分布式锁及其实现
对于Java中的锁大家肯定都很熟悉,在Java中synchronized关键字和ReentrantLock可重入锁在我们的代码中是经常见的,一般我们用其在多线程环境中控制对资源的并发访问,但是随着分布式的快速发展,本地的加锁往往不能满足我们的需要,在我们的分布式环境中上面加锁的方法就会失去作用。为了在分布式环境中也能实现本地锁的效果,人们提出了分布式锁的概念。
分布式锁
分布式锁场景
一般需要使用分布式锁的场景如下:
- 效率:使用分布式锁可以避免不同节点重复相同的工作,比如避免重复执行定时任务等;
- 正确性:使用分布式锁同样可以避免破坏数据正确性,如果两个节点在同一条数据上面操作,可能会出现并发问题。
分布式锁特点
一个完善的分布式锁需要满足以下特点:
- 互斥性:互斥是所得基本特性,分布式锁需要按需求保证线程或节点级别的互斥。;
- 可重入性:同一个节点或同一个线程获取锁,可以再次重入获取这个锁;
- 锁超时:支持锁超时释放,防止某个节点不可用后,持有的锁无法释放;
- 高效性:加锁和解锁的效率高,可以支持高并发;
- 高可用:需要有高可用机制预防锁服务不可用的情况,如增加降级;
- 阻塞性:支持阻塞获取锁和非阻塞获取锁两种方式;
- 公平性:支持公平锁和非公平锁两种类型的锁,公平锁可以保证安装请求锁的顺序获取锁,而非公平锁不可以。
分布式锁的实现
分布式锁常见的实现有三种实现,下文我们会一一介绍这三种锁的实现方式:
- 基于数据库的分布式锁;
- 基于Redis的分布式锁;
- 基于Zookeeper的分布式锁。
基于数据库的分布式锁
基于数据库的分布式锁可以有不同的实现方式,本文会介绍作者在实际生产中使用的一种数据库非阻塞分布式锁的实现方案。
方案概览
我们上面列举出了分布式锁需要满足的特点,使用数据库实现分布式锁也需要满足这些特点,下面我们来一一介绍实现方法:
- 互斥性:通过数据库update的原子性达到两次获取锁之间的互斥性;
- 可重入性:在数据库中保留一个字段存储当前锁的持有者;
- 锁超时:在数据库中存储锁的获取时间点和超时时长;
- 高效性:数据库本身可以支持比较高的并发;
- 高可用:可以增加主从数据库逻辑,提升数据库的可用性;
- 阻塞性:可以通过看门狗轮询的方式实现线程的阻塞;
- 公平性:可以添加锁队列,不过不建议,实现起来比较复杂。
表结构设计
数据库的表名为lock,各个字段的定义如下所示:
| 字段名名称 | 字段类型 | 说明 |
|---|---|---|
| lock_key | varchar | 锁的唯一标识符号 |
| lock_time | timestample | 加锁的时间 |
| lock_duration | integer | 锁的超时时长,单位可以业务自定义,通常为秒 |
| lock_owner | varchar | 锁的持有者,可以是节点或线程的唯一标识,不同可重入粒度的锁有不同的含义 |
| locked | boolean | 当前锁是否被占有 |
获取锁的SQL语句
获取锁的SQL语句分不同的情况,如果锁不存在,那么首先需要创建锁,并且创建锁的线程可以获取锁:
insert into lock(lock_key,lock_time,lock_duration,lock_owner,locked) values ('xxx',now(),1000,'ownerxxx',true)
如果锁已经存在,那么就尝试更新锁的信息,如果更新成功则表示获取锁成功,更新失败则表示获取锁失败。
update lock set
locked = true,
lock_owner = 'ownerxxxx',
lock_time = now(),
lock_duration = 1000
where
lock_key='xxx' and(
lock_owner = 'ownerxxxx' or
locked = false or
date_add(lock_time, interval lock_duration second) > now())
释放锁的SQL语句
当用户使用完锁需要释放的时候,可以直接更新locked标识位为false。
update lock set
locked = false,
where
lock_key='xxx' and
lock_owner = 'ownerxxxx' and
locked = true
看门狗
通过上面的步骤,我们可以实现获取锁和释放锁,那么看门狗又是做什么的呢?
大家想象一下,如果用户获取锁到释放锁之间的时间大于锁的超时时间,是不是会有问题?是不是可能会出现多个节点同时获取锁的情况?这个时候就需要看门狗了,看门狗可以通过定时任务不断刷新锁的获取事件,从而在用户获取锁到释放锁期间保持一直持有锁。
基于Redis的分布式锁
Redis的Java客户端Redisson实现了分布式锁,我们可以通过类似ReentrantLock的加锁-释放锁的逻辑来实现分布式锁。
RLock disLock = redissonClient.getLock("DISLOCK");
disLock.lock();
try {
// 业务逻辑
} finally {
// 无论如何, 最后都要解锁
disLock.unlock();
}
Redisson分布式锁的底层原理
如下图为Redisson客户端加锁和释放锁的逻辑:
加锁机制
从上图中可以看出来,Redisson客户端需要获取锁的时候,要发送一段Lua脚本到Redis集群执行,为什么要用Lua脚本呢?因为一段复杂的业务逻辑,可以通过封装在Lua脚本中发送给Redis,保证这段复杂业务逻辑执行的原子性。
Lua源码分析:如下为Redisson加锁的lua源码,接下来我们会对源码进行分析。
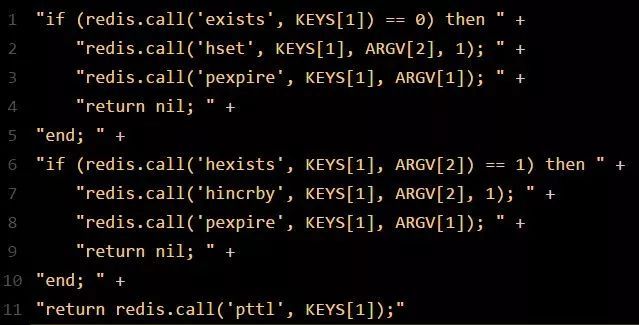
源码入参:Lua脚本有三个输入参数:KEYS[1]、ARGV[1]和ARGV[2],含义如下:
- KEYS[1]代表的是加锁的Key,例如RLock lock = redisson.getLock("myLock")中的“myLock”;
- ARGV[1]代表的就是锁Key的默认生存时间,默认30秒;
- ARGV[2]代表的是加锁的客户端的ID,类似于下面这样的:8743c9c0-0795-4907-87fd-6c719a6b4586:1。
Lua脚本及加锁步骤如下代码块所示,可以看出其大致原理为:
- 锁不存在的时候,创建锁并设置过期时间;
- 锁存在的时候,如果是重入场景则刷新锁的过期事件;
- 否则返回加锁失败和锁的过期时间。
-- 判断锁是不是存在
if (redis.call('exists', KEYS[1]) == 0) then
-- 添加锁,并且设置客户端和初始锁重入次数
redis.call('hincrby', KEYS[1], ARGV[2], 1);
-- 设置锁的超时事件
redis.call('pexpire', KEYS[1], ARGV[1]);
-- 返回加锁成功
return nil;
end;
-- 判断当前锁的持有者是不是请求锁的请求者
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
-- 当前锁被请求者持有,重入锁,增加锁重入次数
redis.call('hincrby', KEYS[1], ARGV[2], 1);
-- 刷新锁的过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
-- 返回加锁成功
return nil;
end;
-- 返回当前锁的过期时间
return redis.call('pttl', KEYS[1]);
看门狗逻辑
客户端1加锁的锁Key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?只要客户端1加锁成功,就会启动一个watchdog看门狗,这个后台线程,会每隔10秒检查一下,如果客户端1还持有锁Key,就会不断的延长锁Key的生存时间。
释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。就是每次都对myLock数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:“del myLock”命令,从Redis里删除这个Key。
而另外的客户端2就可以尝试完成加锁了。这就是所谓的分布式锁的开源Redisson框架的实现机制。
一般我们在生产系统中,可以用Redisson框架提供的这个类库来基于Redis进行分布式锁的加锁与释放锁。
Redisson分布式锁的缺陷
Redis分布式锁会有个缺陷,就是在Redis哨兵模式下:
- 客户端1对某个master节点写入了redisson锁,此时会异步复制给对应的slave节点。但是这个过程中一旦发生master节点宕机,主备切换,slave节点从变为了master节点。
- 客户端2来尝试加锁的时候,在新的master节点上也能加锁,此时就会导致多个客户端对同一个分布式锁完成了加锁。
- 系统在业务语义上一定会出现问题,导致各种脏数据的产生。
这个缺陷导致在哨兵模式或者主从模式下,如果master实例宕机的时候,可能导致多个客户端同时完成加锁。
基于Zookeeper的分布式锁
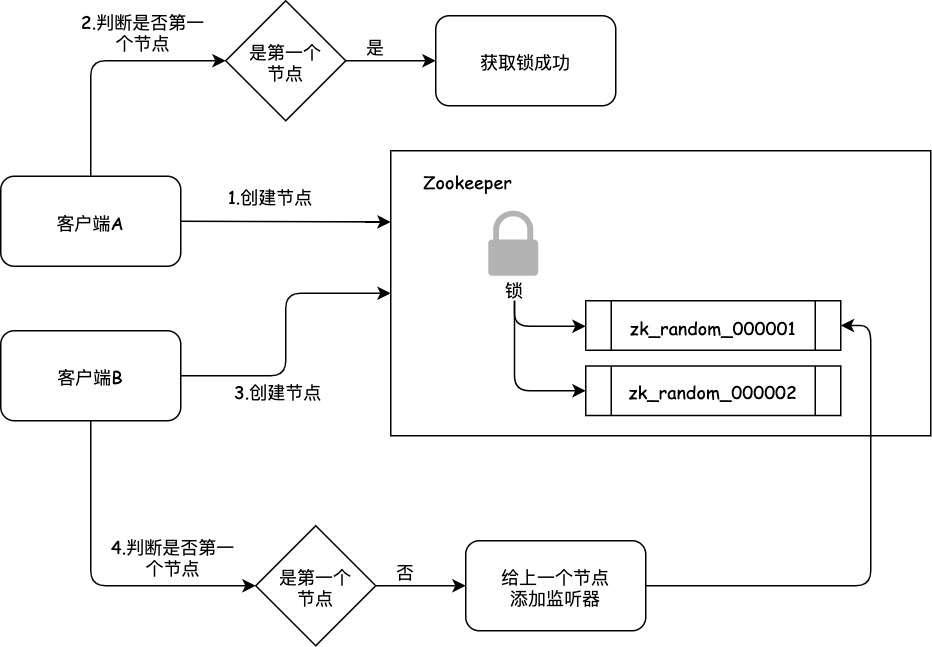
Zookeeper实现的分布式锁适用于引入Zookeeper的服务,如下所示,有两个服务注册到Zookeeper,并且都需要获取Zookeeper上的分布式锁,流程式什么样的呢?

步骤1
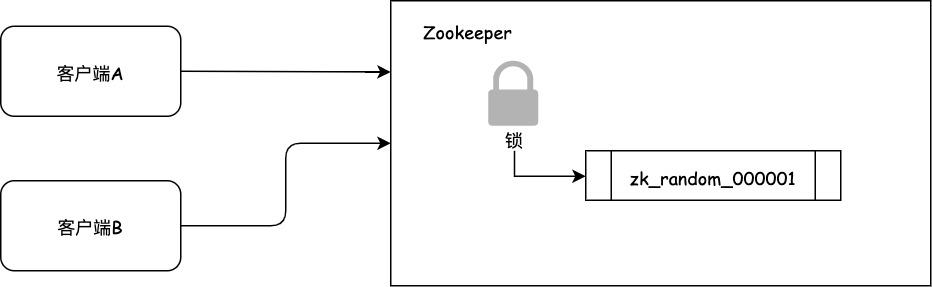
假设客户端A抢先一步,对ZK发起了加分布式锁的请求,这个加锁请求是用到了ZK中的一个特殊的概念,叫做“临时顺序节点”。简单来说,就是直接在"my_lock"这个锁节点下,创建一个顺序节点,这个顺序节点有ZK内部自行维护的一个节点序号。
- 比如第一个客户端来获取一个顺序节点,ZK内部会生成名称xxx-000001。
- 然后第二个客户端来获取一个顺序节点,ZK内部会生成名称xxx-000002。
最后一个数字都是依次递增的,从1开始逐次递增。ZK会维护这个顺序。所以客户端A先发起请求,就会生成出来一个顺序节点,如下所示:
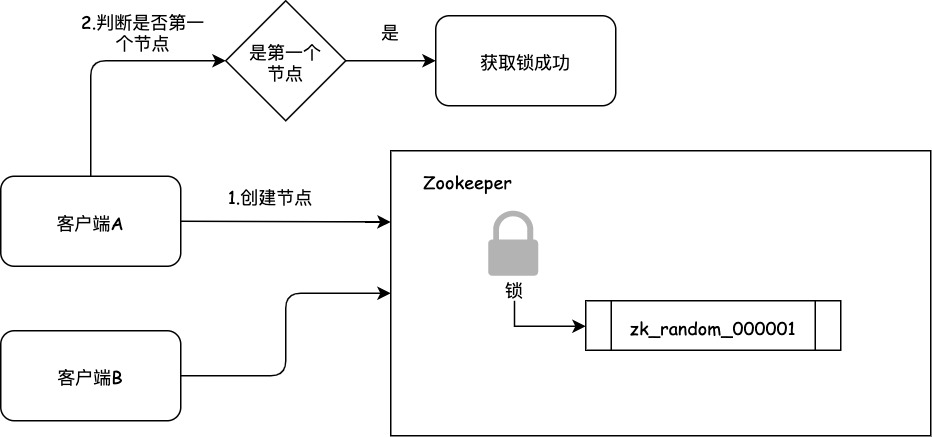
客户端A发起了加锁请求,会先加锁的node下生成一个临时顺序节点。因为客户端A是第一个发起请求,所以节点名称的最后一个数字是"1"。客户端A创建完好顺序节后,会查询锁下面所有的节点,按照末尾数字升序排序,判断当前节点的是不是第一个节点,如果是第一个节点则加锁成功。
步骤2
客户端A都加完锁了,客户端B过来想要加锁了,此时也会在锁节点下创建一个临时顺序节点,节点名称的最后一个数字是"2"。
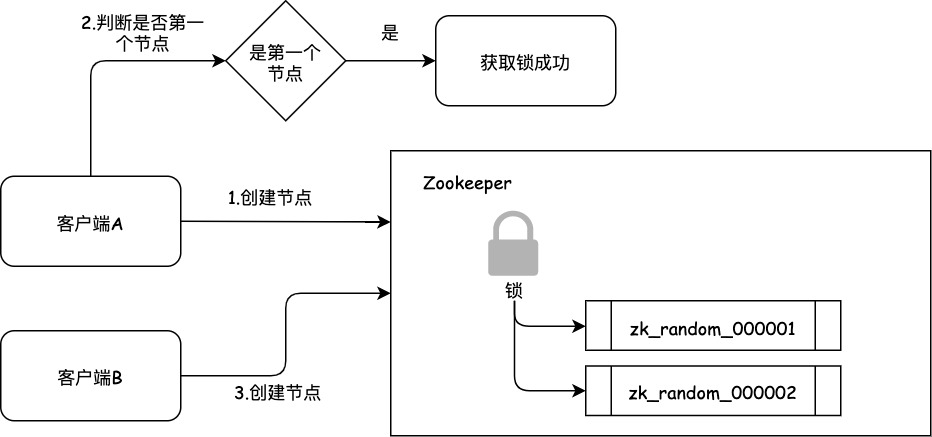
客户端B会判断加锁逻辑,查询锁节点下的所有子节点,按序号顺序排列,此时第一个是客户端A创建的那个顺序节点,序号为"01"的那个。所以加锁失败。加锁失败了以后,客户端B就会通过ZK的API对他的顺序节点的上一个顺序节点加一个监听器。ZK天然就可以实现对某个节点的监听。
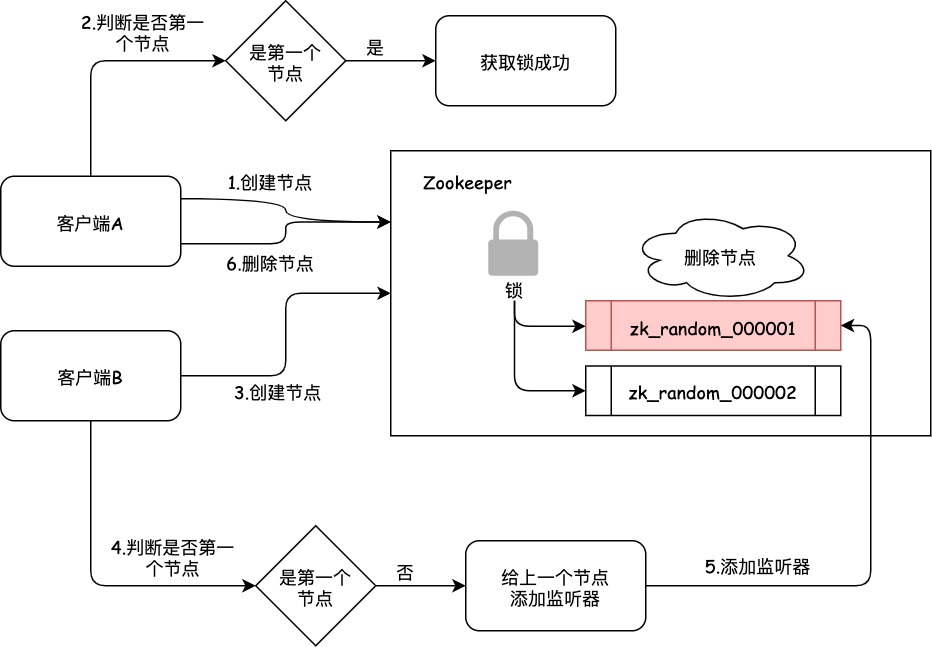
步骤3
客户端A加锁之后,可能处理了一些代码逻辑,然后就会释放锁。Zookeeper释放锁其实就是把客户端A创建的顺序节点zk_random_000001删除。
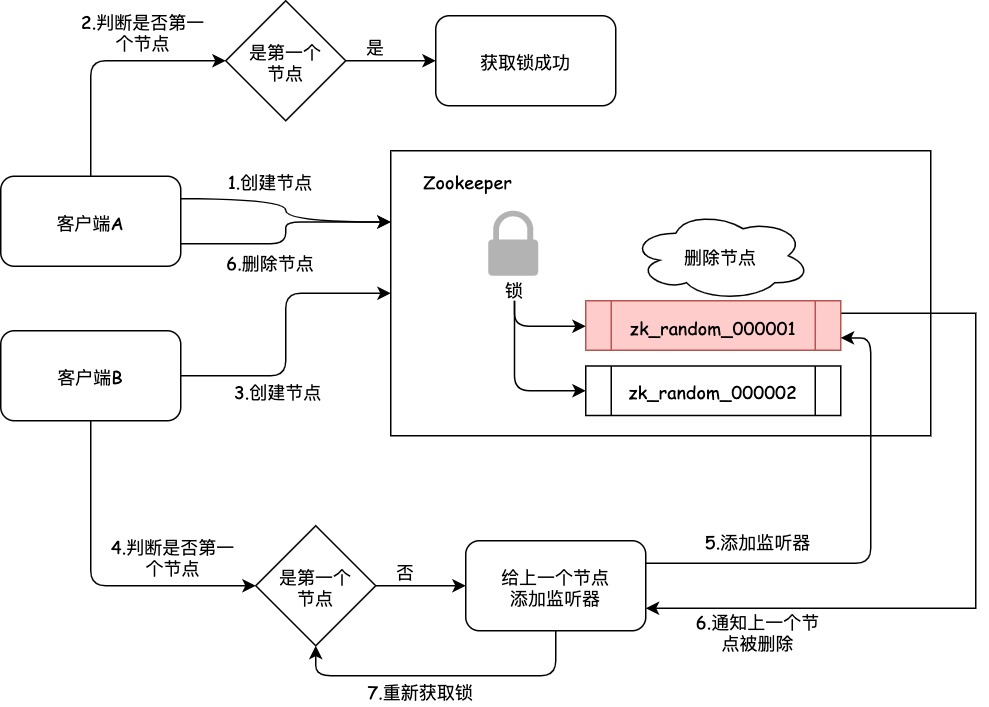
删除客户端A的节点之后,Zookeeper会负责通知监听这个节点的监听器,也就是客户端B之前添加监听器。客户端B的监听器知道了上一个顺序节点被删除,也就是排在他之前的某个客户端释放了锁。此时,就会客户端B会重新尝试去获取锁,也就是获取锁节点下的子节点集合,判断自身是不是第一个节点,从而获取锁。
三种锁的优缺点
基于数据库的分布式锁:
- 数据库并发性能较差;
- 阻塞式锁实现比较复杂;
- 公平锁实现比较复杂。
基于Redis的分布式锁:
- 主从切换的情况下可能出现多客户端获取锁的情况;
- Lua脚本在单机上具有原子性,主从同步时不具有原子性。
基于Zookeeper的分布式锁:
- 需要引入Zookeeper集群,比较重量级;
- 分布式锁的可重入粒度只能是节点级别;
参考文档
我是御狐神,欢迎大家关注我的微信公众号:wzm2zsd

本文最先发布至微信公众号,版权所有,禁止转载!
|








- 上一条: 云端干货|如何使用Docker制作镜像 2021-12-01
- 下一条: 工具 | PG 集群复制管理工具 repmgr 2021-12-02
- 分布式事务的十大神坑 2021-07-18
- 每一个程序员,都渴望成为一名分布式系统架构师 2021-07-11
- 灵活运用分布式锁解决数据重复插入问题 2021-07-27
- 说说Redis分布式锁是如何实现的! 2021-07-24
- OpenHarmony HarmonyOS-面向全场景的分布式操作系统 2021-06-27


