数据开发提效有秘诀!离线开发BatchWorks 六大典型场景拆解
回顾大数据的发展历程,一句话概括就是海量数据的高效处理。在当今快节奏、不断变化的市场环境下,优秀的开发效率已经成为企业数字化转型的必备条件。
数栈离线开发BatchWorks 是一款专注离线数据ELT开发的产品,采用先进的大数据生态底层技术,具备高性能且功能丰富的大数据处理能力,对大数据离线计算、数据仓库建设提供有效支撑,是企业建设数据中台、数据仓库,加速数字化转型的基础设施。
BatchWorks 经过6年多的打磨已经服务于包括金融、教育、政企、零售等多个行业在内的300+客户,在开发效率提升方面发挥了巨大的价值。本文将从多个项目实施过程中遇到的6个典型场景来介绍一下离线开发BatchWorks 在开发效率提升上的一些解决方案,与大家共同探讨。
场景一:大批量数据快速迁移
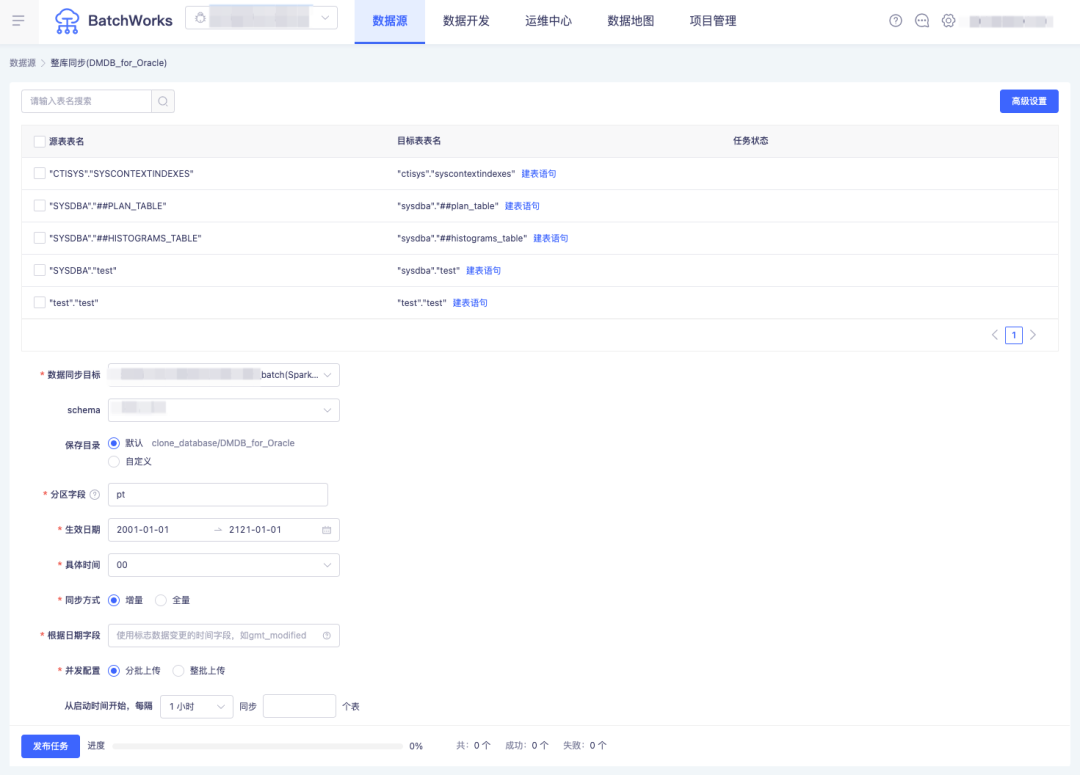
问:客户数仓计划从 Oracle 迁移到 Hadoop,初始化需要完成几万张表的数据同步,如何快速进行大批量 hive 表的创建并做数据抽取?
答:BatchWorks 支持连接数据源进行关系型数据库到包括 Hive 在内的多目标数据库之间的整库同步,可一次性完成大批量表的自动创建和同步任务的生成,支持按日期增量和全量两种数据同步方式。考虑到同一时间点启动大量数据同步任务会造成数据库压力过大,还可支持任务并发数的配置。
场景二:SQL 逻辑的复用和批量管理
问:一条业务线上有20+产品,每个产品的数据分析由一个 SQL 任务完成,所有产品的任务逻辑完全一致且需要保持变更同步,而实际业务在快速变化,数据开发每次调整业务逻辑都需要每个 SQL 任务分别手动变更,经常出现调整错漏的情况,如何解决?
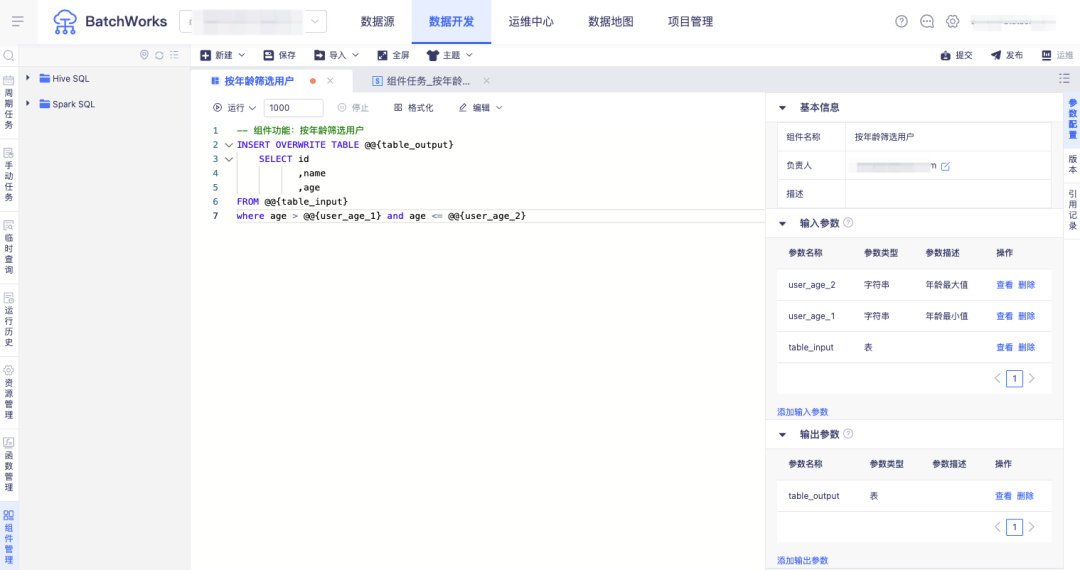
答:增加“组件”功能,用户可把在大量任务中通用的业务 SQL 逻辑抽象出来作为组件进行维护,不同的产品只需引用组件并配置输入输出表和字符参数,即可快速完成任务配置。当业务变更时只要调整组件的逻辑就能实现所有引用此组件任务的同步变更。
一个简单例子:业务方需要对不同产品的用户群体做年龄分层,可创建组件做年龄筛选,配置以下输入输出参数:
• 输入参数:数据来源表
• 输出参数:年龄层中的最大最小值(字符串)、数据输出表
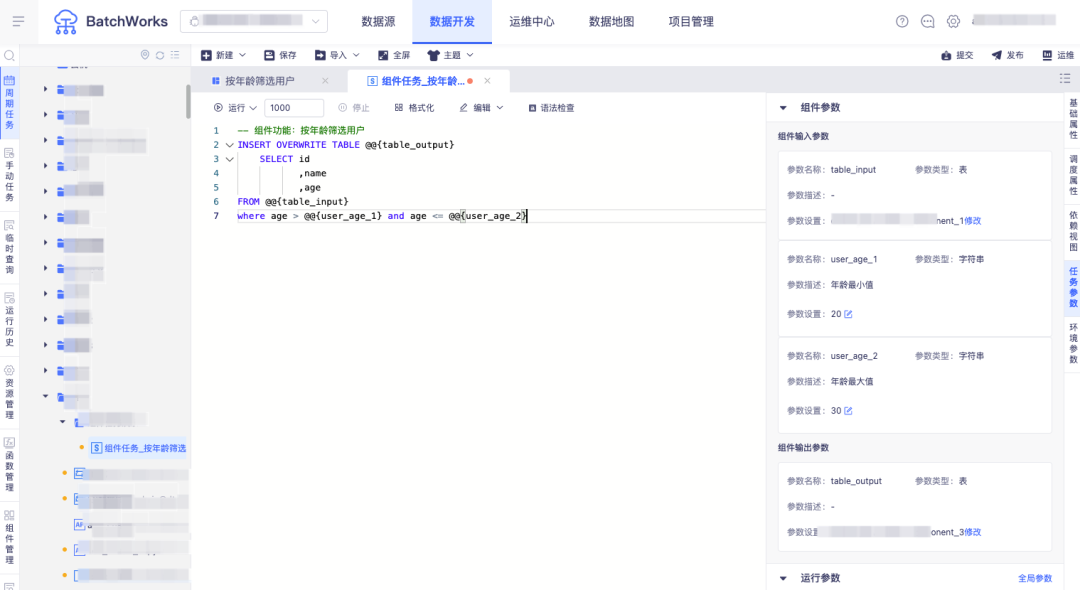
 实现从产品1中筛选出年龄为20-30的用户数据,在创建任务时选择上述组件配置年龄输入参数和数据来源表,并指定写入的结果表:
实现从产品1中筛选出年龄为20-30的用户数据,在创建任务时选择上述组件配置年龄输入参数和数据来源表,并指定写入的结果表:
场景三:计算结果跨任务复用
问:任务存在上下游依赖时,下游任务可能需要直接使用上游部分任务的计算结果,同时用户不希望建太多临时表,或产生一些额外的重复计算,如何解决?
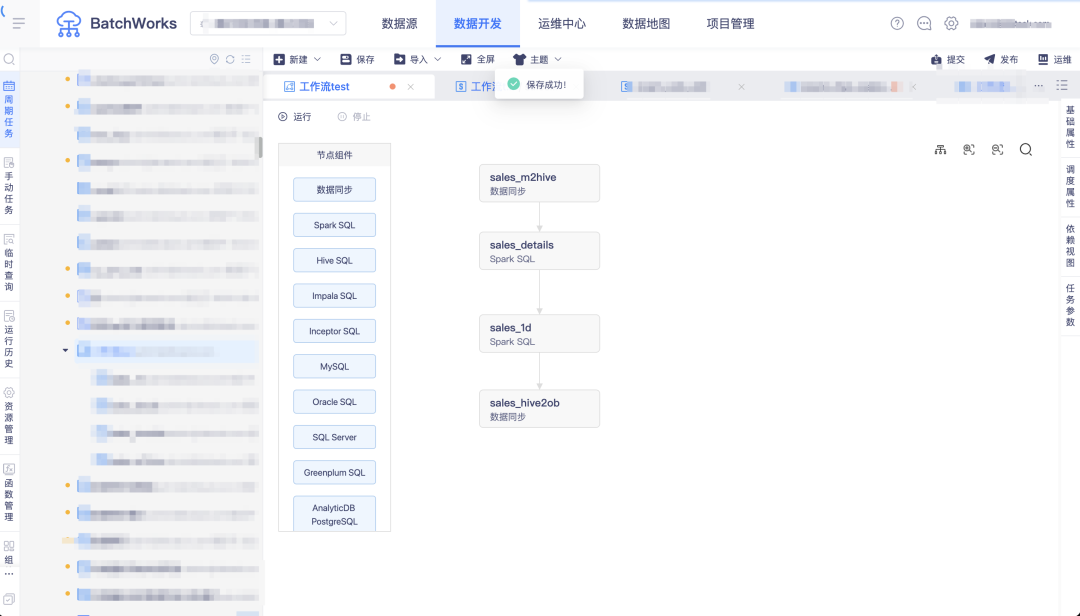
答:BatchWorks 支持了任务上下游参数传递功能,上游任务的计算结果可进行周期性存储,直接被下游计算引用。
一个简单例子:从业务库完成销售明细表数据采集清洗,按天汇总后将销售金额最高的门店数据输出 sales_1d 任务,从 sales_details 中通过输入参数获取日期数据,然后将当天最高销售数据对应的门店通过输出参数输出传递至下游的同步任务,同步任务筛选此门店数据同步至 oceanbase。
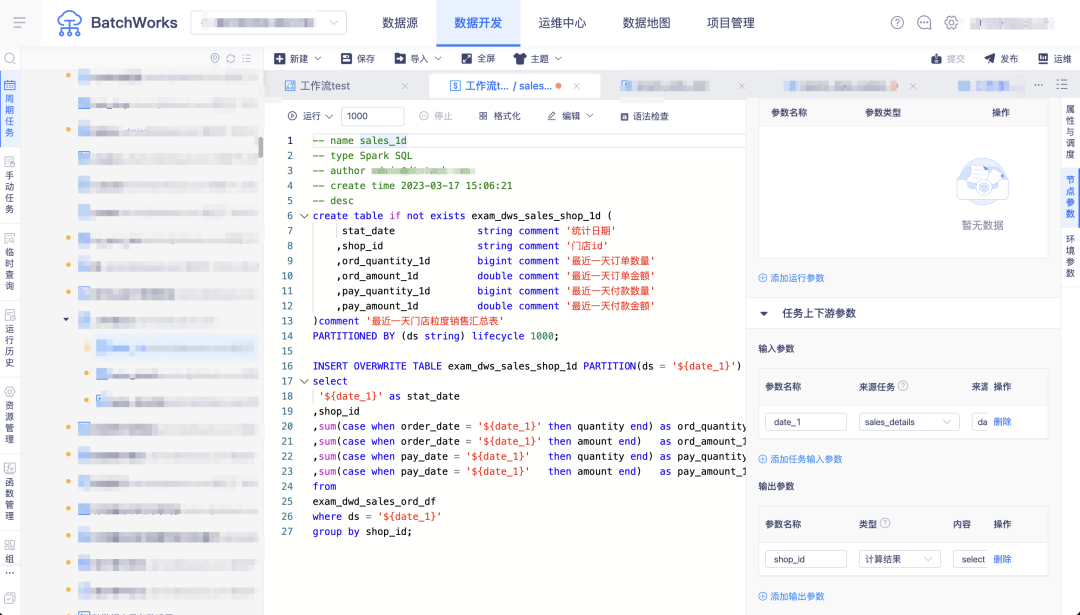
场景四:任务依赖自动解析
问:当任务较多且依赖关系复杂时,依赖关系的配置会占用一定的工作量,尤其在对任务做了修改后,依赖关系可能会有更新不及时/漏更新的情况,发现问题时往往已经到了下游环节,如何解决?
答:BatchWorks 支持了上游任务依赖自动解析推荐/自动依赖功能,选择此功能进行依赖任务配置时,平台将对当前任务进行 SQL 解析,得到来源表和结果表,并寻找来源表的产出任务,用户可从这些推荐任务里选择全部或部分任务添加到上游依赖,也可直接选择自动依赖,当 SQL 调整时自动进行上游依赖的更新。
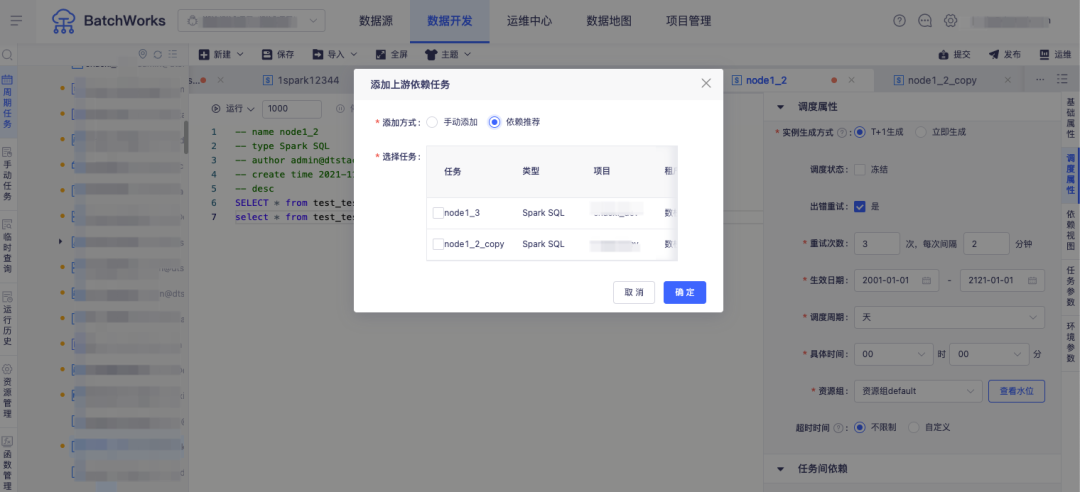
场景五:任务异常快速排查
问:离线实例的运行流程涉及实例上游依赖检查、到达计划时间检查、资源检查、质量校验等多个环节,运行过程出现异常时仅通过日志难以直观地进行问题溯源,问题处理不及时直接影响下游业务,如何解决?
答:BatchWorks 支持实例诊断功能对实例的运行过程进行分析,将实例调度流程及每个流程当前的状态、节点时间全部展示,用户可直观地看到当前实例的运行阶段和异常原因。
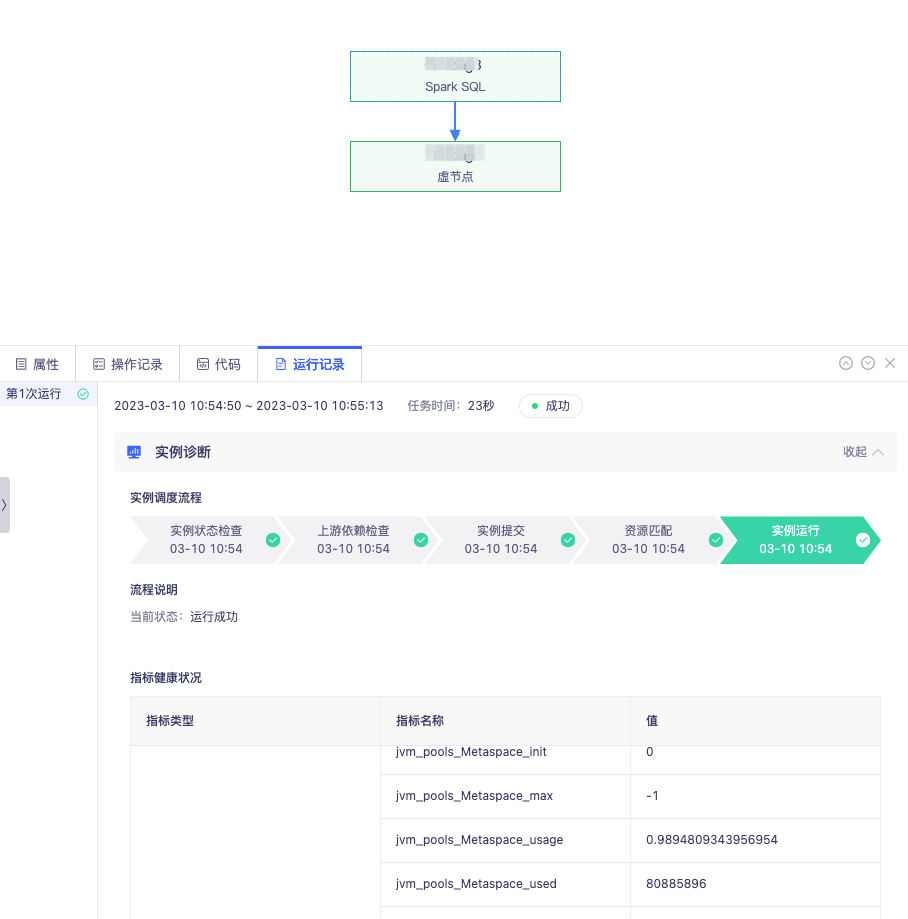
比如在进行上游依赖异常检查时,BatchWorks 将构建以当前实例为末位节点的异常依赖树,寻找直接导致其未运行的根源任务组,快速直达阻塞点。此外针对 SparkSQL,可监控其指标健康状况并给出调参建议,针对 HiveSQL 可观测运行过程中资源使用变化情况,从而可进一步进行任务调优。

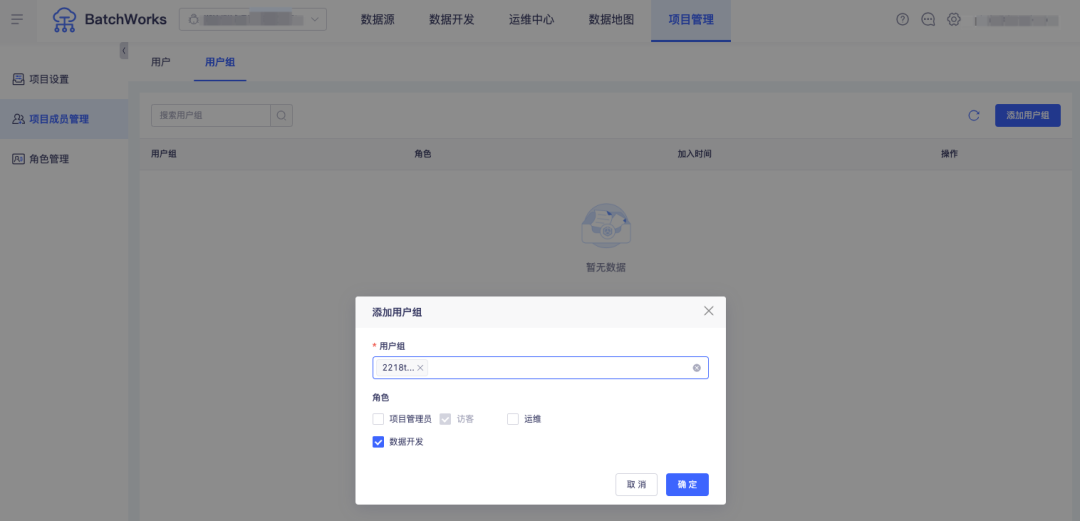
场景六:以用户组为单位的用户管理
问:某公司的数据开发团队不定期会有一些人员调整,因业务量大、开发项目比较多,人员调整后开发平台上的维护十分繁琐。例如有新员工入职,需要将其添加到相关的多个开发项目中并赋予不同的角色,任务告警值班时需要添加进对应的告警规则中等等,增加管理员的用户管理成本且容易缺漏,如何解决?
答:BatchWorks 的用户中心支持以用户组为单位的用户管理,每个用户可被添加进一个或多个用户组。项目添加用户、告警圈选用户时均可以用户组的方式进行配置。后续增删用户时仅需在用户中心的用户组内进行操作,即可完成人员->项目/角色等的快速调整。
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
|








- 上一条: 数据开发提效有秘诀!离线开发BatchWorks 六大典型场景拆解 2023-04-13
- 下一条: 没有了
- 数据可视化系列教程|六大组件基础知识 2022-09-02
- 实践 DevOps 时,可能面临的六大挑战 2022-06-21
- vivo 游戏中心低代码平台的提效秘诀 2022-12-26
- 流批一体!实时数据处理场景化典型应用实例(干货)~ 2022-06-14
- 前后端数据接口协作提效实践 2022-08-30


