GOTC 2023 企业洞见:整个机器学习的工具最后都会被开源所主导
“关键的并不是底层模型,而是它的可用性,包括 RLHF(Reinforcement Learning from Human Feedback)和与之交互的接口。”
“RLHF 是我们利用人类反馈来做调整的方法,最简单的版本就是展示两个输出,询问哪一个更好,哪一个人类读者更喜欢,然后用强化学习将其反馈到模型中。”
“RLHF 让模型与人类期望的目标保持一致。”
以上言论是不久前 OpenAI CEO Sam Altman(山姆·阿尔特曼)在与麻省理工学院的研究科学家 Lex Fridman(莱克斯·弗瑞德曼)的一场对谈中说出的几句话。
随着 ChatGPT 大杀四方,对于人类知识版图的囊括,和初显的推理能力受到赞叹。而这背后的关键一环则是人类反馈强化学习,随之也引申出一系列数据标注相关的需求。
事实上业界有关于数据标注工具的研发实际上已经进行了很长一段时间,倍赛科技便是走在前头的公司之一。2015 年,机器学习从业者杜霖便创立倍赛科技,开始研发自己的数据标注系统 Origin1,2017 年底才开始承接客户业务。2022 年,倍赛基于 Origin1 打造出“训练数据工程化”开源平台 Xtreme1,并搭建了一套云系统。开源不到一年,便已经几十个用户从开源产品用户转为 SAAS 商业产品客户。
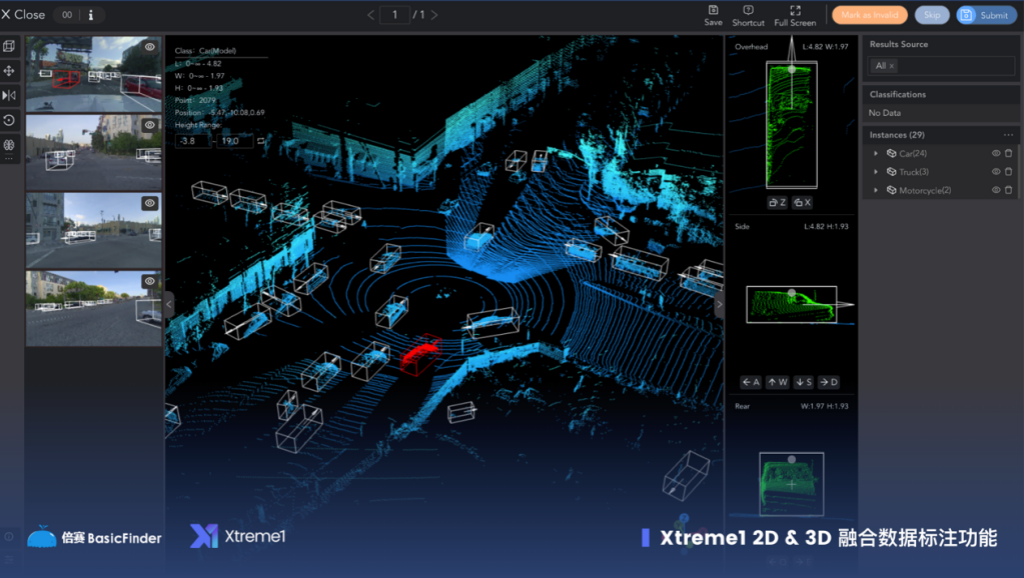
现在回头看,倍赛的成长似乎精妙地提前踩中这一次的 AI 风口,同时其开源产品也在商业市场上取得了不错的成绩。OSC 邀请倍赛创始人杜霖来聊一聊倍赛的成长和背后的故事,以及对当下数据标注领域以及开源的看法。
倍赛科技技术研发总监王家军也将出席 GOTC2023,并带来《Xtreme1 下一代多模态开源训练数据平台》主题演讲,详细介绍 Xtreme1 训练数据平台的技术特性及架构。欢迎感兴趣的小伙伴点击下文链接,报名参会!
参会报名,请访问: https://www.bagevent.com/event/8387611
“我一直坚信工程师和开源能改变世界”

最早接触计算机是在母亲单位用了她的电脑,就喜欢上了这个东西,后来父母给我买了台电脑,那会儿是初中,我就开始自学编程,很痴迷。
高一的时候,我和两位同学组建了机器人小组,我们搭建了一个轮式机器人,并参加了全国科创大赛,当时我负责写机器人控制端和视觉方面的程序。后来我进入上海交大的计算机特长班 A CM班,继续在计算机领域深造,也有了对机器学习、计算机视觉的热爱的底子。
我其实现在也还在写代码,是业余爱好,也是职业。
我一直相信工程师能改变世界,以及开源,我们去做开源也是坚信开源能改变世界。
创立倍赛是因为我本身是机器学习的从业者,我看到训练数据才是消耗机器学习工程师最大时间的一部分。你可以看到 OpenAI 最厉害的地方就是训练数据的工程化能力,它的工程化很大一部分是围绕着训练数据这块的,能力非常强。
所以那会我们就认为在整个行业版图里面,需要一套以训练数据为中心的、从客户端 MLOps 到AI Trainers市场这一整套系统,去加速机器学习的流程。看到这个契机之后,我成立了倍赛。倍赛到现在已经成立 6 年了,数据标注的业务一直是核心业务之一,从业务中我们了解到很多客户在数据训练上的痛点,所以直到两年前,我们决定去凝练所有痛点,打造一个全新的产品,Xtreme1 就这么应运而生了。
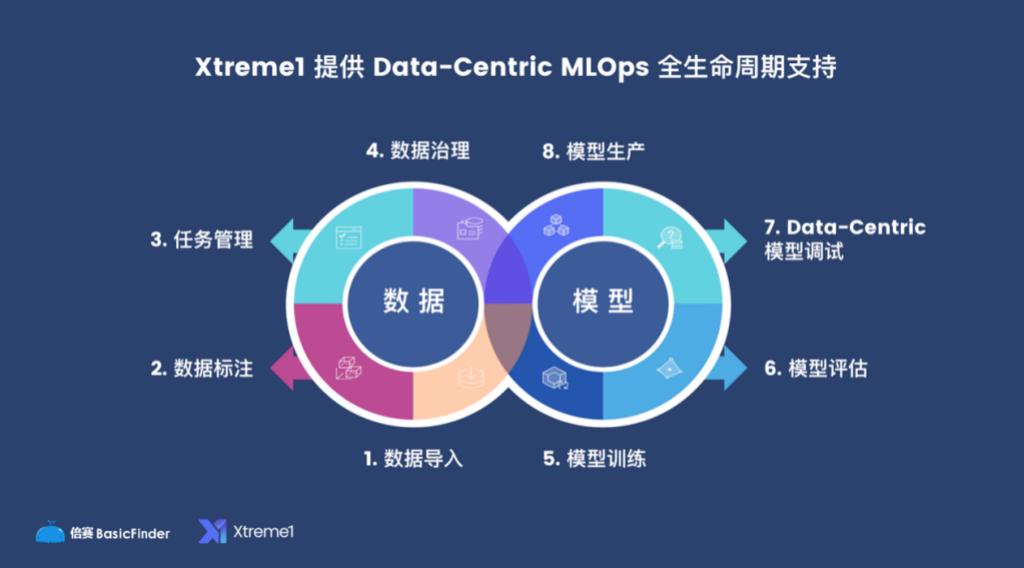
其实数据标注这个事情,以 Model Training 作为时间节点,我们可以将其分成两类,一部分是在 Model Training 之前做的工作,一部分是之后。大家以前可能以为数据标注是前面的部分,标注数据然后建立模型。但其实还有一部分更重要的工作——对整个模型效果的评估,也就是模型反馈回来的推论的结果,需要人去为机器做改错和校正。
这两部分的数据对于模型都非常重要,一部分是构建了基础的模型,一部分相当于通过人类的反馈 输入做了进一步的模型效果的提升。
所以整个机器学习的周期,始终离不开 Human In The Loop,只是随着行业的发展,对于人的这部分的工作会更加精细化、清晰化。所谓清晰化,是说最终我们可以设计出一些流程,来让机器做可以不需要人做的任务,只让人做人必须需要做的任务!这也是我们在搭建 MLOps 工具的目标。
“数据标注的范式在变化,但本质没变”
大语言模型,尤其是最近新兴的这批大语言模型,引入了 Reinforcement Learning From Human Feedback,简称叫 RLHF。
它的核心就是 Human Feedback 作为对大模型的结果的排序和对于答案的修正。本质上就是机器学习引入人的知识来让机器生成的答案和人对齐。
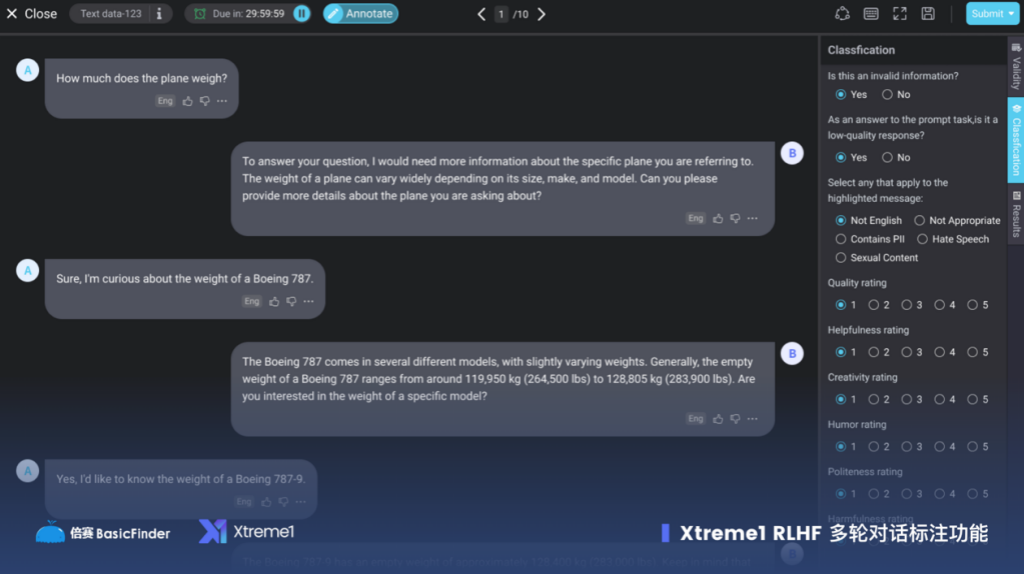
所以为什么它是一个持续的行为,因为大语言模型属于大量的无监督,已经掌握了很多通用的知识,但在一些特垂直的场景上,或者是没见过的语料上,经常会说一些看起来对,但实际都不对的话(hallucination),就是因为没有经过人的标注和对齐。
“From Human Feedback” 依然是 Human In The Loop 。我认为,这是伴随着整个机器学习的生命周期去持续的往前演进的。或者说数据标注的范式发生了变化,但本质没有变化。
范式的变化有两个维度。
一个是我们对于人的要求在逐渐提升,六年前创立倍赛的时候,还有很多 针对2D 图像通用物体的 Object Detection任务,需要对常见物体要进行拉框、打标签处理。伴随着整个模型的进步,这一类作业就慢慢被模型所掌握了,标注的工作就开始迁移到一些更复杂的场景,比如说和客户业务深度结合的场景,或者是机器没有遇到过的corner cases,或者是标注对象有更复杂的属性的场景。所以,标注行业对于人员的要求也在不停提升。
第二个变化就是数据的模态维度在增加,原本我们处理的多是单一图像、语音、文本数据,之后跨模态之间的联合标注开始爆发式增长,比如图文结合、雷达点云和图像结合数据等等。
要说行业的难点。其实整个数据标注依赖的要素由两部分组成。一部分是对人员的需要——AI Trainers,也就是我们所说的数据标注员。那么这第一个挑战便是人员的供给问题,需要有一个对数据标注员的管理、培训、协同和整个任务分发、质检的全流程的平台。尤其是大语言模型出现以后,对人员的要求又有了进一步提升,比如 OpenAI 用了很多博士去帮他们做数据标注的工作,因为他们要求对对话数据的理解力更强。
我们做了一个可量化的、按需分配的标注人力资源平台Origin1 。客户可以通过Origin1 去找到需要的人,分配任务,借助于精准画像以及智能匹配算法,实现了高效任务分发。目前超过5万标注人员和标注公司在我们的平台上接任务,解决了行业对 AI Trainers 弹性的需求。
第二个难点是以数据为中心的 MLOps,这也是我们打造 Xtreme1 开源产品的主要原因。我们认为在客户的业务端,一个很大的痛点是针对客户自己的业务数据,如何将这些数据和标注需求定义好并分发放给标注方,Xtreme1是一个为机器学习工程师解决了数据的管理、可视化,定义标注任务,监控标注流程的一整套训练数据生命周期管理平台。
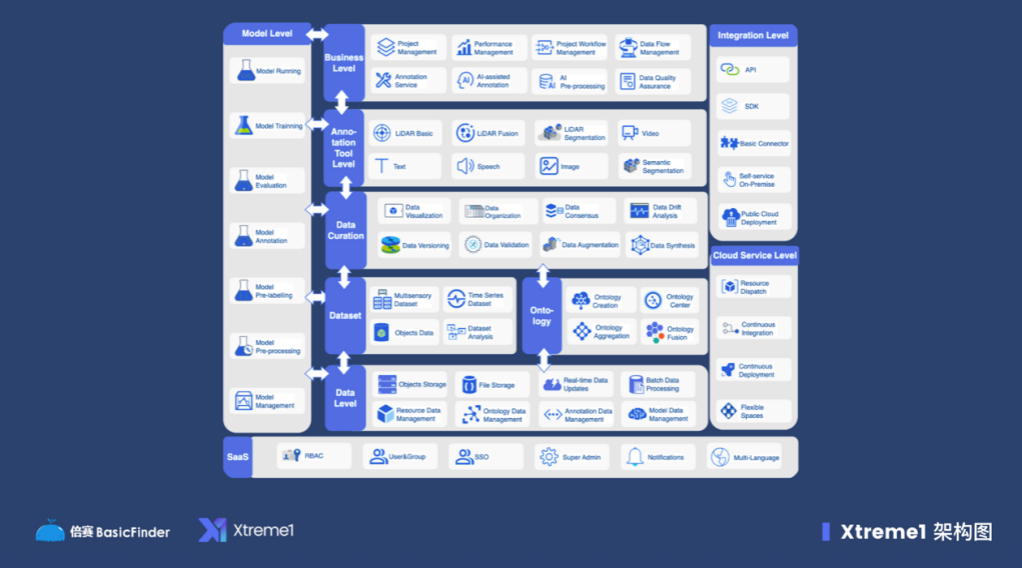
从开源到商业化的正向循环
我们现在有三个产品线:标注人员的任务分配平台 Origin1,开源的 训练数据管理平台Xtreme1以及对应的商业版产品BasicFinder Cloud。我们内部的人马比较平均地分配在三个产品线上,没有说哪个特别重要或特别不重要,因为三个产品共同构成的矩阵能够协同地去完成训练数据标注工作中从供给到需求的全链路工作。
最近比较发力的是在开源端。
开源是一股非常强大的生态,而且在整个生态中,工具链之间是可以产生强协同的,可以加速模型开发效率。
Xtreme1 在 2022 年 9 月决定开源,是因为我们规划清楚了自己的产品定位,在MLOps层需要有一个以数据为中心的训练数据管理平台,并且我们坚信整个机器学习的工具最后都会被开源所主导。
Xtreme1 开源的时候,市场上还没有很多开源的标注类解决方案,尤其是我们主打多模态的能力。我们看到了这样一个以数据为中心的空白地带,既能衔接到机器学习的其他流程,比如数据Pipeline、模型训练、推理、评估等系统;同时又能把我们的这些年通过大量业务积攒的产品能力分享给广大社区用户,来赋能更多的业务场景,所以我们决定开源。
做开源的公司有两种类型,一种是从Day 0开源,从兴趣爱好入手去做开源。另一种是感知到开源的大趋势,在产品有了足够的经验和技术积累后,希望和更多上下游的软件生态区做融合扩大产品影响力,我们属于后者。Xtreme1 现在的商业用户的数量有几十个,这得益于我们的开源路径和模式。很多做开源的公司都会面临一个挑战,平衡开源投入与商业创收。但我们的模式比较清晰,我们在用开源去做生态时,会挖掘到一些对于我们的业务有更强的商业化需求的客户。因为对于很多客户来讲,如果是工程师级别的,他可能就会用一个开源的软件和产品来解决问题,但如果到了企业内部,他们更多地可能会想买一个商业版的软件,因为会有更高的安全性、可控性以及系统性能。
于是就有很多客户从开源产品向我们的商业化版本、SAAS 版本迁移。其实无论是开源用户还是我们的商业软件客户,他们都一定伴随着大量标注需求,他们在用我们的标注软件,我们同时又给他们提供标注服务,这样就形成了一个从开源到商业化的正向循环。
我们骄傲的一件事就是决定把整个开源系统 Xtreme1 捐献给 Linux Foundation ,从2022年9月开始开源,2022 年 12 月决定捐献,2023 年 1 月份就获得了基金会TAC成员的全票认可,成为Linux基金会MLOps 版图中全球首个“Annotation & Visualization”项目,也是目前唯一一个。这个速度非常快。

今年 4 月初我们的全渠道下载量超过2000 。目前GitHub有 400+ star,来自全球的机器学习工程师。
未来我们还会继续壮大开源产品,投入更多研究多模态数据能力,Xtreme1最近的版本已经集成了针对 LLM的多轮对话的标注工具。另外我们也会持续提升产品间的协同能力,实现一站式机器学习训练数据集生命周期管理。
|








- 上一条: GOTC 2023 企业洞见:整个机器学习的工具最后都会被开源所主导 2023-05-17
- 下一条: 没有了
- 开源新秀 MatrixOrigin,即将亮相 GOTC 2023 2023-05-15
- 15 大分论坛不容错过,GOTC 2023 即将拉开帷幕! 2023-03-29
- GOTC2023 嘉宾畅谈:国内数据库厂商能否联合起来 2023-05-11
- GOTC2023 嘉宾畅谈:未来的 5~10 年,其他技术领域的重要性要往 AI 之后排 2023-05-16
- 倒数计时,全球开源技术峰会 GOTC 要来了 2023-05-16