深入解析Apache Pulsar系列(二) —— Broker消息确认的管理

作者简介
林琳 腾讯云中间件专家工程师 Apache Pulsar PMC,《深入解析Apache Pulsar》作者。目前专注于中间件领域,在消息队列和微服务方向具有丰富的经验。负责TDMQ的设计与开发工作,目前致力于打造稳定、高效和可扩展的基础组件与服务。
导语
我们在之前的《深入解析Apache Pulsar系列之一 —— 客户端消息确认》中介绍过Apache Pulsar客户端的多种消息确认模式。这篇文章中,我们将介绍Broker侧对于消息确认的管理。
客户端通过消息确认机制通知Broker某些消息已经被消费,后续不要再重复推送。Broker侧则使用游标来存储当前订阅的消费位置信息,包含了消费位置中的所有元数据,避免Broker重启后,消费者要从头消费的问题。Pulsar中的订阅分为持久订阅和非持久订阅,他们之间的区别是:持久订阅的游标(Cursor)是持久化的,元数据会保存在ZooKeeper,而非持久化游标只保存在Broker的内存中。
游标的简介
Pulsar中每个订阅都会包含一个游标,如果多个消费者拥有相同的订阅名(消费组),那这些消费者们会共享一个游标。游标的共享又和消费者的消费模式有关,如果是Exclusive或者FailOver模式的订阅,那同一时间只有一个消费者使用这个游标。如果是Shared或者Key_Shared模式的订阅,那多个消费者会同时使用这个游标。
每当消费者Ack一条消息,游标中指针的位置都有可能会变化,为什么说是有可能呢?这涉及到我们在客户端章节介绍的Acknowledge的方式:单条消息确认(Acknowledge)、批消息中的单个消息确认(Acknowledge)、累积消息确认(AcknowledgeCumulative)。否定应答(NegativeAcknowledge)不涉及游标的变化,因此不在讨论范围之内。 我们先看单条消息的确认,如果是独占式的消费,每确认一条消息,游标位置都会往后移动一个Entry,如下图所示: 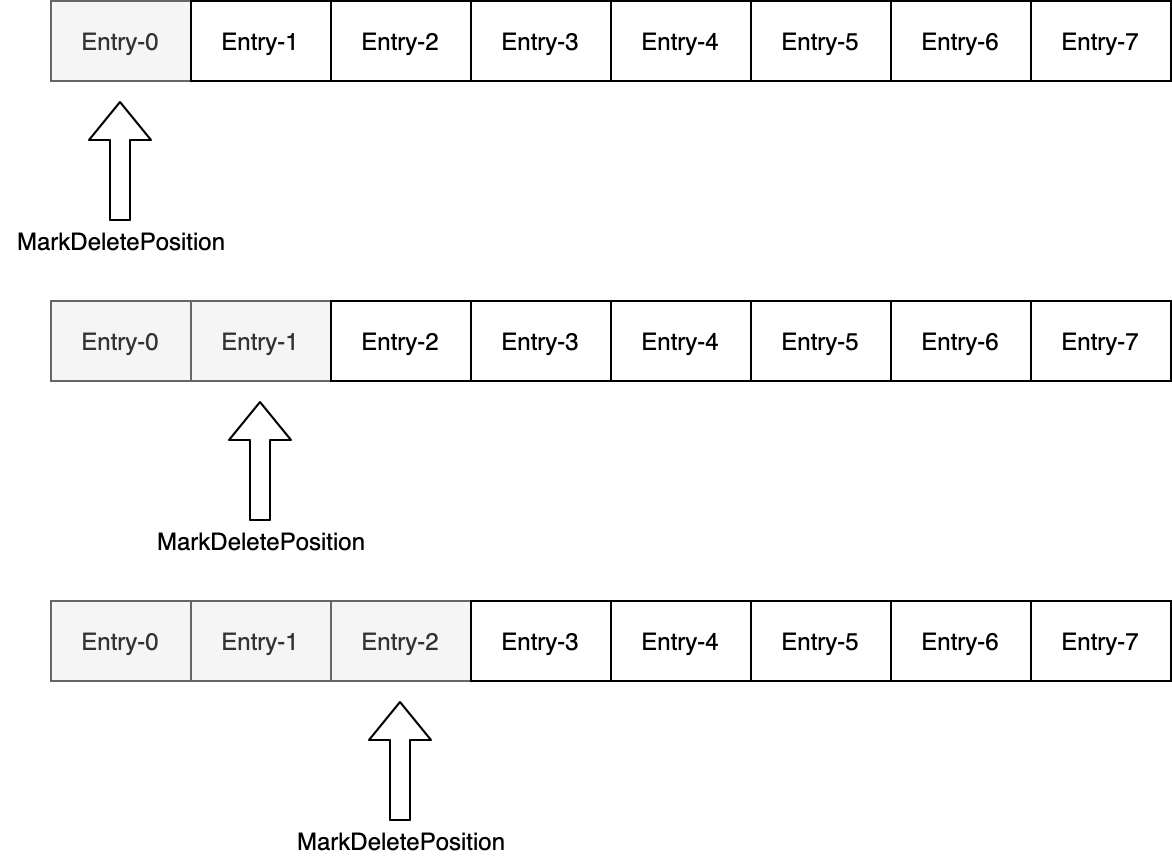
累积消息确认,只需要确认一条消息,游标可以往后移动多个Entry,如:Consumer-1累积确认了Entry-4,则从0开始的Entry都会被确认,如下图所示: 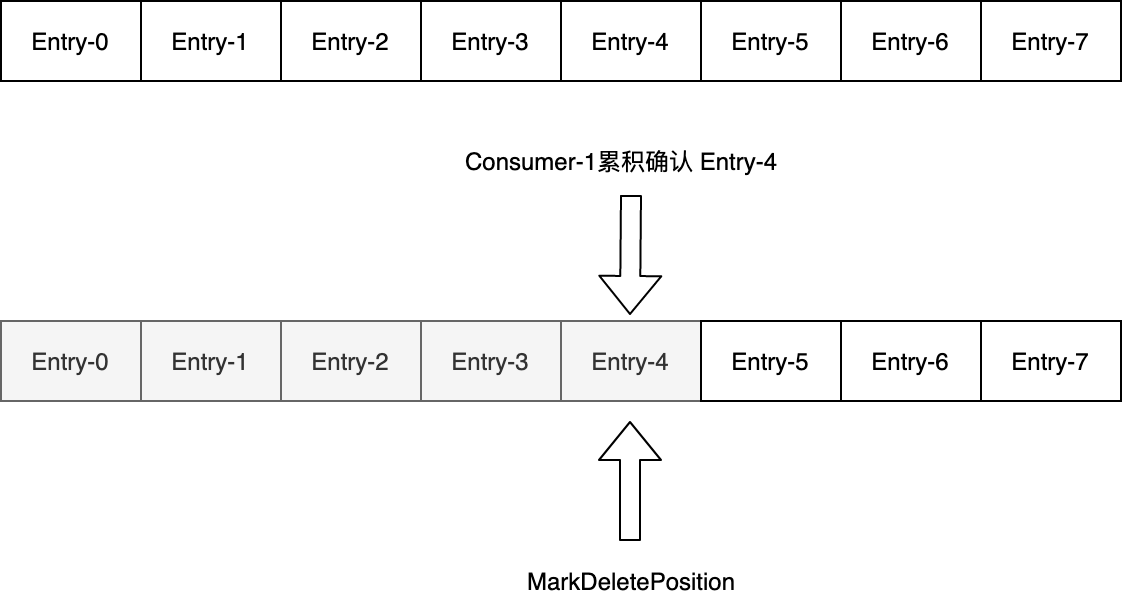
对于共享式的消费,因为有多个消费者同时消费消息,因此消息的确认可能会出现空洞,空洞如下图所示: 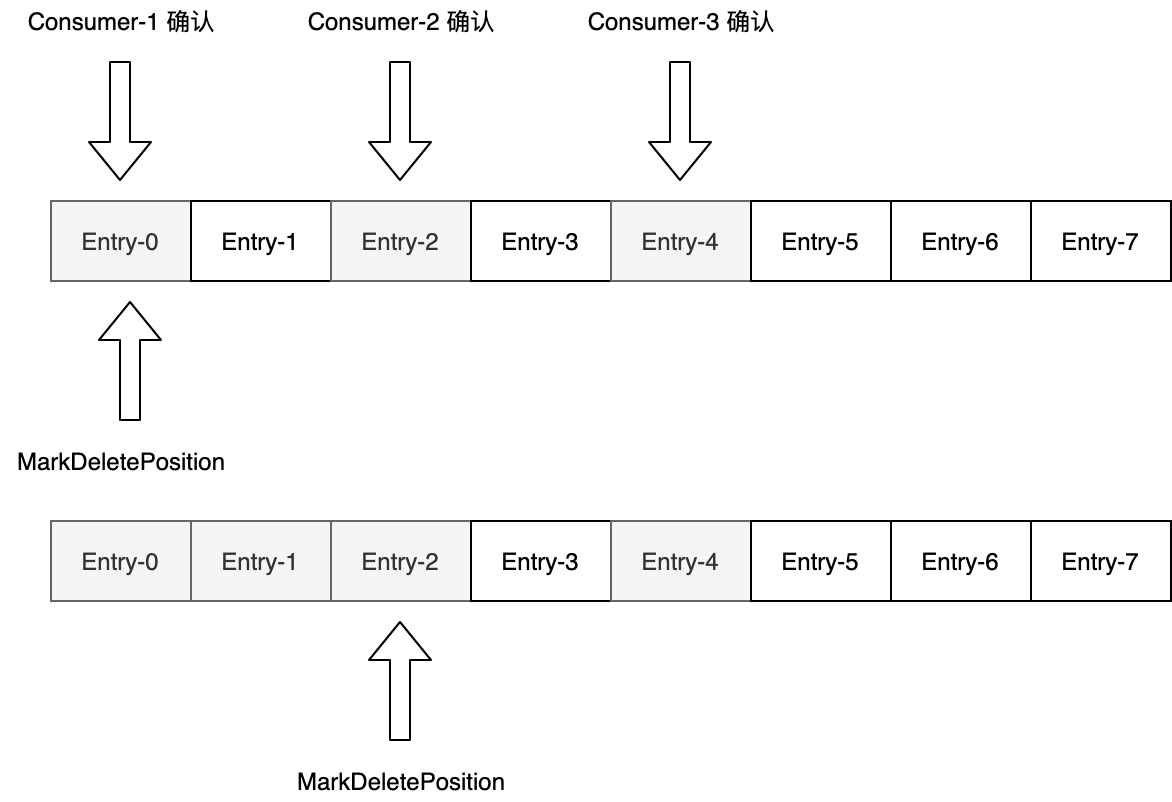
这里也解释了为什么MarkeDeletePosition指针的位置可能发生变化,我们可以从共享式的消费中看到,消息确认是可能出现空洞的,只有当前面所有的Entry都被消费并确认,MarkeDeletePosition指针才会移动。如果存在空洞,MarkeDeletePosition指针是不会往后移动的。那这个MarkeDeletePosition指针和游标是什么关系呢?游标是一个对象,里面包含了多个属性,MarkeDeletePosition指针只是游标的其中一个属性。正如上面所说的Ack空洞,在游标中有另外专门的方式进行存储。如果我们不单独存储空洞,那Broker重启后,消费者只能从MarkDeletePosition开始消费,会存在重复消费的问题。如果以上图为例,Broker重启后Entry-4就会被重复消费。当然,Pulsar中对空洞信息是有单独存储的。
然后,我们看看游标里到底记录了什么元数据,此处只列出一些关键的属性:
| 属性名 | 描述 |
|---|---|
| bookkeeper | Bookkeeper Client的引用,主要用来打开Ledger,例如:读取历史数据,可以打开已经关闭的Ledger;当前Ledger已经写满,打开一个新的Ledger |
| markDeletePosition | 标记可删除的位置,在这个位置之前的所有Entry都已经被确认了,因此这个位置之前的消息都是可删除状态 |
| persistentMarkDeletePosition | markDeletePosition是异步持久化的,这个属性记录了当前已经持久化的markDeletePosition。当markDeletePosition不可用时,会以这个位置为准。这个位置会在游标recovery时初始化,后续在持久化成功后不断更新 |
| readPosition | 订阅当前读的位置,即使有多个消费者,读的位置肯定是严格有序的,只不过消息会分给不同的消费者而已。读取的位置会在游标恢复(recovery)时初始化,消费时会不断更新 |
| lastMarkDeleteEntry | 最后被标记为删除的Entry,即markDeletePosition指向的Entry |
| cursorLedger | cursor在Zookeeper中只会保存索引信息,具体的Ack数据会比较大,因此会保存到Bookkeeper中,这个属性持有了对应Ledger的引用 |
| individualDeletedMessages | 用于保存Ack的空洞信息 |
| batchDeletedIndexes | 用于保存批量消息中单条消息Ack信息 |
看到CursorLedger,说明数据被保存到了Bookkeeper中。有的读者可能会有疑问,既然数据都保存到Bookkeeper中了,那ZooKeeper中保存的Cursor信息有什么用呢?我们可以认为ZooKeeper中保存的游标信息只是索引,包含了以下几个属性:
- 当前的cursorLedger名以及ID,用于打开Bookkeeper中的Ledger;
- LastMarkDeleteEntry,最后被标记为删除的Entry信息,里面包含了LedgerId和EntryId;
- 游标最后的活动时间戳。
游标保存到ZooKeeper的时机有几个:
- 当cursor被关闭时;
- 当发生Ledger切换导致cursorLedger变化时;
- 当持久化空洞数据到Bookkeeper失败并尝试持久化空洞数据到ZooKeeper时。
我们可以把ZooKeeper中的游标信息看作Check Point,当恢复数据时,会先从ZooKeeper中恢复元数据,获取到Bookkeeper Ledger信息,然后再通过Ledger恢复最新的LastMarkDeleteEntry位置和空洞信息。
既然游标不会实时往ZooKeeper中写入数据,那是如何保证消费位置不丢失的呢?
Bookkeeper中的一个Ledger能写很多的Entry,因此高频的保存操作都由Bookkeeper来承担了,ZooKeeper只负责存储低频的索引更新。
消息空洞的管理
在游标对象中,使用了一个IndividualDeletedMessages容器来存储所有的空洞信息。得益于Java中丰富的轮子生态,Broker中直接使用了Guava Range这个库来实现空洞的存储。举个例子,假设在Ledger-1中我们的空洞如下: ![]()
则我们存储的空洞信息如下,即会用区间来表示已经连续Ack的范围: [ (1:-1, 1:2] , (1:3, 1:6] ]
使用区间的好处是,可以用很少的区间数来表示整个Ledger的空洞情况,而不需要每个Entry都记录。当某个范围都已经被消费且确认了,会出现两个区间合并为一个区间,这都是Guava Range自动支持的能力。如果从当前MarkDeletePosition指针的位置到后面某个Entry为止,都连成了一个区间,则MarkDeletePosition指针就可以往后移动了。
记录了这些消息空洞之后,是如何用来避免消息重复消费的呢?
当Broker从Ledger中读取到消息后,会进入一个清洗阶段,如:过滤掉延迟消息等等。在这个阶段,Broker会遍历所有消息,看消息是否存在于Range里,如果存在,则说明已经被确认过了,这条消息会被过滤掉,不再推送给客户端。Guava Range提供了Contains接口,可以快速查看某个位置是否落在区间里。这种Entry需要被过滤的场景,基本上只会出现在Broker重启后,此时游标信息刚恢复。当ReadPosition超过了这段空洞的位置时,就不会出现读到重复消息要被过滤的情况了。
然后,我们来看看IndividualDeletedMessages这个容器的实现。
IndividualDeletedMessages 的类型是LongPairRangeSet,默认实现是DefaultRangeSet,是一个基于Google Guava Range包装的实现类。另外一个Pulsar自己实现的优化版:ConcurrentOpenLongPairRangeSet。优化版的RangeSet和Guava Range的存储方式有些不一样,Guava Range使用区间来记录数据,优化版RangeSet对外提供的接口也是Range,但是内部使用了BitSet来记录每个Entry是否被确认。
优化版RangeSet在空洞较多的情况下对内存更加友好。我们可以假设一个场景,有100W的消息被拉取,但是只有50W的消息已经被Ack,并且每隔一条消息Ack一条,这样就会出现50W个空洞。此时的Range就无法发挥区间的优势了,会出现50W个Range对象,如下图所示。而优化版的RangeSet使用了BitSet,每个ack只占一位。 
我们可以在broker.conf中,通过配置项managedLedgerUnackedRangesOpenCacheSetEnabled=true来开启使用优化版的RangeSet。
也正因如此,如果整个集群的订阅数比较多,游标对象的数据量其实并不小。所以在Pulsar中,MetaDataStore中只保存了游标的索引信息,即保存了游标存储在哪个Ledger中。真正的游标数据会通过上面介绍的cursorLedger写入到Bookkeeper中持久化。整个游标对象会被写入到一个Entry中,其Protobuf的定义如下:
message PositionInfo { required int64 ledgerId = 1; required int64 entryId = 2; repeated MessageRange individualDeletedMessages = 3; repeated LongProperty properties = 4; repeated BatchedEntryDeletionIndexInfo batchedEntryDeletionIndexInfo = 5; }
看到这里,其实Batch消息中单条消息确认的实现也清晰了,BatchDeletedIndexes是一个ConcurrentSkipListMap,Key为一个Position对象,对象里面包含了LedgerId和EntryId。Value是一个BitSet,记录了这个Batch里面哪些消息已经被确认。BatchDeletedIndexes会和单条消息的空洞一起放在同一个对象(PositionInfo)中,最后持久化到Bookkeeper。
空洞数据如果写入Bookkeeper失败了,现在Pulsar还会尝试往ZooKeeper中保存,和索引信息一起保存。但是ZooKeeper不会保存所有的数据,只会保存一小部分,尽可能的让客户端不出现重复消费。我们可以通过broker.conf中的配置项来决定最多持久化多少数据到ZooKeeper,配置项名为:managedLedgerMaxUnackedRangesToPersistInZooKeeper,默认值是1000。
消息空洞管理的优化
空洞存储的方案看起来已经很完美,但是在海量未确认消息的场景下还是会出现一些问题。首先是大量的订阅会让游标数量暴增,导致Broker内存的占用过大。其次,有很多空洞其实是根本没有变化的,现在每次都要保存全量的空洞数据。最后,虽然优化版RangeSet在内存中使用了BitSet来存储,但是实际存储在Bookkeeper中的数据MessageRange,还是一个个由LedgerId和EntryId组成的对象,每个MessageRange占用16字节。当空洞数量比较多时,总体体积会超过5MB,而现在Bookkeeper能写入的单个Entry大小上限是5MB,如果超过这个阈值就会出现空洞信息持久化失败的情况。
对于这种情况,已经有专门的PIP在解决这个问题,笔者在写这篇文章的时候,这个PIP代码已经提交,正在Review阶段,因此下面的内容可能会和最终代码有一定差距。
新的方案中主要使用LRU+分段存储的方式来解决上述问题。由于游标中空洞信息数据量可能会很大,因此内存中只保存少量热点区间,通过LRU算法来切换冷热数据,从而进一步压缩内存的使用率。分段存储主要是把空洞信息存储到不同的Entry中去,这样能避免超过一个Entry最大消息5MB的限制。
如果我们把空洞信息拆分为多个Entry来存储,首先面临的问题是索引。因为使用单个Entry记录时,只需要读取Ledger中最后一个Entry即可,而拆分为多个Entry后,我们不知道要读取多少个Entry。因此,新方案中引入了Marker,如下图所示: 
当所有的Entry保存完成后,插入一个Marker,Marker是一个特殊的Entry,记录了当前所有拆分存储的Entry。当数据恢复时,从后往前读,先读出索引,然后再根据索引读取所有的Entry。
由于存储涉及到多个Entry,因此需要保证原子性,只要最后一个Entry读出来不是Marker,则说明上次的保存没有完成就中断了,会继续往前读,直到找到一个完整的Marker。
空洞信息的存储,也不需要每次全量了。以Ledger为单位,记录每个Ledger下的数据是否有修改过,如果空洞数据被修改过会被标识为脏数据,存储时只会保存有脏数据的部分,然后修改Marker中的索引。
假设Entry-2中存储的空洞信息有修改,则Entry-2会被标记为脏数据,下次存储时,只需要存储一个Entry-2,再存储一个Marker即可。只有当整个Ledger写满的情况下,才会触发Marker中所有Entry复制到新Ledger的情况。如下图所示: 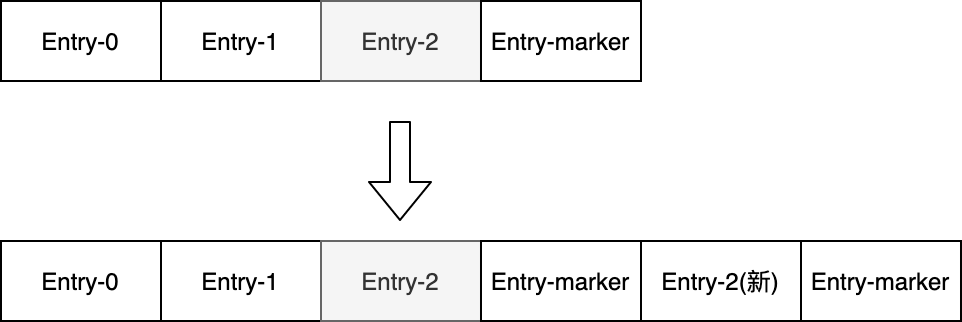
ManagedLedger在内存中通过LinkedHashMap实现了一个LRU链表,会有线程定时检查空洞信息的内存占用是否已经达到阈值,如果达到了阈值则需要进行LRU换出,切换以Ledger为单位,把最少使用的数据从Map中移除。LRU数据的换入是同步的,当添加或者调用Contains时,发现Marker中存在这个Ledger的索引,但是内存中没有对应的数据,则会触发同步数据的加载。异步换出和同步换入,主要是为了让数据尽量在内存中多待一会,避免出现频繁的换入换出。
尾声
Pulsar中的设计细节非常多,由于篇幅有限,作者会整理一系列的文章进行技术分享,敬请期待。如果各位希望系统性地学习Pulsar,可以购买作者出版的新书《深入解析Apache Pulsar》。 
© 著作权归作者所有
作者的其它热门文章

|








- 上一条: 高手问答:云原生大规模微服务如何做产品交付 2021-12-21
- 下一条: 饿了么小程序容器首屏秒开优化实践 2021-12-21
- 深入解析Apache Pulsar系列(一):客户端消息确认 2021-11-19
- Message deduplication 这里的去重与你想的可能不一样|Apache Pulsar 技术系列 2022-01-21
- 技术干货|一文彻底读懂高性能消息组件Apache Pulsar 2022-01-18
- Pulsar vs Kafka?一文掌握高性能消息组件Pulsar基础知识 2022-01-17
- 博文干货|在 Kotlin 中使用 Apache Pulsar 2022-03-01


