HDFS用了这个优化后,性能直接翻倍
【背景】
前段时间在HDFS的dn节点规模1000+的环境中,并且有1亿block数据量的情况下, 进行大量并发写文件测试时,发现部分客户端写异常并导致最终仅写入了部分数据,本文就该问题进行分析总结。
【表面现象分析】
出现该问题时,首先查看了客户端的日志,发现这些客户端的日志中,都出现了NotReplicatedYetException的告警日志,其他全部成功写入的客户端中有的也有这样的日志。
既然都出现了这个告警日志,那为什么有的能全部成功写入,有的就直接退出不写了呢?
这个现象背后的原理其实很简单:当客户端写文件过程中,向nn发送申请新的block的rpc请求时,如果nn以错误形式返回NotReplicatedYetException,客户端的rpc处理会根据该错误构造对应的异常并向上抛出异常,接口调用的处理中又会捕获该异常,然后睡眠一段时间,并再次发送申请block的rpc请求。当重试到达一定次数后,仍旧是失败的,那么就不再继续尝试,直接退出。
关键代码如下:
protected LocatedBlock locateFollowingBlock(DatanodeInfo[] excluded,
ExtendedBlock oldBlock) throws IOException {
final DfsClientConf conf = dfsClient.getConf();
// 默认5次
int retries = conf.getNumBlockWriteLocateFollowingRetry();
// 首次重试睡眠时间为 400ms
long sleeptime = conf.getBlockWriteLocateFollowingInitialDelayMs();
while (true) {
long localstart = Time.monotonicNow();
while (true) {
try {
return dfsClient.namenode.addBlock(src, dfsClient.clientName,
oldBlock, excluded, stat.getFileId(), favoredNodes,
addBlockFlags);
} catch (RemoteException e) {
IOException ue =
e.unwrapRemoteException(FileNotFoundException.class,
AccessControlException.class,
NSQuotaExceededException.class,
DSQuotaExceededException.class,
QuotaByStorageTypeExceededException.class,
UnresolvedPathException.class);
if (ue != e) {
throw ue; // no need to retry these exceptions
}
if (NotReplicatedYetException.class.getName().
equals(e.getClassName())) {
if (retries == 0) {
throw e;
} else {
--retries;
LOG.info("Exception while adding a block", e);
long elapsed = Time.monotonicNow() - localstart;
if (elapsed > 5000) {
LOG.info("Waiting for replication for "
+ (elapsed / 1000) + " seconds");
}
try {
LOG.warn("NotReplicatedYetException sleeping " + src
+ " retries left " + retries);
Thread.sleep(sleeptime);
sleeptime *= 2;
} catch (InterruptedException ie) {
LOG.warn("Caught exception", ie);
}
}
} else {
throw e;
}
}
}
}
}因此,虽然有的客户端有告警日志,但都全部成功写入,只能说明出现了重试,但最终还是成功响应;而有的则连续5次均重试失败,导致仅写入了部分数据。
【问题深入】
既然知道了是因为nn对客户端请求block的rpc请求返回了错误,并且是连续多次请求都返回错误,最终引发客户端终止写入,那么nn为什么会一直返回NotReplicatedYetException的错误呢?
这里就涉及到NN中block的状态,以及申请新block的rpc请求处理逻辑了。
在NN内部,每个block的初始状态为underConstruction,然后依次变为committed,最终变为complete。
客户端写同一个文件,申请新的block时,nn默认将上一个block的状态置为committed,等dn通过增量块汇报将block副本的finalized状态上报时,nn将该block的状态置为complete。
另外,nn在处理客户端申请新的block的rpc请求时,需要检查上上一个block的状态是否为complete。如果不是,则返回NotReplicatedYetException。
也就是说,写同一个文件时,在申请第3个block时,会检查第1个block的状态是否为complete,如果不是则返回错误,后面的依次类推。
实际测试过程中出现问题时,必然是前面的block状态不对导致的。
【问题根因】
了解了错误的产生原因之后,自然会追问,为什么nn中block的状态一直没有达到complete状态,是因为dn没有发送增量块汇报请求吗?
然而,从dn的日志来看,确实都有发送增量块汇报的请求。
在问题分析过程中,没有头绪时却注意到了另外一个细节。在整个测试中,在nn的web页面上,看到有部分dn出现了离线的情况。
顺着这个现象进行分析:nn感知dn下线,肯定是心跳超时,而dn的增量块汇报和心跳是在同一个线程中复用同一个tcp连接串行发送的。因此心跳超时,增量块汇报请求肯定也会受影响。
再次测试复现时,发现dn的心跳线程的堆栈卡在发送增量块汇报的函数中,而在nn节点上通过netstat观察对应的tcp连接情况,发现连接的Recv-Q的数值一直很高。查看nn的jmx指标,发现CallQueueLength也一直维持在最大值,由此断定是rpc处理机制引起的问题。
为什么是rpc处理引起的,请继续往下看。
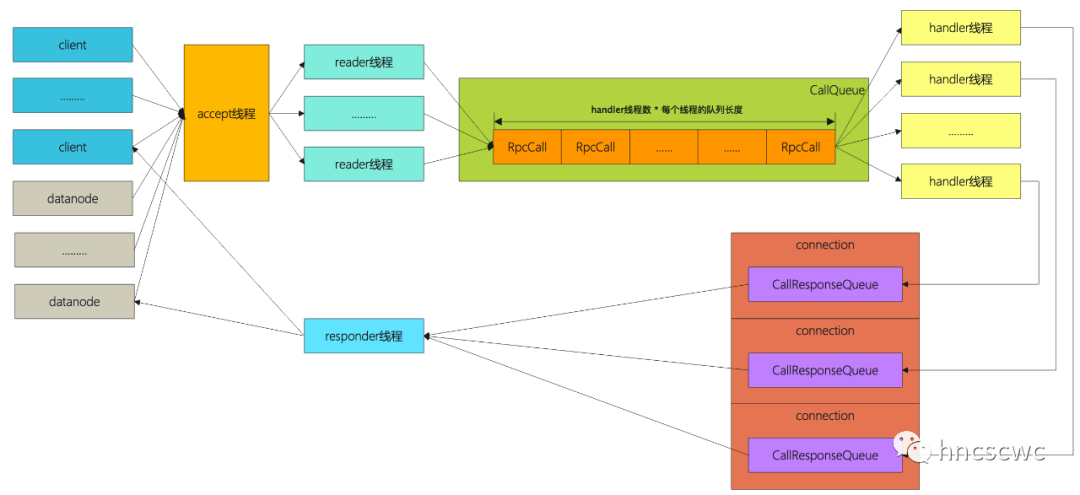
在nn内部,对于每个监听的端口,都有四种类型的线程来处理连接上的请求。
监听线程
负责在指定端口监听,当有新连接到来时,负责完成连接的建立,随后将连接转交给reader线程进行后续的处理。
reader线程
负责连接建立之后,接收该连接上的请求(从socket上读取客户端发送的数据),并请请求封装成callRpc请求对象,然后将请求对象放到请求队列中。
handler线程
通常有多个handler线程,负责从请求队列中取出请求,并进行实际的处理,处理完成后通过连接的socket直接发送请求响应内容,或者将响应内容放到响应队列中。
响应发送线程
负责从响应队列中取出请求对应的响应,然后通过请求对应连接的socket,发送响应内容。
注意:
请求队列的长度是有上限的,具体上限为handler线程的个数乘以每个handler线程的队列长度。
当请求队列达到上限时,reader线程将请求放到队列的动作会被阻塞,继而所有连接过来的请求堆在tcp连接的接收缓冲区中,而不会被处理。
按照默认的配置,10个handler线程,每个线程的队列长度100,那么该监听端口上的请求队列长度为1000。
当有10000的并发写文件时,那么就有10000个申请block的rpc请求,这些请求瞬间将请求队列塞满(nn的jmx指标中CallQueueLenght表示该队列的实际长度),剩余的请求堆积在连接的接收缓冲区中(netstat看到的Recv-Q),等待reader线程读取并处理,并且随着一个block的写完,还会继续写新的block,也就是继续产生新的rpc请求,因此观察nn的jmx指标发现rpc请求队列持续达到最大值。
而dn的增量块汇报请求本质上也是一个rpc请求,这些请求和客户端申请block的请求都发往同一个端口,等待reader线程从连接的接收缓冲区读取,或在请求队列中等待handler线程进行实际处理。
因此就可能出现,某些dn的增量块汇报请求,虽然成功发送,但在连接的接收缓冲区上的请求一直未被reader读取处理。所以,在nn内部block的状态也就没有变化,导致客户端申请新的block时返回错误。同样,也能解释为什么有的客户端出现了离线的情况。
【问题优化】
知道了问题的所在,剩下来就是进行优化了。
首先采用了增加handler线程数的方法。加大请求并发处理,也变相加大了rpc请求队列的长度。这也是网上提得比较多的方案。
然而实际效果却不太理想,因为对于申请block请求的处理,内部有一把大锁锁住,这会导致其他handler线程频繁等锁。因此虽然增加handler线程看是提升了并发处理能力,但是实际多数handler线程都在等锁,导致dn的增量块汇报请求不能及时被处理。其提升的效果不明显。
我们注意到:将dn的增量块汇报请求和客户端申请block的请求混在一个队列中,是无法保证有限处理dn的增量块汇报请求的,因此考虑将其进行分离,即dn的rpc请求和客户端的rpc请求分别发往不同的端口。这只需要在nn上修改相应的配置即可。
端口分离后的测试效果:并发写文件的数量相比分离之前,直接翻倍提升,从并发15000提升到30000+(受限于客户端所在机器的性能,没有继续往上压,实际网络带宽,nn的各项指标表明并发读还可以继续增加),到此问题得到优化解决。
【总结】
来小结一下,本文通过实际测试过程中遇到的问题,结合hdfs中的客户端的请求逻辑、nn内部blocks状态、申请block请求的处理机制、rpc处理机制等原理,一步步进行分析,最终定位问题,并给出优化方案,且优化效果明显。
【你可能感兴趣的文章】
好了,本文就介绍到这里,如果觉得本文对你有些帮助,来个点赞,在看吧,也欢迎分享转发加我微信交流~

本文分享自微信公众号 - hncscwc(gh_383bc7486c1a)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
|








- 上一条: 读 Linux 像读小说「GitHub 热点速览 v.22.03」 2022-01-17
- 下一条: 阿里巴巴DevOps文化浅谈 | 云效 2022-01-17
- 性能提升了200% 2021-08-01
- hdfs——nn的启动优化 2022-01-26
- 带你重走 TiDB TPS 提升 1000 倍的性能优化之旅 2021-12-07
- TiDB 性能分析和优化 2022-06-17
- vivo 万台规模 HDFS 集群升级 HDFS 3.x 实践 2022-05-16


