
撰文 | 袁进辉 我们经常面临如何评价一个大型软件系统质量的问题。首要的评价指标肯定是 功能 ,软件是否满足主要的需求(do right things)。如果有多条技术路径可以实现同样的功能,人们倾向于选择更 简单 的办法。
奥卡姆剃刀准则“ 如无必要,勿增实体 ” 非常好的概括了这种偏好,对简单的偏好是为了对抗复杂性的挑战,其底层逻辑是:“简单的才是对路的”(do things right)。
1 软件研发的亘古难题:对抗复杂性 上世纪60年代,因为软件研发跟不上硬件的发展和现实问题复杂度的增长,而无法在计划的时间内交付,一度被称为“软件危机”。 曾在IBM领导System/360和OS/360研发的图灵奖得主 Fred Brooks 在软件工程的圣经《人月神话》里描述了巨兽在焦油坑(可能和中文的“屎山”意思差不多)垂死挣扎的困境,来类比深陷软件复杂性泥潭而不得脱身的软件研发人员,他还提出了著名的Brooks法则”向进度落后的项目增加人手,只会使进度更加落后“。
在《没有银弹:软件工程的本质性和附属性工作》论文里,他又把软件开发的困难分成本质性的和偶发性的,并指出造成本质性困难的几个主要原因:复杂性 (complexity),隐匿性(invisibility),配合性(conformity)和易变性(changeability),其中复杂性居首。 2006年,有一篇题为《跳出焦油坑》(Out of the Tar Pit)的论文呼应Brooks,这篇论文认为,复杂性才是阻碍大型软件研发成功的唯一的主要困难,Brooks 提出的其它几种原因都是因复杂性无法管理而导致的次生灾害,复杂性是根源。这篇论文,也引用了几位图灵奖得主对复杂性的精彩论述:
“...we have to keep it crisp, disentangled, and simple if we refuse to be crushed by the complexities of our own making...”(by Dijkstra)
“The general problem with ambitious systems is complexity.”, “...it is important to emphasize the value of simplicity and elegance, for complexity has a way of compounding difficulties” (by Corbato)
“there is a desperate need for a powerful methodology to help us think about programs. ... conventional languages create unnecessary confusion in the way we think about programs” (by Backus)
“...there is one quality that cannot be purchased... — and that is reliability. The price of reliability is the pursuit of the utmost simplicity”
“I conclude that there are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies and the other way is to make it so complicated that there are no obvious deficiencies. The first method is far more difficult.”(by Hoare) 把事情做简单是最难的事情,也是对抗复杂性的唯一途径:一方面,简单性意味着可理解性,可理解性对于大型软件的维护和迭代至关重要;另一方面,虽然简单的抽象并不保证简单的实现,但过度复杂的抽象几乎一定意味着复杂的实现。 本文将以TensorFlow中“依赖引擎”的设计为例讨论它是如何违反奥卡姆剃刀准则的。 2 背景:深度学习框架的依赖引擎 深度学习框架和其它分布式计算引擎都喜欢使用数据流模型(Dataflow),直白点说,就是一个有向无环图(DAG),图中的节点分成两种类型,一种是操作节点(op),一种是数据节点(data)。 在数据流模型中,一个操作是否可以开始执行取决于这个操作的输入数据是否就绪,因此所有操作按照有向无环图的拓扑序来执行。
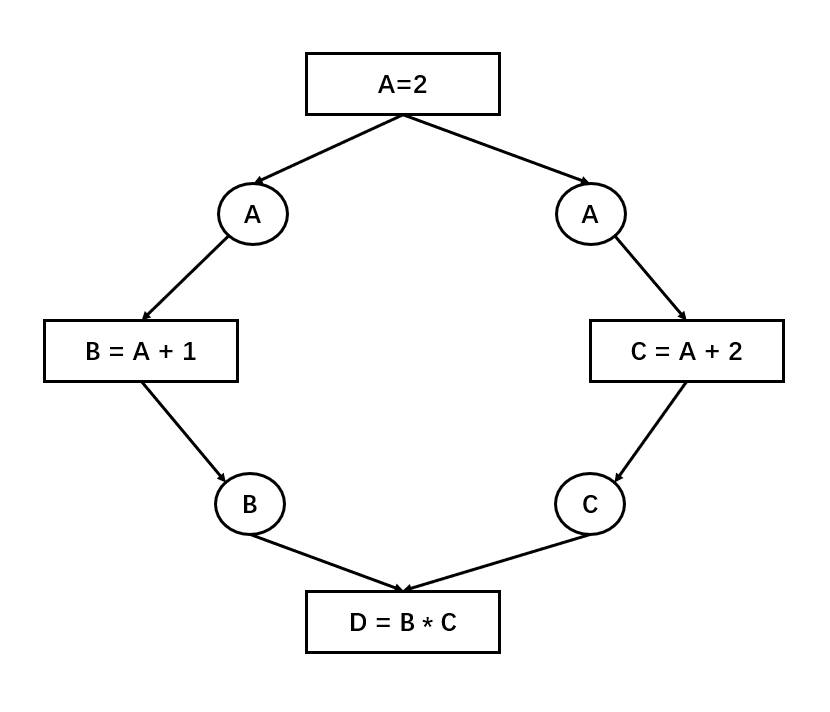 以上图为例,方块表示op,一共有4个op,圆圈表示data(从生产者视角看A实际上只有一份,从消费者视角看有两份,因此画了两遍)。如图所示,{B=A+1}和{C=A+2}之间没有依赖关系,它们之间的执行顺序是未规定的,只要计算资源充足,它们可以并行的执行。如果翻译成命令式程序,以下两个代码片段都是合法的:
以上图为例,方块表示op,一共有4个op,圆圈表示data(从生产者视角看A实际上只有一份,从消费者视角看有两份,因此画了两遍)。如图所示,{B=A+1}和{C=A+2}之间没有依赖关系,它们之间的执行顺序是未规定的,只要计算资源充足,它们可以并行的执行。如果翻译成命令式程序,以下两个代码片段都是合法的:
A = 2 | A = 2B = A + 1 | C = A + 2C = A + 2 | B = A + 1D = B * C | D = B * C
基于静态图的深度学习框架都借助一个依赖引擎(Dependency Engine)模块来管理操作之间的依赖关系以及每个操作的触发时机。
依赖引擎通常的实现方法是:为每个代表数据的圆圈设置一个计数器,用于表示该数据是否就绪。计数器初始值是0,当数据的生产者执行结束会把计数器变更为1,当数据的消费者看到计数器变成1了,也就可以读取这个数据了。上图这个例子中,{D=B*C} 这条操作的触发条件是B和C对应的计数器都变为1。 基于静态图机制的深度学习框架,包括TensorFlow和MXNet,执行引擎(executor)都是采用这样的机制来管理op之间的依赖以及每个op的触发时机。 如果不同的op在同一个进程内的不同线程上执行,多个线程可以通过共享内存机制并发访问计数器,只不过为了解决并发读写间的竞争,每个计数器需要加锁或使用原子变量。 如果不同的op分布在不同的进程乃至不同的机器上,跨机器的依赖关系该怎么表达和管理呢?
3 问题:分布式版本的依赖引擎 对于可以借助NCCL这样的集群通信原语(all-reduce, all-gather, reduce-scatter等)支持的分布式场景(数据并行、模型并行等),各个机器上的子图在计算图层面“看上去”并没有依赖关系,每个节点可以当作完全独立的计算图来管理(这个依赖关系是通过底层集群通信隐式实现的),在执行引擎层面的复杂度反而不大。 但是,当面临”不规则的通信模式“,一个跨机器的依赖关系是通过peer to peer通信来实现生产者和消费者的交互时(生产者在一台机器上,消费者在另一台机器上),就引入一些微妙的问题,复杂性还超过了那些可以被集群通信原语解决的场景,下面只讨论这种情况。 当计算图中的op以peer to peer的方式被划分到不同的机器上时,功能上需要支持:(1)生产者的数据从生产者所在的机器发送到消费者所在的机器上;(2)状态计数器到底该放在生产者所在的进程还是消费者的进程上?(3)如果放在消费者的进程上,生产者通过什么办法去修改这个计数器?
4 TensorFlow对跨机器数据搬运的抽象 让我们看看TensorFlow如何解决生产者-消费者跨网络问题。

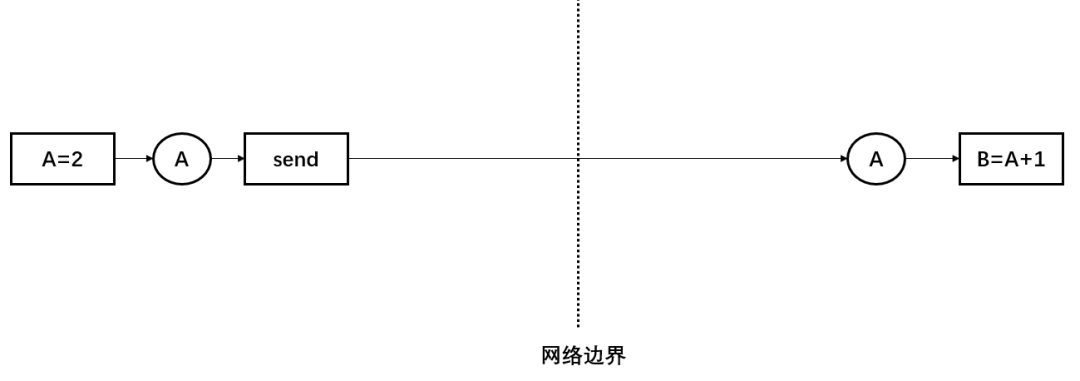
图中虚线表示机器之间的边界,{A=2}在左半部分的机器上执行,{B=A+1}在右半部分的机器上执行,左边的机器生产了A之后,需要被搬运到右边的机器上才能被消费。 实现跨机器的状态同步,一个自然的实现是”消息传递“。TensorFlow在计算图中插入一对send和recv操作,把计算图中用户编写的普通op和跨机器数据搬运解耦,普通的op不需要操心和处理跨机器通信的麻烦。譬如,在生产者一端,{A=2} 执行完毕之后,生产者知道A被send消费,只需要把数据交给send即可。在消费者一端,{B=A+1}知道自己依赖的A要从recv处取,只需要等待recv执行完毕即可。 为了解决send和recv之间执行节奏不匹配的问题,TensorFlow还在生产者一侧引入了rendezvous(约会)的概念,大概的逻辑是: 1、send把数据放在rendezvous的KV字典里,如果发现recv端已经把取数据的需求发过来了,二者正好接上头,就立刻启动底层的数据传输,如果此时recv端还没有发请求过来,只需要把数据放到KV字典里,等待recv发请求过来即可。 2、recv一端向rendezvous请求数据,如果发现数据已经在KV字典里,就立刻启动底层数据传输,如果发现字典里没有需要的数据,那么就把启动数据传输包装进一个回调函数(callback)放在KV字典里,等待send把数据放进KV字典时触发回调函数。 我们可以思考一下:为了让依赖引擎支持生产者和消费者跨机器的问题,TensorFlow的抽象是不是最小化的?是否做到了像奥卡姆剃刀准则一样”如无必要,勿增实体“?它有没有冗余的概念:rendezvous是必要的吗?send和recv都是必要的吗?
5 一定要”约会“吗? Rendezvous主要是为了解决生产者和消费者之间”握手“的需求,放在消费者一端也是可行的,譬如: 生产者一旦生成数据A,可以不用关心消费者一端是否已开始执行,只管把数据发送到消费者所在的机器。如果数据到达了消费者的机器,但消费者子图还没启动,就等消费者子图启动来使用这个数据即可;如果数据到达消费者的机器时,消费者子图已经启动而且正在等待,那么就触发包含消费者子图的回调函数即可。 考虑到我们在处理静态图,每台机器上要执行的子图都是提前知道的,生产者和消费者的关系也是提前知道的,rendezvous并不是必要的,为什么呢? 在静态图机制中很容易实现的一点:数据开始流进系统之前,各个机器上的子图已经初始化完毕(OneFlow是这样做的,当所有机器上的所有子图对应的actor都初始化完毕之后,源头的数据才允许向下流,其实通过一个barrier就实现了)。只要保证这一点,rendezvous就可以去掉,因为生产者确定地知道消费者所在的子图在另一端在等待数据了。 实际上即使在使用动态图机制的PyTorch中,在进行peer to peer传输时,只引入了send和recv抽象,并没有引入rendezvous这个概念。 把多余的rendezvous去掉之后,生产者-消费者跨越网络的概念可以得到简化,如下图所示:
 6
send和recv:二选一
从抽象层面看,如果我们定义send操作的职责是把数据发送(Push)到另外一台机器上,以及定义recv操作的职责是把另外一台机器上的数据拉取(Pull)到本地,会发现无论是生产者主动推送(Push),还是消费者主动拉取(Pull),send和recv二者只需其一。如果非要同时引入,那么send和recv中总有一个操作仅仅扮演了placeholder的角色,不做实际的操作。
更进一步,同时引入send和recv不仅仅是引入多余概念的问题,而是破坏了系统的一致性(回想一下《人月神话》如何强调概念一致性的重要性):一个使用数据流抽象的系统可以使用Push语义,也可以使用Pull语义,但同时使用Push语义和Pull语义,会让系统难以理解。
6
send和recv:二选一
从抽象层面看,如果我们定义send操作的职责是把数据发送(Push)到另外一台机器上,以及定义recv操作的职责是把另外一台机器上的数据拉取(Pull)到本地,会发现无论是生产者主动推送(Push),还是消费者主动拉取(Pull),send和recv二者只需其一。如果非要同时引入,那么send和recv中总有一个操作仅仅扮演了placeholder的角色,不做实际的操作。
更进一步,同时引入send和recv不仅仅是引入多余概念的问题,而是破坏了系统的一致性(回想一下《人月神话》如何强调概念一致性的重要性):一个使用数据流抽象的系统可以使用Push语义,也可以使用Pull语义,但同时使用Push语义和Pull语义,会让系统难以理解。
 如果是生产端主动把数据Push到消费者一端,那么recv是多余的,PyTorch的send和recv可以认为是采取了Push语义,但引入了多余的recv,recv仅仅是占位符的作用。
如果是生产端主动把数据Push到消费者一端,那么recv是多余的,PyTorch的send和recv可以认为是采取了Push语义,但引入了多余的recv,recv仅仅是占位符的作用。
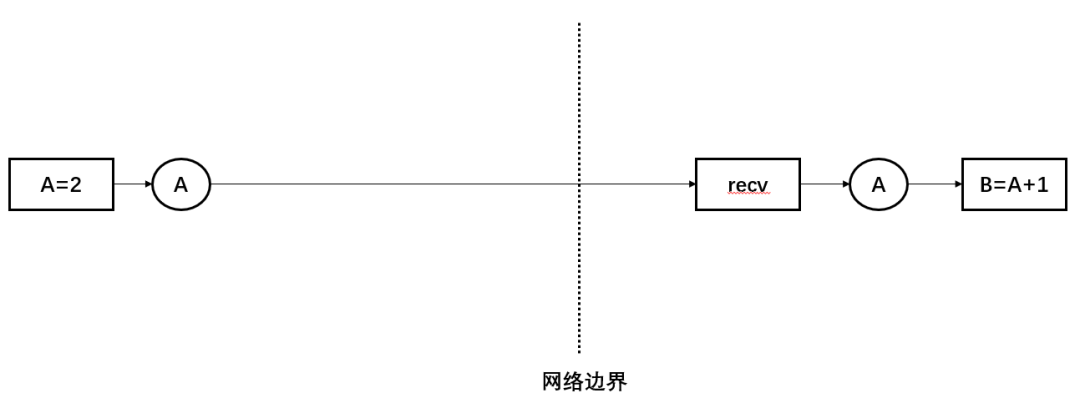 如果是消费端主动把数据Pull过来,那么send就是多余的,TensorFlow的send端总是等待recv端发拉取数据的请求,可以认为采取了Pull语义,send是多余的, send仅仅是占位符的作用。
如果是消费端主动把数据Pull过来,那么send就是多余的,TensorFlow的send端总是等待recv端发拉取数据的请求,可以认为采取了Pull语义,send是多余的, send仅仅是占位符的作用。
7 Push or Pull? 单纯从跨机器的数据搬运的功能需求来看,Push和Pull二者是平等的,并没有优劣之分 (扩展一下,RDMA同时提供了READ和WRITE的单边操作)。要做出抉择,就需要在更大的上下文去考察哪个语义更好了,我们希望使用一个语义可以同时cover单机内部的操作和跨机器操作。 单机器内部的op之间有两种类型的交互行为,一类是状态的传递,在这个层面是一种Push语义,譬如生产者执行完毕之后会主动修改消费者所依赖的计数器,从而把状态Push给消费者;另一类是数据的传递,在这个层面是一种Pull语义,譬如生产者并不会把数据推送给消费者,而是消费者根据自己的需要去读取生产者产出的数据,这种Pull语义的出发点是Zero-copy,效率高。 显然,我们在选择send op还是recv op时,功能需求是数据传递,我们应该选择Pull语义。从这个角度看,PyTorch的Push语义是不自然的,TensorFlow的Pull语义是自然的,不过它的send是多余的。 OneFlow采用了Pull语义,无论是机器内部还是跨机器的关系,消费者op总是从生产者op那里拉取数据,因此只引入了recv,而没有引入send。 通过统一采用Pull语义,在计算图层面的概念上实现了统一,用一句话就可以把系统的数据流动机制解释清楚:机器内部消费者读取生产者产出的数据和跨机器的数据拉取在语义上是一致的,只不过生产者和消费者同在一台机器时,消费者从自身所在的机器读取,并写入到同一台机器上,而当生产者和消费者不在同一台机器时,消费者(recv)是从另一台机器读取而写到所在的机器上而已。 这种概念的一致性会降低认知负担,只需要用最简单的Pull规则就能同时解释单机和多机的情况。 以上讨论的是抽象层面,在实现层面是另一个问题。如果底层通信使用RDMA,那么一个READ的单边操作就可以把Pull支持起来,如果底层是套接字(socket),那么底层要通过send和recv的配合来实现Pull的语义,OneFlow的CommNet模块恰恰是这么实现的。 8 小结 依赖引擎是深度学习框架的核心模块,基于共享内存的计数器机制是实现单机依赖引擎的常见方法。 当引入分布式计算时,跨机器的依赖关系通常借助“消息传递”来实现(当然,如果有分布式共享内存机制的支持,继续使用共享内存的计数器机制也不是不可以)。 TensorFlow在使用“消息传递”实现分布式依赖引擎时引入了多个多余的概念,并不符合“如无必要,勿增实体”。当去除多余的抽象之后,TensorFlow的实现上可以被简化。 借助这个”吹毛求疵“的过程,我想分享的是:只有对极简的偏执追求,才会得到事物的本质。 你可能注意到:单机器内部依靠共享内存的编程模式,跨机器使用消息传递的编程模式,这里又引入了不一致性,这是不是一个问题呢?我们在下一篇文章继续讨论,敬请期待。
注:题图源自Pixabay, xresch
其他人都在看
点击“ 阅读原文 ” ,欢 迎下载体验OneFlow新一代开源深度学习框架











