从 “香农熵” 到 “告警降噪” ,如何提升告警精度?
作者:董善东 & 白玙
对于大部分人来说,信息是一个非常抽象的概念。人们常常说信息很多或信息较少,但却很难说清楚信息到底有多少。比如一份帮助文档或一篇文章到底有多少信息量。直到 1948 年,C.E.Shannon(香农)提出了“信息熵”的概念,才解决了对信息的量化度量问题。信息熵这个词是香农从热力学中借鉴而来来的。热力学中的热熵是表示分子状态混乱程度的物理量。而香农用信息熵的概念来描述信源的不确定度。

香农的信息熵本质上是对我们司空见惯的 “不确定现象” 的数学化度量。譬如说,如果天气预报说 “今天下午下雨的可能性是 60%” ,我们就会不约而同想到出门带伞;如果预报说 “有 60% 的可能性下雨” ,我们就会犹豫是否带伞,因为雨伞无用时确是累赘之物。显然,第一则天气预报中,下雨这件事的不确定性程度较小,而第二则关于下雨的不确定度就大多了。
作为数学中颇为抽象的概念,我们可以把信息熵理解成某种特定信息的出现概率。而信息熵和热力学熵是紧密相关的。根据 Charles H. Bennett 对 Maxwell's Demon 的重新解释,对信息的销毁是一个不可逆过程,所以销毁信息是符合热力学第二定律的。而产生信息,则是为系统引入负(热力学)熵的过程。当一种信息出现概率更高时,表明被传播得更广泛,或者说被引用的程度更高。我们可以认为从信息传播角度来看,信息熵可以表示信息的价值,这样子我们就有一个衡量信息价值高低的标准。
再具体到我们日常运维工作场景中,各类的告警事件作为最典型的一种信息,在面对每天海量高警事件我们该如何评估告警的信息价值成为了一个重要问题。
各大监控平台/工具一般有两种方式去识别指标异常并触发告警事件。第一种是常见的通过设定阈值/动态阈值的方式。第二种就是设定默认规则,触发系统预设规则事件,例如:机器重启等。 与此同时,运维团队往往不会依赖单一的监控工具,经常需要在各种不同层次工具中都设定对应的监控告警。
在这样的背景下,监控源多元化与监控工具类别多样化,往往导致相同故障原因在不同监控工具、不同监控规则下,触发出大量重复、冗余的告警事件。甚至在发生大范围故障时形成告警风暴。运维人员很难从这些海量告警中快速有效的识别到底哪些告警事件是重要且准确的信息,这也往往导致有效告警被淹没。因此,对于运维团队和告警产品来说,存在以下几个痛点:
- 多处监控告警源以及频繁误报导致大量重复、冗余、低效事件,重要事件淹没在其中,无法有效识别;
- 大范围故障导致的告警风暴;
- 测试事件等脏数据混在事件中。
什么是 ARMS 智能降噪
ARMS 智能降噪功能依托于 NLP 算法和信息熵理论建立模型,从大量历史告警事件中去挖掘这些事件的模式规律。当实时事件触发后,实时为每一条事件打上信息熵值与噪音识别的标签,帮助用户快速识别事件重要性。
智能降噪的实现原理介绍
事件中心中大量的历史事件沉积,很难人工实现从这些大量历史事件中抽象出事件模式与价值。应用实时监控服务 ARMS ITSM 产品智能降噪功对不同告警源收归到统一平台进行告警事件处理,将这些历史事件进行模式识别,挖掘内在关联,建立基于信息熵的机器学习模型辅助用户进行事件重要性的识别,模型核心步骤包括:
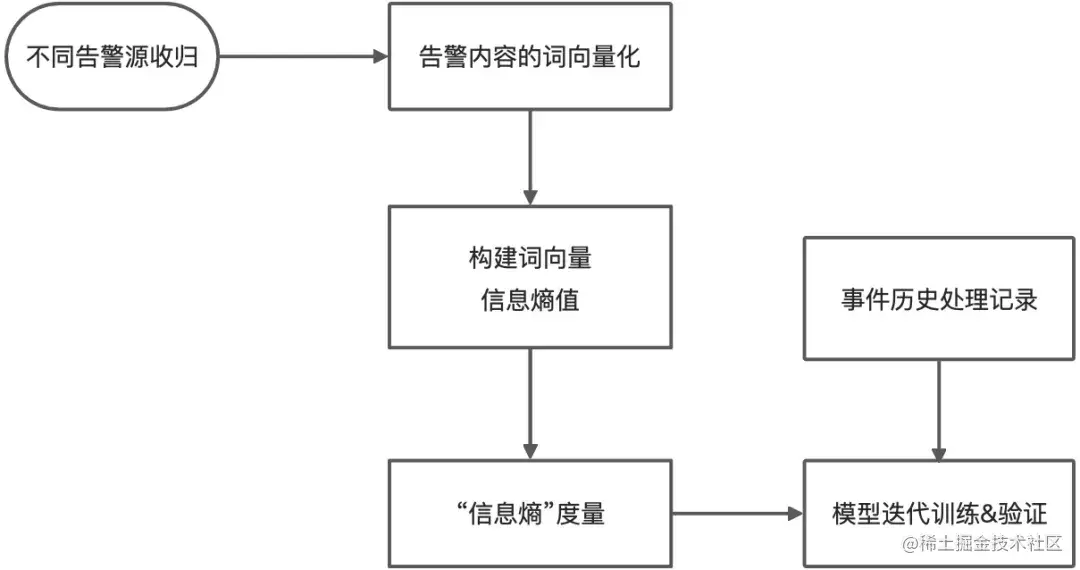
- step 1:基于自然语言处理和领域词汇库, 完成事件内容的词向量化,实现事件最小粒度的度量;
- step 2:基于信息论中信息熵的概念, 结合 tfidf 模型,构建词向量的信息熵值和重要性度量模型;
- step 3:利用 sigmod,完成事件的非线性和归一化 “信息熵” 度量;
- step 4:结合历史事件的处理记录和反馈, 构建模型迭代训练与验证。
利用自然语言处理算法,基于信息论中的信息量和信息熵概念来表征事件重要性,帮助用户利用大量历史事件训练迭代出识别事件重要性的模型。当新实时事件触发时,快速识别事件重要性。同时,结合信息熵阈值设定,来完成噪音事件过滤与屏蔽。并根据时间演进以及事件类型与内容变化,模型通过自适应定期实现迭代式更新(更新频率为每周一次),无需用户进行任何操作,即可保证模型准确性。
智能降噪业务价值
业务价值一:智能化识别重复、低效事件,挖掘新奇事件
(1)大量重复、相似事件的识别
对于大量重复、相似事件,该类事件持续大量出现在事件告警中,模型对于这类事件的信息熵值会持续给予降低的信息熵,即:这类事件的信息熵值会越来越低,直到最后接近为 0。这是因为模型期待对于重要的事件,用户可以更多关注响应, 而如果事件一直重复、大量触发,往往说明这类事件用户根本不关心,从业务逻辑上也辅证了模型机理。
(2)挖掘新奇事件
对于在历史事件中不曾出现、比较少出现的事件,模型则会重点关注,认定该类事件为新奇事件,给予当前事件较大的信息熵值,以期待用户更多的关注该类事件。因此,ARMS 智能降噪模型还具备帮助用户识别重要事件的功能。
业务价值二:定制化需求支持设定
对于一些用户测试事件或特定字段事件,我们常常希望对这类事件进行定制化处理,例如:测试事件只触发查看整个流程,但不需要去点击做任何处理。再比如,有些事件中包含了特别重要字段信息,对于这类事件需要优先处理。
业务价值三: 模型具备高成长性
对于历史事件数量较少的用户(事件数量<1000), 一般不推荐打开该功能,这是因为历史事件数量过少的情况下,模型很难充分训练,识别其内在模式和规律。但是在开启后, 模型每周会在本周新发生的事件基础上,进行模型迭代训练。在用户无需关心的前提下,模型一方面自适应追踪事件模式变化,另外一方面对于原有事件数量不充足的模型, 也在持续进行充分迭代。
最佳实践
使用流程说明
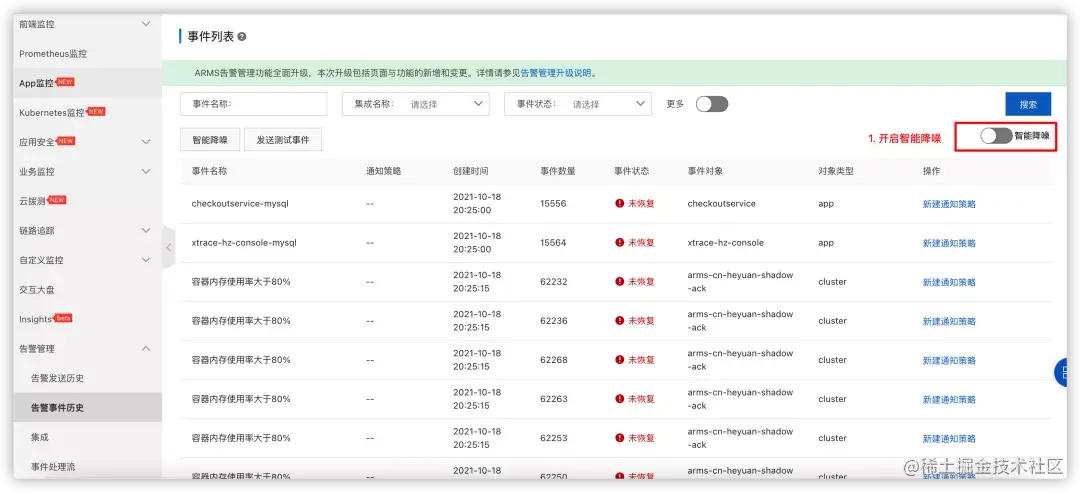
step 0:入口

step 1:开启
当觉得事件量过多, 重复事件,低效/无效事件过多时, 可以选择开启智能降噪。
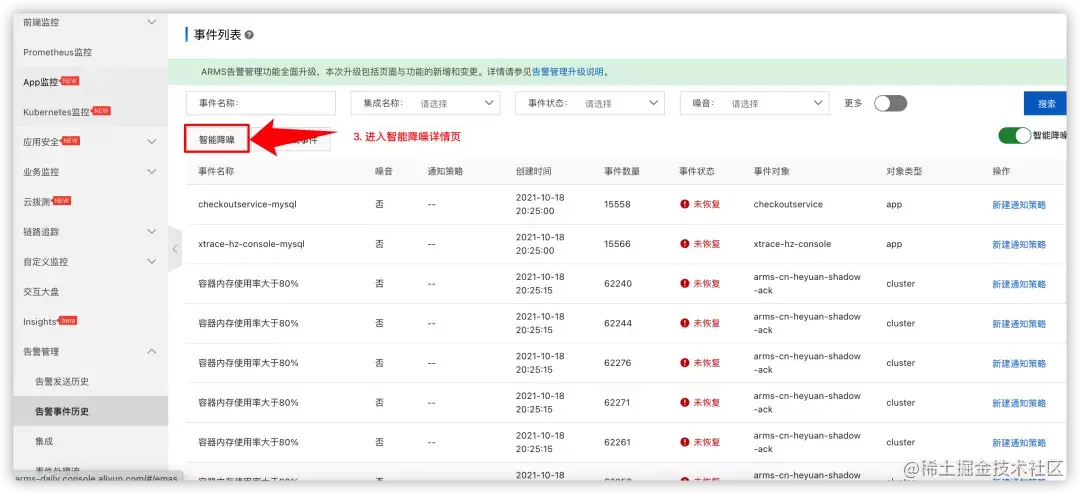
step 2:使用
开启后, 则会拉取历史 1 个月的事件数据(如果一个月内事件数量过多, 目前会拉取一部分进行训练)进行智能模型训练。点击智能降噪,进入详情页。
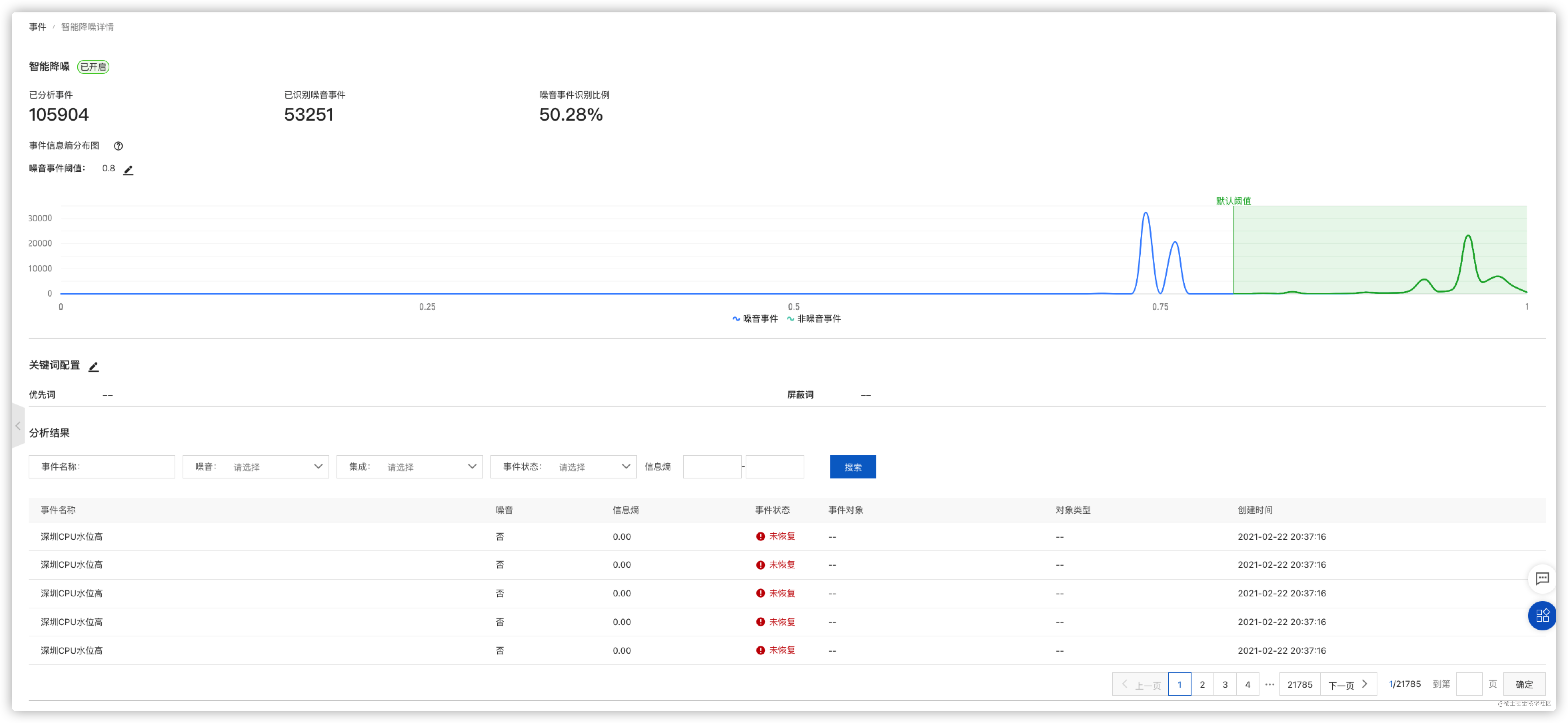
step 3:参数设定
深入了解该功能后, 用户可以开始考虑设定一些关键来进行事件的优先处理和屏蔽。优先词和屏蔽词的详情可以参考名词解释。
名词解释
- 噪音事件阈值: 开启智能降噪后, 我们会对每一条新事件计算信息熵值。噪音事件阈值设定则是划分噪音/非噪音事件的分界线。
- 噪音事件: 事件信息熵低于设定信息熵阈值的事件,统称为噪音事件。
- 非噪音事件: 事件信息熵大于或等于设定信息熵阈值的事件,统称为非噪音事件。
- 优先词: 在关键词设定中,用户可以设定一些自己想要优先看到的词汇, 如:重要, critical 等。当发生事件的事件名称和事件内容包含设定的优先词时, 当前事件的优先级相对应提高, 避免被识别成噪音事件。
- 屏蔽词: 在关键词设定中,用户可以设定一些自己认为不重要的词汇, 如:测试, test 等。当发生事件的事件名称和事件内容包含设定的屏蔽词时, 当前事件会被直接认定为信息熵为 0(如果信息熵阈值设定 >0,则被认定为噪音事件)。
- 常见词 Top50: 根据历史事件的统计学习, 模型会保存一份事件词汇的词频表。常见词则是词频表按照出现频率大小排序, 选择 Top50 进行展示。
常见问题
什么时候开启该功能
对于历史事件数量 > 1000 的用户,ARMS 智能降噪将进行自动开启操作。
对于历史事件数量仍较少的用户,用户可自行打开,但是模型效果需要一段时间时间迭代调优。
需不需要修改模型参数
建议在初期使用,不作修改,采取默认即可。
在了解功能后,可以尝试设定优先词和屏蔽词, 以及信息熵阈值,实现更定制化的需求。
点击此处,前往阿里云可观测专题页查看更多信息!
近期热门
#阿里云可观测系列公开课#
直播间不见不散!

|








- 上一条: 用OneFlow实现基于U型网络的ISBI细胞分割任务 2021-12-17
- 下一条: 链路分析 K.O “五大经典问题” 2021-12-17
- 深度解析智能运维下告警关联频繁项集挖掘算法原理 2022-06-09
- 从构建到使用,openLooKeng 如何实现 Hash Join ? 2021-11-05
- vivo统一告警平台设计与实践 2021-11-22
- 高效实践|频繁项集挖掘算法在告警关联中的应用 2022-06-17
- 有了这个告警系统,DBA提前预警不是难题 2021-10-21


