MRS CDL架构设计与实现

1 前言
MRS CDL是FusionInsight MRS推出的一种数据实时同步服务,旨在将传统OLTP数据库中的事件信息捕捉并实时推送到大数据产品中去,本文档会详细为大家介绍CDL的整体架构以及关键技术。
2 CDL的概念
MRS CDL(Change Data Loader)是一款基于Kafka Connect的CDC数据同步服务,可以从多种OLTP数据源捕获数据,如Oracle、MySQL、PostgreSQL等,然后传输给目标存储,该目标存储可以大数据存储如HDFS,OBS,也可以是实时数据湖Hudi等。
2.1 什么是CDC?
CDC(Change Data Capture)是一种通过监测数据变更(新增、修改、删除等)而对变更的数据进行进一步处理的一种设计模式,通常应用在数据仓库以及和数据库密切相关的一些应用上,比如数据同步、备份、审计、ETL等。
CDC技术的诞生已经有些年头了,二十多年前,CDC技术就已经用来捕获应用数据的变更。CDC技术能够及时有效的将消息同步到对应的数仓中,并且几乎对当前的生产应用不产生影响。如今,大数据应用越来越普遍,CDC这项古老的技术重新焕发了生机,对接大数据场景已经是CDC技术的新使命。
当前业界已经有许多成熟的CDC to大数据的产品,如:Oracle GoldenGate(for Kafka)、 Ali/Canal、Linkedin/Databus、Debezium/Debezium等等。
2.2 CDL支持的场景
MRS CDL吸收了以上成熟产品的成功经验,采用Oracle LogMinner和开源的Debezium来进行CDC事件的捕捉,借助Kafka和Kafka Connect的高并发,高吞吐量,高可靠框架进行任务的部署。
现有的CDC产品在对接大数据场景时,基本都会选择将数据同步到消息队列Kafka中。MRS CDL在此基础上进一步提供了数据直接入湖的能力,可以直接对接MRS HDFS和Huawei OBS以及MRS Hudi、ClickHouse等,解决数据的最后一公里问题。
| 场景 | 数据源 | 目标存储 |
|---|---|---|
| 实时数据湖分析 | Oracle | Huawei OBS, MRS HDFS, MRS Hudi, MRS ClickHouse, MRS Hive |
| 实时数据湖分析 | MySQL | Huawei OBS, MRS HDFS, MRS Hudi, MRS ClickHouse, MRS Hive |
| 实时数据湖分析 | PostgreSQL | Huawei OBS, MRS HDFS, MRS Hudi, MRS ClickHouse, MRS Hive |
表1 MRS CDL支持的场景
3 CDL的架构
作为一个CDC系统,能够从源目标抽取数据并且传输到目标存储中去是基本能力,在此基础上,灵活、高性能、高可靠、可扩展、可重入、安全是MRS CDL着重考虑的方向,因此,CDL的核心设计原则如下:
- 系统结构必须满足可扩展性原则,支持在不损害现有系统功能的前提下添加新的源和目标数据存储。
- 架构设计应当满足不同角色间的业务侧重点分离
- 在合理的情况下减少复杂性和依赖性,最大限度的降低架构、安全性、韧性方面的风险。
- 需要满足插件式的客户需求,提供通用的插件能力,使得系统灵活、易用、可配置。
- 业务安全,避免横向越权和信息泄露。
3.1 架构图/角色介绍
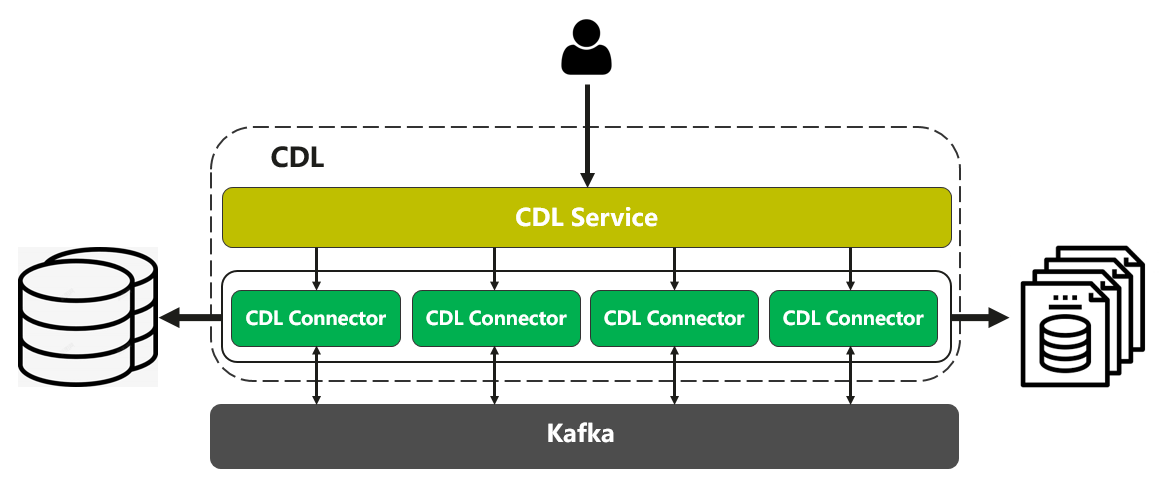 图1 CDL架构
图1 CDL架构
MRS CDL包含CDL Service和CDL Connector两个角色,他们各自的职能如下:
- CDL Service:负责任务的管理和调度,提供统一的API接口,同时监测整个CDL服务的健康状态。
- CDL Connector:本质上是Kafka Connect的Worker进程,负责真实Task的运行,在Kafka Connect高可靠、高可用、可扩展的特性基础上增加了心跳机制来协助CDL Service完成集群的健康监测。
3.2 为什么选择Kafka?
我们将Apache Kafka与Flume和Nifi等各种其他选项进行了比较,如下表所示:
| Flume | Nifi | Kafka |
|---|---|---|
| 优点 | 基于配置的Agent架构;拦截器;Source、Channel、Sink模型 | 有许多开箱即用的处理器;背压机制;处理任意大小的消息;支持MiNifi Agent来收集数据;支持边缘层数据流 |
| 缺点 | 存在数据丢失的场景;没有数据备份;数据大小限制;没有背压机制 | 没有数据复制;脆弱的容错机制;不支持消息保序;可扩展性较差 |
表1 框架比较
对于CDC系统,Kafka有足够的优势来支撑我们做出选择。同时,Kafka Connect的架构完美契合CDC系统:
- 并行 - 对于一个数据复制任务,可以通过拆解成多个子任务并且并行运行来提高吞吐率。
- 保序 - Kafka的partition机制可以保证在一个partition内数据严格有序,这样有助于我们实现数据完整性。
- 可扩展 - Kafka Connect在集群中分布式的运行Connector。
- 易用 - 对Kafka的接口进行了抽象,提升了易用性。
- 均衡 - Kafka Connect自动检测故障,并在剩余进程上根据各自负载重新进行均衡调度。
- 生命周期管理 – 提供完善的Connector的生命周期管理能力。
4 MRS CDL关键技术
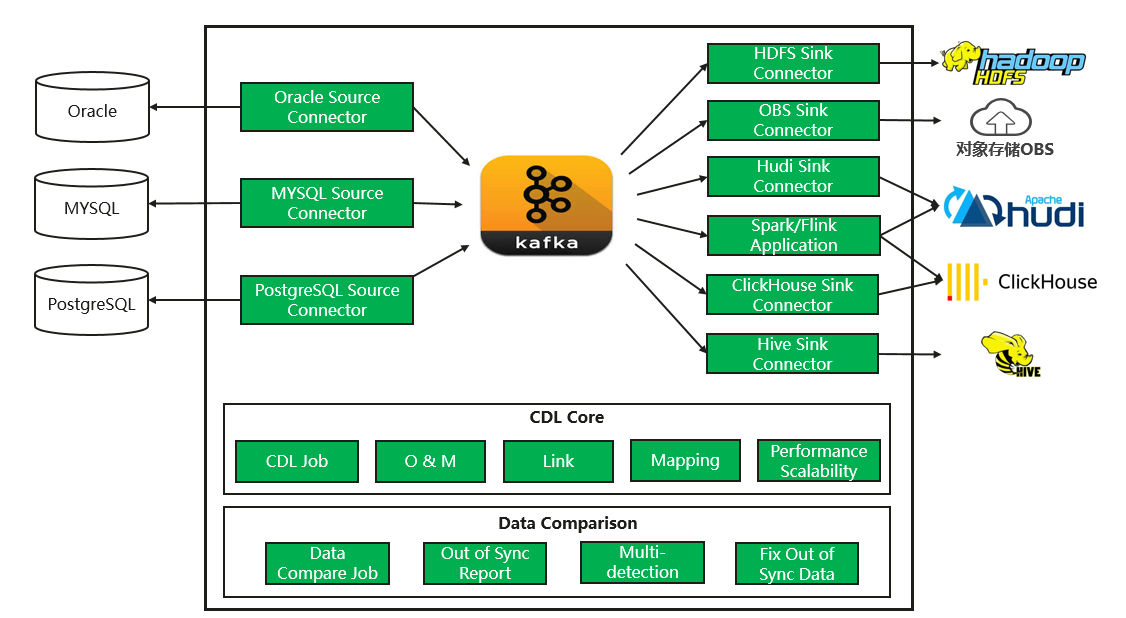 图2 CDL关键技术
图2 CDL关键技术
4.1 CDL Job
MRS CDL对业务进行了上层的抽象,通过引入CDL Job的概念来定义一个完整的业务流程。在一个Job中,用户可以选择数据源和目标存储类型,并且可以筛选要复制的数据表。
在Job结构的基础上,MRS CDL提供执行CDL Job的机制,在运行时,使用Kafka Connect Source Connector结合日志复制技术将CDC事件从源数据存储捕获到Kafka,然后使用Kafka Connect Sink Connector从Kafka提取数据,在应用各种转换规则后将最终结果推送到目标存储。
提供定义表级和列级映射转换的机制,在定义CDL Job的过程中可以指定转换规则。
4.2 Data Comparison
MRS CDL提供一种特殊的Job,用于进行数据一致性对比。用户可以选择源和目标数据存储架构,从源和目标架构中选择各种比较对进行数据比较,以确保数据在源和目标数据存储中一致。
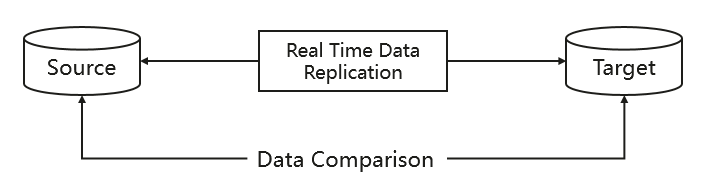 图3 Data Comparison抽象视图
图3 Data Comparison抽象视图
MRS CDL提供了专用的Rest API来运行Data Compare Job,并且提供如下能力:
- 提供多样的数据比较算法,如行哈希算法,非主键列比较等。
- 提供专门的查询接口,可以查询同步报表,展示当前Compare任务的执行明细。
- 提供实时的基于源和目标存储的修复脚本,一键修复不同步数据。
如下是Data Compare Job执行流程:
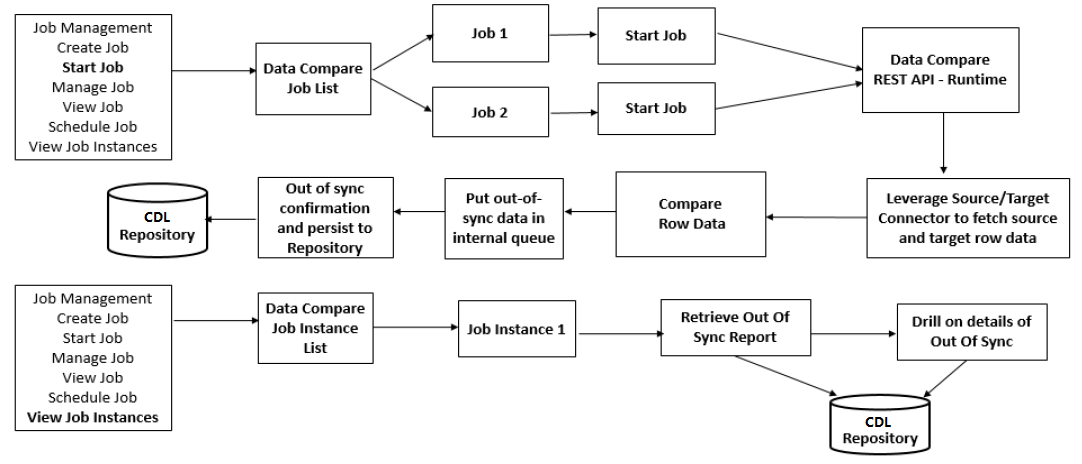 图4 Data Compare Job执行和查看流程
图4 Data Compare Job执行和查看流程
4.3 Source Connectors
MRS CDL通过Kafka Connect SDK创建各种源连接器,这些连接器从各种数据源捕获CDC事件并推送到Kafka。CDL提供专门的Rest API来管理这些数据源连接器的生命周期。
4.3.1 Oracle Source Connector
Oracle Source Connector使用Oracle RDBMS提供的Log Miner接口从Oracle数据库捕获DDL和DML事件。
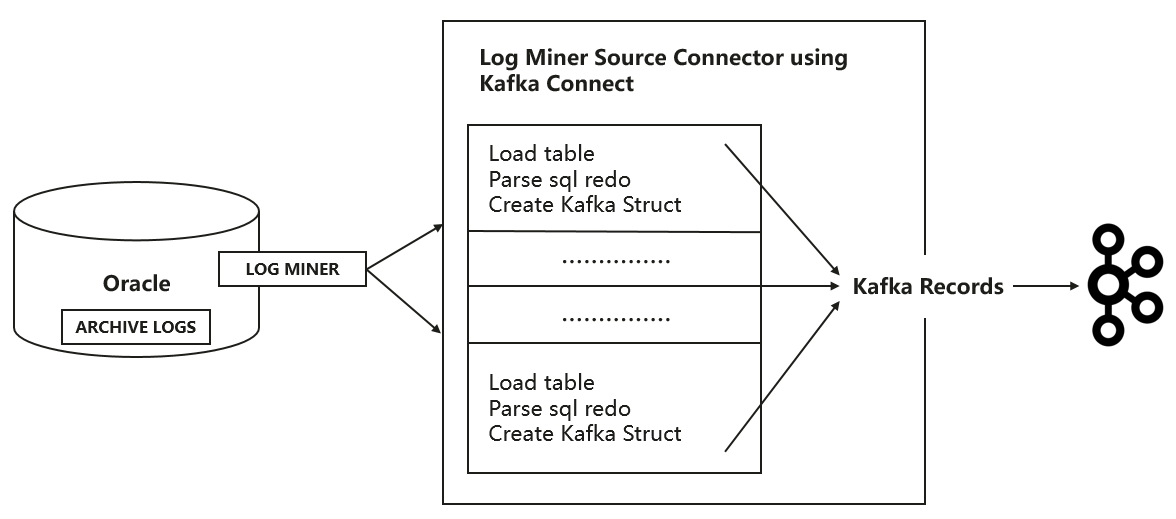 图5 Log Miner抓取数据示意图
图5 Log Miner抓取数据示意图
在处理DML事件时,如果表中存在BOLB/CLOB列,CDL同样可以提供支持。对于BOLB列的处理,关键点处理如下:
- 当insert/update操作发生时,会触发一系列的LOB_WRITE操作。
- LOB_WRITE用于将文件加载到BLOB字段中。
- 每个LOB_WRITE只能写入1KB数据。
- 对于一个1GB的图片文件,我们会整理全部的100万个LOB_WRITE操作中的二进制数据,然后合并成一个对象。我们会把这个对象存储到Huawei OBS中,最终在写入Kafka的message中给出该对象在OBS中的位置。
对于DDL事件的捕获,我们创建单独的会话来持续跟踪。当前支持的DDL语句如下:
| No | DDL语句 | 示例 |
|---|---|---|
| 1 | CREATE TABLE | CREATE TABLE TEST ( EMPID INT PRIMARY KEY, ENAME VARCHAR2(10)) |
| 2 | ALTER TABLE ... ADD (<name> <data type>) | ALTER TABLE TEST ADD ( SALARY NUMBER) |
| 3 | ALTER TABLE ... DROP COLUMN ... | ALTER TABLE TEST DROP (SALARY) |
| 4 | ALTER TABLE ... MODIFY (<column> ... | ALTER TABLE TEST MODIFY SALARY INT |
| 5 | ALTER ... RENAME... | ALTER TABLE TEST RENAME TO CUSTOMER |
| 6 | DROP ... | DROP TABLE TEST |
| 7 | CREATE UNIQUE INDEX ... | CREATE UNIQUE INDEX TESTINDEX ON TEST (EMPID, ENAME) |
| 8 | DELETE INDEX … | Delete existing index |
表2 支持的DDL语句
4.3.2 MYSQL Source Connector
MYSQL的Binary Log(Bin Log)文件顺序记录了所有提交到数据库的操作,包括了对表结构的变更和对表数据的变更。MYSQL Source Connector通过读取Bin Log文件,生产CDC事件并提交到Kafka的Topic中。
MYSQL Source Connector主要支持的功能场景有:
- 捕获DML事件,并且支持并行处理所捕获的DML事件,提升整体性能
- 支持表过滤
- 支持配置表和Topic的映射关系
- 为了保证CDC事件的绝对顺序,我们一般要求一张表只对应一个Partition,但是,MYSQL Source Connector仍然提供了写入多Partition的能力,来满足某些需要牺牲消息保序性来提升性能的场景
- 提供基于指定Bin Log文件、指定位置或GTID来重启任务的能力,保证异常场景下数据不丢失
- 支持多种复杂数据类型
- 支持捕获DDL事件
4.3.3 PostgreSQL Source Connector
PostgreSQL的逻辑解码特性允许我们解析提交到事务日志的变更事件,这需要通过输出插件来处理这些变更。PostgreSQL Source Connector使用pgoutput插件来完成这项工作。pgoutput插件是PostgreSQL 10+提供的标准逻辑解码插件,无需安装额外的依赖包。
PostgreSQL Source Connector和MYSQL Source Connector除了部分数据类型的区别外其他功能基本一致。
4.4 Sink Connectors
MRS提供多种Sink Connector,可以从Kafka中拉取数据并推送到不同的目标存储中。现在支持的Sink Connector有:
- HDFS Sink Connector
- OBS Sink Connector
- Hudi Sink Connector
- ClickHouse Sink Connector
- Hive Sink Connector 其中Hudi Sink Connector和ClickHouse Sink Connector也支持通过Flink/Spark应用来调度运行。
4.5 表过滤
当我们想在一个CDL Job中同时捕获多张表的变更时,我们可以使用通配符(正则表达式)来代替表名,即允许同时捕获名称满足规则的表的CDC事件。当通配符(正则表达式)不能严格匹配目标时,就会出现多余的表被捕获。为此,CDL提供表过滤功能,来辅助通配符模糊匹配的场景。当前CDL同时支持白名单和黑名单两种过滤方式。
4.6 统一数据格式
MRS CDL对于不同的数据源类型如Oracle、MYSQL、PostgreSQL采用了统一的消息格式存储在Kafka中,后端消费者只需解析一种数据格式来进行后续的数据处理和传输,避免了数据格式多样导致后端开发成本增加的问题。
4.7 任务级的日志浏览
通常境况下,一个CDL Connector会运行多个Task线程来进行CDC事件的抓取,当其中一个Task失败时,很难从海量的日志中抽取出强相关的日志信息,来进行进一步的分析。
为了解决如上问题,CDL规范了CDL Connector的日志打印,并且提供了专用的REST API,用户可以通过该API一键获取指定Connector或者Task的日志文件。甚至可以指定起止时间来进一步缩小日志查询的范围。
4.8 监控
MRS CDL提供REST API来查询CDL服务所有核心部件的Metric信息,包括服务级、角色级、实例级以及任务级。
4.9 应用程序错误处理
在业务运行过程中,常常会出现某些消息无法发送到目标数据源的情况,我们把这种消息叫做错误记录。在CDL中,出现错误记录的场景有很多种,比如:
- Topic中的消息体与特定的序列化方式不匹配,导致无法正常读取
- 目标存储中并不存在消息中所存储的表名称,导致消息无法发送到目标端
为了处理这种问题,CDL定义了一种“dead letter queue”,专门用于存储运行过程中出现的错误记录。本质上“dead letter queue”是由Sink Connector创建的特定的Topic,当出现错误记录时,由Sink Connector将其发往“dead letter queue”进行存储。
同时,CDL提供了REST API来供用户随时查询这些错误记录进行进一步分析,并且提供Rest API可以允许用户对这些错误记录进行编辑和重发。
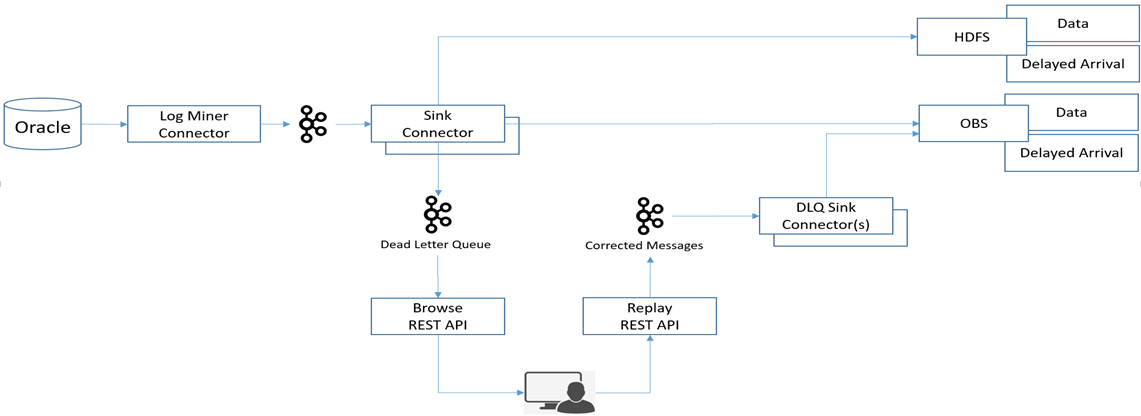 图6 CDL Application Error Handling
图6 CDL Application Error Handling
5 性能
CDL使用了多种性能优化方案来提高吞吐量:
- Task并发 我们利用Kafka Connect提供的任务并行化功能,其中Connect可以将作业拆分为多个任务来并行复制数据,如下所示:
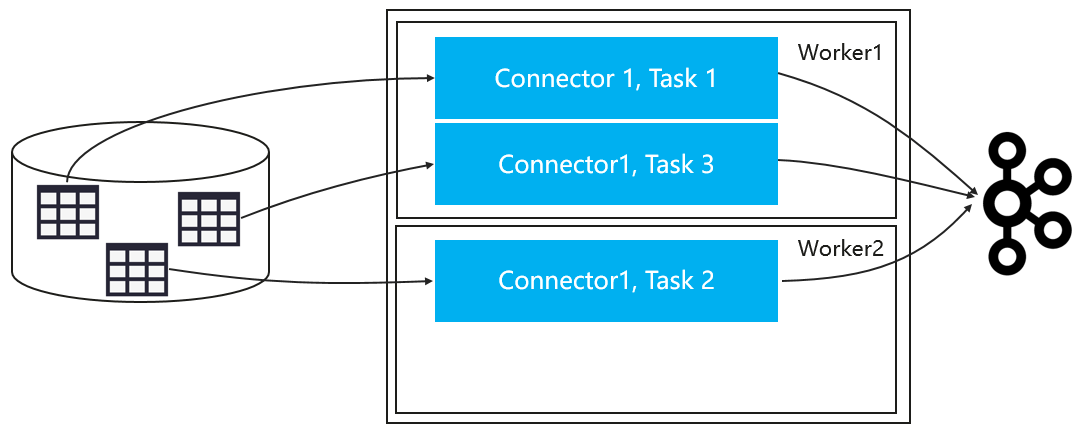 图7 Task并发
图7 Task并发
- 使用Executor线程并行化执行任务 由于Log Miner,Bin Log等数据复制技术的限制,我们的Source Connector只能顺序的捕获CDC事件,因此,为了提高性能,我们将这些CDC事件先缓存到内存队列中,然后使用Executor线程并行的处理它们。这些线程会先从内部队列中读取数据,然后处理并且推送到Kafka中。
 图8 Executor线程并发
图8 Executor线程并发
6 总结
MRS CDL是数据实时入湖场景下重要的一块拼图,我们仍然需要在数据一致性、易用性、多组件对接以及性能提升等场景需要进一步扩展和完善,在未来能够更好的为客户创造价值。
本文由华为云发布。
|








- 上一条: 即学即会 Serverless | 初识 Serverless 架构 2022-03-21
- 下一条: 如何管理并发写入操作?带你快速上手 2022-03-21
- 详解MRS CDL整体架构设计 2021-08-24
- 使用MRS CDL实现实时数据同步的极致性能 2021-11-26
- HDFS、Yarn、Hive…MRS中使用Ranger实现权限管理全栈式实践 2022-07-18
- 基于MRS-Hudi构建数据湖的典型应用场景介绍 2021-12-09
- MRS HetuEgine的数据虚拟化实践 2021-11-04


