一、Lucene简介
1.1 Lucene是什么?
-
Lucene是Apache基金会jakarta项目组的一个子项目;
-
Lucene是一个开放源码的全文检索引擎工具包,提供了完整的查询引擎和索引引擎,部分语种文本分析引擎;
-
Lucene并不是一个完整的全文检索引擎,仅提供了全文检索引擎架构,但仍可以作为一个工具包结合各类插件为项目提供部分高性能的全文检索功能;
-
现在常用的ElasticSearch、Solr等全文搜索引擎均是基于Lucene实现的。
1.2 Lucene的使用场景
适用于需要数据索引量不大的场景,当索引量过大时需要使用ES、Solr等全文搜索服务器实现搜索功能。
1.3 通过本文你能了解到哪些内容?
-
Lucene如此繁杂的索引如何生成并写入,索引中的各个文件又在起着什么样的作用?
-
Lucene全文索引如何进行高效搜索?
-
Lucene如何优化搜索结果,使用户根据关键词搜索到想要的内容?
本文旨在分享Lucene搜索引擎的源码阅读和功能开发中的经验,Lucene采用7.3.1版本。
二、Lucene基础工作流程
索引的生成分为两个部分:
1. 创建阶段:
-
添加文档阶段,通过IndexWriter调用addDocument方法生成正向索引文件;
-
文档添加后,通过flush或merge操作生成倒排索引文件。
2. 搜索阶段:
-
用户通过查询语句向Lucene发送查询请求;
-
通过IndexSearch下的IndexReader读取索引库内容,获取文档索引;
-
得到搜索结果后,基于搜索算法对结果进行排序后返回。
索引创建及搜索流程如下图所示:

三、Lucene索引构成
3.1 正向索引
Lucene的基础层次结构由索引、段、文档、域、词五个部分组成。正向索引的生成即为基于Lucene的基础层次结构一级一级处理文档并分解域存储词的过程。
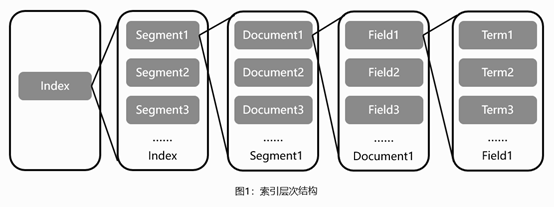
索引文件层级关系如图1所示:
-
索引:Lucene索引库包含了搜索文本的所有内容,可以通过文件或文件流的方式存储在不同的数据库或文件目录下。
-
段:一个索引中包含多个段,段与段之间相互独立。由于Lucene进行关键词检索时需要加载索引段进行下一步搜索,如果索引段较多会增加较大的I/O开销,减慢检索速度,因此写入时会通过段合并策略对不同的段进行合并。
-
文档:Lucene会将文档写入段中,一个段中包含多个文档。
-
域:一篇文档会包含多种不同的字段,不同的字段保存在不同的域中。
-
词:Lucene会通过分词器将域中的字符串通过词法分析和语言处理后拆分成词,Lucene通过这些关键词进行全文检索。
3.2 倒排索引
Lucene全文索引的核心是基于倒排索引实现的快速索引机制。
倒排索引原理如图2所示,倒排索引简单来说就是基于分析器将文本内容进行分词后,记录每个词出现在哪篇文章中,从而通过用户输入的搜索词查询出包含该词的文章。
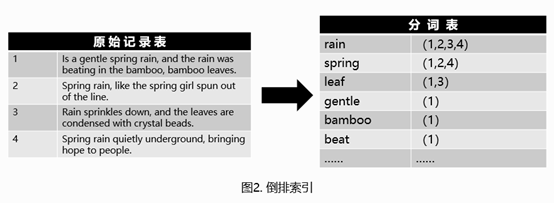
**问题:**上述倒排索引使用时每次都需要将索引词加载到内存中,当文章数量较多,篇幅较长时,索引词可能会占用大量的存储空间,加载到内存后内存损耗较大。
解决方案:从Lucene4开始,Lucene采用了FST来减少索引词带来的空间消耗。
FST(Finite StateTransducers),中文名有限状态机转换器。其主要特点在于以下四点:
-
查找词的时间复杂度为O(len(str));
-
通过将前缀和后缀分开存储的方式,减少了存放词所需的空间;
-
加载时仅将前缀放入内存索引,后缀词在磁盘中进行存放,减少了内存索引使用空间的损耗;
-
FST结构在对PrefixQuery、FuzzyQuery、RegexpQuery等查询条件查询时,查询效率高。
具体存储方式如图3所示:

倒排索引相关文件包含.tip、.tim和.doc这三个文件,其中:
-
tip:用于保存倒排索引Term的前缀,来快速定位.tim文件中属于这个Field的Term的位置,即上图中的aab、abd、bdc。
-
tim:保存了不同前缀对应的相应的Term及相应的倒排表信息,倒排表通过跳表实现快速查找,通过跳表能够跳过一些元素的方式对多条件查询交集、并集、差集之类的集合运算也提高了性能。
-
doc:包含了文档号及词频信息,根据倒排表中的内容返回该文件中保存的文本信息。
3.3 索引查询及文档搜索过程
Lucene利用倒排索引定位需要查询的文档号,通过文档号搜索出文件后,再利用词权重等信息对文档排序后返回。
-
内存加载tip文件,根据FST匹配到后缀词块在tim文件中的位置;
-
根据查询到的后缀词块位置查询到后缀及倒排表的相关信息;
-
根据tim中查询到的倒排表信息从doc文件中定位出文档号及词频信息,完成搜索;
-
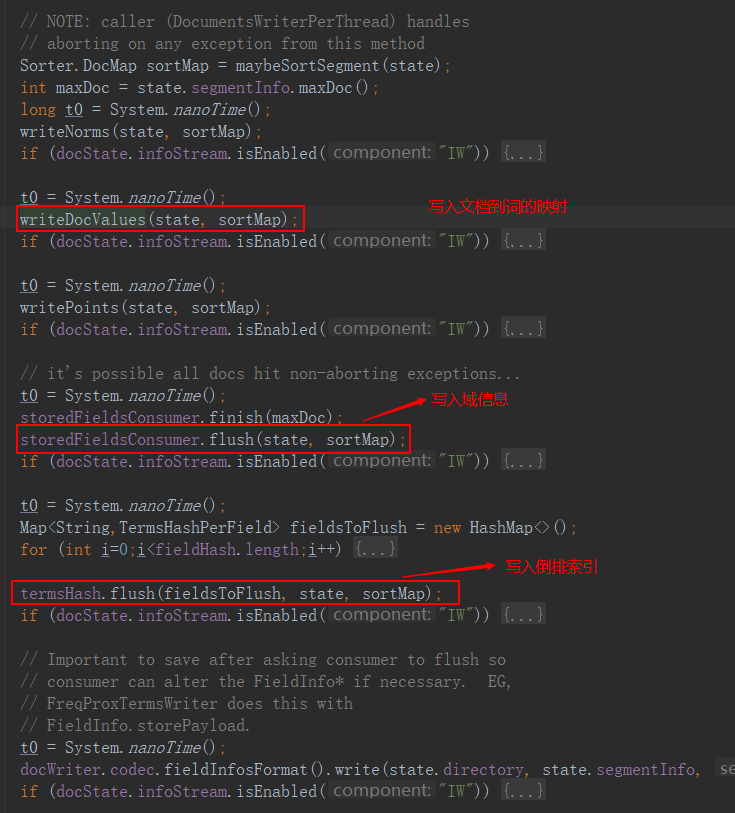
文件定位完成后Lucene将去.fdx文件目录索引及.fdt中根据正向索引查找出目标文件。
文件格式如图4所示:
上文主要讲解Lucene的工作原理,下文将阐述Java中Lucene执行索引、查询等操作的相关代码。
四、Lucene的增删改操作
Lucene项目中文本的解析,存储等操作均由IndexWriter类实现,IndexWriter文件主要由Directory和IndexWriterConfig两个类构成,其中:
Directory:用于指定存放索引文件的目录类型。既然要对文本内容进行搜索,自然需要先将这些文本内容及索引信息写入到目录里。Directory是一个抽象类,针对索引的存储允许有多种不同的实现。常见的存储方式一般包括存储有本地(FSDirectory),内存(RAMDirectory)等。
IndexWriterConfig:用于指定IndexWriter在文件内容写入时的相关配置,包括OpenMode索引构建模式、Similarity相关性算法等。
IndexWriter具体是如何操作索引的呢?让我们来简单分析一下IndexWriter索引操作的相关源码。
4.1. 文档的新增
a. Lucene会为每个文档创建ThreadState对象,对象持有DocumentWriterPerThread来执行文件的增删改操作;
ThreadState getAndLock(Thread requestingThread, DocumentsWriter documentsWriter) {
ThreadState threadState = null;
synchronized (this) {
if (freeList.isEmpty()) {
// 如果不存在已创建的空闲ThreadState,则新创建一个
return newThreadState();
} else {
// freeList后进先出,仅使用有限的ThreadState操作索引
threadState = freeList.remove(freeList.size()-1);
// 优先使用已经初始化过DocumentWriterPerThread的ThreadState,并将其与当前
// ThreadState换位,将其移到队尾优先使用
if (threadState.dwpt == null) {
for(int i=0;i<freeList.size();i++) {
ThreadState ts = freeList.get(i);
if (ts.dwpt != null) {
freeList.set(i, threadState);
threadState = ts;
break;
}
}
}
}
}
threadState.lock();
return threadState;
}
b. 索引文件的插入:DocumentWriterPerThread调用DefaultIndexChain下的processField来处理文档中的每个域,processField方法是索引链的核心执行逻辑。通过用户对每个域设置的不同的FieldType进行相应的索引、分词、存储等操作。FieldType中比较重要的是indexOptions:
-
NONE:域信息不会写入倒排表,索引阶段无法通过该域名进行搜索;
-
DOCS:文档写入倒排表,但由于不记录词频信息,因此出现多次也仅当一次处理;
-
DOCS_AND_FREQS:文档和词频写入倒排表;
-
DOCS_AND_FREQS_AND_POSITIONS:文档、词频及位置写入倒排表;
-
DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS:文档、词频、位置及偏移写入倒排表。
// 构建倒排表
if (fieldType.indexOptions() != IndexOptions.NONE) {
fp = getOrAddField(fieldName, fieldType, true);
boolean first = fp.fieldGen != fieldGen;
// field具体的索引、分词操作
fp.invert(field, first);
if (first) {
fields[fieldCount++] = fp;
fp.fieldGen = fieldGen;
}
} else {
verifyUnIndexedFieldType(fieldName, fieldType);
}
// 存储该field的storeField
if (fieldType.stored()) {
if (fp == null) {
fp = getOrAddField(fieldName, fieldType, false);
}
if (fieldType.stored()) {
String value = field.stringValue();
if (value != null && value.length() > IndexWriter.MAX_STORED_STRING_LENGTH) {
throw new IllegalArgumentException("stored field \"" + field.name() + "\" is too large (" + value.length() + " characters) to store");
}
try {
storedFieldsConsumer.writeField(fp.fieldInfo, field);
} catch (Throwable th) {
throw AbortingException.wrap(th);
}
}
}
// 建立DocValue(通过文档查询文档下包含了哪些词)
DocValuesType dvType = fieldType.docValuesType();
if (dvType == null) {
throw new NullPointerException("docValuesType must not be null (field: \"" + fieldName + "\")");
}
if (dvType != DocValuesType.NONE) {
if (fp == null) {
fp = getOrAddField(fieldName, fieldType, false);
}
indexDocValue(fp, dvType, field);
}
if (fieldType.pointDimensionCount() != 0) {
if (fp == null) {
fp = getOrAddField(fieldName, fieldType, false);
}
indexPoint(fp, field);
}
c. 解析Field首先需要构造TokenStream类,用于产生和转换token流,TokenStream有两个重要的派生类Tokenizer和TokenFilter,其中Tokenizer用于通过java.io.Reader类读取字符,产生Token流,然后通过任意数量的TokenFilter来处理这些输入的Token流,具体源码如下:
// invert:对Field进行分词处理首先需要将Field转化为TokenStream
try (TokenStream stream = tokenStream = field.tokenStream(docState.analyzer, tokenStream))
// TokenStream在不同分词器下实现不同,根据不同分词器返回相应的TokenStream
if (tokenStream != null) {
return tokenStream;
} else if (readerValue() != null) {
return analyzer.tokenStream(name(), readerValue());
} else if (stringValue() != null) {
return analyzer.tokenStream(name(), stringValue());
}
public final TokenStream tokenStream(final String fieldName, final Reader reader) {
// 通过复用策略,如果TokenStreamComponents中已经存在Component则复用。
TokenStreamComponents components = reuseStrategy.getReusableComponents(this, fieldName);
final Reader r = initReader(fieldName, reader);
// 如果Component不存在,则根据分词器创建对应的Components。
if (components == null) {
components = createComponents(fieldName);
reuseStrategy.setReusableComponents(this, fieldName, components);
}
// 将java.io.Reader输入流传入Component中。
components.setReader(r);
return components.getTokenStream();
}
d. 根据IndexWriterConfig中配置的分词器,通过策略模式返回分词器对应的分词组件,针对不同的语言及不同的分词需求,分词组件存在很多不同的实现。
-
StopAnalyzer:停用词分词器,用于过滤词汇中特定字符串或单词。
-
StandardAnalyzer:标准分词器,能够根据数字、字母等进行分词,支持词表过滤替代StopAnalyzer功能,支持中文简单分词。
-
CJKAnalyzer:能够根据中文语言习惯对中文分词提供了比较好的支持。
以StandardAnalyzer(标准分词器)为例:
// 标准分词器创建Component过程,涵盖了标准分词处理器、Term转化小写、常用词过滤三个功能
protected TokenStreamComponents createComponents(final String fieldName) {
final StandardTokenizer src = new StandardTokenizer();
src.setMaxTokenLength(maxTokenLength);
TokenStream tok = new StandardFilter(src);
tok = new LowerCaseFilter(tok);
tok = new StopFilter(tok, stopwords);
return new TokenStreamComponents(src, tok) {
@Override
protected void setReader(final Reader reader) {
src.setMaxTokenLength(StandardAnalyzer.this.maxTokenLength);
super.setReader(reader);
}
};
}
e. 在获取TokenStream之后通过TokenStream中的incrementToken方法分析并获取属性,再通过TermsHashPerField下的add方法构建倒排表,最终将Field的相关数据存储到类型为FreqProxPostingsArray的freqProxPostingsArray中,以及TermVectorsPostingsArray的termVectorsPostingsArray中,构成倒排表;
// 以LowerCaseFilter为例,通过其下的increamentToken将Token中的字符转化为小写
public final boolean incrementToken() throws IOException {
if (input.incrementToken()) {
CharacterUtils.toLowerCase(termAtt.buffer(), 0, termAtt.length());
return true;
} else
return false;
}
try (TokenStream stream = tokenStream = field.tokenStream(docState.analyzer, tokenStream)) {
// reset TokenStream
stream.reset();
invertState.setAttributeSource(stream);
termsHashPerField.start(field, first);
// 分析并获取Token属性
while (stream.incrementToken()) {
……
try {
// 构建倒排表
termsHashPerField.add();
} catch (MaxBytesLengthExceededException e) {
……
} catch (Throwable th) {
throw AbortingException.wrap(th);
}
}
……
}
4.2 文档的删除
a. Lucene下文档的删除,首先将要删除的Term或Query添加到删除队列中;
synchronized long deleteTerms(final Term... terms) throws IOException {
// TODO why is this synchronized?
final DocumentsWriterDeleteQueue deleteQueue = this.deleteQueue;
// 文档删除操作是将删除的词信息添加到删除队列中,根据flush策略进行删除
long seqNo = deleteQueue.addDelete(terms);
flushControl.doOnDelete();
lastSeqNo = Math.max(lastSeqNo, seqNo);
if (applyAllDeletes(deleteQueue)) {
seqNo = -seqNo;
}
return seqNo;
}
b. 根据Flush策略触发删除操作;
private boolean applyAllDeletes(DocumentsWriterDeleteQueue deleteQueue) throws IOException {
// 判断是否满足删除条件 --> onDelete
if (flushControl.getAndResetApplyAllDeletes()) {
if (deleteQueue != null) {
ticketQueue.addDeletes(deleteQueue);
}
// 指定执行删除操作的event
putEvent(ApplyDeletesEvent.INSTANCE); // apply deletes event forces a purge
return true;
}
return false;
}
public void onDelete(DocumentsWriterFlushControl control, ThreadState state) {
// 判断并设置是否满足删除条件
if ((flushOnRAM() && control.getDeleteBytesUsed() > 1024*1024*indexWriterConfig.getRAMBufferSizeMB())) {
control.setApplyAllDeletes();
if (infoStream.isEnabled("FP")) {
infoStream.message("FP", "force apply deletes bytesUsed=" + control.getDeleteBytesUsed() + " vs ramBufferMB=" + indexWriterConfig.getRAMBufferSizeMB());
}
}
}
4.3 文档的更新
文档的更新就是一个先删除后插入的过程,本文就不再做更多赘述。
4.4 索引Flush
文档写入到一定数量后,会由某一线程触发IndexWriter的Flush操作,生成段并将内存中的Document信息写到硬盘上。Flush操作目前仅有一种策略:FlushByRamOrCountsPolicy。FlushByRamOrCountsPolicy主要基于两种策略自动执行Flush操作:
-
maxBufferedDocs:文档收集到一定数量时触发Flush操作。
-
ramBufferSizeMB:文档内容达到限定值时触发Flush操作。
其中 activeBytes() 为dwpt收集的索引所占的内存量,deleteByteUsed为删除的索引量。
@Override
public void onInsert(DocumentsWriterFlushControl control, ThreadState state) {
// 根据文档数进行Flush
if (flushOnDocCount()
&& state.dwpt.getNumDocsInRAM() >= indexWriterConfig
.getMaxBufferedDocs()) {
// Flush this state by num docs
control.setFlushPending(state);
// 根据内存使用量进行Flush
} else if (flushOnRAM()) {// flush by RAM
final long limit = (long) (indexWriterConfig.getRAMBufferSizeMB() * 1024.d * 1024.d);
final long totalRam = control.activeBytes() + control.getDeleteBytesUsed();
if (totalRam >= limit) {
if (infoStream.isEnabled("FP")) {
infoStream.message("FP", "trigger flush: activeBytes=" + control.activeBytes() + " deleteBytes=" + control.getDeleteBytesUsed() + " vs limit=" + limit);
}
markLargestWriterPending(control, state, totalRam);
}
}
}
将内存信息写入索引库。
索引的Flush分为主动Flush和自动Flush,根据策略触发的Flush操作为自动Flush,主动Flush的执行与自动Flush有较大区别,关于主动Flush本文暂不多做赘述。需要了解的话可以跳转链接。
4.5 索引段Merge
索引Flush时每个dwpt会单独生成一个segment,当segment过多时进行全文检索可能会跨多个segment,产生多次加载的情况,因此需要对过多的segment进行合并。
段合并的执行通过MergeScheduler进行管理。mergeScheduler也包含了多种管理策略,包括NoMergeScheduler、SerialMergeScheduler和ConcurrentMergeScheduler。
- merge操作首先需要通过updatePendingMerges方法根据段的合并策略查询需要合并的段。段合并策略分为很多种,本文仅介绍两种Lucene默认使用的段合并策略:TieredMergePolicy和LogMergePolicy。
-
TieredMergePolicy:先通过OneMerge打分机制对IndexWriter提供的段集进行排序,然后在排序后的段集中选取部分(可能不连续)段来生成一个待合并段集,即非相邻的段文件(Non-adjacent Segment)。
-
LogMergePolicy:定长的合并方式,通过maxLevel、LEVEL_LOG_SPAN、levelBottom参数将连续的段分为不同的层级,再通过mergeFactor从每个层级中选取段进行合并。
private synchronized boolean updatePendingMerges(MergePolicy mergePolicy, MergeTrigger trigger, int maxNumSegments)
throws IOException {
final MergePolicy.MergeSpecification spec;
// 查询需要合并的段
if (maxNumSegments != UNBOUNDED_MAX_MERGE_SEGMENTS) {
assert trigger == MergeTrigger.EXPLICIT || trigger == MergeTrigger.MERGE_FINISHED :
"Expected EXPLICT or MERGE_FINISHED as trigger even with maxNumSegments set but was: " + trigger.name();
spec = mergePolicy.findForcedMerges(segmentInfos, maxNumSegments, Collections.unmodifiableMap(segmentsToMerge), this);
newMergesFound = spec != null;
if (newMergesFound) {
final int numMerges = spec.merges.size();
for(int i=0;i<numMerges;i++) {
final MergePolicy.OneMerge merge = spec.merges.get(i);
merge.maxNumSegments = maxNumSegments;
}
}
} else {
spec = mergePolicy.findMerges(trigger, segmentInfos, this);
}
// 注册所有需要合并的段
newMergesFound = spec != null;
if (newMergesFound) {
final int numMerges = spec.merges.size();
for(int i=0;i<numMerges;i++) {
registerMerge(spec.merges.get(i));
}
}
return newMergesFound;
}
2)通过ConcurrentMergeScheduler类中的merge方法创建用户合并的线程MergeThread并启动。
@Override
public synchronized void merge(IndexWriter writer, MergeTrigger trigger, boolean newMergesFound) throws IOException {
……
while (true) {
……
// 取出注册的后选段
OneMerge merge = writer.getNextMerge();
boolean success = false;
try {
// 构建用于合并的线程MergeThread
final MergeThread newMergeThread = getMergeThread(writer, merge);
mergeThreads.add(newMergeThread);
updateIOThrottle(newMergeThread.merge, newMergeThread.rateLimiter);
if (verbose()) {
message(" launch new thread [" + newMergeThread.getName() + "]");
}
// 启用线程
newMergeThread.start();
updateMergeThreads();
success = true;
} finally {
if (!success) {
writer.mergeFinish(merge);
}
}
}
}
3)通过doMerge方法执行merge操作;
public void merge(MergePolicy.OneMerge merge) throws IOException {
……
try {
// 用于处理merge前缓存任务及新段相关信息生成
mergeInit(merge);
// 执行段之间的merge操作
mergeMiddle(merge, mergePolicy);
mergeSuccess(merge);
success = true;
} catch (Throwable t) {
handleMergeException(t, merge);
} finally {
// merge完成后的收尾工作
mergeFinish(merge)
}
……
}
五、Lucene搜索功能实现
5.1 加载索引库
Lucene想要执行搜索首先需要将索引段加载到内存中,由于加载索引库的操作非常耗时,因此仅有当索引库产生变化时需要重新加载索引库。
加载索引库分为加载段信息和加载文档信息两个部分:
1)加载段信息:
-
通过segments.gen文件获取段中最大的generation,获取段整体信息;
-
读取.si文件,构造SegmentInfo对象,最后汇总得到SegmentInfos对象。
2)加载文档信息:
-
读取段信息,并从.fnm文件中获取相应的FieldInfo,构造FieldInfos;
-
打开倒排表的相关文件和词典文件;
-
读取索引的统计信息和相关norms信息;
-
读取文档文件。

5.2 封装
索引库加载完成后需要IndexReader封装进IndexSearch,IndexSearch通过用户构造的Query语句和指定的Similarity文本相似度算法(默认BM25)返回用户需要的结果。通过IndexSearch.search方法实现搜索功能。
搜索:Query包含多种实现,包括BooleanQuery、PhraseQuery、TermQuery、PrefixQuery等多种查询方法,使用者可根据项目需求构造查询语句
排序:IndexSearch除了通过Similarity计算文档相关性分值排序外,也提供了BoostQuery的方式让用户指定关键词分值,定制排序。Similarity相关性算法也包含很多种不同的相关性分值计算实现,此处暂不做赘述,读者有需要可自行网上查阅。
六、总结
Lucene作为全文索引工具包,为中小型项目提供了强大的全文检索功能支持,但Lucene在使用的过程中存在诸多问题:
-
由于Lucene需要将检索的索引库通过IndexReader读取索引信息并加载到内存中以实现其检索能力,当索引量过大时,会消耗服务部署机器的过多内存。
-
搜索实现比较复杂,需要对每个Field的索引、分词、存储等信息一一设置,使用复杂。
-
Lucene不支持集群。
Lucene使用时存在诸多限制,使用起来也不那么方便,当数据量增大时还是尽量选择ElasticSearch等分布式搜索服务器作为搜索功能的实现方案。
作者:vivo互联网服务器团队-Qian Yulun













