消息复杂计算的抽象和简化

作者:蒋文豪(四点)
消息客户端计算的复杂性
在客户端的设计中,一般的分层会至少包含下层的数据服务层和上层的UI层,下层的数据模型主要由所在领域决定,相对独立、稳定,而UI则更多变,且会对多种数据进行组合。由于UI的相对多变性与模型的相对稳定性,在数据层和UI之间,就需要对数据进行若干的处理才能交给UI展示。 比较简单的情况比如将原始数据的时间戳转换为 PD 要求的字符串,如果涉及到对不同数据进行关联、分页加载、变更计算,这部分数据处理逻辑就会比较复杂。
消息作为富客户端,这部分逻辑非常复杂,加上状态的存在,可以说是消息客户端中最复杂的逻辑之一,这种复杂主要体现在这些维度:
- 本地部分数据:客户端只存部分消息数据,获取数据时本地数据不全需要再异步请求服务端,还需要支持上层指定请求策略,这使得接口无法采用 request-response的形式,必须使用流式接口,数据回调和结果回调的分离,以及多次数据回调,增加了处理逻辑的复杂度;
- 支持变更同步:除了主动拉取,会话消息数据需要支持变更的推送,且对于所有的变更,需要保证数据(包括缓存和UI展示)的一致性;
- 多个数据来源:由于历史的原因,消息的同一种数据(比如会话)存在多个来源,因此需要请求多次,将多次数据回调合并,处理错误,还要尽量保证加载速度。经过众多同学的努力,手淘和千牛中下掉了OpenIM、DT两个数据源,今天用户在手淘和千牛中看的会话和消息,依然有BC、CC、IMBA三个来源;
- 多种数据聚合:UI展示需要把会话、消息、Profile(头像昵称)、群、群成员信息以及其他业务数据进行聚合,把相关的多个不同数据按照不同的规则聚合在一起;
- 支持分页请求:总的数据量比较大,需要通过分页机制加载,除了标准的分页加载之外,还要支持定位到某条消息从中间开始加载,这就出现了双向分页加载,以及 进入和退出 中间加载时的状态转换和异常处理;
- 多条数据合并:由于业务的需要,消息之间存在更新和替换关系(比如同一条订单的物流状态更新),拉取的新数据要修改已存的消息状态数据,而非仅仅添加在头部或尾部,新的消息会导致已有消息的更新以及在数据结构中的位置变化;
- 数据结构复杂:消息存在列表、树两种UI形态,对应的状态也有两种形态,对于这些数据结构的变更计算逻辑比较复杂,对于树来说,还需要支持虚拟节点计算和结构动态变化。
这块逻辑在消息客户端涉及会话、消息、profile、群、群成员、关系等所有核心服务数据模型,总计大约25000行代码,占消息总代码的8%左右,是核心的数据处理。由于这些逻辑很容易耦合在一起,形成一些高维的逻辑,表现为大量的条件分支和递归嵌套,这种高维的逻辑很难写,也很难维护,并且占据了不少包大小,因此有必要对这些逻辑抽象和简化。
目标
- 在不同的模型、不同的接口和相似的逻辑之上再建立一层抽象,统一客户端的数据处理;
- 将高维的数据处理逻辑简化为一个更加清晰的处理模型,代码量下降60%;
- 实现数据处理的双端一致。
消息数据处理过程分析
通常会将客户端划分为数据服务层、逻辑层、UI层三层,这部分数据获取和计算会被归到逻辑层。这里的问题在于,数据服务层对应于领域定义,UI层对应于渲染、动画和交互事件处理,这样逻辑层很容易变成一个缝合怪,数据请求、数据转换、上下文维护、异步处理、递归逻辑、状态管理、变更同步,所有不属于另外两层的部分都会被扔到逻辑层,导致逻辑层的臃肿。
下图左侧是这个处理过程的工作内容和上下游,右侧为数据拉取和变更处理的数据流向和计算过程:
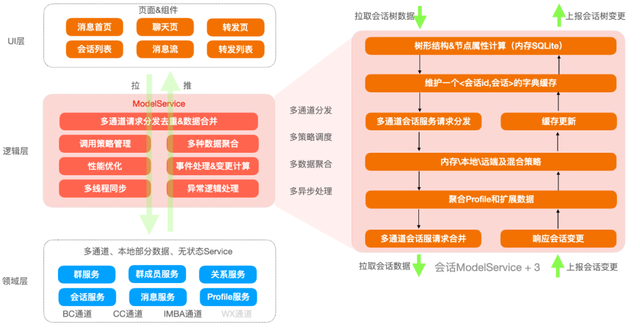
可以看到,将这部分数据处理仅仅定义为逻辑是过于宽泛的,不利于针对性的优化,因此有必要进行深入的分析和研究。
在对会话、消息、profile、群、群成员、关系6大核心数据处理链路进行归纳、分解、分析和综合之后,我们可以将数据处理过程简化为如下的过程:
- 请求每个通道的 会话\消息 数据,并将多次结果回调合并为一次结果回调,处理多次数据回调,请求会话\消息对应的Profile、群、群成员、关系数据、业务数据;
- 建立会话\消息 和Profile、群、群成员、关系数据、业务数据之间的 关联关系 ,生成聚合数据,并处理聚合数据之间的依赖、优先级和缓存一致性;
- 将数据转换为数组\树形结构,支持请求来的数据与数据结构中已存的数据进行替换、更新合并计算,支持树结构和虚拟节点的动态计算,支持UI局部更新;
- 响应各种数据的增删改等变更事件,根据事件处理计算变更和结果,保证数据的一致性;
- 在进入和退出中间加载时,处理各种数据缓存、关联关系、加载信息的正确性;
- 支持特殊逻辑,如实时新数据不按照时间排序,而是直接添加在头部或尾部;
- 中间每个逻辑的异常处理、超时机制、线程同步、上屏时间优化、日志、监控等逻辑。
我们可以将这些逻辑分为两类:
作为计算的逻辑
对应于上面的过程2、3、4、5、6。
如果我们将这块逻辑看做黑盒,关心它的输入输出和功能,可以得出这块逻辑的核心工作是将各种各样的输入数据转换为特定的输出数据,这完美的对应着计算的概念的结论,即:
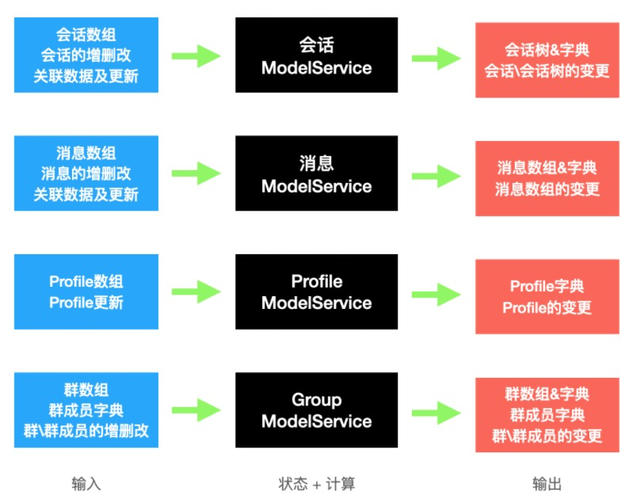
基于计算的概念,可以将这段计算过程形式化地抽象为一个函数f,从而实现对状态计算的抽象,上图很直观的体现了入参为输入和当前状态,输出为新的状态和结果:
f :: (Input, State1) -> (State2, Result)
来分析一下函数f的入出参和形式:
第一,这里的Input可以能是拉取回来的数据,也可以是增删改等数据变更,或者是消息已读等明确的事件。这里我们可以通过定义插入、更新、删除三个来统一所有的事件,因为所有的事件逻辑上都必定可以唯一的映射到这三个事件上(尽管实际上,由于部分服务不具备计算变更细节的能力,我们还支持了RemoveAll和Reload两个事件)。
第二,结合高阶函数,Input实际上已经决定了这个函数的形式,即对于一个数据插入事件,其对应的f必然为 \state -> insert someData into state 的形式,即 Input 已经包含在 f的实现中了,因此可以将函数 f 进一步简化为:
f :: (State1) -> (State2, Result)
其中 f 的形式由输出的事件决定,这样就得到了一个非常简化的函数抽象。
第三,上面的分析还能得出一个推论,即事件和函数是等价的(可以互相转换),这使得我们可以通过处理事件来实现对函数的处理,从而可以通过数据的处理来优化计算的性能,可以看到,数据和过程边界的打破赋予我们更强的能力。
第四,对于 State 参数,需要包含聚合后的数据,因此需要处理数据的关联,一般的,我们可以将数据的关联场景抽象为 一个主数据对应多个附属数据 的形式,通过定义一个 pair 函数来进行关联关系的判断:
pair :: (mainData, subData) -> Bool
这样就可以通过注入 pair 函数来实现主数据和附属数据的关联,然后将有关联关系的数据进行聚合。
第五,State还涉及数据\树形结构计算,这里在不同的场景是不一样的,可以抽象为一个 DataStructure ,定义增删改查接口,然后在不同的场景使用不同的 DataStructure。
作为结构化数据获取的逻辑
对应于上面的过程1、6。
这部分逻辑的作用是会话消息Profile等数据的获取和变更事件监听,由于6大服务的接口各不相同,之前的实现是一一对接。通过抽象之后,我们可以通过定义具备拉取接口和变更接口的Inject来实现这部分逻辑的抽象,这属于标准操作,不再赘述。
这部分数据获取的第二个特点是请求的平行分发和垂直组合,举例来说,有多个通道决定了数据请求时需要平行的请求每个通道,每个通道的请求则根据不同的请求策略和每一步的回调数据决定下一次请求(这里与标准的 Future/Promise 的区别在于,Future/Promise前后步骤的任务是不同的,后面的逻辑需要前面的数据,这里前后步骤的逻辑相同,可能上一步请求本地,下一次请求远端,因此可以比 Future/Promise 更简化)。
如果不进行抽象,这里是一个至少三维的逻辑,即对于多个通道的多个步骤进行主数据的获取,然后对获取的主数据再获取附属数据,逻辑会写的非常复杂。这里的关键在于每个通道的请求,每个步骤的请求都是非常相似的,主要是多次请求的结构不同,并且数据请求的结构由参数和数据决定,因此可以把它称为结构化数据获取,即这里可以通过对请求结构的抽象进行简化。
可以定义出结构化数据获取任务平行和垂直组合的核心函数:
dispatch :: [param] -> [task]
compose :: strategy -> task
其中 dispatch 函数对应于Rx中的 flatMap,不过由于手淘iOS没有集成 RxSwift 和 OpenCombine,官方的 Combine 框架要iOS13之上才能使用,因此只能自己实现一个轻量的。
这样通过 dispatch 和 compose 将任务进行结构化组合实现任务获取的抽象和简化。
技术方案
核心技术方案
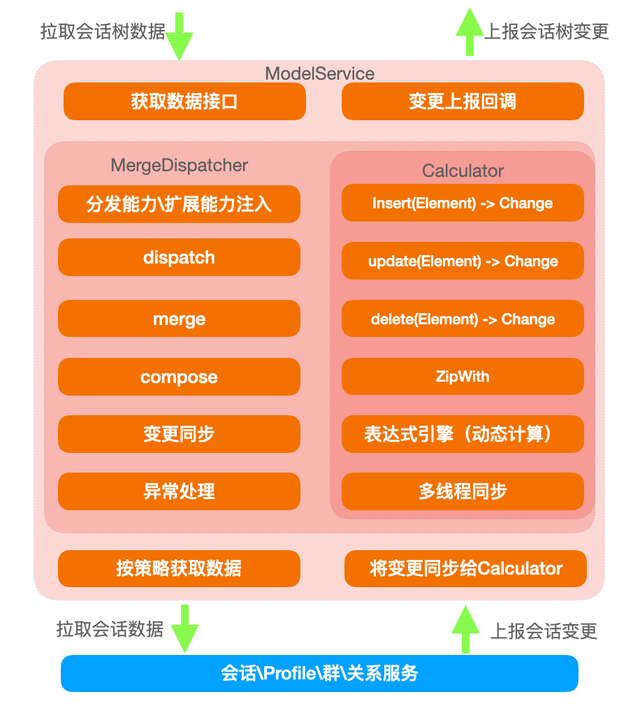
核心模块:
- MergeDispatcher : 实现数据获取的结构化,并将数据和变更统一为变更,处理所有的异常;
- Calculator : 实现主数据和附属数据的关联和聚合,计算的多线程同步,变更上报;
- DataStructure : 进行主数据的结构计算。
此外,Inject为计算提供请求接口和变更事件,为所有数据的注入点,上层通过 ModelService 获取计算后有聚合数据构成的数据结构,以及变更事件。
调用关系与数据流向
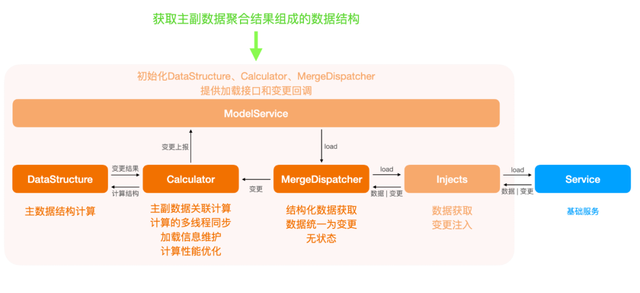
ModelService会使用初始化DataStructure、CalCulator、主数据、附属数据的Inject,并用来初始化MergeDispatcher
- 当UI需要数据时,调用ModelService的load接口;
- ModelService直接调用MergeDispatcher的load接口;
- MergeDispatcher 平行调用主数据Inject的load接口,在每次回调主数据时,调用附属数据Inject的load接口请求附属数据,根据场景执行对应的超时逻辑,将主数据和附属数据给到Calculator进行计算,超时后的数据也继续给到Calculator进行计算;
- Calculator 执行计算的多线程同步,更新主数据、附属数据、关联关系的缓存,生成聚合数据,并将主数据给到DataStructure计算结构,然后将返回的全量和变更进行上报;
- 数据结构接收数据后,对当前状态(数据结构)执行增删改操作,并返回对应的新状态和变更数组。
技术效果
最终,我们实现了计算和数据获取的分离,计算过程全部在Calculator,数据获取主要在MergeDispatcher,两部分独立实现,不再耦合,将逻辑层次从原来的模型数量 * 接口数量 * 数据结构 降为 事件数量 * 数据结构,处理模型非常清晰,且适用于任意模型。
针对计算过程,逻辑上抽象出一个高阶计算函数 f :: (State1) -> (State2, Result),这个函数形式上非常简单,却紧紧抓住这种复杂状态计算的本质,让我们得以统一计算过程,整个计算过程的正确性有完备的理论基础,后续新增模型不会增加计算逻辑。
针对数据获取,我们将数据类型化为主数据和附属数据,并针对由请求的结构进行抽象,实现了所有的数据获取的统一和简化。
关注【阿里巴巴移动技术】微信公众号,每周 3 篇移动技术实践&干货给你思考!
|








- 上一条: NextRPC : RPC多段返回的创新和探索 2022-03-14
- 下一条: 重磅 | 腾讯云服务网格开源项目 Aeraki Mesh 加入 CNCF 云原生全景图 2022-03-14
- 第3章 计算机系统的软件·3.1 计算机软件概述 2021-07-11
- 第4章 计算机系统的应用 ·4.1 计算机网络 2021-07-15
- 计算机接口技术 2021-07-19
- 第4章 计算机系统的应用 ·4.6 计算机信息安全与职业道德 2021-07-15
- 计算机组成原理 第一章 计算机系统概述 2021-07-26


