揭秘你处理数据的“底层逻辑”,详解公式引擎计算(一)
背景
身处信息时代之中,我们最能明显感受到的一点就是密集数据大量爆发,人们积累的数据也越来越多。这些庞杂的数据出现在一起,传统使用的很多数据记录、查询、汇总工具并不能满足人们的需求。更有效的将这些大量数据处理,让计算机听懂人类需要的数据效果,从而形成更加自动化、智能的数据处理方式。
为了处理这些海量数据,出现了各种大数据引擎、搜索引擎、计算引擎、3D引擎等,用以更好解决数据庞杂带来人工无法处理的问题。而作为其中比较基础的计算公式引擎,是在计算程序中负责对数据进行处理的核心部分。接下来我们将展开介绍计算引擎的基本原理、计算链和异步函数构成,并从计算公式引擎的基本概念出发,用我们的表格电子组件作为例子,为大家演示这些内容如何在JavaScript中实现。
公式引擎的计算原理
计算引擎负责解决数据来源的统计,数据的操作,数据的管理,并将合适的计算结果按照要求给予返回。针对数据处理的目的不同,需要返回的内容不同,也有很对多应不同的类别。
为了实现让计算机更好的识别我们需要的处理操作,需要进过编译的过程,将我们书写的语言翻译成机器可以识别的语言。
而整个编译阶段的流程,按照过程划分是按照下图进行的:
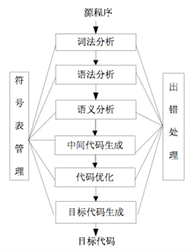
其中比较关键的两个环节是词法分析、语法分析的过程,在这两部分会将我们的输入逐渐拆分,转化为程序能够识别的内容。
输入内容后,编译器先对内容进行词法分析,在这一步编译器的任务是识别源程序中的单词是否有误,编译程序中实现这种功能的部分一般称为词法分析器。通常词法分析的输出是一个个单独的单词符号。
以JS为例,在这个过程中有三个主要部分:分析函数参数、分析变量声明、分析函数声明。语法分析阶段的目的是识别出源程序的语法结构(即语句或句子)是否错误,这一阶段通常可以发现语法的错误。在这个阶段中,编译器实际处理的是来自词法分析得出的单词符号。
而在计算公式引擎中我们处理数据的方式和编译原理中处理语言这一过程极度相似,从实际应用出发实现一个类似Excel的计算公式的计算公式引擎,我们可以采用的思路是从词法分析出发,将完整的长串公式语句拆分成小块内容,然后再进行语法分析,最后对生成语法结构树进行运算。接下来让我们一起看看细节如何实现。
公式引擎的实现细节
我们从公式计算开始为大家说明,公式计算即由一个公式字符串进行计算后,得出表达式结果。比如:公式“=1+10*11” 计算后得到结果111。电子计算机并不是人类,这样一个简单的表达式想要完全正确计算,最终变成我们需要的数据内容,并不是简单的我们看一眼后,口算就得到答案。实现这样类Excel表格计算的功能,需要通过词法分析,语法分析,语法结构树计算这几个过程。
1. 词法分析
以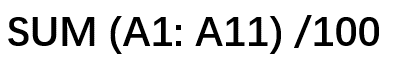 和
和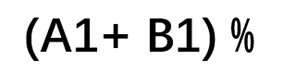 中常用的公式进行说明。
中常用的公式进行说明。
首先我们进行词法分析,在这个过程中我们将公式字符拆成字符串数组,在Excel表格公式计算中,表达式的公式字符串中只包括:运算符、符号、字符串、数字、数组、引用、名称这几类。
名称:sum
运算符:( ) :/ % +
引用:A1 A11 B1
数字:100
2. 语法分析
词法分析完成之后,我们对词法分析的结果进行进一步语法分析。通常计算中语法分析可以采用表达式树或者堆栈(即逆波兰式)来处理。
这里我们先介绍表达式树的方法。
语法分析——表达式树
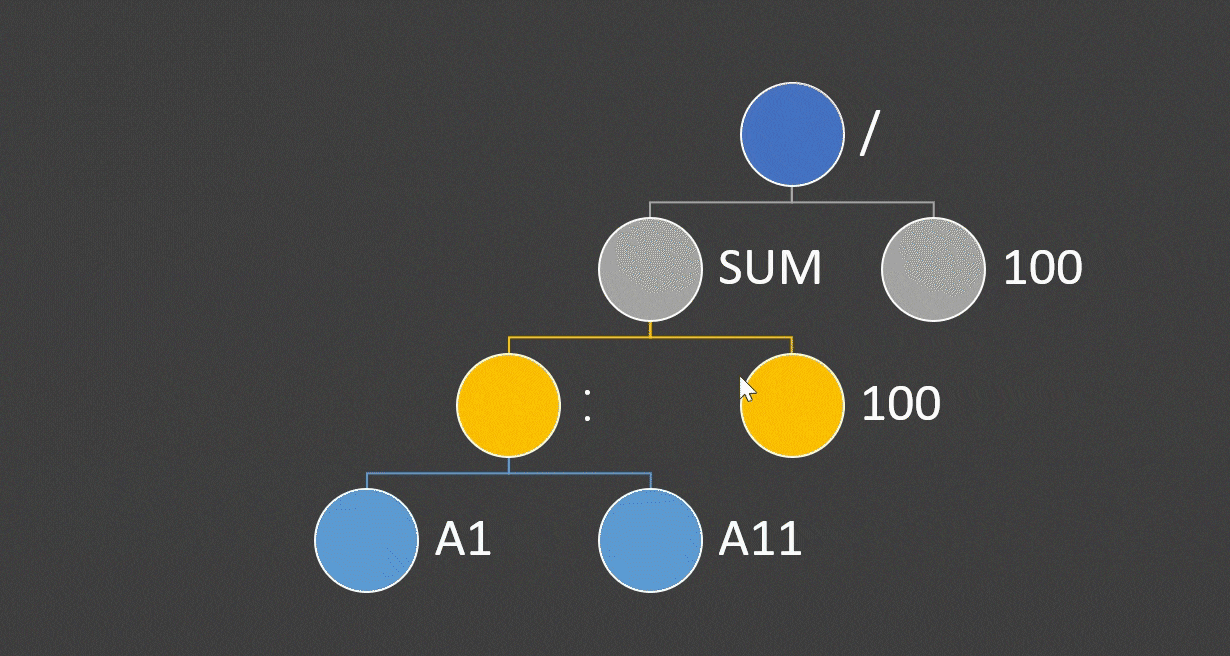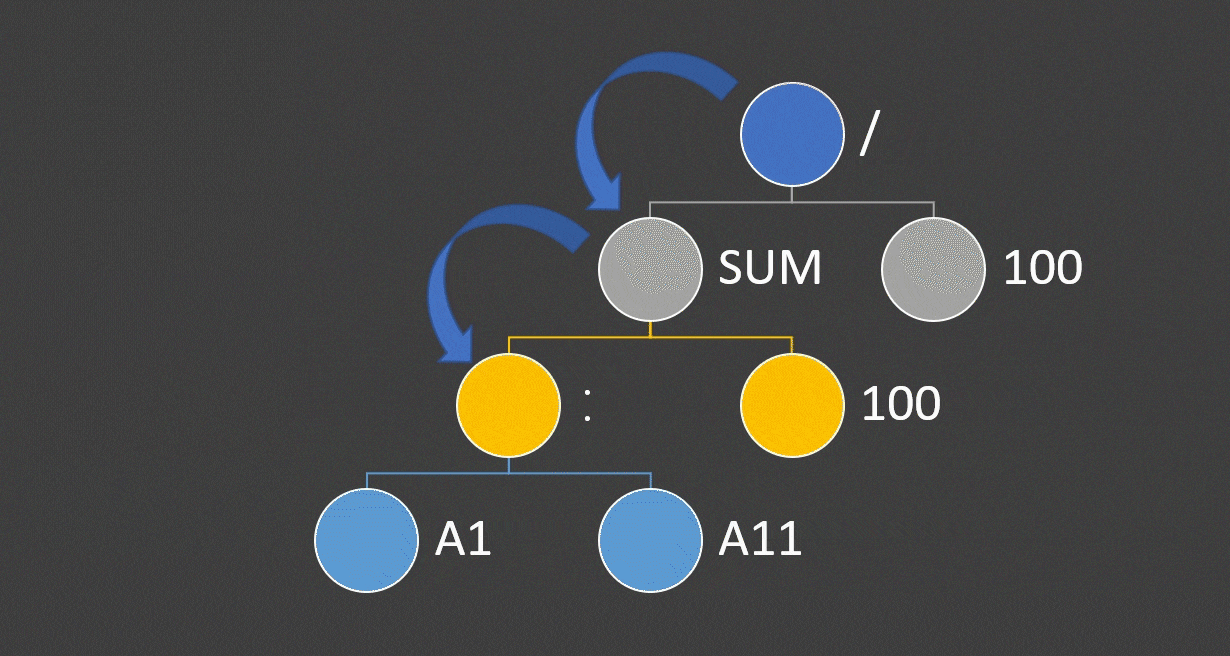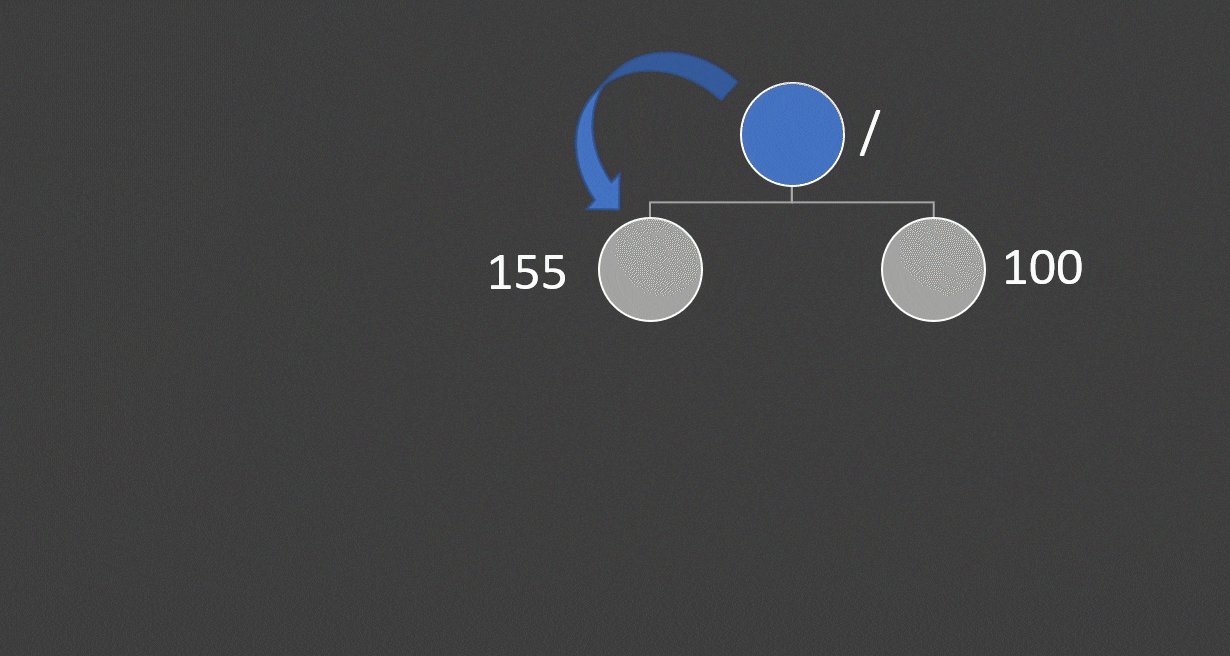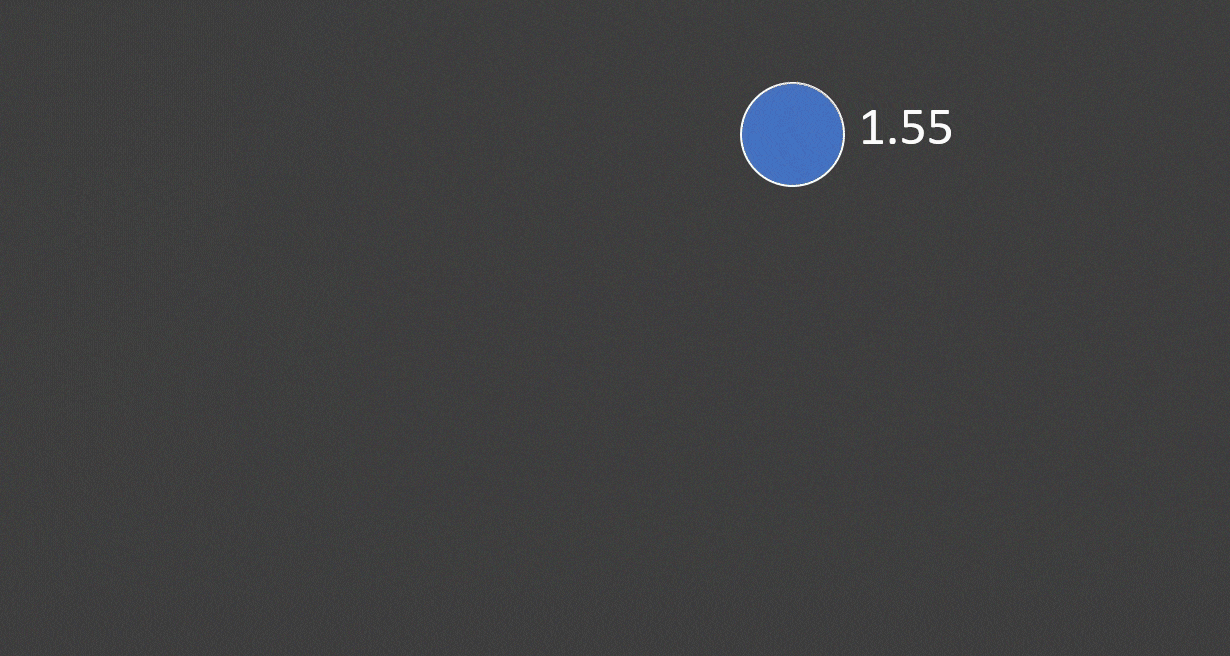
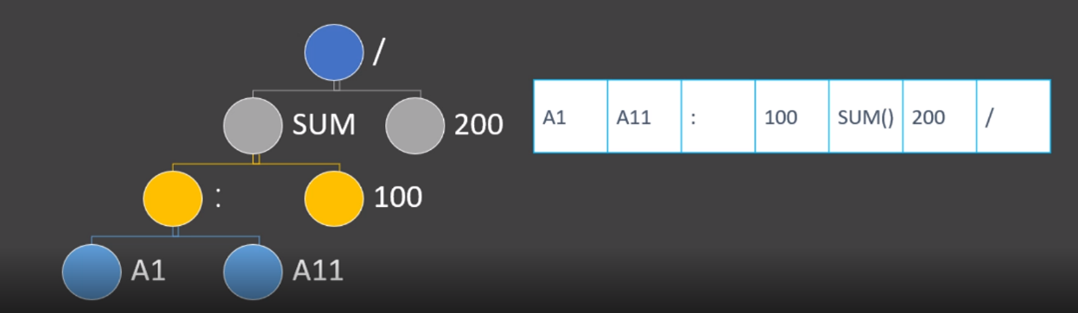
使用表达式树进行分析的过程,从一棵二叉树开始。首先我们将词法分析的结果按照优先级组成表达式树,表达式树的叶子结点就是操作数,内部节点是操作符。
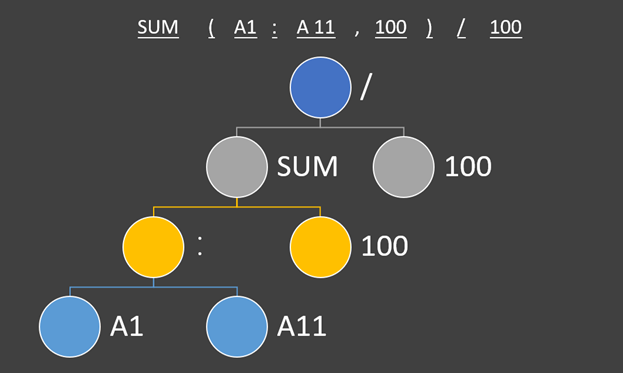
在这个事例中,冒号的优先级最高,其次是括号,最后是除号。当这棵树形成之后,就离我们拿到最终的运算结果很接近了。
我们会采用递归调用的方式对这颗树进行运算,从根结点出发,到sum,一直向下递归,到A1:A11时,有了第一个结果,然后逐层返回计算结果。
这就完证的展示了如何实现一个公式计算。
语法分析——逆波兰算法
逆波兰算法是在语法分析阶段形成了一个堆栈(即逆波兰表达式),这个表达式的核心在于将普通我们是用的中缀表达式转换为后缀表达式。括号在运算的过程中只进行运算顺序的提示,但并不是实际参与计算的元素内容,所以在中缀转后缀的过程中就可以省略掉括号内容,
然后由计算机编写代码完成运算。
这里展示了一棵树转化成对应的逆波兰式的样子。
二叉树递归VS逆波兰算法
与一棵树递归计算相比,逆波兰式更符合数学计算的习惯。但实际在项目中处理这种公式计算的时候,到底哪一种更加能处理更复杂的情况呢?
让我们来看一个多层嵌套的公示内容:

这个公示的使用场景是SUMIFS函数多列求和,等价于下面这个内容:
=SUMIFS($C:$C,$B:$B,$A1)+SUMIFS($D:$D,$B:$B,$A1)+….
很明显上面的公式更加简单,采用二叉树递归的方式,只需要判断SUMIFS节点的父节点以及孩子结点内容,只需要短短一行代码就可以搞定这个多列求和。
但是如果是用逆波兰算法,代码一开始遇到SUM就开始计算,很难判定SUM此时要运行的内容其实在最内层括号之中。可以解决,但却并不是最简单的。
对比结果
与堆栈的方式相比,树的解法更容易扩展、增强,可以更加轻松应对复杂的公式。这在处理大量公式、复杂计算就是得天独厚的优势。
总结
在介绍完如何解析并进行公式计算的全过程之后,接下来我们会继续介绍在公式计算引擎中计算链和异步函数的相关内容。在处理复杂公式时,有向图如何求解,calcOnDemand解法又是什么,还有在前后端计算中异步函数的花式用法。

觉得不错点个赞再走吧~后续还会为大家带来更多有趣的内容~
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具、解决方案和服务,赋能开发者。
|








- 上一条: linux系列之:告诉他,他根本不懂kill 2021-09-15
- 下一条: 如何搭建一台永久运行的个人服务器?试试这个黑科技! 2021-09-15
- 揭秘你处理数据的“底层逻辑”,详解公式引擎计算(二) 2021-09-23
- 详解数据中台的底层架构逻辑 2022-01-11
- 带你玩转Flink流批一体分布式实时处理引擎 2022-01-17
- 详解图像处理的算术运算与逻辑运算 2022-03-14
- 第1章 计算机系统的基础知识 ·1.5 逻辑代数及逻辑电路 2021-07-07


