Elasticsearch 存储成本省 60%,稿定科技干货分享
背景
稿定科技旗下稿定设计产品是一个聚焦商业设计的多场景在线设计平台,打破了软硬件间的技术限制,汇集创意内容与设计工具于一体,为不同场景下的设计需求提供优质的解决方案,满足图片、视频等全类型媒介的设计需求,让设计更简单。
稿定科技使用 Elasticsearch(下文中简称为 ES) 作为日志检索组件,随着业务量的增长,每天有 2T 左右的新增数据,需要保存 15~30 天,给磁盘和系统带来了不小的压力。在 ES 中为了保证日志的写入和查询的性能,大多使用单位存储成本更高的高性能云盘。但是,在实际的业务场景中,超过 7 天的数据仅作低频使用,全部存储在高性能云盘必然会导致过高的成本和空间的浪费。
方案
Elasticsearch 7.10 版本推出了索引生命周期概念,开始支持数据分层存储,可以指定不同节点使用不同的磁盘介质来区分冷热数据,比如使用 HDD 磁盘来存储温冷数据,能获得更大的使用空间和更低的成本。这个特性非常适合日志索引场景。
在温冷数据的存储介质上,使用 JuiceFS 替代 HDD 磁盘,相当于获得了无限容量的存储空间。通过 ES 的索引生命周期管理,可以自动完成索引的创建 - 迁移 - 销毁整个生命周期管理,无需手工干预。
在我们的实践中,首先将 ES 集群升级到目前最新的 7.13 版本。然后拆分冷热节点,热节点优先考虑性能,冷节点优先考虑存储的容量和成本。同时,调整索引和模板方式,配置数据生命周期、索引模板和数据流,完成索引数据写入。
调整后整个索引的流转如下图所示:
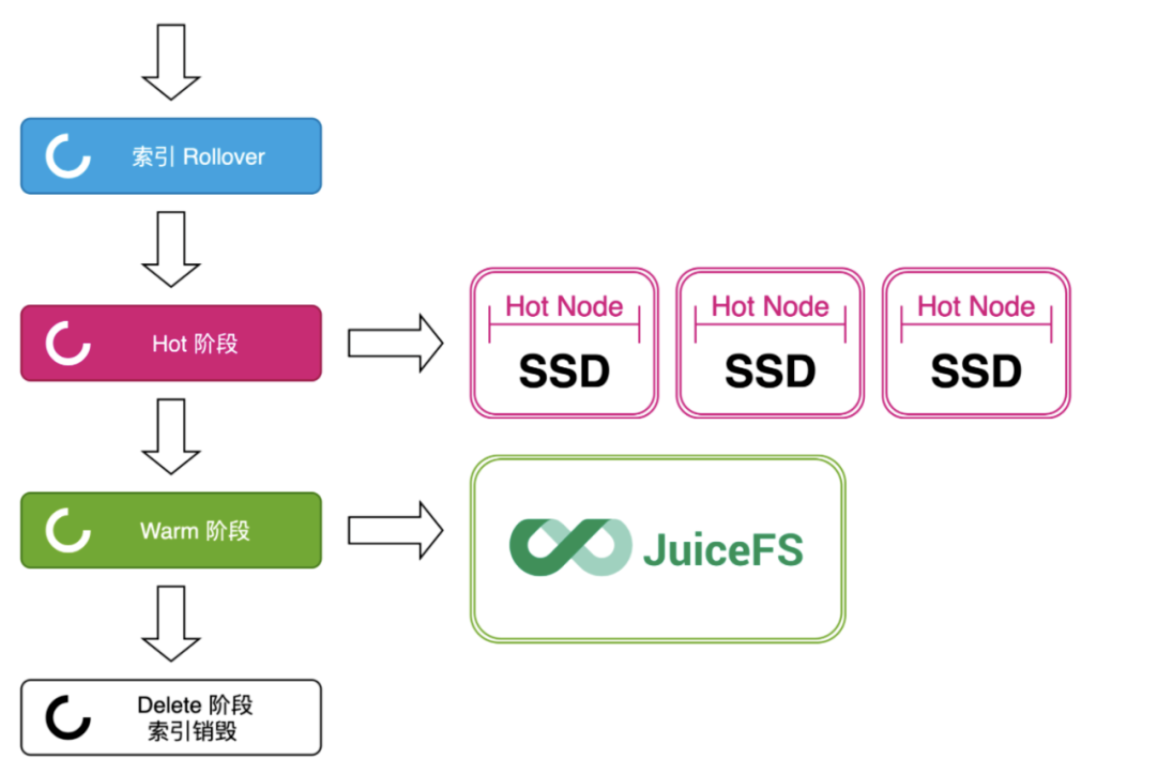
在索引创建时,配置 index.routing.allocation.require.box_type:hot 进行节点筛选; 等待索引进入 warm 周期时,调整 index.routing.allocation.require.box_type:warm,并迁移到 warm 节点后,数据进入冷节点存储,实际存储于 JuiceFS 中; 等待索引进入 delete 周期时,ES 会自动把索引数据删除。
客户收益
方案中使用的 JuiceFS 是什么呢?
JuiceFS 是一款面向云环境设计的企业级分布式文件系统。提供完备的 POSIX 兼容性,为应用提供一个低成本、空间无限的共享文件系统。使用 JuiceFS 存储数据,数据本身会被持久化在对象存储(例如,Amazon S3、阿里云 OSS 等),结合 JuiceFS 的元数据服务来提供高性能文件存储。JuiceFS 在全球公有云服务中都提供有全托管服务,只需点点鼠标,十分钟配置好。同时 JuiceFS 在 2021年初在 GitHub 开源,受到全球开发者的关注和参与,目前已经获得 3700+ stars。
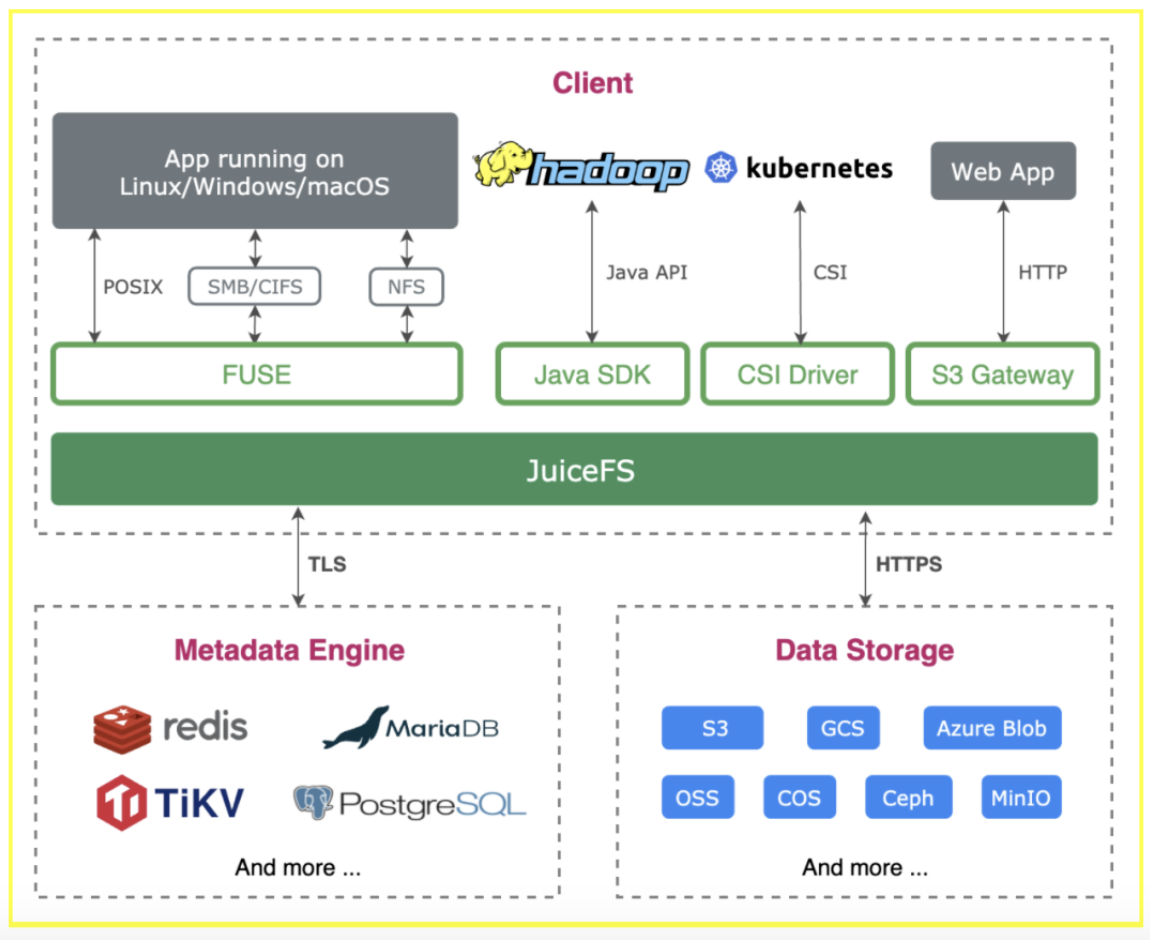
在本方案中 ES 集群 warm 节点使用 JuiceFS 做存储之后,我们不用再对这些节点做容量规划和扩容工作,也省去了节点故障时的数据迁移,降成本的同时还为运维带来很大的便利。
JuiceFS 的持久层使用对象存储,弹性计费,TCO 比使用普通云盘还要低。在本方案的 ES 集群中,Hot 节点使用的云盘价格为 1000元/TB/月,使用全托管的 JuiceFS 服务加上对象存储的开销,价格约为 250元/TB/月。ES 集群总容量 60TB+,通过冷热分层处理,75% 的数据存在 JuiceFS 中,仅存储成本已经节省近 60%。如果再加上运维团队节省的时间精力,这个方案为客户的数据存储带来的 TCO 下降至少有 70%。
实践
集群配置
集群共 9 个节点,⼀个独⽴的 master 节点(elastic_001),另外 8 个数据节点,其中有 5 个热数据节点(elastic_002 ~ elastic_006),3 个冷数据节点(elastic_007 ~ elastic_009)。

目录挂载与配置
JuiceFS 挂载在 ES 冷数据节点,提供 ES 的数据⽬录。
节点配置有⼀块 2T 的数据盘,挂载在 /data ⽬录,ES 进程以容器的⽅式启动,数据盘挂载的是系统的 /data/elastic ⽬录,由于使⽤的容器挂载系统⽬录的⽅式,不能通过 软链 的⽅式将 ES 数据⽬录 ( /data/elastic ) 指向 JuiceFS 挂载的某个⼦⽬录,使⽤了 Linux 系统的 bind mount 将 JuiceFS 的⼦⽬录挂载到 /data/elastic 这个路径上。⽐如在 007 节点上:
# ./juicefs mount gd-elasticsearch-jfs \
--cache-dir=/data/jfsCache --cache-size=307200 \
--upload-limit=800 /jfs
# mount -o bind /jfs/data-elastic-pro-007 /data/elastic
这样在 /data/elastic ⽬录看到 /jfs/data-elastic-pro-007 的内容。
在 008 和 009 节点上也做类似挂载操作。
如果您还不熟悉 JuiceFS 的初始化、挂载等基本操作,请参考 JuiceFS 官方文档。
ES 索引 Rollover 时有很多随机写操作,为了保证写的性能,挂载 JuiceFS 时加上了 writeback 参数,这样会数据先写本地磁盘,后台异步将数据上传到对象存储。本地磁盘⽬录使⽤的是 /data/jfsCache/gd-elasticsearch-jfs/rawstaging/ ,请注意不要删除这个⽬录中的任何⽂件,否则可能出现数据丢失。
cache-size 和 upload-limit 分别⽤来限制本地的读缓存使⽤空间为 300GiB,写对象存储的带宽不超过 800Mbps。attrcacheto 和 entrycacheto 分别表示内核的 attr cache 和 entry cache 的缓存超时时间,单位是秒。
性能优化
降低节点负载
在采用 JuiceFS 之前,ES 集群生命周期中配置了 Force Merge,具体配置项为 warm.actions.forcemerge.max_num_segments: 1,它会导致数据在 Rollover 时重新 Merge,给 CPU 带来极大的压力。而这步动作是完全没必要的,关闭 Force Merge 配置即可避免不必要的性能开销,降低节点负载。
Rollover 参数配置优化
由于 warm 阶段数据写入 JuiceFS,最终会持久化到对象存储上,应用层不用再存储多副本,可以在索引 Rollover 过程中,设置 replicas 为 0,即 warm.actions.number_of_replicas: 0。
另外,考虑当索引数据迁移到 warm 阶段后,数据并不再写入,可以设置 warm 阶段索引只读,即 warm.actions.readonly: {},关闭索引的数据写入可以减少内存占用量。
总结
随着时间的推移和业务量的增长,企业势必面临更大规模的数据存储和管理上的双重挑战。在本案中,稿定科技充分发挥 Elasticsearch 的生命周期管理能力,根据业务需要将日志数据进行分层存储。将需要频繁使用的热数据保存在 SSD,而超过 7 天的低频使用数据则存储在性价比更高的 JuiceFS,为客户节省存储成本 60%。同时,JuiceFS 还为应用提供近乎无限的弹性空间,省去了容量规划、扩容、数据迁移等一系列的运维工作,提升了企业 IT 架构的效率。
推荐阅读:
|








- 上一条: 实现无感刷新token,我是这样做的 2021-10-14
- 下一条: 还在用BeanUtils拷贝对象?MapStruct才是王者!【附源码】 2021-10-14
- ClickHouse与Elasticsearch压测实践 2022-08-29
- ClickHouse与Elasticsearch压测实践 2022-08-29
- Elasticsearch 在地理信息空间索引的探索和演进 2022-06-28
- 在 Windows 上运行 OpenSearch(ElasticSearch) 2021-11-25
- DolphinScheduler 调度 DataX 实现 MySQL To ElasticSearch 增量数据同步实践 2022-03-03


