AI 框架部署方案之模型量化的损失分析
0 前言
在模型实际的业务落地过程中,大家是否遇到过这样的场景:千辛万苦训练出了精度满足业务需求的模型,终于可以上线啦!经过模型转换、量化、打包等等一系列复杂的流程后,成功部署到实际硬件平台上,模型终于可以运行了!然而一波操作猛如虎,模型精度与当初训练结果相比却下降了不少……一脸茫然,不知所措,完全不知该从何下手,也不知道怎样才能有效的恢复模型的训练精度。 本次分享将针对部署流程中导致精度下降的头号疑犯——模型量化进行分析,带大家一探精度损失的幕后真相。
欢迎关注开源深度学习推理引擎 - OpenPPL
本文将从以下三个方面进行“揭秘”: - 量化的基本过程 - 量化的损失来源 - 常见芯片的量化支持
1 量化的基本过程
模型量化粗略地可以分为在线量化(Quantization Aware Training, QAT)和离线量化(Post Training Quantization, PTQ)两大类。 虽然在线量化可以对量化后的模型精度提供更高的保障,但因其与模型的训练过程过于耦合,开发成本和门槛较高,在模型部署阶段采用更多的是另一种方式——离线量化。因此,本文主要针对采用离线量化方式对模型量化后,产生的精度损失进行分析。

图1 量化的三阶段步骤示意图
神经网络的量化本质上是将数据从连续空间 


输入数据 















当前较为成熟且使用较多的量化机制为线性均匀量化,指缩放函数 




在对称量化中, 



2 量化的损失来源
实际部署过程中,为了获得更大的压缩率和更快的运行速度,或受限于部署平台的计算单元类型,模型通常需要对整个网络模型的权值和激活值均进行定点量化。为了简化讨论,我们以一层卷积作为示例,采用线性均匀量化的方法,并假设 bias 已经通过优化融合到了 conv 的 weight 中。如下图所示,整层网络的计算误差主要来自于三部分:
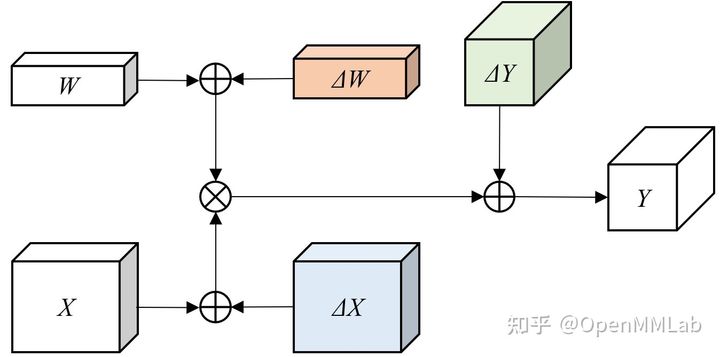
图2 量化的误差位置来源示意图
权值数据量化引入的误差,主要来自于不同量化方法的选取产生的误差。因 weights 的数值是确定可控的,其他来源的误差(如取整舍入误差)可以进行部分修正,属于可控误差,此处暂不进行详细的分析。
激活值数据量化引入的误差,主要来自于不同量化方法产生的误差和数值取整计算带来的误差。
计算过程中数据累计计算的误差,一方面来自多项数据进行累加和累乘等计算过程中,数值溢出和取整等计算带来的误差,另一方面来自定点芯片需要在定点域计算原本应该在浮点域计算的缩放函数和反向缩放函数,产生一定的计算误差。
为了进一步考虑上述误差是如何在计算过程中引入的,我们固定量化的比特位数 
Round 操作实现数据的离散化,将原始连续空间的数值映射到距离它数值最近的离散点。原始数据 



对于每一部分的量化误差, 其最大值不会超过两个相邻的量化离散值的间距,根据公式可知离散量化值之间的间距由原始数据的动态表示范围 

Clip 操作对 




我们来看一个服从正态分布的浮点数据进行线性均匀量化的过程示意:
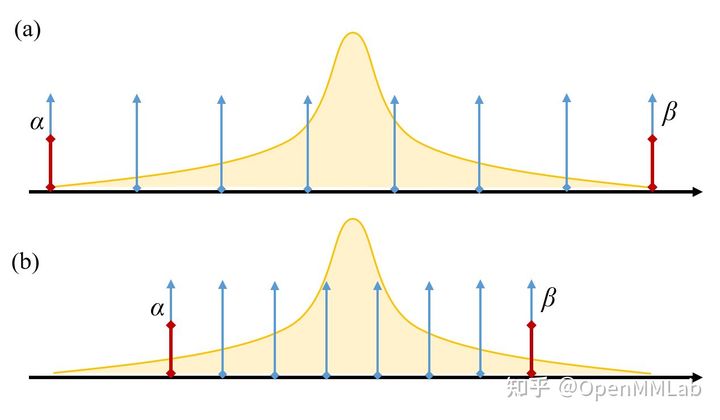
图3 浮点数据离散化示意图
在图3(a) 中,我们选取原始数据的真实最小值和最大值作为动态表示范围 







Scaling factor 和动态表示范围在不同的量化方法中有着不同的计算方法,例如在线性均匀量化中,二者之间的关系为:

通常确定了二者中的一个,另外一个可以根据公式计算得来。除了上述提到的 







3 常见芯片的量化支持
需要进行量化的模型,其部署目标平台多为边缘侧/终端侧,即对模型的大小和运行速度有一定限制和要求的移动端和嵌入式设备。较为常用的典型硬件平台有 NVIDIA Jetson 系列 GPU、Qualcomm Hexagon 系列 DSP、以及新兴的神经网络加速器。在加速器系列中,我们选取寒武纪(Cambricon) 的推理芯片为例,各类硬件平台对量化的支持情况如下表所示:
| 硬件平台 | 后端推理库 | 权值数据量化支持类型 | 是否支持外部参数写入 |
|---|---|---|---|
| NVIDIA Jetson [1] | TensorRT | per-tensor & per-channel | Yes |
| Quanlcomm Hexagon DSP [2] | SNPE | per-tensor | No |
| Cambricon MLU [3] | CNRT | per-tensor & per-channel | Yes |
其中 per-tensor 的量化方法也称 per-layer,指对于给定的网络层的 weight tensor 中的所有数据共享一个量化参数;per-channel 也称 per-axis,指对于给定网络层的 weight tensor,每一个 axis 对应一个 channel,每个 channel 有自己独立的量化参数。通常情况下,per-channel 因为量化的粒度更细致,量化参数的自由度更高,往往更优于 per-tensor 的量化精度。 NVIDIA TensorRT 在对权值(weights) 的量化上支持 per-tensor 和 per-channel 两种方式,采用对称最大值的方法[4];对于激活值(activations) 只支持 per-tensor 的方式,采用 KL-divergence 的方法进行量化;量化参数既支持内部自动生成,也支持外部指定,支持 weights 和 activations 采用不同的指定方式。更为详细的机制解析和使用方式已有官方技术文档[5]和很多文章[6]进行了分析讲解,感兴趣的同学可以自行阅读,此处不再赘述。 Quanlcomm Hexagon DSP 的官方后端推理库 SNPE 只支持 per-tensor 的量化方式,采用非对称最大最小值的方法[7],并提供 Enhanced Quantization Mode 进行精度优化,暂不支持外部量化参数写入。为了补偿SNPE在使用时的量化精度损失,Quanlcomm 推出了自己的模型量化压缩工具 AIMET[8],支持 DFQ[9]、AdaRound[10]等量化算法,依托于 AIMET 也可以实现部分外部量化参数的写入。通过对AIMET源码的阅读,我们也可以获得如何把量化参数写入SNPE后端的方法。寒武纪 MLU 系列加速器的官方后端为 CNRT,同样支持 per-tensor 和 per-channel 两种量化方法,也支持外部参数的写入,但只支持 weights 和 activations 采用同样的指定方式,即同时由内部生成或同时由外部指定。我们可以看到,当前的硬件平台除了自身的工具链提供的原生量化方法外,大部分均支持外部参数的写入,通过指定 scaling_factor 或动态范围 
4 结语
本文对量化过程中的误差来源进行了粗略的归类,理解这些误差如何在计算过程中引入,并对各个误差项之间的耦合和影响关系进行了分析。当前很多量化算法和优化策略本质上还是在寻找一些减小这些误差项的方法,并在其中寻找平衡点。例如,AdaRound 算法不再采用四舍五入的方法,而是采用一种自使用的策略动态决定向上取整还是向下取整,从而减小 Round 操作引入的误差项 


|








- 上一条: Flutter UI自动化测试技术方案选型与探索 2021-11-04
- 下一条: Kubernetes 上调试 distroless 容器 2021-11-04
- 做AI框架必懂的知识 2022-02-11
- AI专家一席谈:复用算法、模型、案例,AI Gallery带你快速上手应用开发 2021-09-27
- DB4AI: 数据库驱动AI 2022-04-13
- 无网低算力也能开发AI模型?飞桨EasyDL桌面版开创本地AI应用新体验 2022-01-04
- 使用Colossal-AI分布式训练BERT模型 2022-05-12


