ClickHouse vs StarRocks 选型对比
作者:懂的都懂
面向列存的 DBMS 新的选择
Hadoop 从诞生已经十三年了,Hadoop 的供应商争先恐后的为 Hadoop 贡献各种开源插件,发明各种的解决方案技术栈,一方面确实帮助很多用户解决了问题,但另一方面因为繁杂的技术栈与高昂的维护成本,Hadoop 也渐渐地失去了原本属于他的市场。对于用户来说,一套高性能,简单化,可扩展的数据库产品能够帮助他们解决业务痛点问题。越来越多的人将目光锁定在列存的分布式数据库上。
ClickHouse 简介
ClickHouse 是由俄罗斯的第一大搜索引擎 Yandex 公司开源的列存数据库。令人惊喜的是,ClickHouse 相较于很多商业 MPP 数据库,比如 Vertica,InfiniDB 有着极大的性能提升。除了 Yandex 以外,越来越多的公司开始尝试使用 ClickHouse 等列存数据库。对于一般的分析业务,结构性较强且数据变更不频繁,可以考虑将需要进行关联的表打平成宽表,放入 ClickHouse 中。
相比传统的大数据解决方案,ClickHouse 有以下的优点:
-
配置丰富,只依赖与 Zookeeper
-
线性可扩展性,可以通过添加服务器扩展集群
-
容错性高,不同分片间采用异步多主复制
-
单表性能极佳,采用向量计算,支持采样和近似计算等优化手段
-
功能强大支持多种表引擎
StarRocks 简介
StarRocks 是一款极速全场景 MPP 企业级数据库产品,具备水平在线扩缩容,金融级高可用,兼容 MySQL 协议和 MySQL 生态,提供全面向量化引擎与多种数据源联邦查询等重要特性。StarRocks 致力于在全场景 OLAP 业务上为用户提供统一的解决方案,适用于对性能,实时性,并发能力和灵活性有较高要求的各类应用场景。
相比于传统的大数据解决方案,StarRocks 有以下优点:
-
不依赖于大数据生态,同时外表的联邦查询可以兼容大数据生态
-
提供多种不同的模型,支持不同维度的数据建模
-
支持在线弹性扩缩容,可以自动负载均衡
-
支持高并发分析查询
-
实时性好,支持数据秒级写入
-
兼容 MySQL 5.7 协议和 MySQL 生态
StarRocks 与 ClickHouse 的功能对比
StarRocks 与 ClickHouse 有很多相似之处,比如说两者都可以提供极致的性能,也都不依赖于 Hadoop 生态,底层存储分片都提供了主主的复制高可用机制。但功能、性能与使用场景上也有差异。ClickHouse 在更适用与大宽表的场景,TP 的数据通过 CDC 工具的,可以考虑在 Flink 中将需要关联的表打平,以大宽表的形式写入 ClickHouse。StarRocks 对于 join 的能力更强,可以建立星型或者雪花模型应对维度数据的变更。
大宽表 vs 星型模型
ClickHouse:通过拼宽表避免聚合操作
- 在 ETL 的过程中处理好宽表的字段,分析师无需关心底层的逻辑就可以实现数据的分析
- 宽表能够包含更多的业务数据,看起来更直观一些
- 宽表相当于单表查询,避免了多表之间的数据关联,性能更好
- 宽表中的数据可能会因为 join 的过程中存在一对多的情况造成错误数据冗余
- 宽表的结构维护麻烦,遇到维度数据变更的情况需要重跑宽表
- 宽表需要根据业务预先定义,宽表可能无法满足临时新增的查询业务
StarRocks:通过星型模型适应维度变更
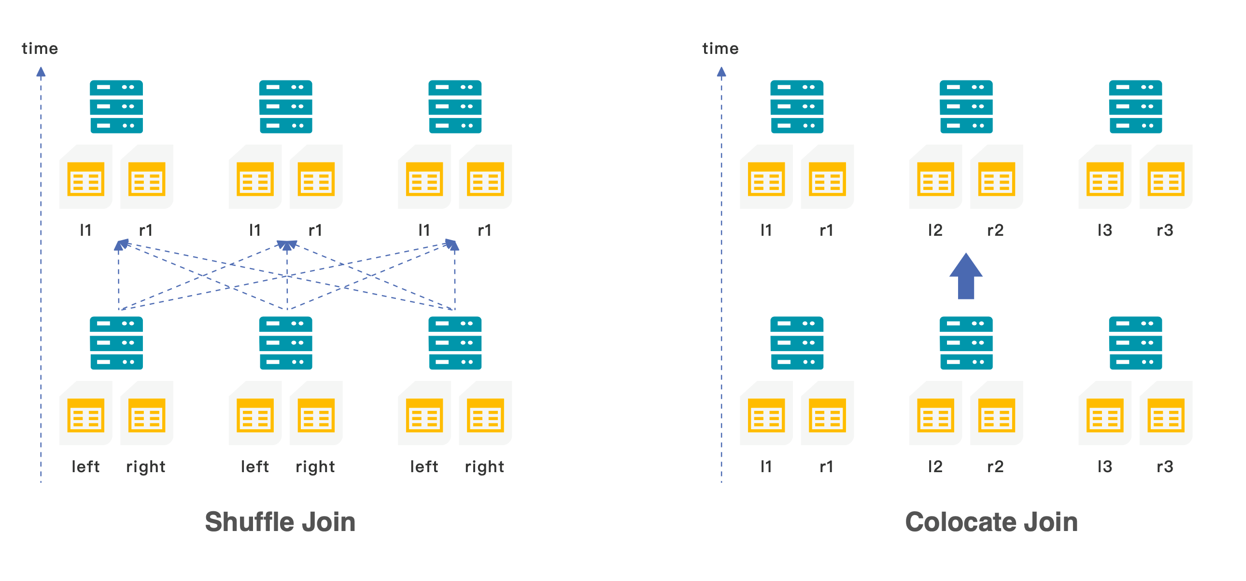
- 当小表与大表关联时,可以使用 boardcast join,小表会以广播的形式加载到不同节点的内存中
- 当大表与大表关联式,可以使用 shuffle join,两张表值相同的数据会 shuffle 到相同的机器上
- 为了避免 shuffle 带来的网络与 I/O 的开销,也可以在创建表示就将需要关联的数据存储在同一个 colocation group 中,使用 colocation join
CREATE TABLE tbl (k1 int, v1 int sum) DISTRIBUTED BY HASH(k1) BUCKETS 8 PROPERTIES( "colocate_with" = "group1" );目前大部分的 MPP 架构计算引擎,都采用基于规则的优化器(RBO)。为了更好的选择 join 的类型,StarRocks 提供了基于代价的优化器(CBO)。用户在开发业务 SQL 的时候,不需要考虑驱动表与被驱动表的顺序,也不需要考虑应该使用哪一种 join 的类型,CBO 会基于采集到的表的 metric,自动的进行查询重写,优化 join 的顺序与类型。高并发支撑
ClickHouse 对高并发的支撑
为了更深维度的挖掘数据的价值,就需要引入更多的分析师从不同的维度进行数据勘察。更多的使用者同时也带来了更高的 QPS 要求。对于互联网,金融等行业,几万员工,几十万员工很常见,高峰时期并发量在几千也并不少见。随着互联网化和场景化的趋势,业务逐渐向以用户为中心转型,分析的重点也从原有的宏观分析变成了用户维度的细粒度分析。传统的 MPP 数据库由于所有的节点都要参与运算,所以一个集群的并发能力与一个节点的并发能力相差无几。如果一定要提高并发量,可以考虑增加副本数的方式,但同时也增加了 RPC 的交互,对性能和物理成本的影响巨大。在 ClickHouse 中,我们一般不建议做高并发的业务查询,对于三副本的集群,通常会将 QPS 控制在 100 以下。ClickHouse 对高并发的业务并不友好,即使一个查询,也会用服务器一半的 CPU 去查询。一般来说,没有什么有效的手段可以直接提高 ClickHouse 的并发量,只能考虑通过将结果集写入 MySQL 中增加查询的并发度。StarRocks 对高并发的支撑
相较于 ClickHouse,StarRocks 可以支撑数千用户同时进行分析查询,在部分场景下,高并发能力能够达到万级。StarRocks 在数据存储层,采用先分区再分桶的策略,增加了数据的指向性,利用前缀索引可以快读对数据进行过滤和查找,减少磁盘的 I/O 操作,提升查询性能。
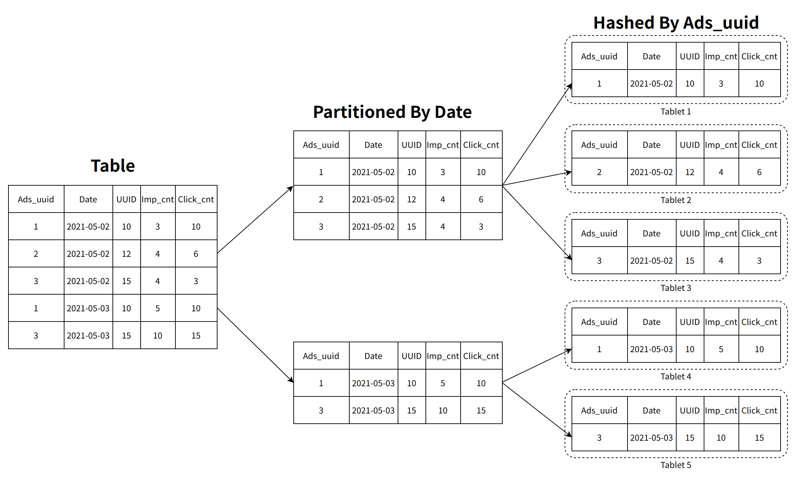
数据的高频变更
ClickHouse 中的数据更新
StarRocks 中的数据更新
| 特点 | 适用场景 | |
|
明细模型
|
用于保存和分析原始明细数据,以追加写为主要写入方式,数据写入后几乎无更新。
|
日志,操作记录,设备状态采样,时序类数据等
|
|
聚合模型
|
用于保存和分析汇总类(如:max、min、sum等)数据,不需要查询明细数据。数据导入后实时完成聚合,数据写入后几乎无更新。
|
按时间、地域、机构汇总数据等
|
|
Primary Key模型
|
支持基于主键的更新,delete-and-insert,大批量导入时保证高性能查询。用于保存和分析需要更新的数据。
|
状态会发生变动的订单,设备状态等
|
|
Unique 模型
|
支持基于主键的更新,Merge On Read,更新频率比主键模型更高。用于保存和分析需要更新的数据。
|
状态会发生变动的订单,设备状态等
|
集群的维护
ClickHouse 中的节点扩容与重分布
- 如果业务允许,可以给集群中的表设置 TTL,长时间保留的数据会逐渐被清理到,新增的数据会自动选择新节点,最后会达到负载均衡。
- 在集群中建立临时表,将原表中的数据复制到临时表,再删除原表。当数据量较大时,或者表的数量过多时,维护成本较高。同时无法应对实时数据变更。
- 通过配置权重的方式,将新写入的数据引导到新的节点。权重维护成本较高。
StarRocks 中的在线弹性扩缩容
ClickHouse 与 StarRocks 的性能对比
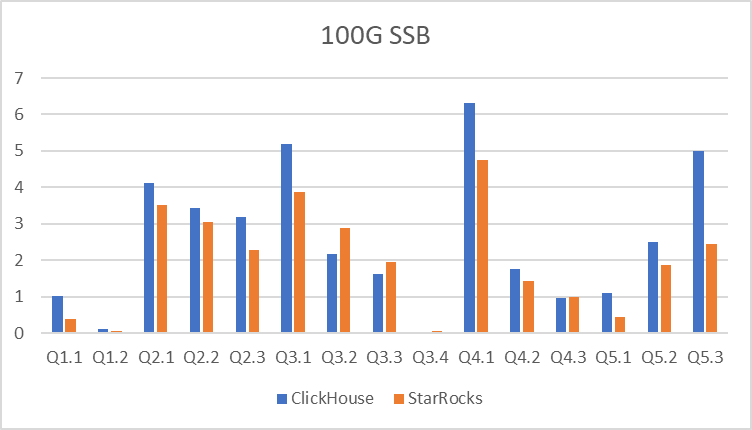
单表 SSB 性能测试
测试环境
|
机器
|
配置 (阿里云主机 3 台)
|
|
CPU
|
64 核 Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.5GHz
Cache Size: 36608 KB
|
|
内存
|
128G
|
|
网络贷款
|
100G
|
|
磁盘
|
SSD 高效云盘
|
|
CK 版本
|
21.9.5.16-2.x86_64 (18-Oct-2021)
|
|
StarRocks 版本
|
v1.19.2
|
测试数据
|
表名
|
行数
|
说明
|
|
lineorder
|
6 亿
|
SSB 商品订单表
|
|
customer
|
300 万
|
SSB 客户表
|
|
part
|
140 万
|
SSB 零部件表
|
|
supplier
|
20 万
|
SSB 供应商表
|
|
dates
|
2556
|
日期表
|
|
lineorder_flat
|
6 亿
|
SSB 打平后的宽表
|
测试结果
| ClickHouse | StarRocks | |
| Q1.1 | 1.022 | 0.37 |
| Q1.2 | 0.105 | 0.05 |
| Q2.1 | 4.107 | 3.51 |
| Q2.2 | 3.421 | 3.06 |
| Q2.3 | 3.175 | 2.28 |
| Q3.1 | 5.196 | 3.86 |
| Q3.2 | 2.159 | 2.88 |
| Q3.3 | 1.61 | 1.95 |
| Q3.4 | 0.036 | 0.05 |
| Q4.1 | 6.304 | 4.75 |
| Q4.2 | 1.761 | 1.43 |
| Q4.3 | 0.969 | 0.98 |
| Q5.1 | 1.107 | 0.45 |
| Q5.2 | 2.499 | 1.86 |
| Q5.3 | 5.009 | 2.44 |
多表 TPCH 性能测试
测试环境
|
机器
|
配置 (阿里云主机 3 台)
|
|
CPU
|
64 核 Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.5GHz
Cache Size: 36608 KB
|
|
内存
|
128G
|
|
网络贷款
|
100G
|
|
磁盘
|
SSD 高效云盘
|
|
StarRocks 版本
|
v1.19.2
|
测试数据
|
表名
|
行数
|
|
customer
|
15000000
|
|
lineitem
|
600037902
|
|
nation
|
25
|
|
orders
|
150000000
|
|
part
|
20000000
|
|
partsupp
|
80000000
|
|
region
|
5
|
|
supplier
|
1000000
|
测试结果
|
|
StarRocks
|
|
Q1
|
0.691s
|
|
Q2
|
0.635s
0.290s
|
|
Q3
|
1.445s
|
|
Q4
|
0.611s
|
|
Q5
|
1.361s
|
|
Q6
|
0.172s
|
|
Q7
|
2.777s
|
|
Q8
|
1.81s
|
|
Q9
|
3.470s
|
|
Q10
|
1.472s
|
|
Q11
|
0.241s
|
|
Q12
|
0.613s
|
|
Q13
|
2.102s
|
|
Q14
|
0.298s
|
|
Q16
|
0.468s
|
|
Q17
|
7.441s
|
|
Q18
|
2.479s
|
|
Q19
|
0.281s
|
|
Q20
|
2.422s
|
|
Q21
|
2.402s
|
|
Q22
|
1.110s
|
导入性能测试
数据集
导入方式
CREATE TABLE github_events_all AS github_events_local \
ENGINE = Distributed( \
perftest_3shards_1replicas, \
github, \
github_events_local, \
rand());CREATE TABLE github_events_hdfs
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4,
'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8,
'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11,
'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15,
'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19,
'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9,
'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
body String,
path String,
position Int32,
line Int32,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
locked UInt8,
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
comments UInt32,
author_association Enum('NONE' = 0, 'CONTRIBUTOR' = 1, 'OWNER' = 2, 'COLLABORATOR' = 3, 'MEMBER' = 4, 'MANNEQUIN' = 5),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
requested_teams Array(LowCardinality(String)),
head_ref LowCardinality(String),
head_sha String,
base_ref LowCardinality(String),
base_sha String,
merged UInt8,
mergeable UInt8,
rebaseable UInt8,
mergeable_state Enum('unknown' = 0, 'dirty' = 1, 'clean' = 2, 'unstable' = 3, 'draft' = 4),
merged_by LowCardinality(String),
review_comments UInt32,
maintainer_can_modify UInt8,
commits UInt32,
additions UInt32,
deletions UInt32,
changed_files UInt32,
diff_hunk String,
original_position UInt32,
commit_id String,
original_commit_id String,
push_size UInt32,
push_distinct_size UInt32,
member_login LowCardinality(String),
release_tag_name String,
release_name String,
review_state Enum('none' = 0, 'approved' = 1, 'changes_requested' = 2, 'commented' = 3, 'dismissed' = 4, 'pending' = 5)
)
ENGINE = HDFS('hdfs://XXXXXXXXXX:9000/user/stephen/data/github-02/*', 'TSV')LOAD LABEL github.xxzddszxxzz (
DATA INFILE("hdfs://XXXXXXXXXX:9000/user/stephen/data/github/*")
INTO TABLE `github_events`
(event_type,repo_name,created_at,file_time,actor_login,updated_at,action,comment_id,body,path,position,line,ref,ref_type,creator_user_login,number,title,labels,state,locked,assignee,assignees,comments,author_association,closed_at,merged_at,merge_commit_sha,requested_reviewers,requested_teams,head_ref,head_sha,base_ref,base_sha,merged,mergeable,rebaseable,mergeable_state,merged_by,review_comments,maintainer_can_modify,commits,additions,deletions,changed_files,diff_hunk,original_position,commit_id,original_commit_id,push_size,push_distinct_size,member_login,release_tag_name,release_name,review_state)
)
WITH BROKER oss_broker1 ("username"="user", "password"="password")
PROPERTIES
(
"max_filter_ratio" = "0.1"
);导入结果
|
|
|
并发数
|
总耗时(s)
|
单机平均速率(MB/s)
|
ck-test01 Server or be CPU峰值/平均值
|
ck-test02 Server or be CPU峰值/平均值
|
ck-test03 Server or be CPU峰值/平均值
|
|
clickhouse
|
单客户端
|
1
|
|
|
|
|
|
|
2
|
13154.497
|
37.20
|
223%/36%
|
358%/199%
|
197%/34%
| ||
|
4
|
4623.641
|
105.85
|
303%/127%
|
1140%/714%
|
330%/96%
| ||
|
8
|
3570.095
|
137.07
|
383%/128%
|
1595%/1070%
|
346%/122%
| ||
|
16
|
3277.488
|
149.32
|
361%/165%
|
1599% /1471%
|
440% /169%
| ||
|
3客户端
|
1
|
8211/9061/6652
|
73.54
|
352% /144%
|
415% /155%
|
365% /160%
| |
|
2
|
4501/5075/3452
|
108.74
|
405% /249%
|
443% /252%
|
430% /265%
| ||
|
4
|
2538/3046/1579
|
192.80
|
980% /492%
|
1186 % /523%
|
1054 % /477%
| ||
|
8
|
2863/3379/1850
|
170.91
|
1449% /466%
|
1229% /464%
|
1475% /582%
| ||
|
16
|
2986/3817/1772
|
163.87
|
1517%/466%
|
1491% /423%
|
1496% /655%
| ||
|
StarRocks
|
1
|
6420
|
76.22
|
305%/176%
|
324%/163%
|
305%/161%
| |
|
2
|
3632
|
134.73
|
453%/320%
|
444%/306%
|
455%/303
| ||
|
4
|
3900
|
125.47
|
728%/397%
|
363%/659%
|
709%/366%
| ||
|
8
|
3300
|
148.28
|
934%/523%
|
959%/521%
|
947%/520%
| ||
|
16
|
3050
|
160.44
|
824%/408%
|
889%%/394%
|
850%%/388%
|

结论
|








- 上一条: 详解布隆过滤器的原理和实现 2021-12-07
- 下一条: 全网最全-混合精度训练原理 2021-12-07
- 容器化 | ClickHouse Operator 原理解析 2021-10-14
- StarRocks 技术内幕:向量化编程精髓 2022-08-22
- StarRocks2.0发布,新一年,新启航,新极速! 2022-01-05
- TiDB VS MySQL 2022-06-22
- Learning by contributing!访 StarRocks Committer 周康、冯浩桉 2022-04-02


