摘要
“DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node” [1] 是 2019 年发表在 NeurIPS 上的论文。该文提出了一种基于磁盘的 ANN 方案,该方案可以在单个 64 G 内存和足够 SSD 的机器上对十亿级别的数据进行索引、存储和查询, 并且能够满足大规模数据 ANNS 的三个需求: 高召回、低查询时延和高密度(单节点能索引的点的数量)。该文提出的方法做到了在 16 核 64G 内存的机器上对十亿级别的数据集 SIFT1B 建基于磁盘的图索引,并且 recall@1 > 95% 的情况下 qps 达到了 5000, 平均时延不到 3ms。
论文作者
Suhas Jayaram Subramanya: 前微软印度研究院员工,CMU 在读博士。主要研究方向有高性能计算和面向大规模数据的机器学习算法。
Devvrit:Graduate Research Assistant at The University of Texas at Austin。研究方向是理论计算机科学、机器学习和深度学习。
Rohan Kadekodi:德克萨斯大学的博士研究生。研究方向是系统和存储,主要包括持久化存储、文件系统和 kv 存储领域。
Ravishankar Krishaswamy:微软印度研究院 Principal Researcher。 CMU 博士学位。 研究方向是基于图和聚类的近似算法。
Harsha Vardhan Simhadri:微软印度研究员 Principal Researcher。CMU 博士学位。以前研究并行算法和运行时系统,现在主要工作是开发新算法,编写编程模型。
论文动机
目前有很多向量检索的 ANN 算法,这些算法在建索引性能、查询性能和查询召回率方面各有取舍。当前在查询时间和召回率上表现较好的是基于图的索引如 HNSW 和 NSG。由于图索引内存占用比较大,在单机内存受限的情况下,常驻内存的方案能处理点集的规模就十分有限。
许多应用需要快速在十亿级别数据规模上做基于欧几里得距离的近似查询,目前有两种主流的方法:
- 基于 倒排表+量化 的方法。缺点是召回率不高,因为量化会产生误差。虽然可以提高 topk 以改善召回率,但是相应的会降低 qps。
- 基于 分治。将数据集分成若干个不相交的子集,每个子集建基于内存的索引,最后对结果做归并。这种方法比较耗内存和机器。例如对 100M, 128 维的 float 数据集上建 NSG 索引,假设出度上限为 50, 大约需要 75G 内存。因此处理十亿级别的数据就需要多台机器。在阿里巴巴淘宝的实际应用中,将 20 亿 128 维浮点数据分到 32 个分片中分别建 NSG 索引,recall@100 为 98% 的时延大约在 5ms。当数据规模增加到千亿级别时需要数千台机器。<sup>[2]</sup>
以上两种方法的局限性在于太依赖内存。所以这篇论文考虑设计一种索引常驻 SSD 的方案。索引常驻 SSD 的方案主要面临的挑战是如何减少随机访问 SSD 的次数和减少发起 SSD 访问请求的数量。将传统的基于内存的 ANNS 算法放到 SSD 上的话平均单条查询会产生数百个读磁盘操作,这会导致极高的时延。
论文贡献
这篇论文提出了能够有效支持大规模数据的常驻 SSD 的 ANNS 方案: DiskANN。该方案基于这篇论文中提出的另一个基于图的索引: Vamana,后面会详细介绍。这篇论文的主要贡献包括但不限于:
- DiskANN 可以在一台 64G 内存的机器上对十亿级别的维度大于 100 的数据集进行索引构建和提供查询服务,并在单条查询 recall@1 > 95% 的情况下平均时延不超过 5ms。
- 提出了基于图的新索引 Vamana,该索引相比目前最先进的 NSG 和 HNSW 具有更小的搜索半径,这个性质可以最小化 DiskANN 的磁盘访问次数。
- Vamana 搜索性能不慢于目前最好的图索引 NSG 和 HNSW。
- DiskANN 方案通过将大数据集分成若干个相交的分片,然后对每个分片建基于内存的图索引 Vamana,最后将所有分片的索引合并成一个大索引,解决了内存受限的情况下对大数据集建立索引的问题。
- Vamana 可以和现有的量化方法如 PQ 结合,量化数据可以缓存在内存中,索引数据和向量数据可以放在 SSD 上。
Vamana
这个算法和 NSG<sup>[2]</sup> <sup>[4]</sup>思路比较像(不了解 NSG 的可以看参考文献 2,不想读 paper 的话可以看参考文献 4),主要区别在于裁边策略。准确的说是给 NSG 的裁边策略上加了一个开关 alpha。NSG 的裁边策略主要思路是:对于目标点邻居的选择尽可能多样化,如果新邻居相比目标点,更靠近目标点的某个邻居,我们可以不必将这个点加入邻居点集中。也就是说,对于目标点的每个邻居节点,周围方圆 dist(目标点,邻居点)范围内不能有其他邻居点。这个裁边策略有效控制了图的出度,并且比较激进,所以减少了索引的内存占用,提高了搜索速度,但同时也降低了搜索精度。Vamana 的裁边策略其实就是通过参数 alpha 自由控制裁边的尺度。具体作用原理是给裁边条件中的 dist(某个邻居点,候选点) 乘上一个不小于 1 的参数 alpha,当 dist(目标点,某个候选点)大于这个被放大了的参考距离后才选择裁边,增加了目标点的邻居点之间的互斥容忍度。
Vamana 的建索引过程比较简单:
- 初始化一张随机图;
- 计算起点,和 NSG 的导航点类似,先求全局质心,然后求全局离质心最近的点作为导航点。和 NSG 的区别在于:NSG 的输入已经是一张近邻图了,所以直接在初始近邻图上对质心点做一次近似最近邻搜索就可以了。但是 Vamana 初始化是一张随机近邻图,所以不能在随机图上直接做近似搜索,需要全局比对,得到一个导航点,这个点作为后续迭代的起始点,目的是尽量减少平均搜索半径;
- 基于初始化的随机近邻图和步骤 2 中确定的搜索起点对每个点做 ANN,将搜索路径上所有的点作为候选邻居集,执行 alpha = 1 的裁边策略。这里和 NSG 一样,选择从导航点出发的搜索路径上的点集作为候选邻居集会增加一些长边,有效减少搜索半径。
- 调整 alpha > 1(论文推荐 1.2)重复步骤 3。因为 3 是基于随机近邻图做的,第一次迭代后图的质量不高,所以需要再迭代一次来提升图的质量,这个对召回率很重要。
论文比较了 Vamana、NSG、HNSW 3种图索引,无论是建索引性能还是查询性能, Vamana 和 NSG 都比较接近,并且都稍好于 HNSW。具体数据可以看下文实验部分。

为了直观地表现建 Vamana 索引过程,论文中给出了这么一张图,用 200 个二维点模拟了两轮迭代过程。第一行是用 alpha = 1 来裁边,可以发现改裁边策略比较激进,大量的边被裁剪。经过放大 alpha,裁边条件放松后,明显加回来了不少边,并且第二行最右这张图,即最终的图中,明显加了不少长边。这样可以有效减少搜索半径。
DiskAnn
一台只有 64G 内存的个人电脑连十亿原始数据都放不下,更别说建索引了。摆在我们面前的有两个问题:1. 如何用这么小的内存对这么大规模的数据集建索引?2. 如果原始数据内存放不下如何在搜索时计算距离?
本文提出的方法:
- 对于第一个问题,先做全局 kmeans,将数据分成 k 个簇,然后将每个点分到距离最近的 I 个簇中,一般 I 取 2 就够了。对每个簇建基于内存的 Vamana 索引,最后将 k 个 Vamana 索引合并成一个索引。
- 对于第二个问题,可以使用量化的方法,建索引时用原始向量,查询的时候用压缩向量。因为建索引使用原始向量保证图的质量,搜索的时候使用内存可以 hold 住的压缩向量进行粗粒度搜索,这时的压缩向量虽然有精度损失,但是只要图的质量足够高,大方向上是对的就可以了,最后的距离结果还是用原始向量做计算的。
DiskANN 的索引布局和一般的图索引类似,每个点的邻居集和原始向量数据存在一起。这样做的好处是可以利用数据的局部性。
前面提到了,如果索引数据放在 SSD 上,为了保证搜索时延,尽可能减少磁盘访问次数和减少磁盘读写请求。因此 DiskANN 提出两种优化策略:
- 缓存热点:将起点开始 C 跳内的点常驻内存,C 取 3~4 就比较好。
- beam search: 简单的说就是预加载,搜索 p 点时,如果 p 的邻居点不在缓存中,需要从磁盘加载 p 点的邻居点。由于一次少量的 SSD 随机访问操作和一次 SSD 单扇区访问操作耗时差不多,所以我们可以一次加载 W 个未访问点的邻居信息,W 不能过大也不能过小,过大会浪费计算和 SSD 带宽,太小了也不行,会增加搜索时延。
实验
实验分三组:
一、 基于内存的索引比较: Vamana VS. NSG VS. HNSW
数据集:SIFT1M(128 维), GIST1M(960 维), DEEP1M(96 维) 以及从 DEEP1B 中随机采样了 1M 的数据集。
索引参数(所有数据集都采用同一组参数):
HNSW:M = 128, efc = 512.
Vamana: R = 70, L = 75, alpha = 1.2.
NSG: R = 60, L = 70, C= 500.
论文里没有给搜索参数,可能和建索引参数一致。对于这个参数选择,文中提到 NSG 的参数是根据 NSG 的github repository <sup>[3]</sup>里列出的参数中选择出性能比较好的那组,Vamana 和 NSG 比较接近,因此参数也比较接近,但是没有给出 HNSW 的参数选择理由。在笔者看来,HNSW 的参数 M 选择偏大,同为图索引,出度应该也要在同一水平才能更好做对比。
在上述建索引参数下,Vamana、HNSW 和 NSG 建索引时间分别为 129s、219s 和 480s。NSG 建索引时间包括了用 EFANN [3] 构建初始化近邻图的时间。
召回率-qps 曲线:

从 Figure 3 可以看出,Vamana 在三个数据集上都有着优秀的表现,和 NSG 比较接近,比 HNSW 稍好。
比较搜索半径:
这个结果可以看 Figure 2.c,从图中可以看出 Vamana 相比 NSG 和 HNSW,在相同召回率下平均搜索路径最短。
二、 比较一次性建成的索引和多个小索引合并成一个大索引的区别
数据集: SIFT1B
一次建成的索引参数:L = 50, R = 128, alpha = 1.2. 在 1800G DDR3 的机器上跑了 2 天, 内存峰值大约 1100 G,平均出度 113.9。
基于合并的索引步骤:
- 将数据集用 kmeans 训练出 40 个簇;
- 每个点分到最近的 2 个簇;
- 对每个簇建 L = 50, R = 64, alpha = 1.2 的 Vamana 索引;
- 合并每个簇的索引。
这个索引生成了一个 384G 的索引,平均出度 92.1。这个索引在 64G DDR4 的机器上跑了 5 天。
比较结果如下(Figure 2a):
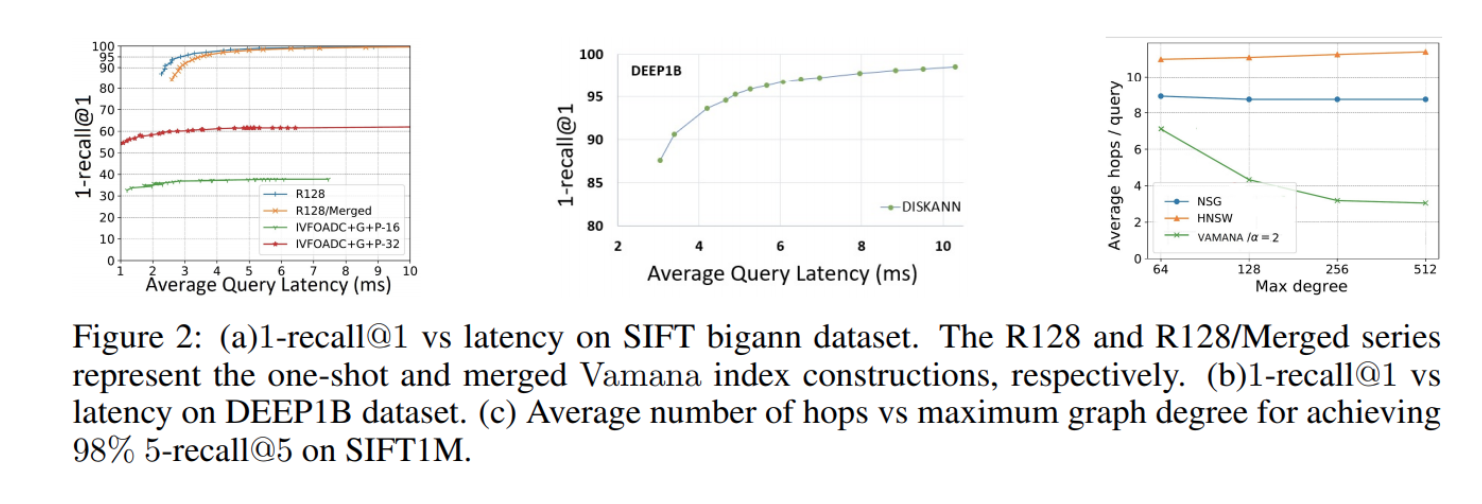
结论:
- 一次建成的索引显著优于基于合并的索引;
- 基于合并的索引也很优秀;
- 基于合并的索引方案也适用于 DEEP1B 数据集(Figure 2b)。
三、 基于磁盘的索引: DiskANN VS. FAISS VS. IVF-OADC+G+P
IVFOADC+G+P 是参考文献 [5] 提出的一种算法。
这篇论文只和 IVFOADC+G+P 比较,因为参考文献 [5] 中已经证明比 FAISS 要更优秀,另外 FAISS 要用 GPU,并不是所有平台都支持。
IVF-OADC+G+P 好像是一个 hnsw + ivfpq。用 hnsw 确定 cluster,然后在目标 cluster 上加上一些剪枝策略进行搜索。
结果在 Figure 2a 里。图里的 16 和 32 是码本大小。数据集是 SIFT1B,用的 OPQ 量化。
代码实现细节
DiskANN 的源码已经开源:[GitHub 地址][https://github.com/microsoft/DiskANN]
2021 年 1 月开源了磁盘方案的源码,稍微看了下,大概介绍一下磁盘方案的实现细节。
这个代码质量比较高,可读性比较强,建议有能力的可以读一下。
下面主要介绍建索引过程和搜索过程。
建索引
建索引参数有 8 个:
data_type: float/int8/uint8 三选一
data_file.bin: 原始数据二进制文件,文件前 2 个 int 分别表示数据集向量总数 n 和向量维度 dim。后 n * dim * sizeof(data_type) 字节就是连续的向量数据。
index_prefix_path: 输出文件的路径前缀,索引建完后会生成若干个索引相关文件,这个参数是公共前缀。
R: 全局索引的最大出度。
L: Vamana 索引的参数 L,候选集大小上界。
B: 查询时的内存阈值,单位 GB,控制 pq 码本大小。
M: 建索引时的内存阈值,决定分片大小,单位 GB。
T: 线程数。
建索引流程(入口函数:aux_utils.cpp::build_disk_index):
-
根据 index_prefix_path 生成各种产出文件名。
-
参数检查。
-
读 data_file.bin 的 meta 获取 n 和 dim。根据 B 和 n 确定pq 的码本子空间数 m。
-
generate_pq_pivots: 用 p = 1500000/n 的采样率全局均匀采样出 pq 训练集训练 pq 中心点。
-
generate_pq_data_from_pivots: 生成全局 pq 码本,中心点和码本分别保存。
-
build_merged_vamana_index: 对原始数据集切片,分段建 Vamana 索引,最后合并。
-
6.1: partition_with_ram_budget: 根据参数 M 确定分片数 k。对数据集采样做 kmeans,每个点分到最近的两个簇中,对数据集进行分片,每个分片产生两个文件:数据文件和 id 文件。id 文件和数据文件一一对应,id 文件中每个 id 对应数据文件中每条向量一一对应。这里的 id 可以认为是对原始数据的每条向量按 0 ~ n-1 编号。这个 id 比较重要,跟后面的合并相关。
- 6.1.1: 用 1500000 / n 的采样率全局均匀抽样出训练集
- 6.1.2: 初始化 num_parts = 3。从 3 开始迭代。
- 6.1.2.1:对步骤 6.1.1 中的训练集做 num_parts-means++;
- 6.1.2.2:用 0.01 的采样率全局均匀采样出一个测试集,将测试集中的分到最近的 2 个簇中;
- 6.1.2.3:统计每个簇中的点数,除以采样率估算每个簇的点数;
- 6.1.2.4:按 Vamana 索引大小估算步骤 6.1.2.3 中最大的簇需要的内存,如果不超过参数 M,转步骤 6.1.3,否则 num_parts ++ 转步骤 6.1.2;
- 6.1.3: 将原始数据集分成 num_parts 组文件,每组文件包括分片数据文件和分片数据对应的 id 文件。
-
6.2: 对步骤 6.1 中的所有分片单独建立 Vamana 索引并存盘;
-
6.3: merge_shards: 将 num_parts 个分片 Vamana 合并成一个全局索引。
-
6.3.1: 读取 num_parts 个分片的 id 文件到 idmap 中,这个 idmap 相当于建立了分片->id 的正向映射;
-
6.3.2:根据 idmap 建立 id-> 分片的反向映射,知道每条向量在哪两个分片中。
-
6.3.3:用带 1G 缓存的 reader 打开 num_parts 个分片 Vamana 索引,用带 1G 缓存的 writer 打开输出文件,准备合并;
-
6.3.4:将 num_parts 个 Vamana 索引的导航点落盘到中心点文件中,搜索的时候会用到;
-
6.3.5:按 id 从小到大开始合并,根据反向映射依次读取每条原始向量在各个分片的邻居点集,去重,shuffle,截断,写入输出文件。因为当初切片时是全局有序的,现在合并也按顺序来,所以最终的落盘索引中的 id 和原始数据的 id 是一一对应的。
-
6.3.6:删除临时文件,包括分片文件、分片索引、分片 id 文件;
-
-
-
create_disk_layout: 步骤 6 中生成的全局索引只有邻接表,而且还是紧凑的邻接表,这一步就是把索引对齐,邻接表和原始数据存在一起,搜索的时候加载邻接表顺便把原始向量一起读上去做精确距离计算。这里还有一个 SECTOR 的概念,默认大小是 4096,每个 SECTOR 只放 4096 / node_size 条向量信息,node_size = 单条向量大小+单节点邻接表大小。
-
最后再做一个 150000 / n 的全局均匀采样,存盘,搜索时用来 warmup。
搜索
搜索参数主要有 10 个:
index_type: float/int8/uint8 三选 1,和建索引第一个参数 data_type 是一样的;
index_prefix_path: 同建索引参数 index_prefix_path;
num_nodes_to_cache: 缓存热点数;
num_threads: 搜索线程数;
beamwidth: 预加载点数上限,如果为 0 由程序自己确定;
query_file.bin: 查询集文件;
truthset.bin: 结果集文件,“null” 表示不提供结果集,程序自己算;
K: topk;
result_output_prefix: 搜索结果保存路径;
L: 搜索参数列表,可以写多个值,对于每个 L 都会做搜索并输出不同参数 L 下的统计信息。
搜索流程:
- 加载相关数据:查询集、pq 中心点数据、码本数据、搜索起点等数据,读取索引 meta;
- 用建索引时采样的数据集做 cached_beam_search,统计每个点的访问次数,将 num_nodes_to_cache 个访问频次最高的点加载到缓存;
- 默认有一个 WARMUP 操作,和步骤 2 一样,也是用这个采样数据集做一次 cached_beam_search,不太明白这一步有什么用,因为步骤 2 其实已经起到了 warm up 的作用了,难道是再刷一遍系统缓存?
- 根据给的参数 L 个数,每个参数 L 都会用查询集做一遍 cached_beam_search,输出召回率、qps 等统计信息。warm up 和 统计热点数据的过程不计入查询时间。
关于 cached_beam_search:
-
从候选起点中找离查询点最近的,这里用的 pq 距离,起点加入搜索队列;
-
开始搜索:
-
2.1:从搜索队列中看不超过 beam_width + 2 个未访问过的点,如果这些点在缓存中,加入缓存命中的队列,如果不命中,加入未命中的队列,保证未命中的队列大小不超过 beam_width;
-
2.2:对于未命中队列中的点,发送异步磁盘访问请求;
-
2.3:对于缓存命中的点,用原始数据和查询数据算精确距离加入结果队列,然后对这些点未访问过的邻居点,用 pq 算距离后加入搜索队列,搜索队列长度受参数限制;
-
2.4:处理步骤 a 中缓存未命中的点,过程和步骤 c 一样;
-
2.5:搜索队列为空时结束搜索,返回结果队列 topk。
-
总结
这篇论文加代码花了一点时间,总体来说还是很优秀的。论文和代码思路都比较清晰,通过 kmeans 分若干 overlap 的桶,然后分桶建图索引,最后合并的思路还是比较新颖的。至于基于内存的图索引 Vamana,本质上是一个随机初始化版本的可以控制裁边粒度的 NSG。查询的时候充分利用了缓存 + pipline,掩盖了部分 io 时间,提高了 qps。不过按论文中说的,就算机器配置不高,训练时间长达 5 天,可用性也比较低,后续可以考虑对训练部分做一些优化。从代码来看,质量比较高,可以直接上生产环境那种。感觉建索引那段代码在算法和实现方面还是有加速空间的。
参考文献
- Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, Rohan Kadekodi. DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. NeurIPS 2019.
- Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. Fast approximate nearest neighbor search with the navigating spreading-out graphs. PVLDB, 12(5):461 – 474, 2019. doi: 10.14778/3303753.3303754. URL http://www.vldb.org/pvldb/vol12/p461- fu.pdf.
- [NSG GitHub][https://github.com/ZJULearning/efanna]
- Search Engine For AI:高维数据检索工业级解决方案
- Dmitry Baranchuk, Artem Babenko, and Yury Malkov. Revisiting the inverted indices for billion-scale approximate nearest neighbors.
笔者简介
李成明,Zilliz 研发工程师,东南大学计算机硕士。主要关注大规模高维向量数据的相似最近邻检索问题,包括但不限于基于图和基于量化等向量索引方案,目前专注于 Milvus 向量搜索引擎 knowhere 的研发。喜欢研究高效算法,享受实现纯粹的代码,热衷压榨机器的性能。
[Github][https://github.com/op-hunter]











