副本的功能特性和使用方法

【摘要】:
副本是云溪数据库分布式与高可用特性的实现基础,本文聚焦副本变更的整个流程,首先阐释副本的分类方式,并详细介绍了云溪数据库在raft算法基础上新增的各类副本的功能特性。Configure zone是控制副本数量、类型和分布的主要途径,我们将从语法、字段到特性,全面了解configure zone的使用方法。通过副本增加、删除和均衡,副本的数量、类型和分布将尽可能满足configure zone,整个数据库的性能和资源利用率也会得到提升。最后探讨云溪数据库对于数据分片的管理机制——Range分裂与合并是怎样决策和进行的。
Part 1 - 副本类型
1. 副本分类

图1. 副本分类方式
(1)副本按照是否有投票权分为voter和non-voter(注:投票权包括raft leader选举投票权和raft日志提交投票权)。
(2) voter按照是否存储用户数据分为全能型副本(Universal)和日志型副本(Logonly)。
(3)non-voter目前有列存副本(Column),使用列存引擎,提供一致性读服务。
(4)voter按照日志提交时是否具有一票否决权分为强同步副本(Synchronizer)和非强同步副本。
2. 强同步副本特性
(1)可以配置在任何voter副本上。
(2)日志提交时拥有一票否决权。
Raft协议原有的日志提交策略:需要过半数副本投票。
引入强同步副本后,新的日志提交策略:需要过半数副本投票,和全部强同步副本投票。
如果强同步副本发生故障,在故障被识别之前,写入会被阻塞。在故障被识别之后,此前阻塞的写入会成功提交,不需要回滚。
该特性可用于跨地域的同步写入。
(3)故障识别与恢复
强同步副本的故障识别基于raft心跳。当发送给强同步副本的心跳未得到回复达到强同步超时时间,leader识别强同步故障,日志提交忽略故障的强同步副本,该副本的强同步标识也会被强制取消。
Leader所在node会产生日志,告知是哪个store的哪张表的哪个range出现了强同步故障,并记录强同步故障事件,告知故障store(可在AdminUI-指标-事件查看,或通过“select* from system.eventlog”查询)。
![]()
图2. 强同步故障日志
强同步副本恢复工作后,强同步标识恢复,也会有对应的日志和事件产生。
强同步超时时间默认值100(单位tick,相当于20s),用户可配置,必须大于5(心跳超时时间,表示发送心跳的间隔)。
用例:setcluster setting raft.synchronizer_timeout_ticks = 50;
3. 日志型副本特性
(1)只存储raft日志,不存储用户数据
(2)有投票权,可以当选为raft leader,但不能发送快照
(3)不能成为lease holder
日志型副本不能成为lease holder,可以保证:
● 不能从日志型副本读写数据;
● 由于leader会尽量与lease holder保持一致,在日志型副本当选为leader的情况下,只要存在全能型副本拥有最新数据,leader将立即转移到该全能型副本上。
(4)日志型副本保留日志
● 原有的raft日志清理策略:
Step1. 计算可清理日志的最大index值。
(i)确保要清理的日志已经追加到大多数副本上。
(ii)对于活跃的副本,为避免发送快照,要保证日志已经追加到每一个副本。
(iii)当有失活副本时,会保护该副本的last index直到日志大小超过4MB。
(iv)保护等待中的快照的index。
Step2. 如果可清理的日志index数量≥100,或者index数量>0且日志实际大小≥64KB,发起TruncateLogRequest,各个副本立即应用truncateState。

图3. truncateState的类型,包含index和term字段
● 新策略:
发起TruncateLogRequest的条件不变。
日志型副本将truncateState拦截,按小时合并记录,暂不应用;扫描拦截记录,找到达到日志型副本日志清理时间(用户可配置,最小值-1)的最后一条记录,应用并将记录清除。
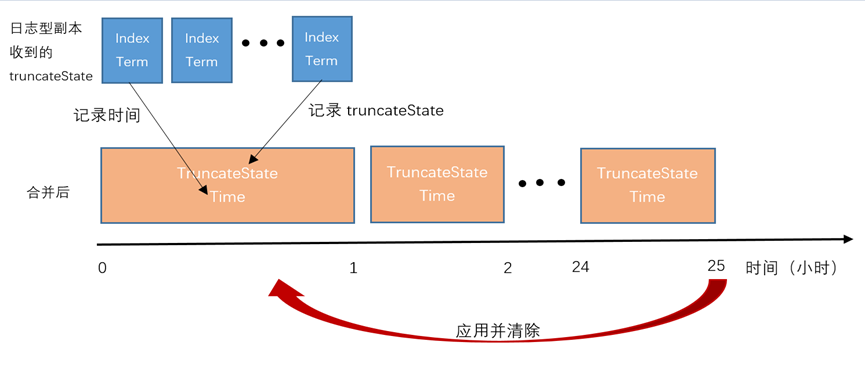
图4. 日志型副本的日志清理逻辑
● 日志型副本日志清理时间默认值为24,表示日志型副本的日志实际保留时间至少为24小时。
● set clustersetting raft.logonly_truncate_hours = -1;表示关闭日志型副本保留日志的功能。
(5)日志型副本异地重启
● 部署模式:两数据中心三副本(全能型副本、强同步副本、日志型副本),全能型副本与强同步副本分别存放在DC1与DC2的高配机器(或多数机器)中,日志型副本存放在DC1或DC2的低配机器(或少量机器)中,并将日志增量复制到另一个数据中心的低配机器(或少量机器)。
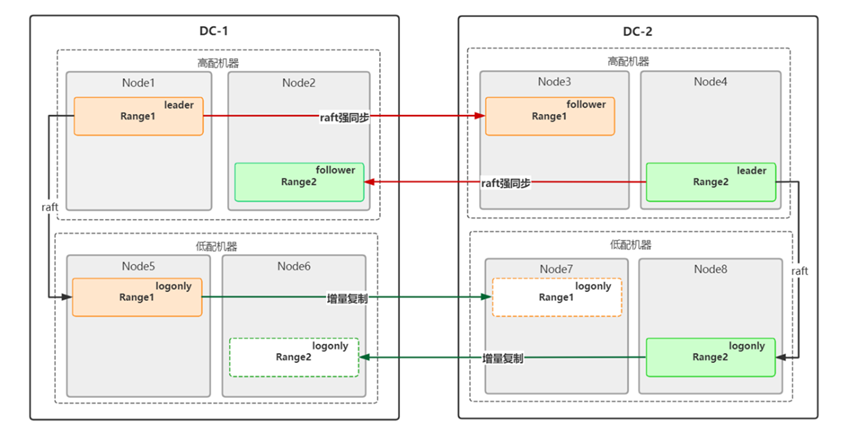
图5. 日志型副本异地重启之部署模式(node内的实线框表示实际运行的副本,虚线框表示复制的数据)
● 容灾处理:遭遇数据中心级别的故障失去两个副本(一个全能型、一个日志型)时,在另一个数据中心基于增量复制得到的日志数据手动重新启动存放日志型副本的节点,集群可用性得到恢复。
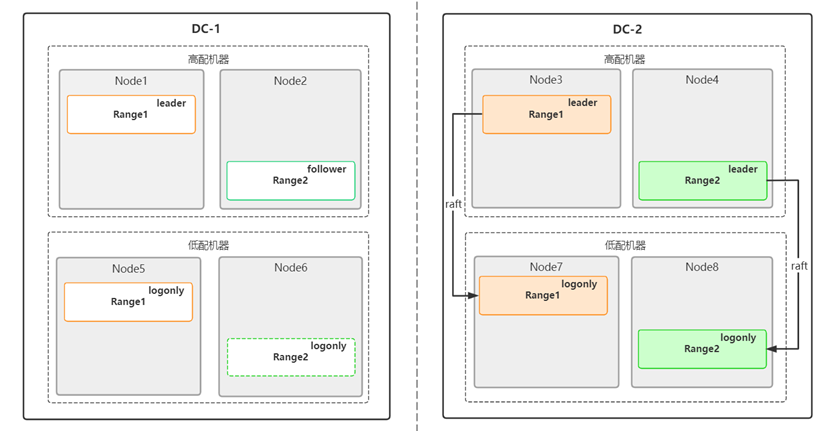
图6. 日志型副本异地重启之容灾处理
4. non-voter副本特性
(1)存储raft日志和用户数据。
(2)没有投票权,不可以当选为raft leader和lease holder。
(3)提供learner read一致性读服务。
用于learner read调优的系统参数:
kv.closed_timestamp.target_duration:更新Closed Timestamp的时间间隔,默认3s
kv.closed_timestamp.learner_read_retries:learner read失败后的重试次数,默认8次
Part 2 - Configure Zone用法
1. 云溪数据库的最小数据分片单位是range,通过configurezone来控制range大小、GC时间和副本分布。
2. Configurezone语法
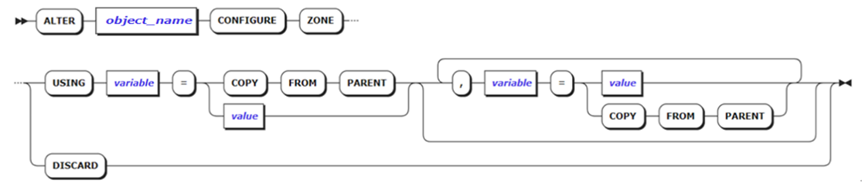
图7. Alter Configure Zone语法图
● object_name:包括database、table、index、partition和range的名字。
● COPY FROMPARENT:拷贝父级别object该字段的值。
● DISCARD:清空configure zone。
3. 副本相关字段
(1)num_replicas:全能型副本数量。
(2)num_logonlys:日志型副本数量。
(3)num_columns:列存副本数量。
(4)constraints:全能型副本约束列表,配合locality、attrs等节点启动参数使用。默认是空,副本将随机均匀分布。
● 启动参数格式:
--locality=key1=value1, key2=value2, …
--store=storedir, attrs=attr1 :attr2: …
● constraints的两种格式:
(i)constraints='[+(-)key1=value1,+(-)key2=value2, …,+(-)attr1,+(-)attr2, …]'
用例:'[+region=US, -dc=dc1,+ssd]'表示把所有全能型副本放到region=US、dc≠dc1、ssd的store上。
(ii)constraints='{"+region=west,+raid": 2, "+region=east,+dc=dc3,+ssd":1}'表示在region=west、raid的store上放2个副本,在region=east、dc=dc3、ssd的store上放1个副本
(5)logonly_constraints:日志型副本约束列表,用法同constraints。
(6)column_constraints:列存副本约束列表,用法同constraints。
(7)lease_preferences:lease holder偏好约束列表。
格式:'[[+(-)key1=value1,… ,+(-)attr1, …], [+(-)key1=value2, … ,+(-)attr2,…], …]'
用例:'[[+region=east],[+region=west,-dc=dc3,+ssd]]'表示若region=east的store上有全能型副本,就选取其中一个成为leaseholder;否则,如果region=west、dc≠dc3、ssd的store上有全能型副本,就选取其中一个成为leaseholder;如果没有符合上述约束的全能型副本,就会自动分配。
(8)strong_synchronizations:强同步副本约束,格式与lease_preferences相同,区别是所有符合该约束列表的副本全部配置为强同步副本。
用例:strong_synchronizations='[[+region=east], [+region=west,-dc=dc3,+ssd]]'
将region=east和region=west、dc≠dc3、ssd的store上的副本配置为强同步副本;
strong_synchronizations= '[[+region=east]]'取消其中一个强同步配置;
strong_synchronizations='[]'取消所有强同步配置。
4. configure zone特性
(1)默认继承:所有未配置或被清空的configure zone,默认继承父级别的configure zone,没有父级别则继承range default的configure zone。
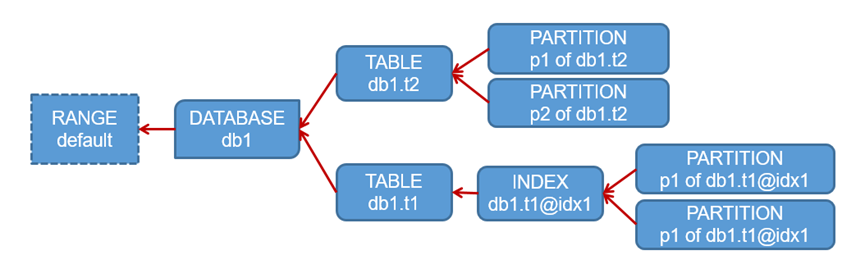
图8. Configure zone继承关系示例
(2)增量修改:alter configure zone语句包含的字段会被修改,不包含的字段保持不变。
(3)副本变更检测:负责控制副本变化的ReplicateQueue扫描所有range,逐个检查是否需要副本变更;此外,当检测到某个range的configure zone的副本相关字段被修改时,会直接触发这个range的副本变更,从而加速修改的生效。
(4)顺序配置:6个voter副本数量、约束相关的字段的配置必须遵循下图的拓扑顺序。
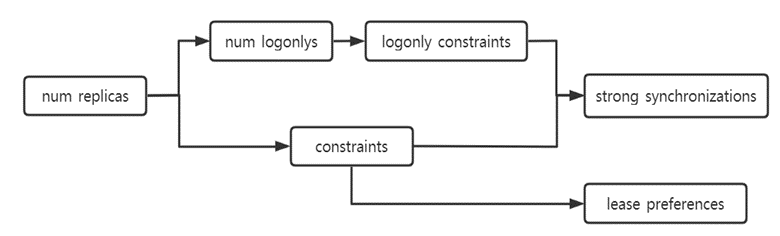
图9. Configure zone配置的拓扑顺序
(5)错误检查:
● num_replicas的最小值是1。
● num_replicas必须大于num_logonlys。
● num_replicas + num_logonlys等于1或大于等于3。
● constraints约束的副本总数不能超过num_replicas,logonly_constraints约束的副本总数不能超过num_logonlys。
● strong_synchronizations的约束项必须出现在constraints或logonly_constraints中。
● 约束中出现的key=value或attr至少匹配一个node/store。
● range_min_bytes和range_max_bytes必须同时配置。
(6)关联继承:为防止configure zone通过继承跳过错误检查造成混乱,num_replicas、num_logonlys、constraints、logonly_constraints、strong_synchronizations字段全部为空,这些字段才能继承自父级别。
5. 一些特殊range及其configure zone的默认值。
● range default:默认配置,不对应实际的range。3副本,GC时间90000s 。
● range meta:元数据,rangeID=1。默认5副本,GC时间3600s 。
● range liveness:节点存活状态,rangeID=2 。默认5副本,GC时间600s 。
● range system:系统,rangeID=3、5。默认5副本,GC时间90000s 。
● range timeseries:时序数据,rangeID=4。默认未配置。
● database system:system数据库。默认5副本,GC时间90000s 。
● table system.jobs:jobs表。默认5副本,GC时间600s。
6. 查看已配置的Configure zone

图10. 查看ConfigureZone的语法图
● object_name:包括database、table、index、partition和range。
● Show all zone configurations; 查看所有已配置的configure zone。
7. 查询副本分布、configure zone生效情况
(1)show experimental_ranges from table table_name;

图11. 查看指定table的range情况
(2)select * from zbdb_internal.ranges;
(注:该语句会查询到已删除但未GC的range。)

图12. 查看所有range情况
Part 3 - 副本变更
1. 副本变更通过replicateQueue完成
(1)基于现有的副本情况,得到have(已有副本数)、deadReplicas(死亡副本)、decommissionReplicas(退役副本)。
(2)基于可用的node数量和configure zone,计算need(需要副本数)。
(3)基于have、need、deadReplicas、decommissionReplicas计算应进行哪种变化——增加、删除、还是均衡。

图13. 计算应进行哪种副本变更的决策树
(4)在配置了奇数个voter时,会避免形成偶数个voter的局面。
(5)存活voter少于半数时无法进行副本变化。
2. 副本均衡的机制:比较是否有更好的位置可以添加副本替换现有副本。比较标准按优先级排列如下:
(1)副本位置满足约束
(2)磁盘余量大小
(3)副本是否是必要的
(4)diversity评分——副本越分散,评分越高
(5)converge评分——range数趋于平均值,评分越高
(6)balance评分——综合range数、磁盘使用情况、QPS计算得出
(7)Range数——越少越好
3. 多种类型副本的增删与均衡
(1)副本不能在全能型副本、日志型副本和列存副本之间直接转换类型。
(2)当出现多种类型副本不满足配置的副本数量/约束,且某种类型副本占用了其他类型副本的位置时,需要一个额外的空余节点进行副本的增删和均衡。
(3)node数量不足时优先满足全能型副本。
Part 4 - Range分裂与合并
1. 触发Range分裂的条件
(1)新建数据库、表等。
(2)Range大小超过range_max_bytes。
(3) Range QPS过高:QPS大于kv.range_split.load_qps_threshold(默认值250,可配置),range列入分裂候选。
(4)修改index或partition的configurezone使其从父级别中独立出来。
(5)导入大量数据时会自动分裂成多个range。
(6)导入数据时会为后续可能导入的数据预分裂出一个空白range。
(7)手动分裂:alter table table_name split at values(key1,key2, …)
values为主键值,若为联合主键可写多个,不能超过主键列数。
2. Range分裂对副本的影响
(1)如果分裂发生在一张表内部,且不是修改index、partition的configurezone导致的分裂:新分裂出来的range初始化时副本数量、位置、类型以及强同步配置保持不变。
(2)其他情况:新分裂出来的range初始化时保持voter副本数量、位置不变,但全部为全能型副本,不含non-voter副本和强同步标记。如有需要,再根据这个range对应的configure zone进行副本变更。
3. Range合并的条件

图14.range合并需要满足的条件
使用如下命令禁用merge:
SET CLUSTERSETTING kv.range_merge.queue_enabled = false;
|








- 上一条: 全网最全-网络模型低比特量化 2022-02-25
- 下一条: 一文带你认识30个重要的数据结构和算法 2022-02-25
- 浪潮云溪数据库--关于副本的功能特性和使用方法 2022-02-25
- MongoDB 4.4 主要新特性解读 2021-06-24
- 带你熟悉鸿蒙轻内核Kconfig使用指南 2021-12-29
- 教你3种Kafka的指定副本作为Leader的实现方式 2022-03-04
- 从 async 和 await 函数返回值说原理 2021-08-11


