一行降低 100000kg 碳排放量的代码!

文|张稀虹(花名:止语 )
蚂蚁集团技术专家
负责蚂蚁集团云原生架构下的高可用能力的建设 主要技术领域包括 ServiceMesh、Serverless 等
本文 3631 字 阅读 8 分钟
PART. 1 故事背景
今年双十一大促后,按照惯例我们对大促期间的系统运行数据进行了详细的分析,对比去年同期的性能数据发现,MOSN 的 CPU 使用率有大约 1% 的上涨。
为什么增加了?
是合理的吗?
可以优化吗?
是不可避免的熵增,还是人为的浪费?
带着这一些列灵魂拷问我们对系统进行了分析

PART. 2 问题定位
我们从监控上发现,这部分额外的开销是在系统空闲时已有,并且不会随着压测流量增加而降低,CPU 总消耗增加 1.2%,其中 0.8% 是由 cpu_sys 带来。
通过 perf 分析发现新版本的 MOSN 相较于老版本, syscall 有明显的增加。
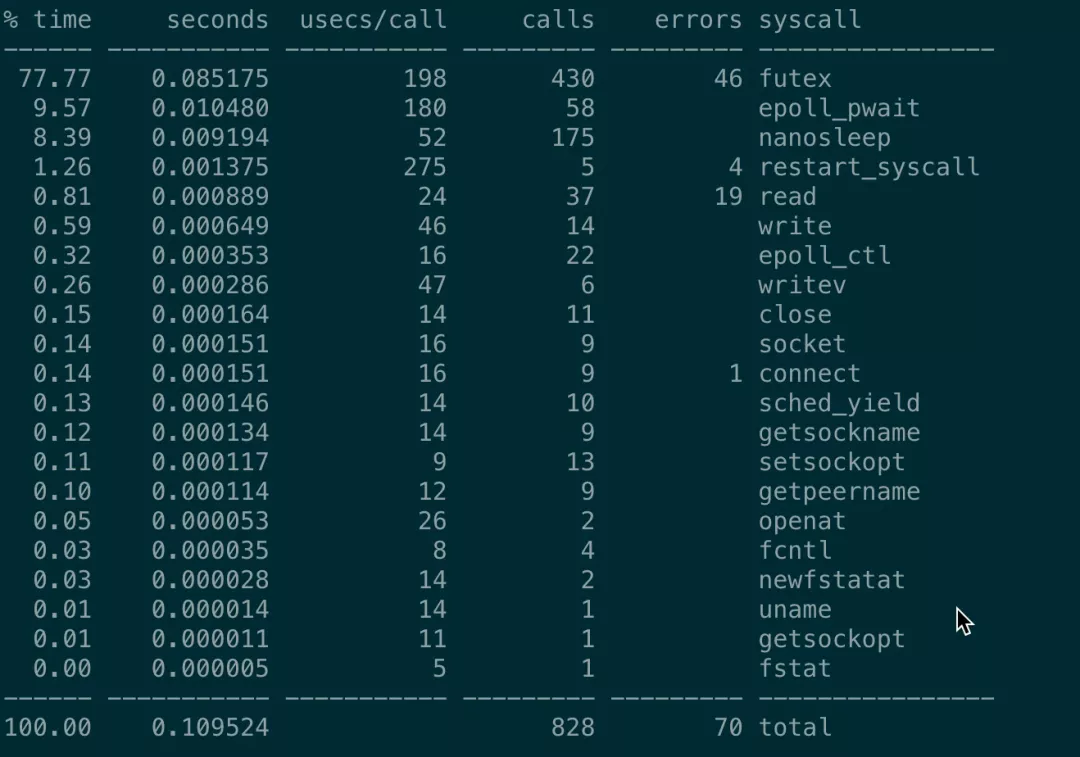
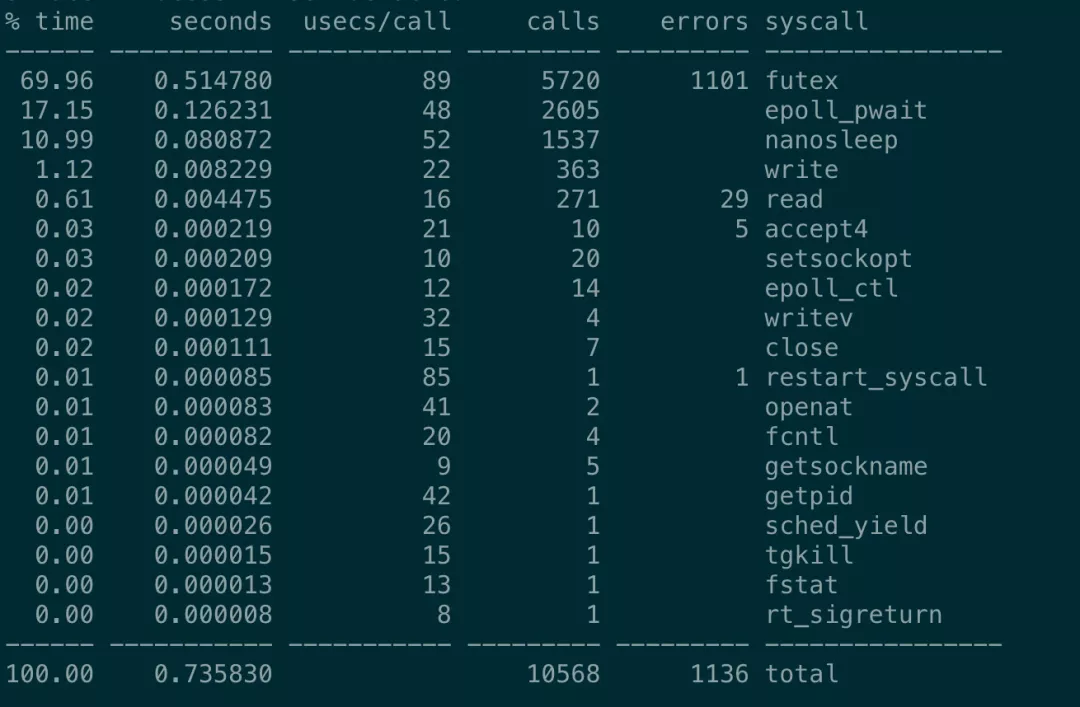

经过层层分析,发现其中一部分原因是 MOSN 依赖的 sentinel-golang 中的一个StartTimeTicker 的 func 中的 Sleep 产生了大量的系统调用,这是个什么逻辑?
PART. 3 理论分析

查看源码发现有一个毫秒级别的时间戳缓存逻辑,设计的目的是为了降低高调用频率下的性能开销,但空闲状态下频繁的获取时间戳和 Sleep 会产生大量的系统调用,导致 cpu sys util 上涨。我们先从理论上分析一下为什么这部分优化在工程上通常是无效的,先来看看 Sentinel 的代码:
package util
import (
"sync/atomic"
"time"
)
var nowInMs = uint64(0)
// StartTimeTicker starts a background task that caches current timestamp per millisecond,
// which may provide better performance in high-concurrency scenarios.
func StartTimeTicker() {
atomic.StoreUint64(&nowInMs, uint64(time.Now().UnixNano())/UnixTimeUnitOffset)
go func() {
for {
now := uint64(time.Now().UnixNano()) / UnixTimeUnitOffset
atomic.StoreUint64(&nowInMs, now)
time.Sleep(time.Millisecond)
}
}()
}
func CurrentTimeMillsWithTicker() uint64 {
return atomic.LoadUint64(&nowInMs)
}
从上面的代码可以看到,Sentinel 内部用了一个 goroutine 循环的获取时间戳存到 atomic 变量里,然后调用 Sleep 休眠 1ms,通过这种方式缓存了毫秒级别的时间戳。外部有一个开关控制这段逻辑是否要启用,默认情况下是启用的。从这段代码上看,性能开销最大的应该是 Sleep,因为 Sleep 会产生 syscall,众所周知 syscall 的代价是比较高的。
time.Sleep 和 time.Now 对比开销到底大多少呢?
查证资料(1)后我发现一个反直觉的事实,由于 Golang 特殊的调度机制,在 Golang 中一次 time.Sleep 可能会产生 7 次 syscall,而 time.Now 则是 vDSO 实现的,那么问题来了 vDSO 和 7 次系统调用相比提升应该是多少呢?
我找到了可以佐证的资料,恰好有一个 Golang 的优化(2),其中提到在老版本的 Golang 中(golang 1.9-),Linux/386 下没有这个 vDSO 的优化,此时会有 2 次 syscall,新版本经过优化后理论性能提高 5~7x+,可以约等于一次 time.Now <= 0.3 次 syscall 的开销。
Cache 设计的目的是为了减少 time.Now 的调用,所以理论上这里调用量足够大的情况下可能会有收益,按照上面的分析,假设 time.Now 和 Sleep 系统调用的开销比是 0.3:7.3(7+0.3),Sleep 每秒会执行 1000 次(不考虑系统精度损失的情况下),这意味着一秒内 CurrentTimeMillsWithTicker 的调用总次数要超过 2.4W 才会有收益。
所以我们再分析一下 CurrentTimeMillsWithTicker 的调用次数,我在这个地方加了一个 counter 进行验证,然后模拟请求调用 Sentinel 的 Entry,经过测试发现:
-
当首次创建资源点时,Entry 和 CurrentTimeMillsWithTicker 的放大比为 20,这主要是因为创建底层滑动窗口时需要大量的时间戳计算
-
当相同的 resource 调用 Entry 时,调用的放大比⁰为 5:1
|注 0: 内部使用的 MOSN 版本基于原版 Sentinel 做了一些定制化,社区版本放大比理论上低于该比值。
考虑到创建资源点是低频的,我们可以近似认为此处调用放大比为 5。所以理论上当单机 QPS 至少超过 4800 以上才可能会取得收益......我们动辄听说什么 C10K、C100K、C1000K 问题,这个值看上去似乎并不很高?但在实际业务系统中,这实际上是一个很高的量。
我随机抽取了多个日常请求量相对大的应用查看 QPS(这里的 QPS 包含所有类型的资源点,入口/出口调用以及子资源点等,总之就是所有会经过 Sentinel Entry 调用的请求量),日常峰值也未超过 4800QPS,可见实际的业务系统中,单机请求量超过这个值的场景是非常罕见的。¹
|注 1: 此处监控为分钟级的数据监控,可能与秒级监控存在一定的出入,仅用于指导日常请求量评估。
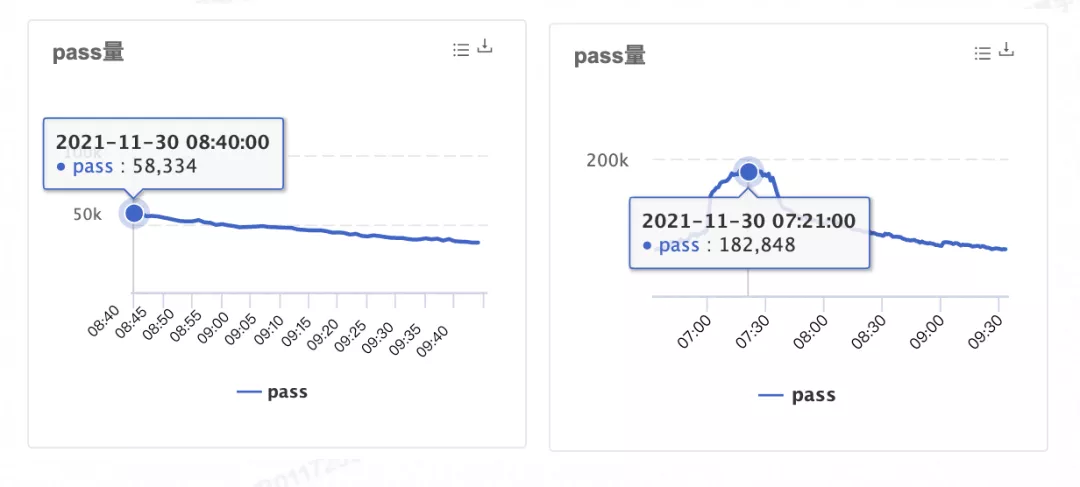
考虑到这个优化还有一个好处,是可以降低同步请求时间戳时的耗时,所以我们可以再对比一下直接从 atomic 变量读取缓存值和通过 time.Now() 读取时间戳的速度。

可以看到单次直接获取时间戳确实比从内存读取开销大很多,但是仍然是 ns 级别的,这种级别的耗时增长对于一笔请求而言是可以忽略不计的。

大概是 0.06 微秒,即使乘以 5,也就是 0.3 微秒的增加。在 4000QPS 这个流量档位下我们也可以看一下 MOSN 实际 RT。
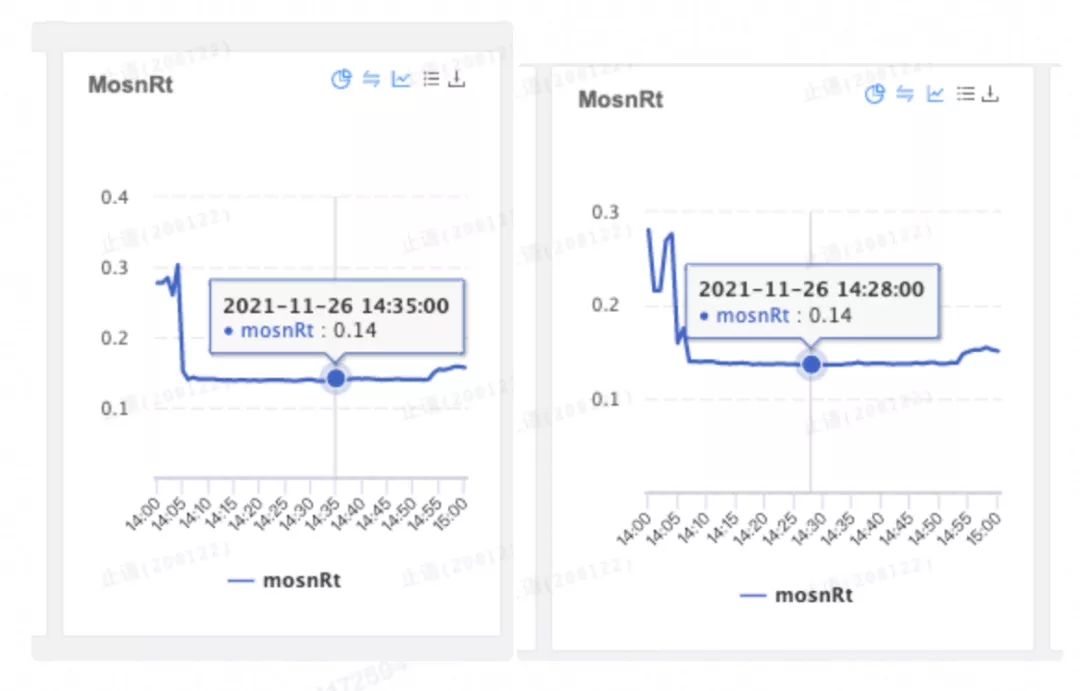
两台机器的 MOSN RT 也没有明显的差异,毕竟只有 0.3 微秒...
PART. 4 测试结论
同时我们也找了两台机器,分别禁用/启用这个 Cache 进行测试,测试结果佐证了上述分析的结论。
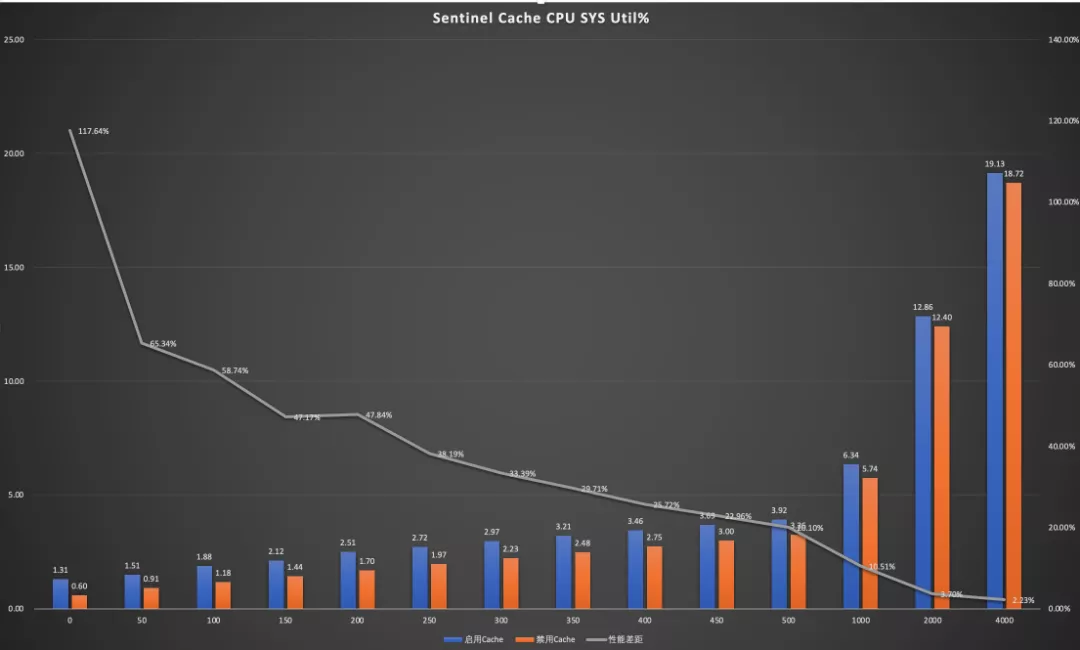
从上图的数据可以看出来,启用 Cache 的情况下 cpu sys util 始终比不启用 Cache 的版本要大,随着请求量增加,性能差距在逐步缩小,但是直至 4000QPS 仍然没有正向的收益。
经过测试和理论分析可得知,在常规的场景下,Sentinel 的这个 Cache 特性是没有收益的,反而对性能造成了损耗,尤其是在低负载的情况下。即使在高负载的情况下,也可以推论出:没有这个 Cache 不会对系统造成太大的影响。
这次性能分析也让我们意识到了几个问题:
-
不要过早优化,正所谓过早优化是万恶之源;
-
一定要用客观数据证明优化结果是正向的,而不是凭借直觉;
-
要结合实际场景进行分析,而不应该优先考虑一些小概率场景;
-
不同语言间底层实现可能存在区别,移植时应该仔细评估。
PART. 5 有必要吗?
你上面不是说了,不要过早优化,那这个算不算过早优化呢,你是不是双标?
“过早优化是万恶之源”实际上被误用了,它是有上下文的。
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%. —— Donald Knuth
Donald Knuth 认为许多优化是没必要的,我们可能花费了大量的时间去做了投入产出比不高的事情,但他同时强调了一些关键性优化的必要性。简而言之就是要考虑性价比,不能盲目地、没有数据支撑地去做性能优化,premature 似乎翻译成“不成熟、盲目的”更为贴切,因此这句话的本意是“盲目的优化是万恶之源”。这里只需要一行代码的改动,即可省下这部分不必要的开销,性价比极高,何乐而不为呢?
从数据上看,这个优化只是降低了 0.7% 的 cpu sys util,我们缺这 0.7% 吗?
从系统水位的角度思考或许还好,毕竟我们为了保险起见预备了比实际需求更多的资源,这 0.7% 并不会成为压垮我们系统的最后一颗稻草。但从环保的角度,很有必要!今年我们强调的是绿色环保,提效降本。这区区一行代码,作为 Sidecar 跑在数十万的业务 Pod 中,背后对应的是上万台的服务器。
用不太严谨的一种方式进行粗略的估算,以常规的服务器 CPU Xeon E5 为例,TDP² 为 120W,0.7% * 120W * 24 * 365 / 1000 = 73584 度电,每一万台机器一年 7 万度电,这还不包括为了保持机房温度而带来的更大的热交换能耗损失(简单说就是空调费,常规机房 PUE 大概 1.5),按照不知道靠谱不靠谱的专家估算,节约 1 度电=减排 0.997 千克二氧化碳,这四舍五入算下来大概减少了 100000kg 的二氧化碳吧。
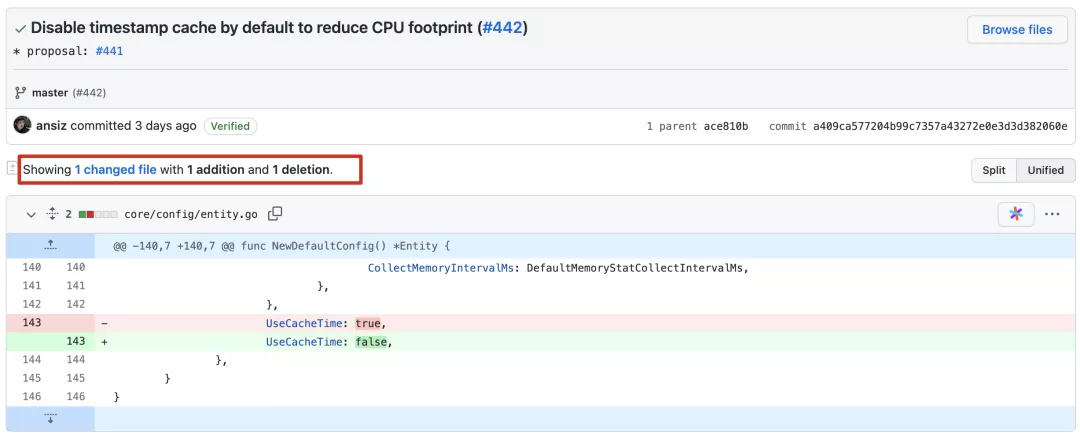
同时这也是一行开源社区的代码,社区已经采纳我们的建议(3)将该特性默认设置为关闭,或许有上千家公司数以万计的服务器也将得到收益。

|注 2: TDP 即热功耗设计,不能等价于电能功耗,热设计功耗是指处理器在运行实际应用程序时,可产生的最大热量。TDP 主要用于和处理器相匹配时,散热器能够有效地冷却处理器的依据。处理器的 TDP 功耗并不代表处理器的真正功耗,更没有算术关系,但通常可以认为实际功耗会大于 TDP。
「扩展阅读」
-
time: Sleep requires ~7 syscalls #25471: https://github.com/golang/go/issues/25471
-
How does Go know time.Now?: https://tpaschalis.github.io/golang-time-now/
-
It's Go Time on Linux: https://blog.cloudflare.com/its-go-time-on-linux/
-
69390: runtime: use vDSO on linux/386 to improve - - time.Now performance: https://go-review.googlesource.com/c/go/+/69390
(1)查证资料:https://github.com/golang/go/issues/25471
(2)Golang 的优化:https://go-review.googlesource.com/c/go/+/69390
(3)我们的建议:https://github.com/alibaba/sentinel-golang/issues/441
感谢艺刚、茂修、浩也、永鹏、卓与等同学对问题定位做出的贡献,本文部分引用了 MOSN 大促版本性能对比文档提供的数据。同时感谢宿何等 Sentinel 社区的同学对相关 issue 和 PR 的积极支持。
本周推荐阅读
深入 HTTP/3(一)|从 QUIC 链接的建立与关闭看协议的演进
网商双十一基于 ServiceMesh 技术的业务链路隔离技术及实践

|








- 上一条: 版本不兼容Jar包冲突该如何是好? 2021-12-29
- 下一条: Kubernetes 与 OpenYurt 无缝转换(命令式) 2021-12-29
- 一行Java代码实现游戏中交换装备 2021-09-14
- 用100行代码提升10倍的性能 2021-07-05
- 终于可以一行代码也不用改了!ShardingSphere 原生驱动问世 2022-07-06
- 一行Python代码,给PDF文件添加水印 2022-06-14
- 一行Python代码,如何成为办公小助手?这5个操作,超实用! 2022-05-26


