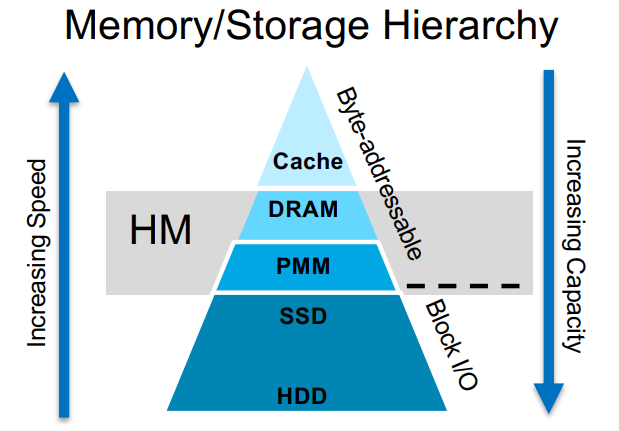
HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogenous Memory 是一篇被2020年 Conference on Neural Information Processing Systems (NeurIPS 2020). 本文提出了一种基于图的相似性搜索的新型算法,称为 HM-ANN。该算法在现代硬件设置中同时考虑了内存异质性和数据异质性。HM-ANN 可以在单台机器上实现十亿级的相似性搜索,同时没有采用任何数据压缩技术。异质存储器(HM)代表了快速但小的 DRAM 和缓慢但大的 PMem 的组合。HM-ANN 实现了低搜索延迟和高搜索精度,特别是在数据集无法装入单机有限 DRAM 的情况下。与最先进的近似近邻(ANN)搜索方案相比,该算法具有明显的优势。
动机
由于 DRAM 容量有限,ANN 搜索算法在查询精度和查询延迟之间进行了基本的权衡。为了在 DRAM 中存储索引以实现快速查询,有必要限制数据点的数量或存储压缩的向量,这两者都会损害搜索的准确性。基于图形的索引(如 HNSW)具有优越的查询运行时间性能和查询精度。然而,当在十亿规模的数据集上操作时,这些索引也会消耗 TiB 等级的 DRAM。
还有其他的变通方法来避免让 DRAM 以原始格式存储十亿规模的数据集。当一个数据集太大,无法装入单台机器的 DRAM 时,就会使用数据压缩的方法,如对数据集的点进行乘积量化。但是,由于量化过程中精度的损失,这些索引在压缩数据集上的召回率通常很低。Subramanya 等人[1]探索了利用固态硬盘 SSD 实现十亿级 ANN 搜索的方法,该方法称为 Disk-ANN ,其中原始数据集存储在 SSD 上,压缩后的表示方法存储在 DRAM 上。
Heterogeneous Memory的介绍