Global View的概念和实现|OneFlow学习笔记

撰文|月踏
更新|赵露阳
在OneFlow中,Global View也被称作一致性视角,用来把一个物理集群抽象成一个逻辑设备,并使用Placement和SBP来实现这种抽象。本文从基本概念、数据结构、接口实现等方面对其进行学习和总结。
1
Placement
1.1 使用示例
Placement用来描述设备信息,包括设备类型、设备分布信息,先看一个具体的使用示例,然后根据这个示例来做分析:
import oneflow as flowx = flow.placement(type="cuda", ranks=[[0, 1, 2, 3], [4, 5, 6, 7]])
type(x)的输出为:
<class 'oneflow._oneflow_internal.placement'>
print(x)的输出为:
oneflow.placement(type="cuda", ranks=[[0, 1, 2, 3], [4, 5, 6, 7]])
可见Placement有下面两个属性:
-
type:表示设备类型,目前只支持CPU和CUDA
-
ranks:一个Python list,用于表示device的排布信息,ranks可以是一维至多维的,其shape表示了设备的排布信息(hierarchy)。上述ranks表示Tensor存放在集群中的2个节点中,其中节点1中使用设备0~3,节点2中使用设备4~7。
1.2 追踪代码
先看Python端的接口,在python/oneflow/__init__.py+27可以看到下面语句:
placement = oneflow._oneflow_internal.placement
可见Placement是在前文《 OneFlow学习笔记:python到C++调用过程分析 》
讲的一个pybind定义的_oneflow_internal这个module的子module,在oneflow/api/python/symbol/placement_symbol.cpp+226可以找到下面的定义:
ONEFLOW_API_PYBIND11_MODULE("", m) { py::class_<Symbol<ParallelDesc>, std::shared_ptr<Symbol<ParallelDesc>>>(m, "placement", py::dynamic_attr()) .def(...) .def(py::init([](const std::string& type, const py::object& ranks) { return PlacementSymbolExportUtil::CreateParallelDescSymbol(type, ranks).GetOrThrow(); }), py::arg("type"), py::arg("ranks"))
通过上面的多个def接口可以看到,通过调用 PlacementSymbolExportUtil::CreateParallelDescSymbol()来构造Placement对象,这个函数是个重载函数,定义在同一个文件中,多个重载版本只是参数有区别,其中的创建Placement的逻辑基本一致,下面列一个重载版本作为示例:
// create Symbol<ParallelDesc> object through given device_type and ranks parametersstatic Maybe<Symbol<ParallelDesc>> CreateParallelDescSymbol(const std::string& type,const py::object& ranks) {auto* obj = reinterpret_cast<PyArrayObject*>(PyArray_FromAny(ranks.ptr(), nullptr, 0, 0, NPY_ARRAY_DEFAULT | NPY_ARRAY_ENSURECOPY, nullptr));if (!obj) { return Error::RuntimeError() << "placement ranks must be int64 array."; }const auto& shape = JUST(GetRanksShape(obj));const auto& formated_machine_device_ids = JUST(ParseAndFormatRanks(obj));return SymbolOf(*JUST(CreateParallelDesc(type, *formated_machine_device_ids, shape)));}
由这个函数的返回值可见,Placement在C++中对应的数据结构是ParallelDesc,这个数据结构后面再说,现在先继续看创建逻辑,这里继续调用了CreateParallelDesc函数,同样定义在PlacementSymbolExportUtil这个类中:
static Maybe<ParallelDesc> CreateParallelDesc(const std::string& type, const std::vector<std::string>& formated_machine_device_ids,const std::shared_ptr<Shape>& hierarchy_shape) {JUST(CheckDeviceTag(type));auto parallel_conf = JUST(MakeParallelConf(type, formated_machine_device_ids, hierarchy_shape));std::shared_ptr<ParallelDesc> parallel_desc;JUST(PhysicalRun([¶llel_desc, ¶llel_conf](InstructionsBuilder* builder) -> Maybe<void> {parallel_desc = JUST(builder->GetParallelDescSymbol(parallel_conf));return Maybe<void>::Ok();}));return parallel_desc;}
这里最重要的是调用MakeParallelConf这个函数,位于oneflow/core/framework/parallel_conf_util.cpp+38,它根据传入的device type、machine device ids、hierarchy shape信息创建了一个cfg::ParallelConf类型的对象parallel_conf。
这里需要注意的是,hierarchy shape表示设备的排放层次序列,即上面通过const auto& shape = JUST(GetRanksShape(obj));得到的由ranks参数所表示的list shape。创建完parallel_conf之后,通过后面的GetParallelDescSymbol接口来得到需要返回的ParallelDesc类型对象,下面是MakeParallelConf的主要实现:
Maybe<cfg::ParallelConf> MakeParallelConf(const std::string& device_tag, const std::vector<std::string>& machine_device_ids, const std::shared_ptr<Shape>& hierarchy) { std::shared_ptr<cfg::ParallelConf> parallel_conf = std::make_shared<cfg::ParallelConf>(); parallel_conf->set_device_tag(device_tag); for (const std::string& machine_device_id : machine_device_ids) { size_t pos = machine_device_id.find(':'); CHECK_NE_OR_RETURN(pos, std::string::npos) << "device_name: " << machine_device_id; std::string machine_id = machine_device_id.substr(0, pos); CHECK_OR_RETURN( (IsStrInt(machine_id) || (machine_id[0] == '@' && IsStrInt(machine_id.substr(1))))) << " machine_id: " << machine_id; std::string device_id = machine_device_id.substr(pos + 1); size_t minus_pos = device_id.rfind('-'); if (minus_pos == std::string::npos) { CHECK_OR_RETURN(IsStrInt(device_id)); } else { std::string min_id = device_id.substr(0, minus_pos); CHECK_OR_RETURN(IsStrInt(min_id)); std::string max_id = device_id.substr(minus_pos + 1); CHECK_OR_RETURN(IsStrInt(max_id)); } parallel_conf->add_device_name(machine_device_id); if (hierarchy) { ShapeProto proto; hierarchy->ToProto(&proto); parallel_conf->mutable_hierarchy()->CopyFrom(cfg::ShapeProto(proto)); } } return parallel_conf; }
再继续看下GetParallelDescSymbol是怎么根据cfg::ParallelConf的对象得到ParallelDesc类型对象的,GetParallelDescSymbol定义在oneflow/core/framework/instructions_builder.cpp+230:
Maybe<ParallelDesc> InstructionsBuilder::GetParallelDescSymbol( const std::shared_ptr<cfg::ParallelConf>& parallel_conf) { int64_t symbol_id = JUST(FindOrCreateSymbolId(*parallel_conf)); return Global<symbol::Storage<ParallelDesc>>::Get()->MaybeGetPtr(symbol_id); }
大概过程就是在一个全局表里面去查有没有cfg::ParallelConf对应的已经创建好的ParallelDesc的对象,有的话直接返回,没有的话就创建出来放到全局表中去,至此就得到了前面展示的pybind接口中需要的ParallelDesc对象。
下面继续看下相关的数据结构,主要是cfg::ParallelConf和ParallelDesc,它们都和下面这个proto文件相关:
-
oneflow/core/job/placement.proto
这个proto文件是所有placement相关数据结构的源头,根据它会先自动生成下面三个文件:
-
build/oneflow/core/job/placement.pb.h
-
build/oneflow/core/job/placement.pb.cc
-
build/of_cfg_proto_python/oneflow/core/job/placement_pb2.py
前两者的接口主要是为了对placement数据做序列化,但是这些接口不适合对接python,所以使用tools/cfg中的工具对第三个文件做了处理,生成了下面三个方便给python端提供接口的文件:
-
build/oneflow/core/job/placement.cfg.h
-
build/oneflow/core/job/placement.cfg.cpp
-
build/oneflow/core/job/placement.cfg.pybind.cpp
cfg::ParallelConf这个数据结构就定义在build/oneflow/core/job/placement.cfg.h这个自动生成的文件中,再看ParallelDesc,它其实可以看作是cfg::ParallelConf的一层wrapper,主要是用在c++代码中来表示placement的数据结构,位于oneflow/core/job/parallel_desc.h+46,我们只需要关注这个数据结构就行:
class ParallelDesc final { ... ... Optional<int64_t> symbol_id_; DeviceType device_type_; ParallelConf parallel_conf_; std::shared_ptr<Shape> hierarchy_; std::vector<int64_t> sorted_machine_ids_; std::shared_ptr<HashMap<int64_t, std::shared_ptr<std::vector<int64_t>>>> machine_id2sorted_dev_phy_ids_; int64_t parallel_num_; int64_t device_num_of_each_machine_; std::vector<int64_t> parallel_id2machine_id_; std::vector<int64_t> parallel_id2device_id_; HashMap<int64_t, HashMap<int64_t, int64_t>> machine_id2device_id2parallel_id_; // TODO(lixinqi): merge cfg_parallel_conf_ and parallel_conf_ after cfg::ParallelConf taken as the // constructor argument std::shared_ptr<cfg::ParallelConf> cfg_parallel_conf_; // cached result of ContainingMachineId(GlobalProcessCtx::Rank()) for performace optimization. bool containing_current_rank_; };
这里面的数据结构看起来很复杂,我也不完全明白所有成员的含义,但归根结底这里数据成员的值还都是根据cfg::ParallelConf中的内容来的,在前面调用GetParallelDescSymbol时,如果全局表中没有找到,就会根据cfg::ParallelConf类型对象创建一个ParallelConf类型对象,再根据这个ParallelConf类型对象创建一个ParallelDesc类型对象,在ParallelDesc的构造函数中会调用类内的MaybeInit函数,位于oneflow/core/job/parallel_desc.cpp+112,这里面会完成ParallelDesc数据成员的赋值:
Maybe<void> ParallelDesc::MaybeInit(const ParallelConf& user_conf) { parallel_conf_ = user_conf; device_type_ = DeviceType::kInvalidDevice; const std::string& device_tag = parallel_conf_.device_tag(); DeviceType device_type = JUST(DeviceType4DeviceTag(device_tag)); CHECK_OR_RETURN(device_type_ == DeviceType::kInvalidDevice || device_type_ == device_type); device_type_ = device_type; machine_id2sorted_dev_phy_ids_ = std::make_shared<HashMap<int64_t, std::shared_ptr<std::vector<int64_t>>>>(); for (const std::string& device_name : parallel_conf_.device_name()) { if (device_name[0] == '@') { JUST(SetMachineIdAndDeviceIdsByParsingDeviceName(device_name.substr(1), 1)); } else { JUST(SetMachineIdAndDeviceIdsByParsingDeviceName(device_name, GlobalProcessCtx::NumOfProcessPerNode())); } } containing_current_rank_ = machine_id2sorted_dev_phy_ids_->count(GlobalProcessCtx::Rank()) > 0; ClearUp(); JUST(SanityCheck()); return Maybe<void>::Ok(); }
以上就是在python端使用placement时从上到下的大概过程和placement相关的数据结构。
2
SBP
2.1 基本概念
SBP是OneFlow发明的概念,在OneFlow的官方文档和论文中都有详细的说明(具体链接都在文末Reference中列出),这里只做简单介绍,它是下面三个单词的缩写:
-
Split:表示把数据按照指定的维度进行切分,被切分出的数据块会被分发到前面Placement指定的各个物理设备中去
-
Broadcast:表示把整份数据广播到前面Placement指定的各个物理设备中去
-
Partial:表示前面Placement指定的各个物理设备中所存的数据不是最终的运算结果,需要对各个物理设备上的数据进行Elementwise的add/min/max等操作,才能得到最终的结果
SBP描述了一致性视角下的数据与物理设备上的数据的映射关系,计算的时候,数据会根据自己的SBP属性被分发到各个物理设备进行计算,下面贴一张OneFlow官方文档的截图来直观的展示SBP的三种情况:
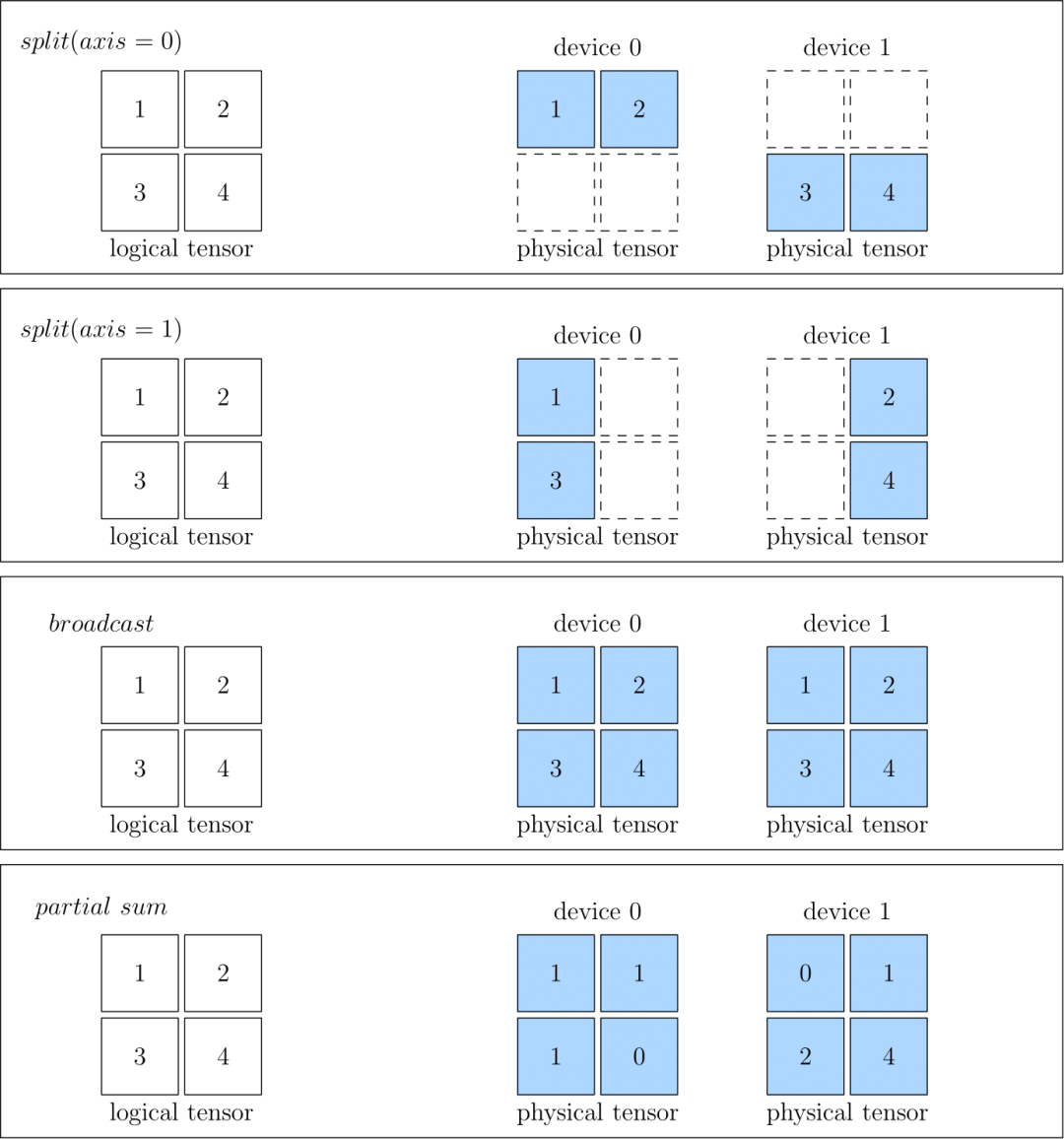
图1
2.2 使用示例
在Python环境做下面这个简单的示例:
import oneflow as flow s=flow.sbp.split(1) b=flow.sbp.broadcast p=flow.sbp.partial_sum
type(s)、type(b)、type(p)的输出如下:
<class 'oneflow._oneflow_internal.sbp.sbp'><class 'oneflow._oneflow_internal.sbp.sbp'><class 'oneflow._oneflow_internal.sbp.sbp'>
print(s)、print(b)、print(p)的输出如下:
oneflow.sbp.split(axis=1) oneflow.sbp.broadcast oneflow.sbp.partial_sum
2.3 追踪代码
先找入口,在python/oneflow/__init__.py+196:
from . import sbp
这用到了同目录下的这个module文件:python/oneflow/sbp.py,内容如下:
import oneflowfrom oneflow.framework.distribute import split_sbp as splitimport oneflow._oneflow_internalsbp = oneflow._oneflow_internal.sbp.sbpbroadcast = oneflow._oneflow_internal.sbp.broadcast()partial_sum = oneflow._oneflow_internal.sbp.partial_sum()# 其中split_sbp的定义如下def split_sbp(axis: int) -> oneflow._oneflow_internal.sbp.sbp:assert type(axis) is intreturn oneflow._oneflow_internal.sbp.split(axis)
可见split、broadcast和partial_sum都是定义在pybind定义的_oneflow_internal这个module的子module sbp的内部,在oneflow/api/python/symbol/sbp_symbol.cpp+85可以找到下面定义:
ONEFLOW_API_PYBIND11_MODULE("sbp", m) { m.attr("max_split_axis") = kMaxSplitAxis; py::class_<Symbol<SbpParallel>, std::shared_ptr<Symbol<SbpParallel>>>(m, "sbp", py::dynamic_attr()) .def("__str__", &api::SbpToString) ... ... m.def("split", GetSplitSbpParallel, py::arg("axis")); m.def("broadcast", &GetBroadcastSbpParallel); m.def("partial_sum", &GetPartialSumSbpParallel); }
可以看到sbp对接python接口时用的是cfg::SbpParallel这个数据结构,这里它和placement中的cfg::ParallelConf一样,同样下面这个proto文件自动生成出来:
-
oneflow/core/job/sbp_parallel.proto
编译的时候protoc会先根据这个proto文件生成下面三个文件:
-
build/oneflow/core/job/sbp_parallel.pb.h
-
build/oneflow/core/job/sbp_parallel.pb.cc
-
build/of_cfg_proto_python/oneflow/core/job/sbp_parallel_pb2.py
其中前两个文件提供接口用于对SBP数据做序列化,接口都属于oneflow namespace,第三个文件结合tools/cfg中的工具用于生成下面三个文件给Python端来用,文件中的接口属于cfg namespace:
-
build/oneflow/core/job/sbp_parallel.cfg.h
-
build/oneflow/core/job/sbp_parallel.cfg.cpp
-
build/oneflow/core/job/sbp_parallel.cfg.pybind.cpp
OneFlow的内部c++代码中用的是cfg::NdSbp这个数据结构,它其实可以看作是vector<cfg::SbpParallel>,这些数据结构之间的关系,直接看proto文件最为直接:
message SplitParallel { required int64 axis = 1; }message BroadcastParallel { }message PartialSumParallel { }message SbpParallel {oneof parallel_type {SplitParallel split_parallel = 1;BroadcastParallel broadcast_parallel = 2;PartialSumParallel partial_sum_parallel = 3;}}message SbpSignature { map<string, SbpParallel> bn_in_op2sbp_parallel = 1; }message NdSbp { repeated SbpParallel sbp_parallel = 1; }message NdSbpSignature { map<string, NdSbp> bn_in_op2nd_sbp = 1; }message SbpSignatureList { repeated SbpSignature sbp_signature = 1; }
继续看前面定义SBP的Python接口时所调用的GetSplitSbpParallel、GetBroadcastSbpParallel、GetPartialSumSbpParallel这三个C++函数,位于oneflow/api/python/symbol/sbp_symbol.cpp+41:
Maybe<Symbol<SbpParallel>> GetSplitSbpParallel(int axis) { CHECK_LT_OR_RETURN(axis, kMaxSplitAxis); static std::vector<Symbol<SbpParallel>> split_sbp_sym_list = *JUST(MakeSplitSbpParallelList(kMaxSplitAxis)); return split_sbp_sym_list.at(axis); }
Maybe<Symbol<SbpParallel>> GetBroadcastSbpParallel() { static Symbol<SbpParallel> broadcast_sbp = JUST(MakeBroadcastSbpParallel()); return broadcast_sbp; }
Maybe<Symbol<SbpParallel>> GetPartialSumSbpParallel() { static Symbol<SbpParallel> partial_sum_sbp = JUST(MakePartialSumSbpParallel()); return partial_sum_sbp; }
它们各自又分别调用了MakeSplitSbpParallel、MakeBroadcastSbpParallel、MakePartialSumSbpParallel这三个函数,位于oneflow/core/job/sbp_parallel.cpp+68:
Maybe<Symbol<SbpParallel>> MakeSplitSbpParallel(int axis) { CHECK_LT_OR_RETURN(axis, kMaxSplitAxis); SbpParallel split_sbp_parallel; split_sbp_parallel.mutable_split_parallel()->set_axis(axis); return SymbolOf(split_sbp_parallel); }
Maybe<Symbol<SbpParallel>> MakeBroadcastSbpParallel() { SbpParallel broadcast_sbp; broadcast_sbp.mutable_broadcast_parallel(); return SymbolOf(broadcast_sbp); }
Maybe<Symbol<SbpParallel>> MakePartialSumSbpParallel() { SbpParallel partial_sum_sbp; partial_sum_sbp.mutable_partial_sum_parallel(); return SymbolOf(partial_sum_sbp); }
SymbolOf背后用到的是Symbol这个OneFlow的基本组件,它的实现就不在这里展开了,总体来讲,它是把创建的对象维护到下面这个全局的SymbolMap中:
std::unordered_map<HashEqTraitPtr<const T>, std::shared_ptr<const T>>;
这样以后再用到的话,如果已经存在就不需要重新创建了,直接返回就好。
3
Global Tensor
Tensor的基本概念就不用说了,相信没有人不知道,在OneFlow的设计中,Global Tensor就是为了能够满足Global View所需抽象的一种Tensor,里面需要有前面讲的Placement和SBP相关的属性,下面把OneFlow所有Tensor一并总结列出:

图2
OneFlow的Tensor设计采用了bridge design pattern,把接口和实现做了分离,在Global View的情况下,用到的是上图中的ConsistentTensor(0.7版统称GlobalTensor),可以看到它持有一个指向ConsistentTensorImpl的指针,真正的实现就在ConsistentTensorImpl这个类中,下面是TensorImpl系列类的hierarchy图示:
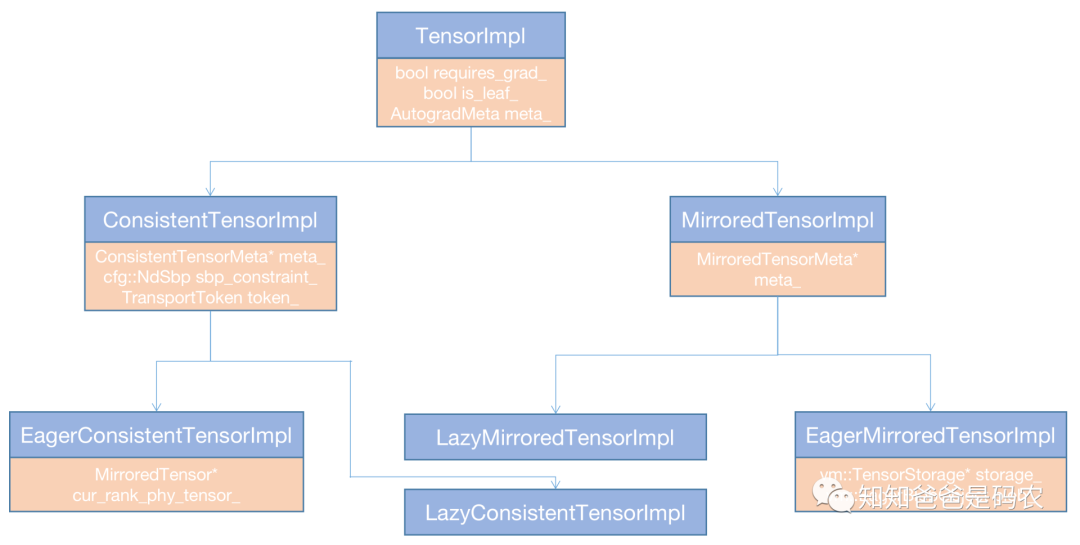
图3
先看这个图里的基类部分,橙色部分是它包含的数据成员,总体来讲这个基类维护了一些用于反向求导的信息。
再看EagerConsistentTensorImpl,前面讲过,Global View实际上是一个逻辑视角,对应的global tensor实际上也是个逻辑tensor,那么它实际的数据存在于集群的每台机器的每张卡对应的tensor中,即图2中的MirroredTensor中,EagerConsistentTensorImpl持有指向MirroredTensor的指针,MirroredTensor持有指向MirroredTensorImpl的指针,MirroredTensorImpl的子类EagerMirroredTensorImpl中则持有指向TensorStorage的指针,tensor中的数据最终是存在于TensorStorage对象中,它定义在oneflow/core/eager/eager_blob_object.h+32,下面是主要的数据成员:
class TensorStorage { ... size_t blob_bytes_; std::unique_ptr<char, std::function<void(char*)>> blob_dptr_; std::unique_ptr<MemoryAllocator> non_pod_allocator_; Optional<Symbol<Stream>> producer_stream_; Optional<Symbol<Stream>> last_used_stream_; std::vector<std::function<void()>> storage_delete_hooks_; };
继续看ConsistentTensorImpl,它持有一个指向ConsistentTensorMeta的指针,TensorMeta这个系列类维护了Tensor的一些元信息,如shape、data_type、device等,如果要是ConsistentTensor的话,还会持有placement和SBP的信息,下面是TensorMeta系列类的hierarchy图示:
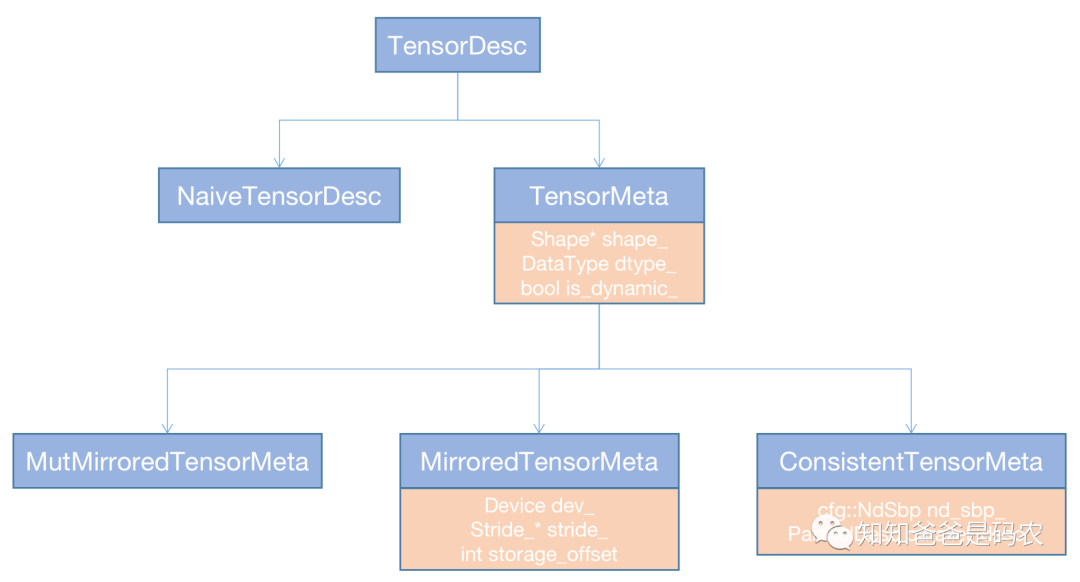
图4
可以看到在ConsistentTensorMeta中,维护了Placement和SBP的信息。
本文大概梳理了一下Global View的基本概念和部分具体实现,主要的参考资料是OneFlow的官方代码、官方文档和论文,以下是具体链接:
1.https://github.com/Oneflow-Inc/oneflow
2.https://arxiv.org/abs/2110.15032
3.https://docs.oneflow.org/master/parallelism/02_sbp.html
4.https://docs.oneflow.org/master/parallelism/03_consistent_tensor.html
其他人都在看
欢迎下载体验OneFlow v0.7.0最新版本:https://github.com/Oneflow-Inc/oneflow/

本文分享自微信公众号 - OneFlow(OneFlowTechnology)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
|








- 上一条: 王世杰:读博被美国拒签之后|OneFlow U 2022-04-13
- 下一条: 开源|Fair 在 58 同城拍客 App 中的实践 2022-04-13
- OneFlow学习笔记:从Functor到OpExprInterpreter 2022-04-22
- Autograd解析|OneFlow学习笔记 2022-05-13
- 推出全新分布式计算接口!OneFlow v0.7.0发布,LiBai代码库、Serving、MLIR一应俱全 2022-04-07
- OneFlow学习笔记:从Python到C++调用过程分析 2022-04-07
- OneFlow v0.5.0正式上线:四大特性实现轻快上手,高效、易用从此兼得 2021-10-08


