基于OpenStack Ironic与DPU的网易数帆裸金属方案实践
背景
目前,所有号称性能损耗小的VM技术,实际上都会有5-15%甚至更高的损耗。作为替代方案,如Gartner在2015年发布的报告“Market Trends: The Rise of Bare-Metal Cloud and Containers”预测的一样,在虚拟化蓬勃发展了多年以后,裸金属(Bare Metal)产品已几乎成为云平台的标配。目前主流的云平台,国外的比如AWS、Azure, 国内的比如阿里、腾讯、华为等,都有裸金属业务。
所有的裸金属服务中,AWS和阿里的比较相似,均采用了专有的硬件和配套的Hypervisor,GuestOS依然运行在Hypervisor上,但是GuestOS可以直接访问存储和网络等硬件;腾讯和华为则是不使用Hypervisor的BMS系统,比如腾讯裸金属2.0就是将云核心能力在智能网卡架构体系下进行了升级和进化。
在网易内部,大部分业务都已经跑在云上,背后是云主机和容器的支撑。但是目前仍然有部分业务不适合直接运行在虚拟化层上,比如高性能的计算集群,对性能要求更高的数据库主机等等。我们一方面希望物理服务器能做到像云主机一样的高效生命周期管理, 同时也希望服务器能提供更高的网络和计算性能。因此,裸金属服务的研发在网易数帆同样成为刚需。我们希望裸金属服务产品能够实现:
第一,完全兼容现有的云主机平台和VPC网络。
第二,极致的网络和计算性能。
第三,自动化运维管理,分钟级别的交付。
方案选择
管控面
OpenStack 作为业内成熟、实用验证、广泛部署的云基础设施公共服务软件组件集,为虚拟机、裸金属和容器提供实施简单、可大规模扩展、标准统一的云计算管理平台。Ironic 是 OpenStack 下用于提供裸金属服务器管理的一个子项目。它可以独立部署,用于裸金属服务器的部署与管理;也可以作为 OpenStack 的一部分来使用,与 OpenStack Nova、Keystone、Glance 等服务集成,使得裸金属服务器实例无缝接入现有的云主机平台,提供与云主机服务一致的使用体验。这里的Ironic的地位就相当于libvirt在传统虚拟化环境中扮演的角色。与libvirt对应的是,Ironic结合多个厂商的物理机驱动提供出来一套hypervisor API来操作物理机。
基于现有业务自身的特点以及当前私有云环境的控制面管理方案,我们选择了在开源基础上进行二次开发,使用 Ironic 与 OpenStack 相关服务集成的方式作为裸金属服务产品的管控面。
数据面
数据面的选择比较多, 比如我们的第一代裸金属服务器方案选择了“物理机服务器+普通网卡”的形式,裸机侧和VPC侧虚拟机通过专线的形式对接。这种方案的优点在同时提供了物理机的性能和虚拟机的可扩展性和灵活性;缺点在于运维和部署复杂,成本太高,同时接入VPC网络有很多规模上的限制,没法提供更高的网络性能。
最近两年风靡业界的智能网卡,则是另外一种方案。 随着网络、存储等IO的处理带宽增加,底层基础设施Workload所占的CPU资源越来越多,留给用户应用的CPU资源越来越少,而DPU则比智能网卡更进一步,除了把存储、网络等功能做硬件卸载加速外,还能把基础设施层的所有任务都从Host CPU转移到DPU或IPU中,把CPU完整的交给业务应用,达到了业务和管理分离。
目前市场上可供选择的智能网卡厂商主要以 NVIDIA(英伟达), 英特尔(Intel), 博通(Broadcom)为主,在我们2020年初开始做智能网卡方案调研时,BlueField DPU是为数不多可供选择的智能网卡之一。其中的BlueField-1 基于ConnectX5 设计,支持ASAP2加速,可以把网络相关Workload卸载到eSwitch。BlueField-2则基于CX6-DX, 在一代网卡的基础上做了功能和性能的增强 ,同时提供了1Gbps的带外管理接口,提升了网卡本身的运维管理功能。
关键技术
Smart NIC都拥有一套自己独立的网卡系统,如下图所示,我们可以将SDN Agent,OVS等都跑在这套网卡系统上,并通过Agent将网络规则offload到网卡。
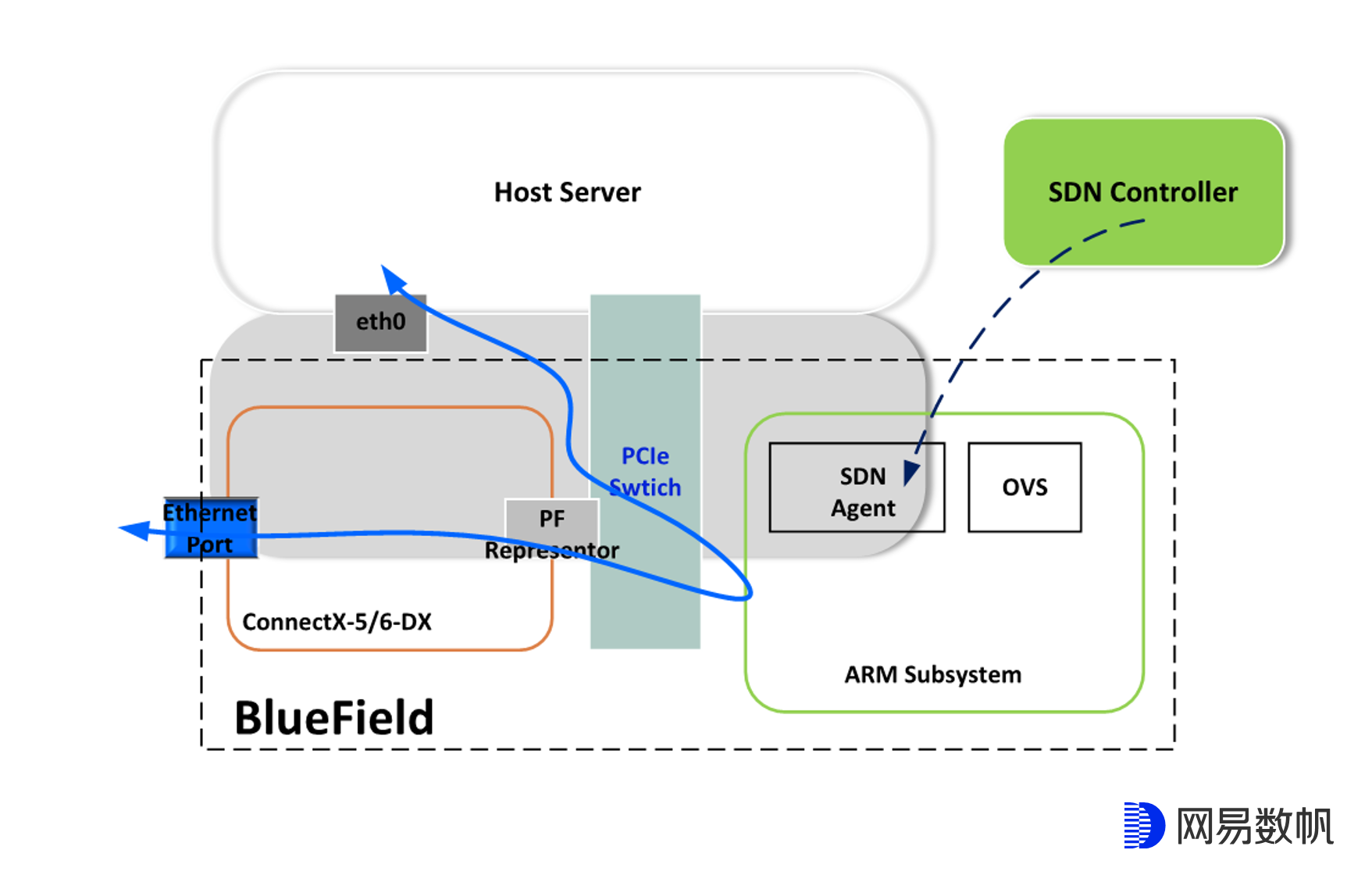
BlueField Smart NIC 提供了两种网卡模式:
- Separated Host 模式。在这种模式下,主机服务器和 NVIDIA BlueField DPU 可以作为 multi-host 共享内置网卡。在这个模式下并未启用 NVIDIA BlueField DPU 的卸载功能。(后面的文章描述中统称为普通网卡模式)
- Embedded ( ECPF – Embedded CPU Physical Function )模式。在这种模式下,主机服务器的网络工作负载卸载到了 NVIDIA BlueField DPU,并启用了 ASAP2 ( Accelerated Switch and Packet Processing )加速功能。(后面的文章描述中统称为智能网卡模式)
这两种模式之间的切换可以通过如下命令来进行:
# 切换到智能网卡模式(bluefield2 要把设备名称换成mt41686)
mlxconfig -y -d /dev/mst/mt41682_pciconf0 s INTERNAL_CPU_MODEL=1
# 切换到普通网卡模式
mlxconfig -d -y /dev/mst/mt41682_pciconf0 s HIDE_PORT2_PF=0
我们的目标是纳管并统一调度物理服务器,并将其接入现有的VPC网络,那么在Openstack Ironic + BlueFiled的裸金属方案里,我们需要解决几个关键问题:
- 如何将智能网卡裸机节点接入现有的VPC网络?
- 如何达到最优的网络性能?
- DPU有自己的Subsystem,一般需要按照需求对其进行改造定制,子系统的安装时机与安装方法?
VPC网络接入
在网易云计算的VPC架构中,主要存在着以下几种网络:
- 业务网络。 该网络用于承载租户的业务流量。
- 管理网络。 该网络用于承载管理流量和控制流量。
与Openstack Neutron网络不同,我们的VPC架构是自研的,不存在二层的流量,无论是同子网内部还是跨子网之间,或者是访问外网的所有流量均走三层, 节点之间的流量通过VXLAN隧道,虚拟机的ARP和DHCP由本地计算节点代答, 所以流量模型非常简单。前文提到,BlueField有两种工作模式,只有在智能网卡模式下才能达到最好的网络性能,而为了最大限度的使用网卡带宽,我们也需要将BlueField上的两个上联口做bond。最后我们得到下面的网络拓扑:
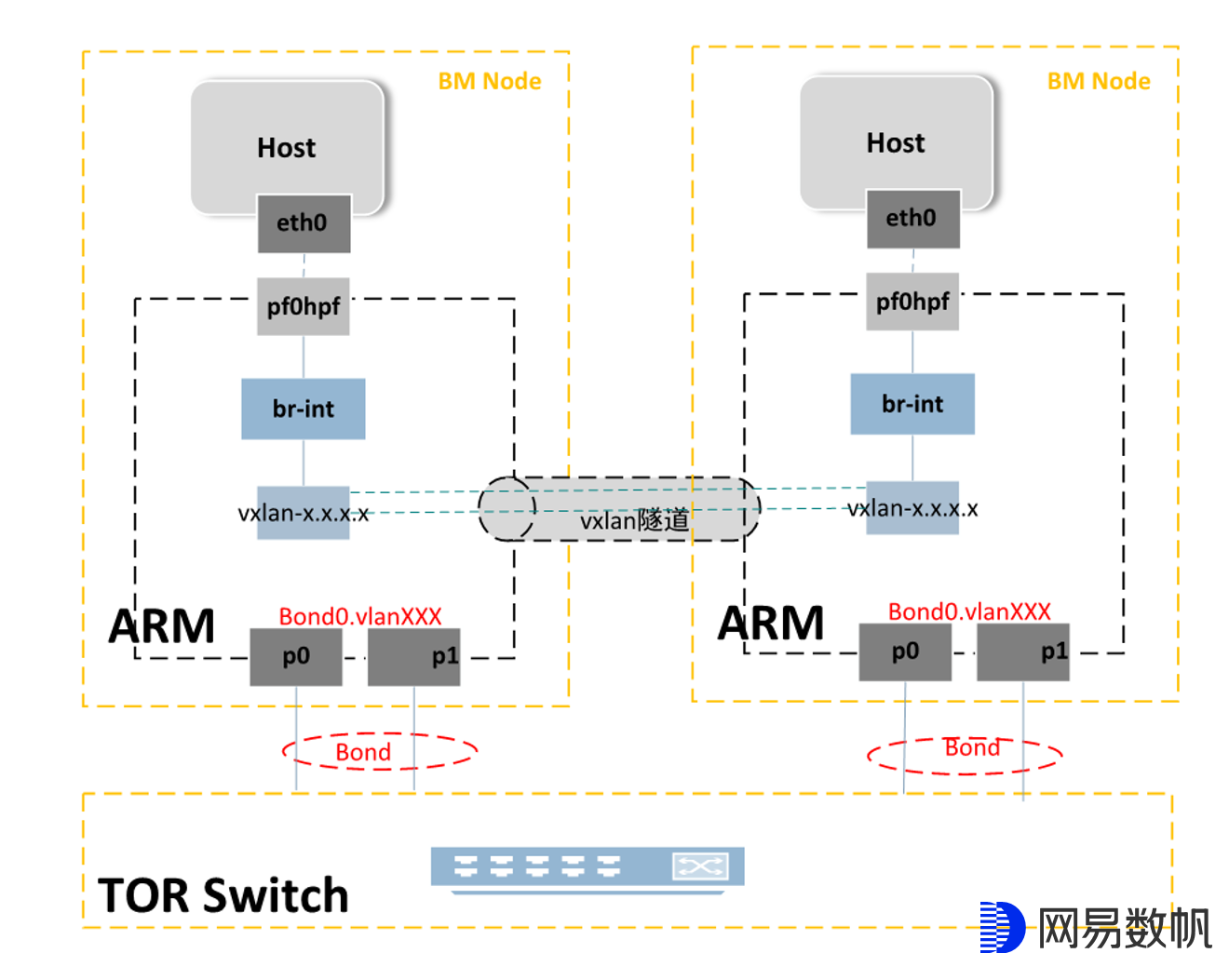
智能网卡模式下HOST上的每一个网口会对应DPU上的一个representor口,但是我们看到只画了HOST上的eth0与其representor口的互联。这并不是画图的时候偷懒了,而是bond模式下无论将pf0hpf/eth0或者是pf1hpf/eth1接入都能达到一样的效果,此时HOST上实际能使用的最大带宽依旧是p0+p1两个网口的总和。
另外我们还能通过下面的命令让HOST上只显示一个网卡:
mlxconfig -d /dev/mst/mt41682_pciconf0 s HIDE_PORT2_PF=1 #在HOST上只显示一个网口
在实际测试过程中发现, 如果在HOST上修改网卡MTU等特性,实际会影响DPU上的p0和p1两个口的属性,所以我们一般还需要通过如下命令来禁用HOST上网卡的部分权限:
mlxprivhost -d /dev/mst/mt41682_pciconf0 r --disable_port_owner #在HOST上禁用网卡的一些权限
DPU系统安装
智能网卡出厂的时候,一般会有个默认的系统, 但是大部分客户都有一些自己特定的需求,需要对其进行定制,比如换成Debian系统,比如安装java虚拟环境package等等。另外,就算是默认系统能符合要求,我们也需要在DPU的ARM Subsystem上做一些网络配置,安装特定的SDN Agent才能让网卡工作。
BlueField DPU用户手册里提供了两种安装ARM 子系统的方式,一种是PXE方式,需要在HOST设备搭建一个pxe Server; 另外一种是nonePXE方式,通过在HOST上加载BlueField的rshim驱动,通过rshim pcie的方式来进行安装,命令行如下:
cat installcentosXXX.bfb > /dev/rshim0/boot
我们这里采用的是nonePXE方式。但此时还有两个问题:
- 问题1:裸机节点上的HOST系统是属于业务方的, ARM子系统安装的时候,HOST系统还未安装,怎么才能用rshim pcie的方式给ARM装系统?
- 问题2:裸机节点上除了DPU网卡外,不额外加其他的网卡,HOST系统安装时网络如何配置?
对于第一个问题,Ironic给我们提供了一种思路。目前,在OpenStack体系结构中,Ironic还是通过Nova来调用的,模拟Nova的一个虚拟化驱动(其它的虚拟化驱动还有KVM、VMware、Xen等),实现基于Ironic的虚拟化驱动。 对Nova而言,通过Ironic部署物理机,和部署虚拟机的调用流程是一样的,都是通过Nova的接口来执行创建实例,只是底层的nova-scheduler和nova-compute驱动不一样,虚拟机底层驱动采用的是虚拟化技术,而物理机采用的是PXE和IPMI技术。因此,我们可以采用安装裸机HOST系统类似的方式,先通过PXE 安装ramdisk小系统(需要安装rshim驱动和BlueField的ofed驱动),然后通过网络获取DPU ARM Subsystem镜像文件,此时就可以通过nonePXE的方式来实现DPU系统安装了。
在裸机部署的整个生命周期中,大致分成3个阶段:
- register裸机节点,节点UUID信息会被用于后续的裸机生命周期管理,注册时可以选择裸机驱动方式。
- inspect获得裸机节点的硬件信息(包括CPU,内存,硬盘,网卡等)以及上联的交换机信息,其中的硬件信息会被用做 Nova Scheduler 的调度因子。
- deploy安装裸机系统。即用户根据业务需要指定镜像、网络等信息来部署裸金属实例。由云平台自动化完成资源调度、操作系统安装、网络配置等工作。
物理机系统安装的时间一般都比较长,至少都是分钟级别的,所以为了提升用户体验,给DPU安装系统就需要放在deploy阶段之前,我们这里选择直接放在inspect阶段,大致流程如下图所示:
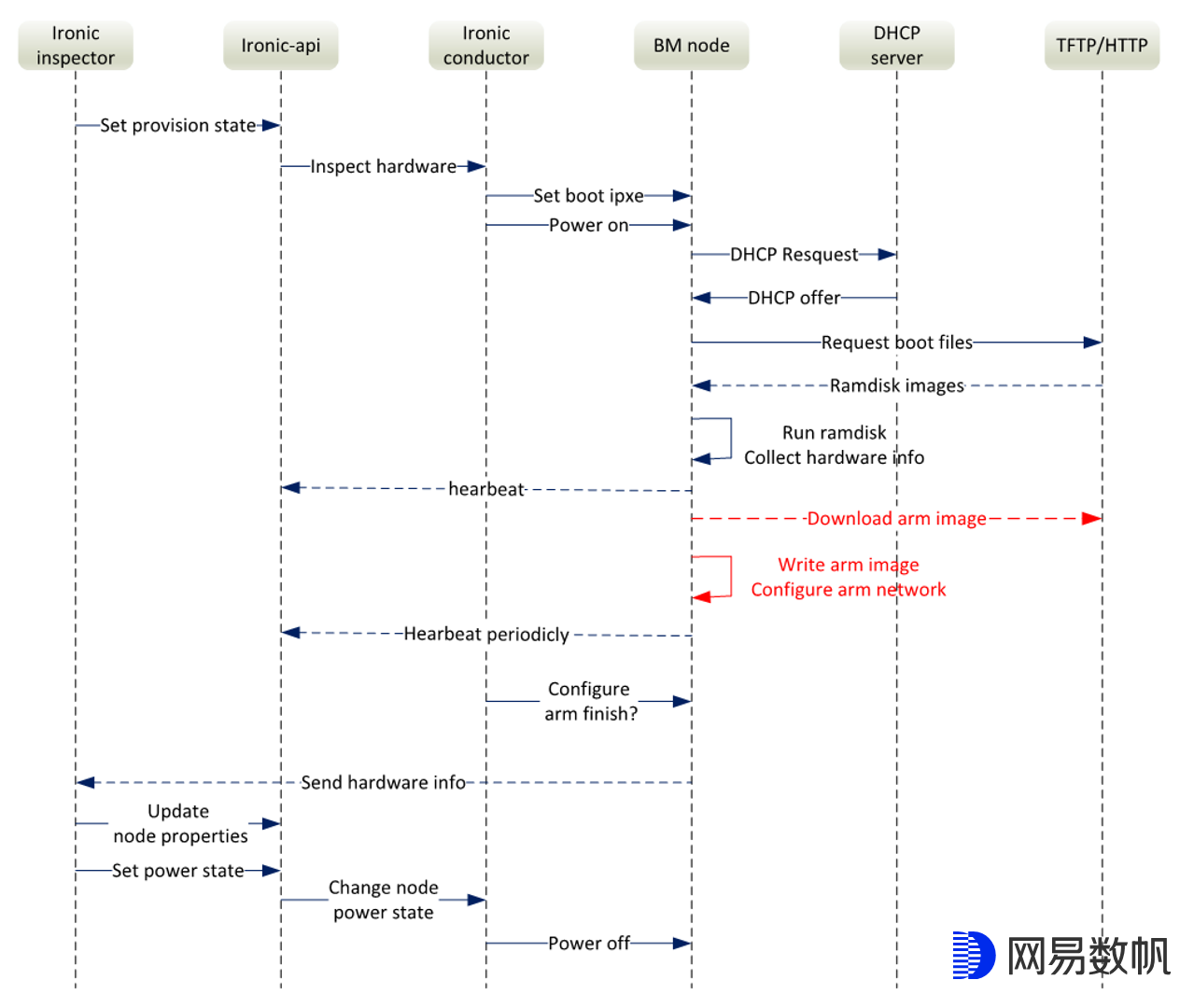
除了给网卡安装系统外,其他的流程与社区的Ironic inspect基本一致。ironic-inspector 发起请求,ironic conductor收到请求后通过IPMI 给裸机节点设置PXE启动并开机,接下来就是DHCP 获取IP并从HTTP Server获取带IPA(Ironic Python Agent)的ramdisk镜像。通过ramdisk image里带的内核参数,从HTTP Server下载指定的网卡镜像,安装完毕后通知Ironic inspect结束整个流程。
DPU上的网络配置,SDN Agent package安装都可以在这个阶段完成。DPU系统安装完成后,在HOST上配置SNAT,就可以让DPU ARM子系统通过HOST网络来访问外网,得到想要的package和相应的配置。
对于问题2,如果只是想给HOST安装一个系统,那么有了前面提到的ramdisk小系统,还是有比较简单的方式,比如download host镜像后,直接dd到根磁盘上。但不管是给DPU安装系统,还是给HOST安装系统,都绕不开一个核心的问题,PXE 方式需要网络支持。什么样的网络部署模式才能既满足业务的高性能网络要求,又能满足装机要求?
网络部署架构
使用iPXE方式来安装系统,网络中会有如下几种报文:
- DHCP报文,用于给网卡获得IP地址;
- TFTP报文,用于获得ramdisk小系统的镜像;
- HTTP报文,用于与管控通信,以及获得host系统的镜像等等;
前面提到,只有处于智能网卡模式的DPU才能获得最优的网络性能,因此装机时有几种方案可供考虑:
-
系统装机时与用户的正常业务流量都使用智能网卡模式,并且都使用vxlan overlay隧道;
-
系统装机时与用户的正常业务流量都使用智能网卡模式, 但是要区分装机网络流量和用户的正常业务流量。
装机网络流量走underlay,用户业务流量走vxlan overlay;
-
系统装机时流量走普通网卡模式,用户的正常业务流量走智能网卡模式。
PXE方式安装系统时,报文都是普通的DHCP,UDP和TCP报文,所以要区分流量是不是属于用户的业务报文,这个不太现实;如果不做报文区分,PXE装系统时和业务流量使用同一套流表,那就需要在overlay环境中部署一套PXE专属的服务(DHCP server,http server等),基于网易云计算现有的部署架构和实现方案,这个实现起来难度太大;如果PXE装机流量使用一套流表, 而用户业务流量使用另一套流表,实际验证下来发现在智能网卡模式下给DPU安装ARM Subsystem时,网络会断开。
BlueField DPU网卡在出厂时,默认是普通网卡模式。因此,我们最后选用了方案三,装机时与用户正常使用时使用不同的网卡模式,只有在HOST 系统deploy成功开启业务流量时,才使用智能网卡模式,其他情况下都使用普通网卡模式。

如上图所示,处于普通网卡模式的HOST,DPU上不会存在representor口。将两个网口都接入TOR交换机,交换机上做bond,HOST上不做bond,但需要交换机上开启LACP edge port功能,此时HOST上的任意一个网口都能通过DHCP获取到IP地址。
这种方案下,智能网卡裸机节点部署就存在3种网络:
- 业务网络。 该网络的用途在于将裸机节点接入VPC,承载租户的业务报文。
- 管理网络。 该网络的用途在于管理裸机节点,承载管理流量和控制流量。
- 部署网络。 用于在inspect和deploy过程中与控制节点进行通信,比如从HTTP Server下载镜像。
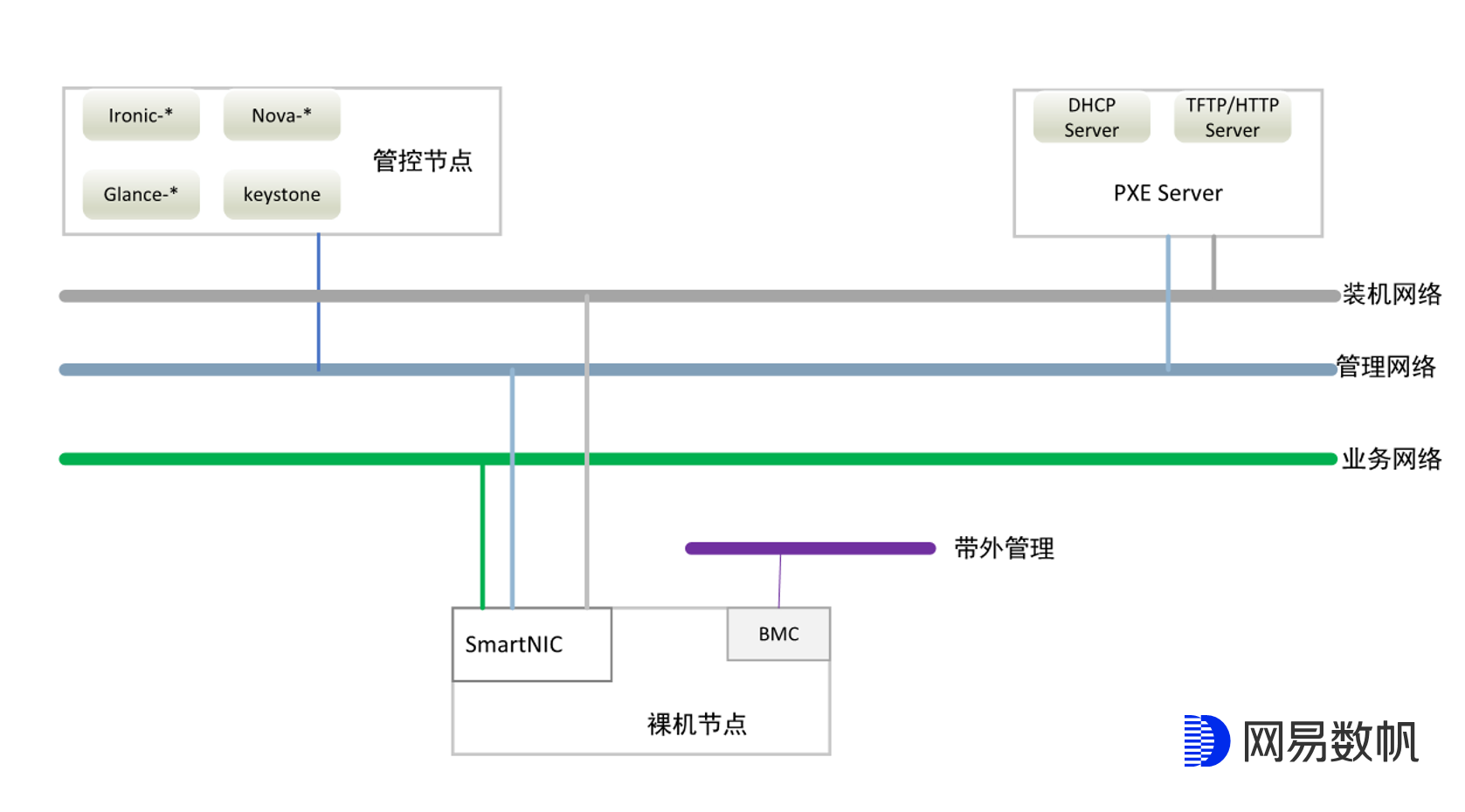
如上图所示,业务网络是overlay报文,用VXLAN来进行承载; 部署网络和管理网络是underlay报文, 这3种网络处于不同的VLAN内。装机网络用access接入,这样在使用PXE装机的时候就可以不用去配置VLAN,直接从与部署网络直连的DHCP Server为裸机节点获取到IP,并通过该IP与管控节点,HTTP Server等进行通信; 管理网络和业务网络用trunk接入,在DPU ARM Subsystem上分别配置不同的vlan子接口。
这种方案下,我们无需再去通过netconf更改交换机配置,只需要在机器上架时将与裸机直连的TOR交换机配置为trunk allow (部署网络VLAN,业务网络VLAN, 管理网络VLAN), 并配置trunk pvid为部署网络vlan即可。
总结
使用NVDIA BlueField1 25Gbps双口网卡(实际接10G交换机),用iperf2来简单测试两台裸机节点间的带宽和PPS,带宽18.3Gbps,pps 1100万,同样的测试方法用于82599网卡的物理服务器上测试差不多是600万的PPS。由此可见,在使用DPU将数据报文offload后,性能上确实还是提升了不少。当然,在测试过程中也发现了一些问题,比如TCP短连接的性能问题,offload之后的报文无法直接通过tcdump来抓包,DPU子系统安装时间过长等等,都需要后续做进一步的优化。
总体来说,裸金属产品内嵌到自己的产品体系,形成闭环,和已有的产品打通,兼容已有的API只是第一步;由于DPU的发展还处在初期阶段,而且DPU网卡的价格相比于普通网卡售价偏高很多,因此若能让产品功能更稳定,性能更强大,运维更容易,不断满足客户越来越严苛的要求,同时还能形成成本上的优势,则DPU与裸金属服务器的发展一定会大放异彩。
本文作者:网易数帆网络技术团队
|








- 上一条: 分布式训练硬核技术——通讯原语 2022-02-17
- 下一条: 微服务从代码到k8s部署应有尽有系列(十、错误处理) 2022-02-18
- 网易数帆基于 Envoy 的云原生网关实践 2022-01-06
- OpenShift 与 OpenStack:让云变得更简单 2022-03-24
- IstioCon 回顾 | 网易数帆的 Istio 推送性能优化经验 2022-05-20
- 慎思笃行——网易数帆开源这一年 2022-01-04
- 网易数帆王佰平:我的 Envoy Maintainer 之路 2022-04-21


