两招提升硬盘存储数据的写入效率
如今存储数据的方式有很多,而硬盘因为价格和数据保护方面的优势,是大部分用户的首选。但是,硬盘和内存相比在 IO 读写上慢了好几个数量级,那为什么会更偏好硬盘呢?
首先需要提到的是,操作磁盘之所以慢主要是因为对磁盘的读写耗时。读写主要有三部分耗时: 寻道时间+旋转时间+传输时间,其中寻道时间是最久的。因为寻道需要移动磁头到对应的磁道上,通过马达驱动磁臂移动,是一种机械运动因此耗时较长。同时我们对磁盘的操作通常都是随机读写,也就需要频繁移动磁头到对应的磁道,这就让耗时延长了,显得性能比较低。
这样看来如果要让磁盘读写速度变快,只要不使用随机读写,或者减少随机的次数,就可以有效提升磁盘读写速度了。那具体要如何操作呢?
顺序读写
先来聊聊第一个方法,如何使用顺序读写,而不是随机读写?上面提到寻道时间是耗时最久的,所以最直观的思路就是省去这部分时间,而顺序 IO 正好可以满足需求。
追加写就是一种典型的顺序 IO,使用这个思路优化的典型的产品就是消息队列。以热门的 Kafka 为例,Kafka 为了实现高性能 IO,用了很多优化的方法,其中就使用了顺序写这种优化方法。
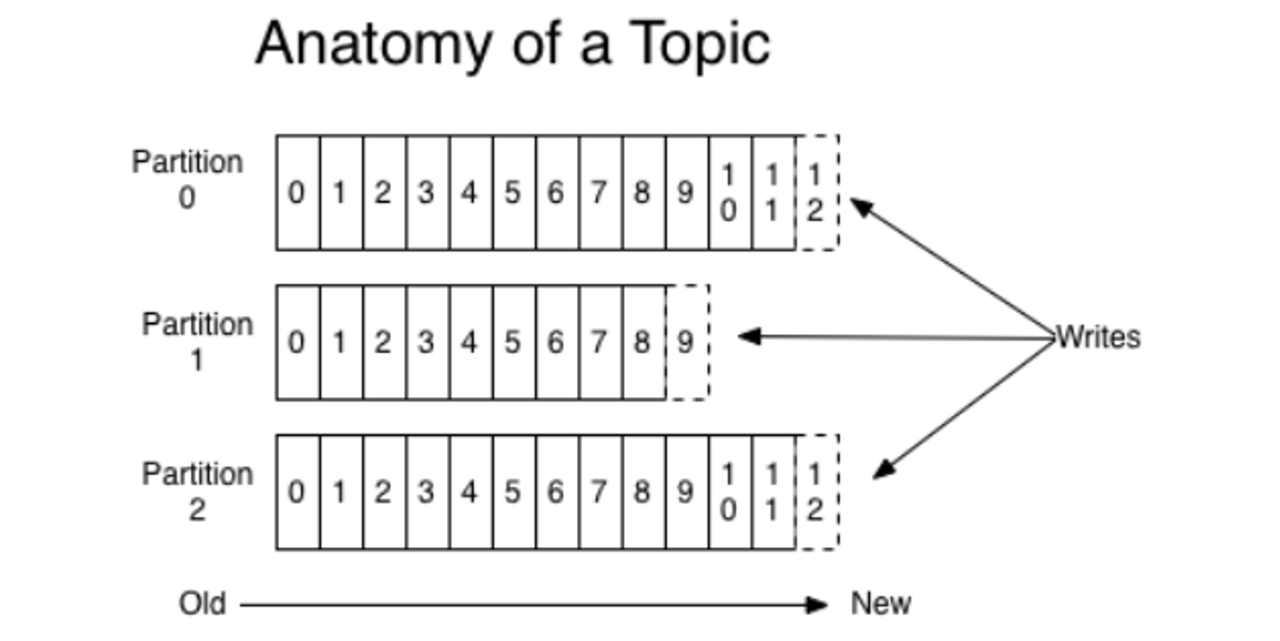
Kafka 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。对于每个分区,它把从 Producer 收到的消息,顺序地写入对应的 log 文件中,一个文件写满后,才开启一个新的文件。消费的时候,也是从某个全局的位置开始,也就是某一个 log 文件中的某个位置开始,按顺序地读出消息。
减少随机次数
看完了顺序方式,我们再来看看减少随机写次数的方法。在很多场景中,为了方便我们后续对数据的读取和操作,我们要求写入硬盘的数据是有序的。比如在 MySQL 中,索引在 InnoDB 引擎中是以 B+ 树方式来组织的,而 MySQL 主键是聚簇索引(一种索引类型,数据与索引数据放在一起),既然数据和索引数据放在一起,那么在数据插入或者更新的时候,我们需要找到要插入的位置,再把数据写到特定的位置上,这就产生了随机的 IO。所以,如果我们每次插入、更新数据都把数据写入至 .ibd 文件的话,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高,数据库的性能和效率都会大打折扣。
为了解决写入性能问题,InnoDB 引入了 WAL 机制,更确切的说,就是 redo log。下面我再简单介绍下 Redo Log。
InnoDB redo log 是一个顺序写入的、大小固定的环形日志。主要作用有两个:
-
提高 InnoDB 存储引擎写入数据的效率
-
保证 crash-safe 能力
在这里我们只关心它是如何提高写入数据的效率的。下图是 redo log 的示意图。

从图中可以看出,red olog 的写入是顺序写入的,不需要找到某一个具体的索引位置,而是简单地从 write-pos 指针位置追加。
其次当一个写事务或者更新事务执行时,InnoDB 首先取出对应的 Page,然后进行修改。当事务提交时,将位于内存中的 redo log buffer 强制刷新至硬盘中,如果不考虑 binlog 的话,我们可以认为事务执行可以返回成功了,写入 DB 的操作由另外的线程异步进行。
再然后,可由 InnoDB 的 Master Thread 定时地将缓冲池中的脏页,也就是上面儿我们修改的页,刷新至磁盘,此时被修改数据真正的写入至 . ibd 文件。
总结
很多时候,我们不得不把数据存储到硬盘上,但是由于硬盘相对于内存来说实在是太“慢”了。所以我们就得想办法提升性能。文章里总结了两个方法,第一个是追加写,利用顺序 IO 来实现快速写;第二个是很多数据库中为了提升性能都会引入的 WAL 机制。文章里分别拿了 Kafka 和 MySQL 的 InnoDB 存储引擎举例。除了这两个,感兴趣的同学也可以看下 LSM 树,etcd 等是怎么实现快速写的。
推荐阅读
|








- 上一条: 网易数帆开源iSCSI服务器tgt独门优化,彻底解决性能问题 2022-02-17
- 下一条: 分布式训练硬核技术——通讯原语 2022-02-17
- 查询速度提升两倍,TDengine在GPS服务中的应用 2022-03-01
- 解决两大难题,TDengine 助力亿咖通打造自动驾驶技术典范 2022-04-07
- 应用实践 | 数仓体系效率全面提升!同程数科基于 Apache Doris 的数据仓库建设 2022-07-11
- DevOps 如何帮助前端提升研发效率? 2022-06-27
- 用100行代码提升10倍的性能 2021-07-05


