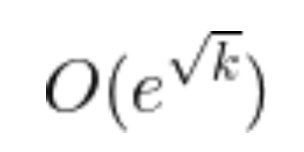 。
然而借助泰勒展开式和待求导的算子的性质,我们可以将时间复杂度降低到 O(k^2)。我们知道泰勒展开式里第 i 项的系数,其实就是原始函数的第 i 阶导数除以 i!。仍以
。
然而借助泰勒展开式和待求导的算子的性质,我们可以将时间复杂度降低到 O(k^2)。我们知道泰勒展开式里第 i 项的系数,其实就是原始函数的第 i 阶导数除以 i!。仍以 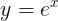 为例,根据一阶导数的链式法则我们有
为例,根据一阶导数的链式法则我们有 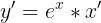 ,也就是
,也就是 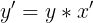 ,对 y 和 x 做泰勒展开:
,对 y 和 x 做泰勒展开:
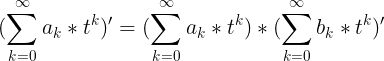 其中
其中  是 x 的泰勒展开式的第 k 项系数,也就是 x 相对于 t 的 k 阶导数除以 k !,是已知的。
上式也就是
是 x 的泰勒展开式的第 k 项系数,也就是 x 相对于 t 的 k 阶导数除以 k !,是已知的。
上式也就是
 对照系数,就能得到
对照系数,就能得到
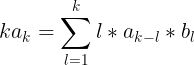 显然根据这个式子,我们能在 O(k^2) 的时间内算出
显然根据这个式子,我们能在 O(k^2) 的时间内算出  。
事实上,只要 y = g(x) 满足方程 b(y)g'(y) = a(y)g(y) + c(y),我们都能得到一个类似形式的结果(
。
事实上,只要 y = g(x) 满足方程 b(y)g'(y) = a(y)g(y) + c(y),我们都能得到一个类似形式的结果( 对应 b(y) = 1,a(y) = 1,c(y) = 0),而几乎所有的操作都满足上述的方程,如 ln(x)、x^c、sin(x)、cos(x) 等等,它们的 k 阶导数都可以通过这种方式在 O(k^2) 时间内算出来。
对应 b(y) = 1,a(y) = 1,c(y) = 0),而几乎所有的操作都满足上述的方程,如 ln(x)、x^c、sin(x)、cos(x) 等等,它们的 k 阶导数都可以通过这种方式在 O(k^2) 时间内算出来。
Taylar Mode 求高阶导数相当于将前向自动微分涉及的对象从实数扩展为了 k 阶泰勒多项式,Jax 的相应 API 是https://jax.readthedocs.io/en/latest/jax.experimental.jet.html。它在深度学习框架界是一个很新的东西,也可以用在反向自动微分里,待更新......
(注:这篇文章假设读者了解梯度和 Jacobian 矩阵的定义,如果不了解可以阅读维基百科。文章一些地方没有完全严谨,比如一些向量可能该加上转置符号。LaTeX 和 Markdown 混打比较麻烦所以只有复杂符号用了 LaTeX。)
其他人都在看
本文分享自微信公众号 - OneFlow(OneFlowTechnology)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
|








- 上一条: OSPO如何帮助保护你的软件供应链 2022-04-19
- 下一条: JuiceFS 缓存预热详解 2022-04-19
- 【自动微分原理】自动微分的具体实现 2022-05-26
- 一个算子在深度学习框架中的旅程 2022-06-15
- 深度学习框架量化感知训练的思考及OneFlow的解决方案 2021-10-08
- 一个Tensor在深度学习框架中的执行过程 2022-02-09
- 深度学习风潮迭起,如何开始有效学习? 2021-11-15


