新一代日志型系统在 SOFAJRaft 中的应用
 📄
📄
文|黄章衡(SOFAJRaft 项目组)
福州大学 19 级计算机系
研究方向|分布式中间件、分布式数据库
Github 主页|https://github.com/hzh0425
校对|冯家纯(SOFAJRaft 开源社区负责人)
本文 9402 字 阅读 18 分钟
▼
PART. 1 项目介绍
1.1 SOFAJRaft 介绍
SOFAJRaft 是一个基于 RAFT 一致性算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。使用 SOFAJRaft 你可以专注于自己的业务领域,由 SOFAJRaft 负责处理所有与 RAFT 相关的技术难题,并且 SOFAJRaft 非常易于使用,你可以通过几个示例在很短的时间内掌握它。
Github 地址:
https://github.com/sofastack/sofa-jraft
1.2 任务要求
**目标:*当前 LogStorage 的实现,采用 index 与 data 分离的设计,我们将 key 和 value 的 offset 作为索引写入 rocksdb,同时日志条目(data)*写入 Segment Log。因为使用 SOFAJRaft 的用户经常也使用了不同版本的 rocksdb,这就要求用户不得不更换自己的 rocksdb 版本来适应 SOFAJRaft, 所以我们希望做一个改进:移除对 rocksdb 的依赖,构建出一个纯 Java 实现的索引模块。
PART. 2 前置知识
Log Structured File Systems
如果学习过类似 Kafka 等消息队列的同学,对日志型系统应该并不陌生。
如图所示,我们可以在单机磁盘上存储一些日志型文件,这些文件中一般包含了旧文件和新文件的集合。区别在于 Active Data File 一般是映射到内存中的并且正在写入的新文件*(基于 mmap 内存映射技术)*,而 Older Data File 是已经写完了,并且都 Flush 到磁盘上的旧文件,当一块 Active File 写完之后,就会将其关闭,并打开一个新的 Active File 继续写。
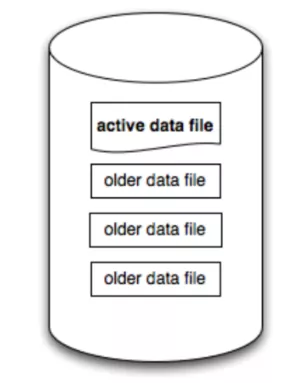
并且每一次的写入,每个 Log Entry 都会被 Append 到 Active File 的尾部,而 Active File 往往会用 mmap 内存映射技术,将文件映射到 os Page Cache 里,因此每一次的写入都是内存顺序写,性能非常高。
终上所述,一块 File 无非就是一些 Log Entry 的集合,如图所示:
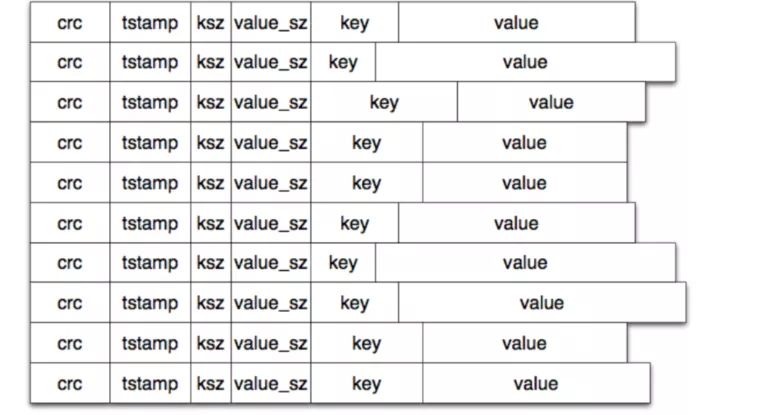
同时,仅仅将日志写入到 File 中还不够,因为当需要搜索日志的时候,我们不可能顺序遍历每一块文件去搜索,这样性能就太差了。所以我们还需要构建这些文件的 “目录”,也即索引文件。这里的索引本质上也是一些文件的集合,其存储的索引项一般是固定大小的,并提供了 LogEntry 的元信息,如:
- File_Id : 其对应的 LogEntry 存储在哪一块 File 中
- Value_sz : LogEntry 的数据大小
(注: LogEntry 是被序列化后, 以二进制的方式存储的)
- Value_pos: 存储在对应 File 中的哪个位置开始
- 其他的可能还有 crc,时间戳等......

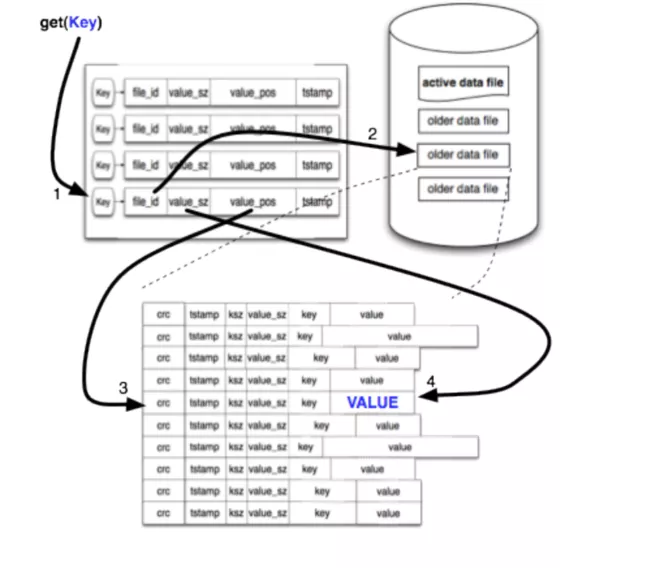
那么依据索引文件的特性,就能够非常方便的查找 IndexEntry。
- 日志项 IndexEntry 是固定大小的
- IndexEntry 存储了 LogEntry 的元信息
- IndexEntry 具有单调递增的特性
举例,如果要查找 LogIndex = 4 的日志:
- 第一步,根据 LogIndex = 4,可以知道索引存储的位置:IndexPos = IndexEntrySize * 4
- 第二步,根据 IndexPos,去索引文件中,取出对应的索引项 IndexEntry
- 第三步,根据 IndexEntry 中的元信息,如 File_Id、Pos 等,到对应的 Data File 中搜索
- 第四步,找到对应的 LogEntry
内存映射技术 mmap
上文一直提到了一个技术:将文件映射到内存中,在内存中写 Active 文件,这也是日志型系统的一个关键技术,在 Unix/Linux 系统下读写文件,一般有两种方式。
传统文件 IO 模型
一种标准的 IO 流程, 是 Open 一个文件,然后使用 Read 系统调用读取文件的一部分或全部。这个 Read 过程是这样的:内核将文件中的数据从磁盘区域读取到内核页高速缓冲区,再从内核的高速缓冲区读取到用户进程的地址空间。这里就涉及到了数据的两次拷贝:磁盘->内核,内核->用户态。
而且当存在多个进程同时读取同一个文件时,每一个进程中的地址空间都会保存一份副本,这样肯定不是最优方式的,造成了物理内存的浪费,看下图:
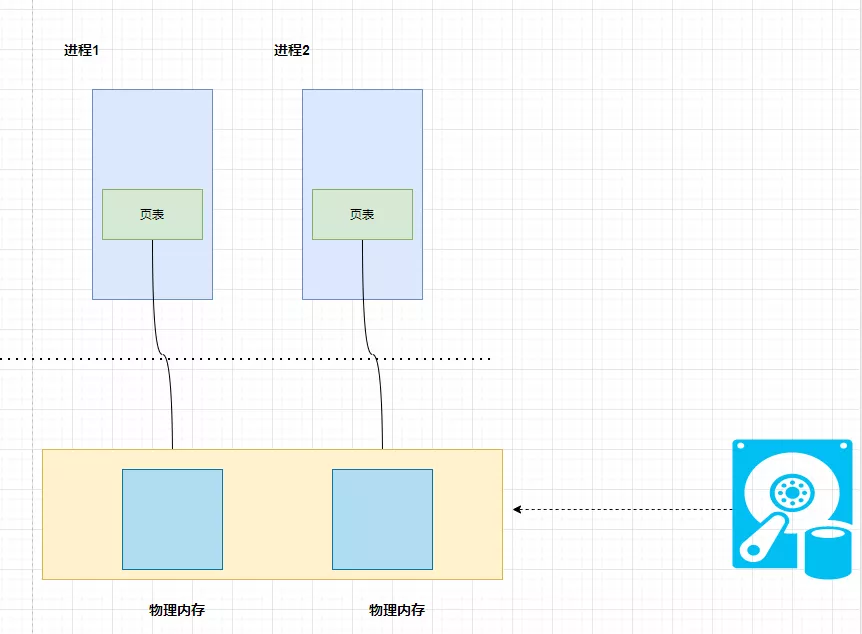
内存映射技术
第二种方式就是使用内存映射的方式
具体操作方式是:Open 一个文件,然后调用 mmap 系统调用,将文件内容的全部或一部分直接映射到进程的地址空间*(直接将用户进程私有地址空间中的一块区域与文件对象建立映射关系)*,映射完成后,进程可以像访问普通内存一样做其他的操作,比如 memcpy 等等。mmap 并不会预先分配物理地址空间,它只是占有进程的虚拟地址空间。
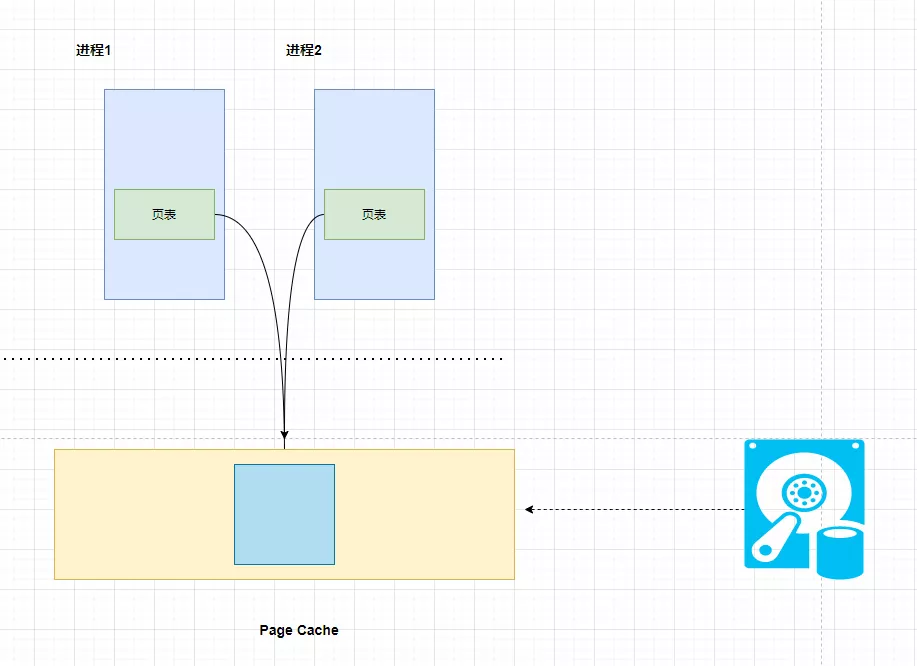
当第一个进程访问内核中的缓冲区时,因为并没有实际拷贝数据,这时 MMU 在地址映射表中是无法找到与地址空间相对应的物理地址的,也就是 MMU 失败,就会触发缺页中断。内核将文件的这一页数据读入到内核高速缓冲区中,并更新进程的页表,使页表指向内核缓冲中 Page Cache 的这一页。之后有其他的进程再次访问这一页的时候,该页已经在内存中了,内核只需要将进程的页表登记并且指向内核的页高速缓冲区即可,如下图所示:
对于容量较大的文件来说*(文件大小一**般需要限制在 1.5~2G 以下)*,采用 mmap 的方式其读/写的效率和性能都非常高。
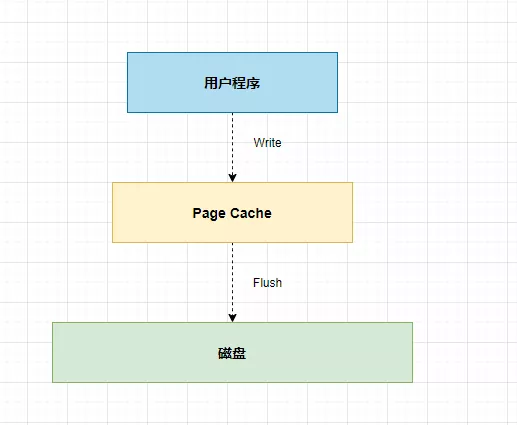
当然,需要如果采用了 mmap 内存映射,此时调用 Write 并不是写入磁盘,而是写入 Page Cache 里。因此,如果想让写入的数据保存到硬盘上,我们还需要考虑在什么时间点 Flush 最合适 (后文会讲述)。
PART. 3 架构设计
3.1 SOFAJRaft 原有日志系统架构
下图是 SOFAJRaft 原有日志系统整体上的设计:
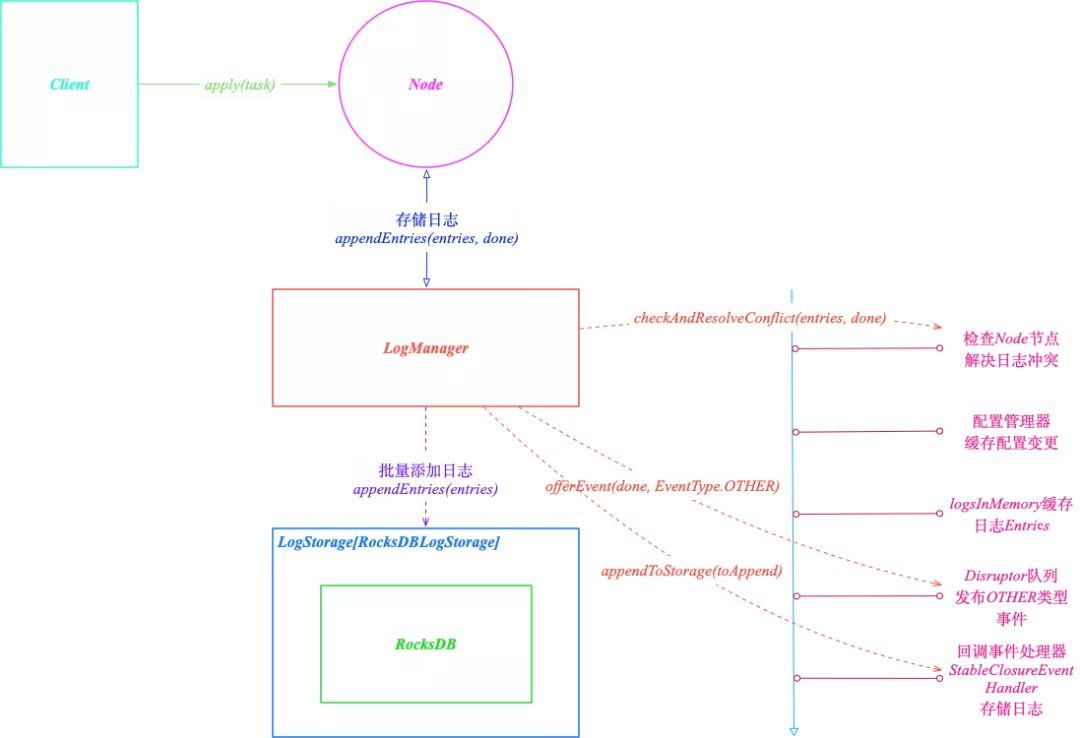
其中 LogManager 提供了和日志相关的接口,如:
/**
* Append log entry vector and wait until it's stable (NOT COMMITTED!)
*
* @param entries log entries
* @param done callback
*/
void appendEntries(final Listentries, StableClosure done);
/**
* Get the log entry at index.
*
* @param index the index of log entry
* @return the log entry with {@code index}
*/
LogEntry getEntry(final long index);
/**
* Get the log term at index.
*
* @param index the index of log entry
* @return the term of log entry
*/
long getTerm(final long index);
实际上,当上层的 Node 调用这些方法时,LogManager 并不会直接处理,而是通过 OfferEvent*( done, EventType )* 将事件发布到高性能的并发队列 Disruptor 中等待调度执行。
因此,可以把 LogManager 看做是一个 “门面”,提供了访问日志的接口,并通过 Disruptor 进行并发调度。
「注」: SOFAJRaft 中还有很多地方都基于 Disruptor 进行解耦,异步回调,并行调度, 如 SnapshotExecutor、NodeImpl 等,感兴趣的小伙伴可以去社区一探究竟,对于学习 Java 并发编程有很大的益处 !
关于 Disruptor 并发队列的介绍,可以看这里:
https://tech.meituan.com/2016/11/18/disruptor.html
最后,实际存储日志的地方就是 LogManager 的调用对象,LogStorage。
而 LogStorage 也是一个接口:
/**
* Append entries to log.
*/
boolean appendEntry(final LogEntry entry);
/**
* Append entries to log, return append success number.
*/
int appendEntries(final Listentries);
/**
* Delete logs from storage's head, [first_log_index, first_index_kept) will
* be discarded.
*/
boolean truncatePrefix(final long firstIndexKept);
/**
* Delete uncommitted logs from storage's tail, (last_index_kept, last_log_index]
* will be discarded.
*/
boolean truncateSuffix(final long lastIndexKept);
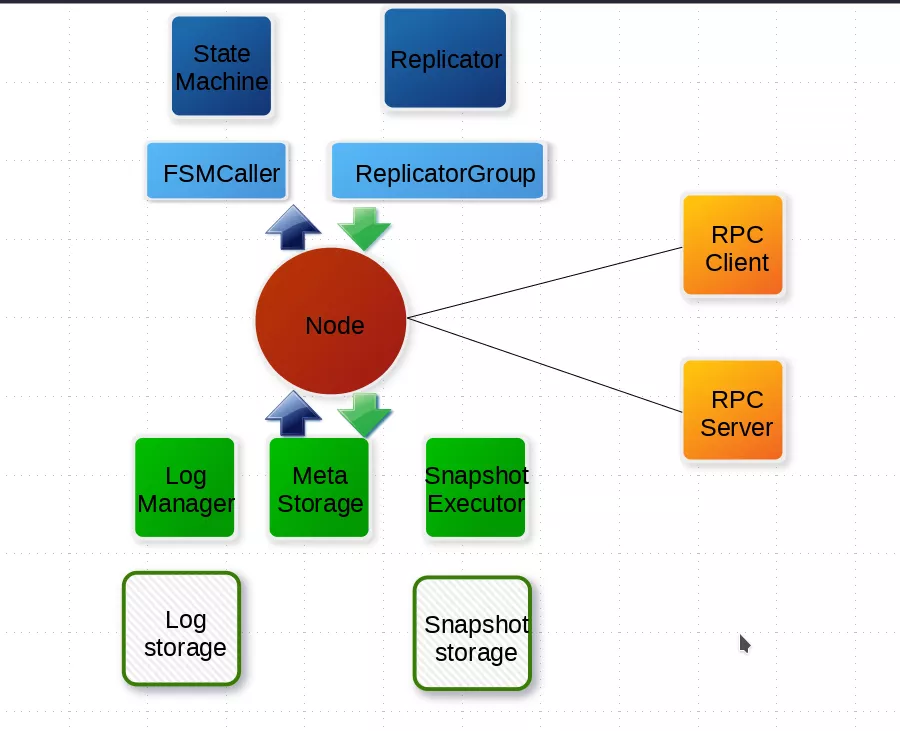
在原有体系中,其默认的实现类是 RocksDBLogStorage,并且采用了索引和日志分离存储的设计,索引存储在 RocksDB 中,而日志存储在 SegmentFile 中。
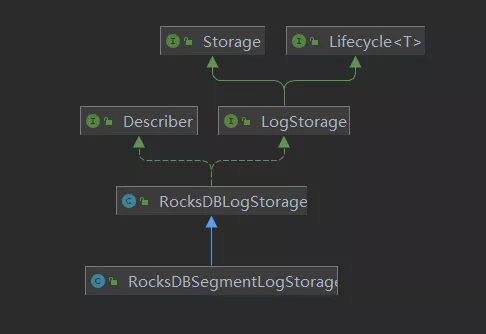
如图所示,RocksDBSegmentLogStorage 继承了 RocksDBLogStorageRocksDBSegmentLogStorage 负责日志的存储 RocksDBLogStorage 负责索引的存储。
3.2 项目任务分析
通过上文对原有日志系统的描述,结合该项目的需求,可以知道本次任务我需要做的就是基于 Java 实现一个新的 LogStorage,并且能够不依赖 RocksDB。实际上日志和索引存储在实现的过程中会有很大的相似之处。例如,文件内存映射 mmap、文件预分配、异步刷盘等。因此我的任务不仅仅是做一个新的索引模块,还需要做到以下:
- 一套能够被复用的文件系统, 使得日志和索引都能够直接复用该文件系统,实现各自的存储
- 兼容 SOFAJRaft 的存储体系,实现一个新的 LogStorage,能够被 LogManager 所调用
- 一套高性能的存储系统,需要对原有的存储系统在性能上有较大的提升
- 一套代码可读性强的存储系统,代码需要符合 SOFAJRaft 的规范
......
在本次任务中,我和导师在存储架构的设计上进行了多次的讨论与修改,最终设计出了一套完整的方案,能够完美的契合以上的所有要求。
3.3 改进版的日志系统
架构设计
下图为改进版本的日志系统,其中 DefaultLogStorage 为上文所述 LogStorage 的实现类。三大 DB 为逻辑上的存储对象, 实际的数据存储在由 FileManager 所管理的 AbstractFiles 中,此外 ServiceManager 中的 Service 起到辅助的效果,例如 FlushService 可以提供刷盘的作用。
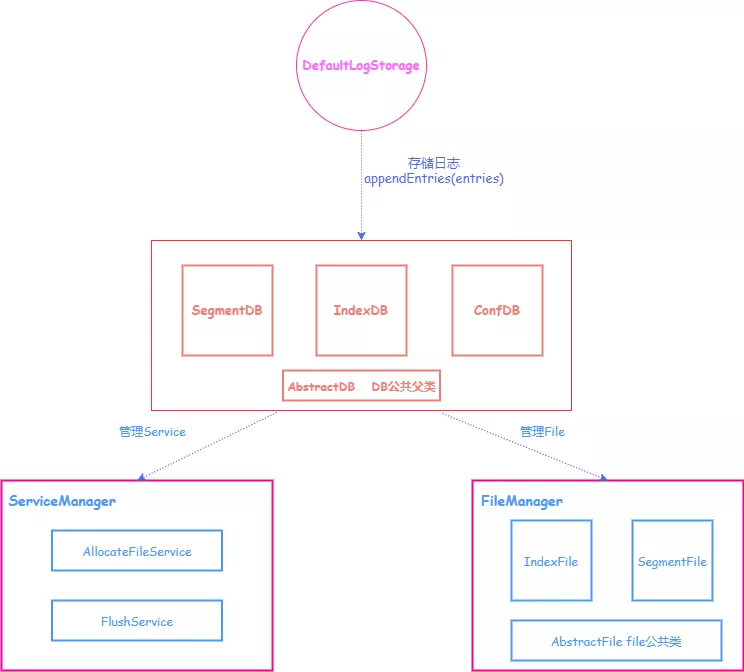
为什么需要三大 DB 来存储数据呢? ConfDB 是干什么用的?
以下这幅图可以很好的解释三大 DB 的作用:
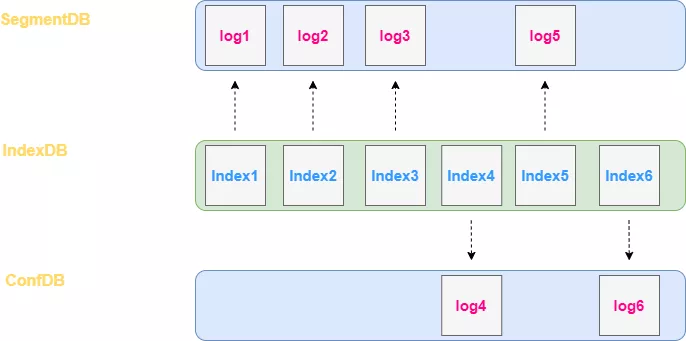
因为在 SOFAJraft 原有的存储体系中,为了提高读取 Configuration 类型的日志的性能,会将 Configuration 类型的日志和普通日志分离存储。因此,这里我们需要一个 ConfDB 来存储 Configuration 类型的日志。
3.4 代码模块说明
代码主要分为四大模块:
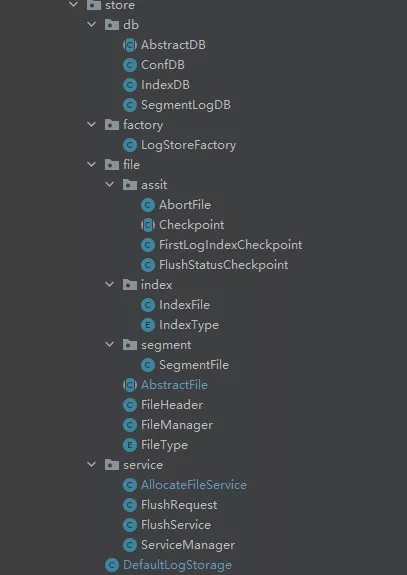
- db 模块 (db 文件夹下)
- File 模块 (File 文件夹下)
- service 模块 (service 文件夹下)
- 工厂模块 (factory 文件夹下)
- DefaultLogStorage 就是上文所述的新的 LogStorage 实现类
3.5 性能测试
测试背景
- 操作系统:Window
- 写入数据总大小:8G
- 内存:24G
- CPU:4 核 8 线程
- 测试代码:
#DefaultLogStorageBenchmark
数据展示
Log Number 代表总共写入了 524288 条日志
Log Size 代表每条日志的大小为 16384
Total size 代表总共写入了 8589934592 (8G) 大小的数据
写入耗时 (45s)
读取耗时 (5s)
Test write:
Log number :524288
Log Size :16384
Cost time(s) :45
Total size :8589934592
Test read:
Log number :524288
Log Size :16384
Cost time(s) :5
Total size :8589934592
Test done!
PART. 4 系统亮点
4.1 日志系统文件管理
在 2.1 节中,我介绍了一个日志系统的基本概念,回顾一下:
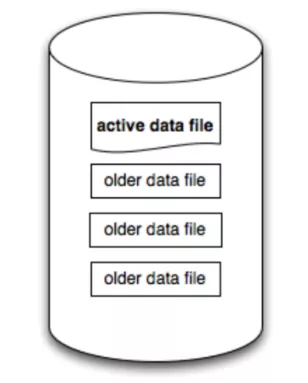
而本项目日志文件是如何管理的呢? 如图所示,每一个 DB 的所有日志文件*(IndexDB 对应 IndexFile, SegmentDB 对应 SegmentFile)* 都由 File Manager 统一管理。
以 IndexDB 所使用的的 IndexFile 为例,假设每个 IndexFile 大小为 126,其中 fileHeader = 26 bytes,文件能够存储十个索引项,每个索引项大小 10 bytes。

而 FileHeader 存储了一块文件的基本元信息:
// 第一个存储元素的索引 : 对应图中的 StartIndexd
private volatile long FirstLogIndex = BLANK_OFFSET_INDEX;
// 该文件的偏移量,对应图中的 BaseOffset
private long FileFromOffset = -1;
因此,FileManager 就能根据这两个基本的元信息,对所有的 File 进行统一的管理,这么做有以下的好处:
- 统一的管理所有文件
- 方便根据 LogIndex 查找具体的日志在哪个文件中, 因为所有文件都是根据 FirstLogIndex 排列的,很显然在这里可以基于二分算法查找:
int lo = 0, hi = this.files.size() - 1;
while (lo <= hi) {
final int mid = (lo + hi) >>> 1;
final AbstractFile file = this.files.get(mid);
if (file.getLastLogIndex() < logIndex) {
lo = mid + 1;
} else if (file.getFirstLogIndex() > logIndex) {
hi = mid - 1;
} else {
return this.files.get(mid);
}
}
- 方便 Flush 刷盘*(4.2 节中会提到)*
4.2 Group Commit - 组提交
在章节 2.2 中我们聊到,因为内存映射技术 mmap 的存在,Write 之后不能直接返回,还需要 Flush 才能保证数据被保存到了磁盘上,但同时也不能直接写回磁盘,因为磁盘 IO 的速度极慢,每写一条日志就 Flush 一次的话性能会很差。
因此,为了防止磁盘 '拖后腿',本项目引入了 Group commit 机制,Group commit 的思想是延迟 Flush,先尽可能多的写入一批的日志到 Page Cache 中,然后统一调用 Flush 减少刷盘的次数,如图所示:
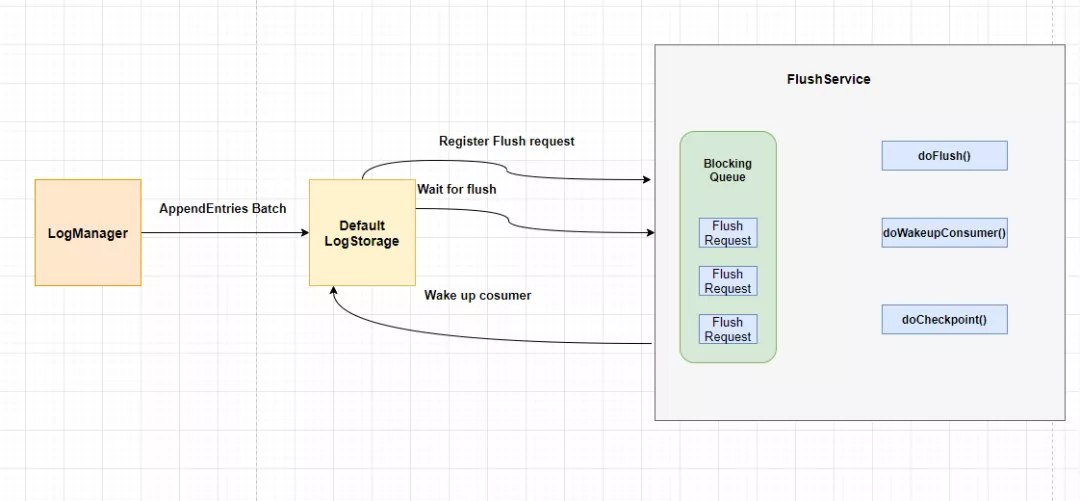
- LogManager 通过调用 appendEntries() 批量写入日志
- DefaultLogStorage 通过调用 DB 的接口写入日志
- DefaultLogStorage 注册一个 FlushRequest 到对应 DB 的 FlushService 中,并阻塞等待,FlushRequest 包含了期望刷盘的位置 ExpectedFlushPosition。
private boolean waitForFlush(final AbstractDB logDB, final long exceptedLogPosition,
final long exceptedIndexPosition) {
try {
final FlushRequest logRequest = FlushRequest.buildRequest(exceptedLogPosition);
final FlushRequest indexRequest = FlushRequest.buildRequest(exceptedIndexPosition);
// 注册 FlushRequest
logDB.registerFlushRequest(logRequest);
this.indexDB.registerFlushRequest(indexRequest);
// 阻塞等待唤醒
final int timeout = this.storeOptions.getWaitingFlushTimeout();
CompletableFuture.allOf(logRequest.getFuture(), indexRequest.getFuture()).get(timeout, TimeUnit.MILLISECONDS);
} catch (final Exception e) {
LOG.error(.....);
return false;
}
}
- FlushService 刷到 expectedFlushPosition 后,通过 doWakeupConsumer() 唤醒阻塞等待的 DefaultLogStorage
while (!isStopped()) {
// 阻塞等待刷盘请求
while ((size = this.requestQueue.blockingDrainTo(this.tempQueue, QUEUE_SIZE, WAITING_TIME,
TimeUnit.MILLISECONDS)) == 0) {
if (isStopped()) {
break;
}
}
if (size > 0) {
.......
// 执行刷盘
doFlush(maxPosition);
// 唤醒 DefaultLogStorage
doWakeupConsumer();
.....
}
}
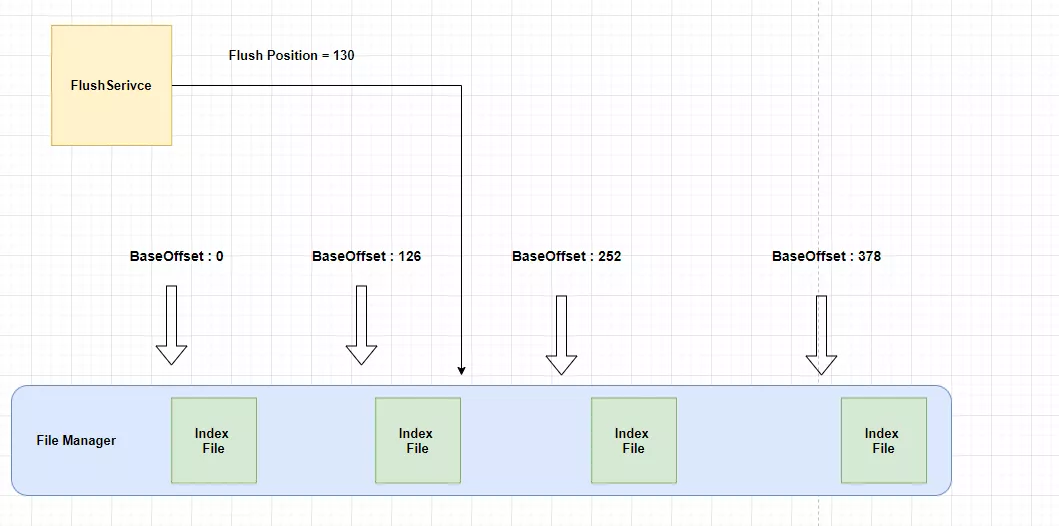
那么 FlushService 到底是如何配合 FileManager 进行刷盘的呢? 或者应该问 FlushService 是如何找到对应的文件进行刷盘?
实际上在 FileManager 维护了一个变量 FlushedPosition,就代表了当前刷盘的位置。从 4.1 节中我们了解到 FileManager 中每一块 File 的 FileHeader 都记载了当前 File 的 BaseOffset。因此,我们只需要根据 FlushedPosition,查找其当前在哪一块 File 的区间里,便可找到对应的文件,例如:
当前 FlushPosition = 130,便可以知道当前刷到了第二块文件。
4.3 文件预分配
当日志系统写满一个文件,想要打开一个新文件时,往往是一个比较耗时的过程。所谓文件预分配,就是事先通过 mmap 映射一些空文件存在容器中,当下一次想要 Append 一条 Log 并且前一个文件用完了,我们就可以直接到这个容器里面取一个空文件,在这个项目中直接使用即可。有一个后台的线程 AllocateFileService 在这个 Allocator 中,我采用的是典型的生产者消费者模式,即用了 ReentrantLock + Condition 实现了文件预分配。
// Pre-allocated files
private final ArrayDequeblankFiles = new ArrayDeque<>();
private final Lock allocateLock
private final Condition fullCond
private final Condition emptyCond
其中 fullCond 用于代表当前的容器是否满了,emptyCond 代表当前容器是否为空。
private void doAllocateAbstractFileInLock() throws InterruptedException {
this.allocateLock.lock();
try {
// 如果容器满了, 则阻塞等待, 直到被唤醒
while (this.blankAbstractFiles.size() >= this.storeOptions.getPreAllocateFileCount()) {
this.fullCond.await();
}
// 分配文件
doAllocateAbstractFile0();
// 容器不为空, 唤醒阻塞的消费者
this.emptyCond.signal();
} finally {
this.allocateLock.unlock();
}
}
public AbstractFile takeEmptyFile() throws Exception {
this.allocateLock.lock();
try {
// 如果容器为空, 当前消费者阻塞等待
while (this.blankAbstractFiles.isEmpty()) {
this.emptyCond.await();
}
final AllocatedResult result = this.blankAbstractFiles.pollFirst();
// 唤醒生产者
this.fullCond.signal();
return result.abstractFile;
} finally {
this.allocateLock.unlock();
}
}
4.4 文件预热
在 2.2 节中介绍 mmap 时,我们知道 mmap 系统调用后操作系统并不会直接分配物理内存空间,只有在第一次访问某个 page 的时候,发出缺页中断 OS 才会分配。可以想象如果一个文件大小为 1G,一个 page 4KB,那么得缺页中断大概 100 万次才能映射完一个文件,所以这里也需要进行优化。
当 AllocateFileService 预分配一个文件的时候,会同时调用两个系统:
- **Madvise()****:**简单来说建议操作系统预读该文件,操作系统可能会采纳该意见
- **Mlock()****:**将进程使用的部分或者全部的地址空间锁定在物理内存中,防止被操作系统回收
对于 SOFAJRaft 这种场景来说,追求的是消息读写低延迟,那么肯定希望尽可能地多使用物理内存,提高数据读写访问的操作效率。
- 收获 -
在这个过程中我慢慢学习到了一个项目的常规流程:
- 首先,仔细打磨立项方案,深入考虑方案是否可行。
- 其次,项目过程中多和导师沟通,尽快发现问题。本次项目也遇到过一些我无法解决的问题,家纯老师非常耐心的帮我找出问题所在,万分感谢!
- 最后,应该注重代码的每一个细节,包括命名、注释。
正如家纯老师在结项点评中提到的,"What really makes xxx stand out is attention to low-level details "。
在今后的项目开发中,我会更加注意代码的细节,以追求代码优美并兼顾性能为目标。
后续,我计划为 SOFAJRaft 项目作出更多的贡献,期望于早日晋升成为社区 Committer。也将会借助 SOFAStack 社区的优秀项目,不断深入探索云原生!
- 鸣谢 -
首先很幸运能参与本次开源之夏的活动,感谢冯家纯导师对我的耐心指导和帮助 !
感谢开源软件供应链点亮计划和 SOFAStack 社区给予我的这次机会 !
*本周推荐阅读*
基于 RAFT 的生产级高性能 Java 实现 - SOFAJRaft 系列内容合辑

|








- 上一条: JuiceFS 如何帮助趣头条超大规模 HDFS 降负载 2021-10-27
- 下一条: 大规模数据如何实现数据的高效追溯 2021-10-27
- 百度搜索中台新一代内容架构:FaaS化和智能化实战 2022-01-13
- 系列开篇|VMware 新一代云原生平台(TAP) 助力企业实现应用现代化 2022-05-18
- 高效压缩位图在推荐系统中的应用 2022-04-19
- MongoDB在腾讯零售优码中的应用 2022-06-27
- Hazelcast在openLooKeng中的应用(Cache篇) 2021-09-17


