【问题排查篇】一次业务问题对 ES 的 cardinality 原理探究 | 京东云技术团队
作者:京东科技 王长春
业务问题
小编工作中负责业务的一个服务端系统,使用了 Elasticsearch 服务做数据存储,业务运营人员反馈,用户在使用该产品时发现,用户后台统计的订单笔数和导出的订单笔数不一致!
交易订单笔数不对,出现差错订单了?这一听极为震撼!出现这样的问题,在金融科技公司里面是绝对不允许发生的,得马上定位问题并解决!
小编马上联系业务和相关人员,通过梳理上游系统的调用关系,发现业务系统使用到的是我这边的 ES 的存储服务,然后对线上情况进行复现,基本了解问题的现象:
- 用户操作后台里的订单总笔数:商户页面的"订单总笔数","订单总笔数"使用的是小编 ES 存储服务中 ES 的统计聚合功能,其中订单总笔数是使用了 cardinality 操作,并且使用的是 orderId(订单编号)进行统计去重。
- 导出功能里的订单总笔数:导出功能使用的是 ES 存储服务中的 ES 条件查询功能,导出功能是进行分页查询的。
问题定位
这两个查询数量不一致,首先看查询条件是否一致呢?
经过一番排查,业务系统在调用查询订单总数和导出订单总数的这两个查询条件是一致的,也就是请求到我这边 ES 服务时,统计聚合的查询和分页导出的查询条件是一致的,但是为什么会在 ES 里面查询的结果是不一致的呢?难道 ES 里面的数据不全?统计聚合或分页导出的其中有一个不准了?
为了具体排查哪个操作可能存在问题,于是通过相同条件下查询数据库的总数和 ES 里面的数据进行对比。发现相同条件下,数据库里面的数据和 ES 条件查询的总数是一致的, 同时业务的 orerId 字段是没有重复,所以可以确定的是:通过 orderId 进行统计聚合去重的操作是有问题的。
数据库查询:数据库是做分库分表,此处数据库查询使用的是公司内的数据部银河大表——公司数据部会 T+1日从业务从库数据库中抽取 T 日的增量数据放在建立的"大表"中, 方便各业务进行数据使用。
运营后台查询:运营后台查询是直接查询 ES 存储服务。
数据部大表数量 = MySQL 数据库分库分表表里数量 = 运营控制台查询数量 = ES 存储文档数量
问题定位:
ES 存储服务对外给业务提供的: 通过 orderId 进行统计聚合去重(cardinality)的功能应该是有问题的。
ES 的 cardinality 原理探究
上面说过,小编负责的 ES 存储服务对外给业务提供了通过指定业务字段进行统计聚合去重的功能,统计聚合去重使用的是 ES 的 cardinality 功能。通过业务的查询的条件,使用 ES 的聚合功能 cardinality 操作,映射到 ES 层的操作命令如下代码所示,
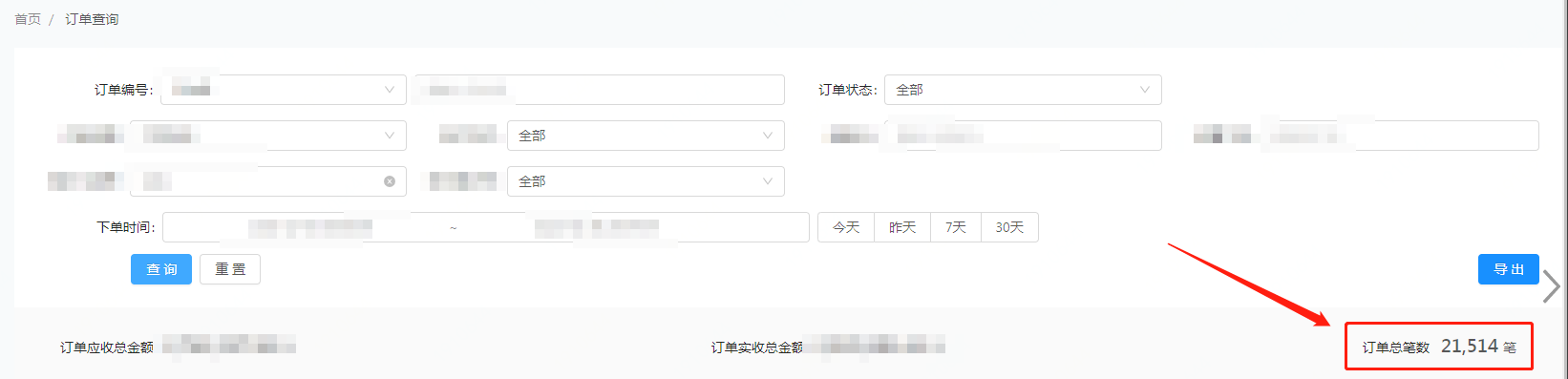
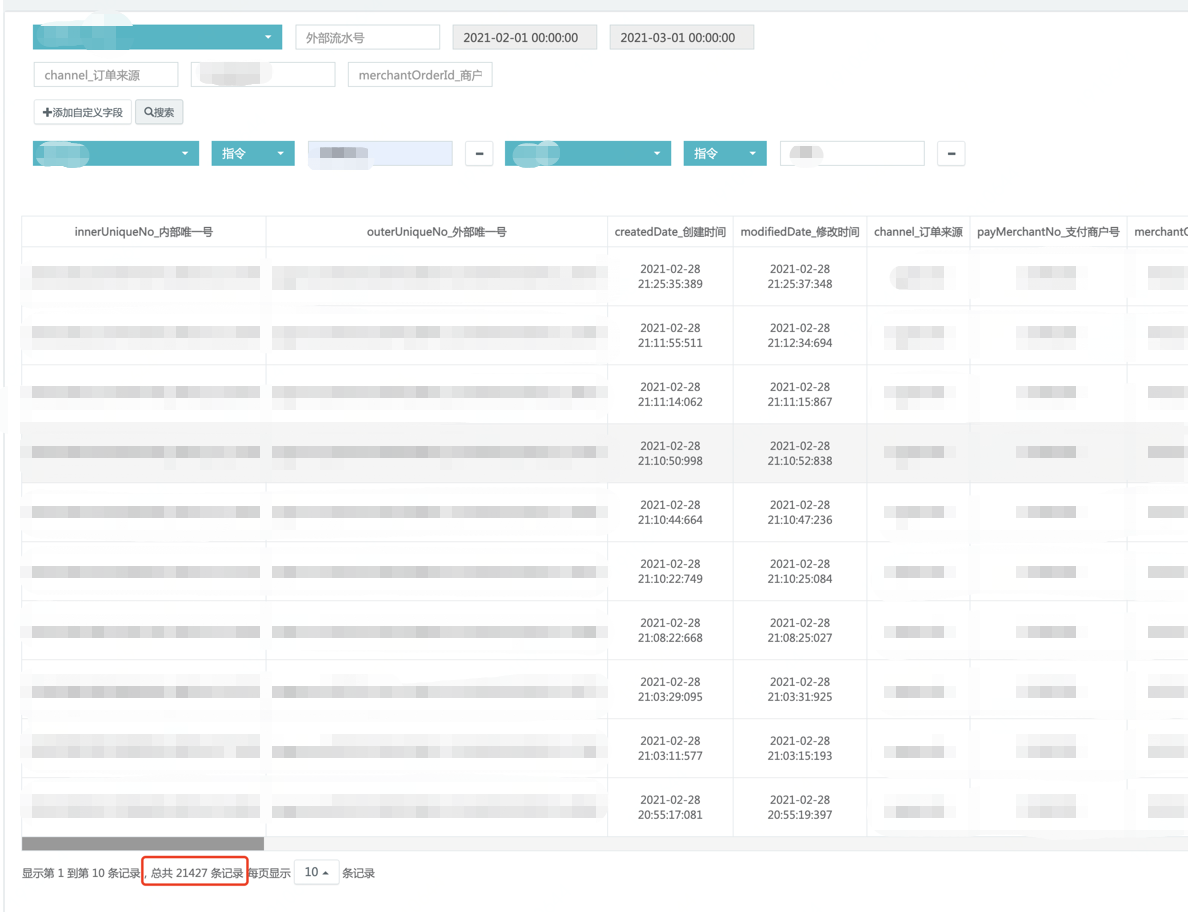
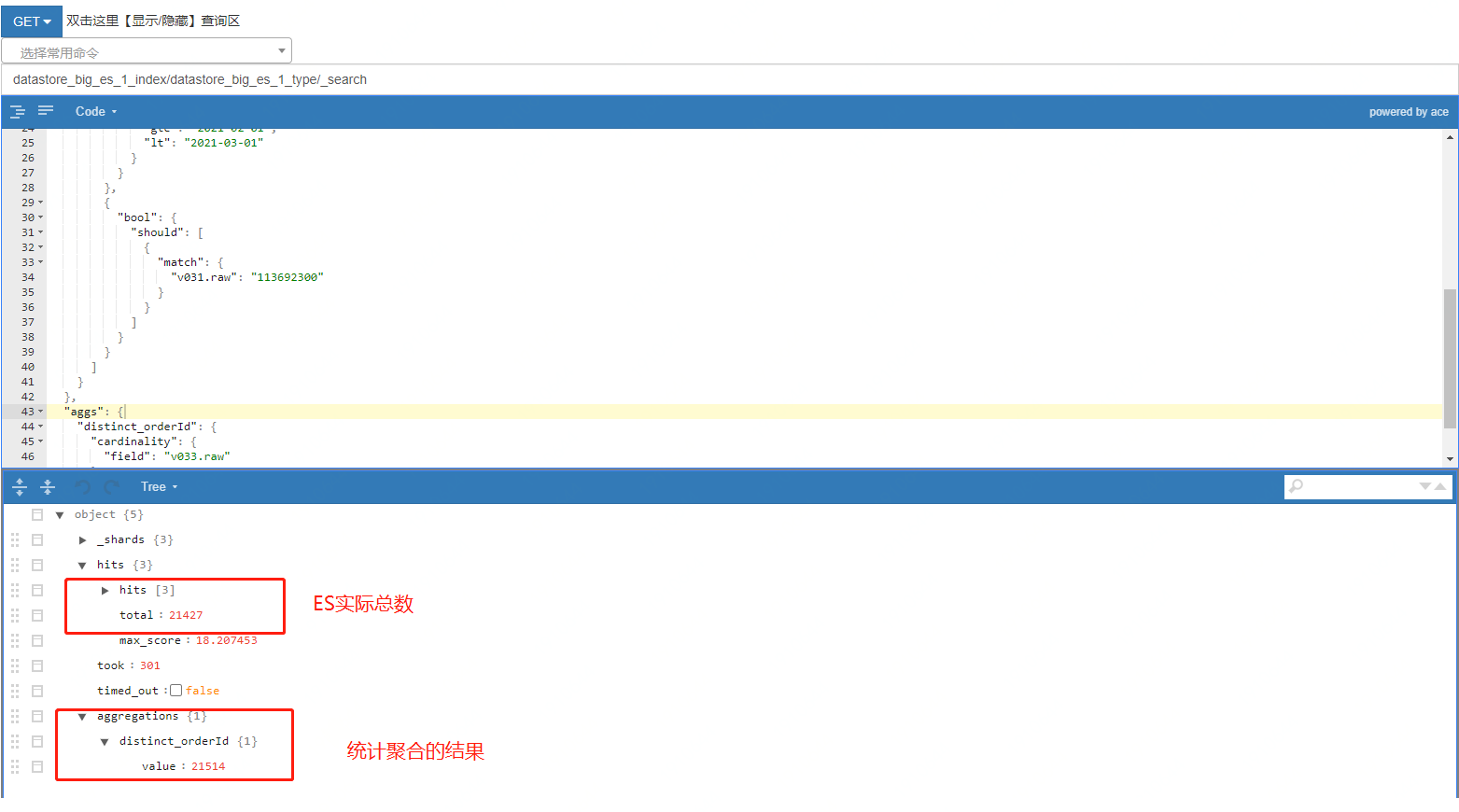
执行业务的查询条件操作,从 ES 的管理端后台里面查询竟然复现了和线上生产一样的结果,聚合统计的是 21514,条件查询的是 21427!!!
可以确定的就是这个 cardinality 操作,导致了两个查询的数据不一致,如下图所示:
GET datastore_big_es_1_index/datastore_big_es_1_type/_search
{
"size": 3,
"query": {
"bool": {
"must": [
{
"match": {
"v021.raw": "selfhelp"
}
},
{
"match": {
"v012.raw": "1001"
}
},
{
"match": {
"typeId": "00029"
}
},
{
"range": {
"createdDate": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
},
{
"bool": {
"should": [
{
"match": {
"v031.raw": "113692300"
}
}
]
}
}
]
}
},
"aggs": {
"distinct_orderId": {
"cardinality": {
"field": "v033.raw"
}
}
}
}
为什么 cardinality 操作会出现这样的结果呢?
小编开始陷入了想当然的陷阱—— 以为这就是一个简简单单的统计去重的功能,ES 做的多好,帮你去重并统计数量了。然后事实并不是,通过 Elasticsearch 对 cardinality 官方文档解释,终于找到了原因。
可以参考Elasticsearch 2.x 版本官方文档对 cardinality的解释:cardinality
其中对 cardinality 算法核心解释是:

可以总结如下:
- cardinality 并不是像关系型数据库 MySQL 一样精确去重的,cardinality做的是一个近似值,是 ES 帮你"估算"出的,这个估算使用的HyperLogLog++(HLL)算法,在速度上非常快,遍历一次即可统计去重,具体可看文档中推荐的论文。
- ES 做cardinality估算,是可以设置估算精确度,即设置参数 precision_threshold 参数,但是这个参数在 0-40000, 这个值越大意味着精度越高,同时意味着损失更多的内存,是以内存空间换精度。
- 在小数据量下,ES 的这个"估算"精度是非常高的,几乎可以说是等于实际数量。
ES 中 cardinality 参数验证
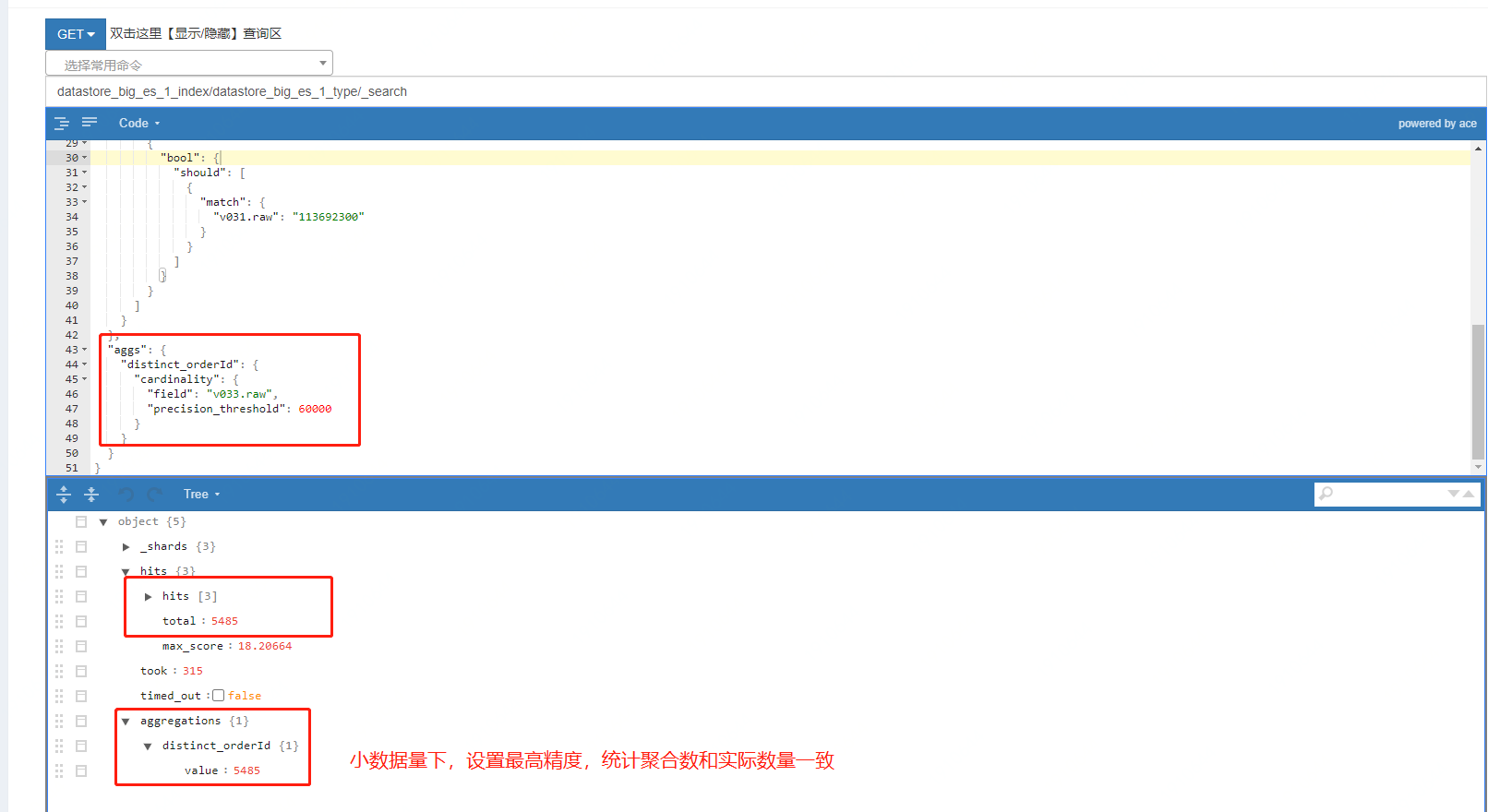
下面对 ES 的 cardinality 的precision_threshold参数进行验证:
1、大数据量下,设置最高精度及其以上,仍然会存在误差:

2、小数据量下,设置最高精度,可以和实际数量保持一致:
那么线上的为什么聚合统计的是 21514,条件查询的是 21427?
线上代码运行和ES集群设置都没有主动设置过 precision_threshold 参数,那么可以知道,这个应该是 ES 集群设置的默认值。线上 ES 集群版本为 5.4x 因此找到 5.4 版本的官方文档,发现 5.4 版本中设置的是默认值 precision_threshold=3000, 在此条件下查询的统计聚合出来的值是 21514。
另外 ES 官方对 cardinality 操作中的precision_threshold参数也做了研究,研究了官方文档中precision_threshold设置和cardinality查询失败率、查询数据量级的关系,可作为我们在业务开发中进行参考,如下图所示:
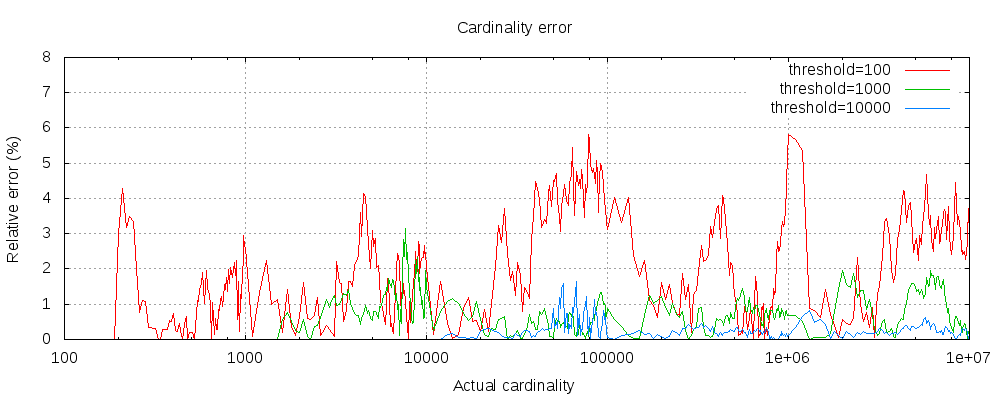
Elasticsearch 5.4版本官方文档对cardinality中precision_threshold参数的研究文档:precision_threshold
总结与方案
通过对 cardinality 的原理探究, 需要明白的是 : 我们使用 cardinality 是需要区分使用场景的。
- 对于精确统计的业务场景,是不建议使用的。例如:订单数的统计(统计结果会引起歧义)的场景下,不建议使用。
- **对于非精确统计的业务场景,那么可以说是很有用了,尤其是在大数据量的场景下,在保持一定的准确性下,同时能提供高性能。**例如:监控指标数据,大盘比例计算等场景,在非精确统计下,是有很大用处。
基于小编的这个业务场景,对商户订单进行统计,是属于精确统计场景,那 cardinality 操作就不适合了。又因为业务的 orderId 是不会重复的,理论上在我们 ES 集群中每个记录的 orderId 都是唯一的,因此可以不用进行去重,而可以直接使用 ES 的 count 操作,将订单数统计汇总出,对应 Elasticsearch 开发包中 COUNT API 如下:
org.springframework.data.elasticsearch.core.ElasticsearchTemplate
#count(org.springframework.data.elasticsearch.core.query.SearchQuery, java.lang.Class<T>)
public <T> long count(SearchQuery searchQuery, Class<T> clazz) {
QueryBuilder elasticsearchQuery = searchQuery.getQuery();
QueryBuilder elasticsearchFilter = searchQuery.getFilter();
return elasticsearchFilter == null ? this.doCount(this.prepareCount(searchQuery, clazz), elasticsearchQuery) : this.doCount(this.prepareSearch(searchQuery, clazz), elasticsearchQuery, elasticsearchFilter);
}
最后欢迎大家点赞、收藏、评论,转发!❤️❤️❤️
|








- 上一条: 【问题排查篇】一次业务问题对 ES 的 cardinality 原理探究 | 京东云技术团队 2023-05-06
- 下一条: 没有了
- 解密Elasticsearch:深入探究这款搜索和分析引擎 | 京东云技术团队 2023-05-05
- 一次“不负责任”的 K8s 网络故障排查经验分享 2021-06-27
- 深入了解 Commonjs 和 Es Module 2021-08-09
- 线上FullGC问题排查实践——手把手教你排查线上问题 | 京东云技术团队 2023-05-06
- 京东云开发者|mysql基于binlake同步ES积压解决方案 2022-11-08