架构师日记-如何写的一手好代码
作者:京东零售 刘慧卿
一 前言
在日常工作中,我经常听到部分同学抱怨代码质量问题,潜台词是:“除了自己的代码,其他人写的都是垃圾,得送到绞刑架上,重构!”。今天就来聊一聊,如何写的一手好代码。要回答这个问题之前,得先弄清楚一个问题,好代码的标准是什么?易阅读,可扩展,高内聚,低耦合,编程范式,设计原则......,要求不少,却很难度量。实则代码和文章一样,正所谓文无第一,武无第二。
这里不打算从规则宝典,最佳实践等方面入手,因为那将陷入到无数的规则细节中去,容易不得要领。这也是很多同学,学了很多当下最新技术,掌握了N门编程语言,却始终没有明显提升的原因。对于技术而言,底层的原理和运行规律是根本,它和编程语言,语法等应用层的重要程度是不一样的,切记不要进入这个误区。
技能的掌握一般需要经历学习、模仿、思考、创新四个过程,下面就分几个阶段来探讨一下,到底该如何快速学习成长。
二 学习出来的代码
学习意识
如果说人生有什么捷径,寻找前人走出来的路,就算是捷径了吧。前人需要花了几年,甚至穷其一生研究的成果,摆在那里,用还是不用?答案应该是肯定的,接下来要做的,只是如何把它们找出来,结合当下的情形,在众多的解决方案中选出行之有效的就可以了。 Henry Spencer曾说:“不懂 Unix 的人注定最终还要重复发明一个撇脚的 Unix”。
所以有必要建立这种意识:有效的学习是降低目标成本的最佳策略之一。这比自己摸着石头过河,在时间成本上,会有很大的节省,这还没考虑物质和精力上的投入,各种试错,就更划算了。
选择榜样
既然是取经学习,就要学习优秀的,成功的经验,如此,相同的精力投入,获得的回报往往更高。半路出家,或者正在和你同行的都不是好的选择,你不知道他们最终会不会误入歧途。所以选择榜样时,一定要跳出圈子,去找你能找到的最优质的的那些,你的选择可以涵盖历史上,行业里,公司中各个维度。
学习的过程中,带着批判的思维去消化,只有这样才能改进创新,所有的金科玉律都有其限定范围,当限定边界打破了,之前的正确性,就值得你去怀疑。举个例子,很多编码规范里都有那么一条:“一行代码长度,不超过80个字符”。
它的来历是这样的:在很久很久以前,有一个很流行的人机交互接口(终端) 叫 VT100,用来处理字符/文本,后来其它的很多终端都是以它为标准。这个终端屏幕24行、80列,编辑器菜单还占了 4 行。所以,代码编写建议是一个逻辑的处理代码,20行最佳、每行字符长度不超过80列。目的就是为了可视性(目之所能及)、可维护性。而如今显示终端的分辨率普遍提高了,所以升级调整规范并无不可,比如:“每行 120 个字符,每个函数体代码 80 行以内”。
所以,很多历史经验,了解其背后的运行逻辑,才能发挥出它原本的作用。
学以致用
大家常说万事开头难,究竟难在哪里?难在决心上,难在门槛上。决心可以通过痛点和目标来牵引,门槛可以通过目标拆解来降低。高质量的完成某件事情,有很多科学的工具和方法,比如:PDCA循环,SMART原则等,有兴趣的,可以拓展学习。
这里想要表达的是,拥有痛点和目标是能够持之以恒的前提,因为在学习实践的过程中,能够练习中进行应用,并能获得真实反馈和回报,这是能够坚持精进的原动力。否则就容易陷入,类似我们背诵四级应用单词‘’“abandon”的魔咒,也不知道从它开始背诵了多少遍了。
再举个例子,我们需要做系统模块解耦,调研下来,使用消息队列MQ中间件,能够很好的解决我们目前面临的问题。
如果没有真实的应用场景,往往会始终停留在第一步,反复开始,直到失去耐心,最终放弃。
小结
想要写好代码,需要有学习的意识,至少能够知道什么样的代码是好的,什么样的代码是有改进空间的。这种判断能力,需要通过不断的阅读各种类型的代码,从中找出榜样。资料的来源可以是经典书籍,好的开源项目,甚至是你身边的优秀项目。同时也需要规避一些误区:
三 模仿出来的代码
认知陷阱
所谓代码模仿,不是简单的照猫画虎。而是遇到问题了,可以基于之前的学习积累,能够快速的找到优秀的解决方案,并加以利用。可以是一个技术点,可以是一种模式策略,可以是一种解决方案,甚至是一种编程思想。
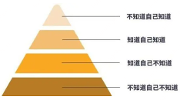
这个阶段通常处于认知模型的第二层:“知道自己不知道”。也是突破认知极限,快速成长的阶段。直观感受就是一个问题接一个问题,一个概念接一个概念,要理解和学习的知识太多了。这对个人的毅力和耐心是一个考验,很多人就是在这个阶段进入认知陷阱,最终转行了。
以终为始
在实践过程中,会面临着要学的知识,要补的课,太多了:“计算机网络,应用服务,数据存储......”。计算机网络又包含运营商,光纤,电缆,域名,cdn,交换机,代理服务,http协议,客户端,浏览器,会话...,每一个节点又可以往下拆下去,感觉没有尽头。
是需要全部弄懂再去动手吗?我到底是要做一个专才,还是成为一个全才?这个问题还要以发展的眼光来看。下面就以市场人才发展观为例,展开探讨一下。
现实中往往是“T型人才”比较受用,"一"表示有广博的知识面,"|"表示知识的深度。两者的结合,就是传说中的一专多能。特别是大公司,员工岗位分工比较细,像螺丝钉一样,只要做好眼前的事情就好了。如果专之外加上多能,在横向上具备比较广泛的一般性知识修养,而且在纵向的专业知识上具有较深的理解能力和独到见解,就有了较强的创新能力。
我们知道,由于行业的快速迭代,叠加各种不确定性,有些岗位的合理性受到不同程度的挑战,失去竞争力,遭遇下岗的境遇。业内又喊出了“π型人才”的概念。
π型人才是源于新加坡的一种人才观,在T型人才的基础上,进一步进化。π比T多出来的一竖,一般是源于兴趣爱好或工作所需,孵化出来的第二事业线。“两条腿走路”,势必有更强的抗风险能力,和更强的市场变化应对能力。
梳子型人才更加形象了,多条腿走路,即在多个专业有深入的专业知识,同时在顶层保持一个终身学习的习惯。它代表着强大的底层思维和逻辑能力,它决定了你是否具有知识迁移能力,一定要先夯实它,否则很容易变成三天打鱼两天晒网。
人的精力和能力是有限的,机会也不是人人都能碰上的,所以梳子型人才往往不是我们的第一目标。我们可以先从T型人才开始努力,时机成熟之后再往π型,甚至梳子型人才上迈进。
以终为始,才能看得清脚下的路。对于技术的学习和应用也是如此,当前需要什么,就学习什么,深挖什么。有余力了,机会来了,就可以主动转身,再创辉煌。
小结
学习实践阶段处于比较吃力的爬坡过程。考验的是对实现目标的毅力和决心,认识到这一点至关重要。技术的研究方向,深入程度,还是建议循序渐进,结合实际应用场景,先在当前领域扎深扎透,再伺机发展,多条腿并行。
四 设计出来的代码
编程思维
所谓编程思维,就是“理解问题,找出路径”的思维过程,它由分解、模式识别、抽象、算法四个步骤组成。
编程思维并不是编写程序的技巧,而是一种高效解决问题的思维方式。
编码原则
计算机是人造的学科,编码原则就三个字:好维护。如果考虑目标诉求,可能还可以追加一条:“运行快”,但目前大部分应用场景,计算机性能已经足够快了,很多时候,第二条往往被忽略掉了。
开闭原则,KISS 原则,组合原则,依赖反转,单一职责原则等大部分设计原则都是围绕着这个基本原则展开的。如果你觉得你的编码设计比较别扭,老得腾出精力来调整维护,那么大概率这个设计是不合理的,你得想办法让自己从中解放出来。
实际编码过程中的各种规范约束,比如:代码规范,设计模式,日志打印规范,异常处理策略,接口设计规范,圈复杂度等,参照基本编码原则去理解,就能想的通了。
抽丝剥茧
所有的技巧都是建立在熟悉的基础上,对于程序员来说,就是代码。阅读海量的代码,编写海量的代码,在这个过程中,不断的改进调优,是练就硬功夫的前提。下面就以案例的形式,为大家展现一下该如何阅读源码,借此提升自己的设计能力。
案例是取自RocketMQ开源项目,你能想象下面这段代码为什么这么写吗?
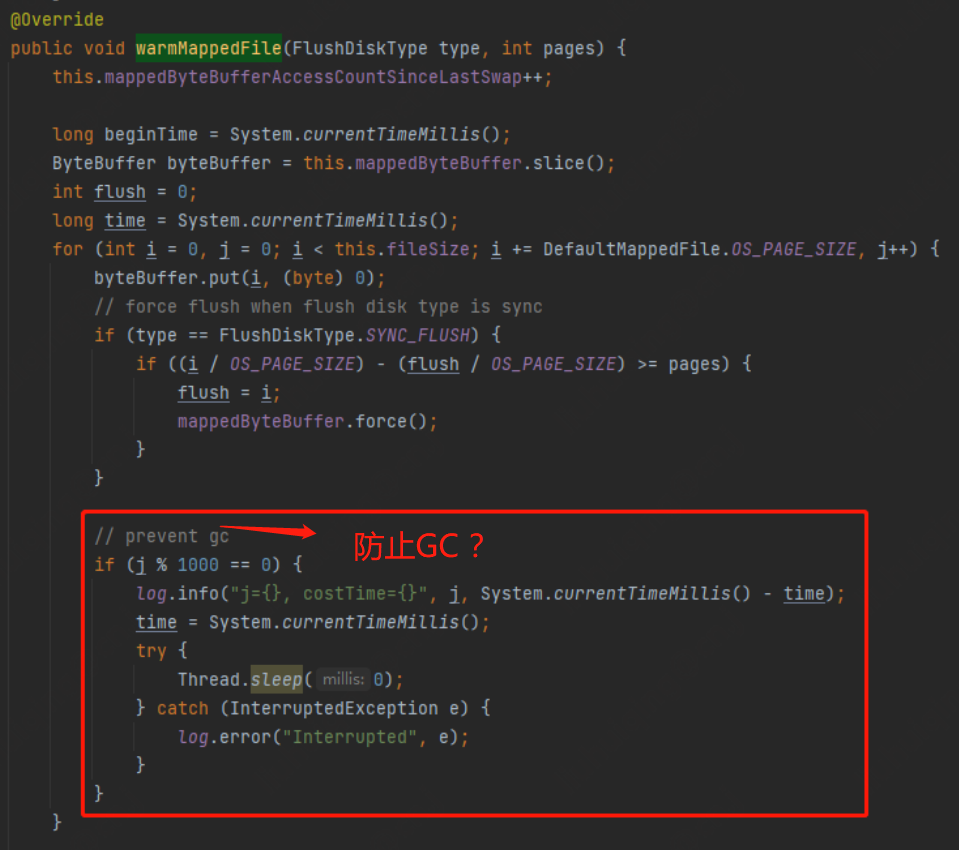
代码出处:org.apache.rocketmq.store.logfile.DefaultMappedFile#warmMappedFileRocketMQ 使用文件预热优化后,在进行内存映射后,会预先写入数据到文件中,并且将文件内容加载到 page cache,当消息写入或者读取的时候,可以直接命中 page cache,避免多次缺页中断。这个方法的作用就是文件预热。
1)先探讨第一个问题,关于缺页中断的原理,属于计算机组成原理的范畴,这里不展开详细介绍,大概流程可以参照下面这张图:
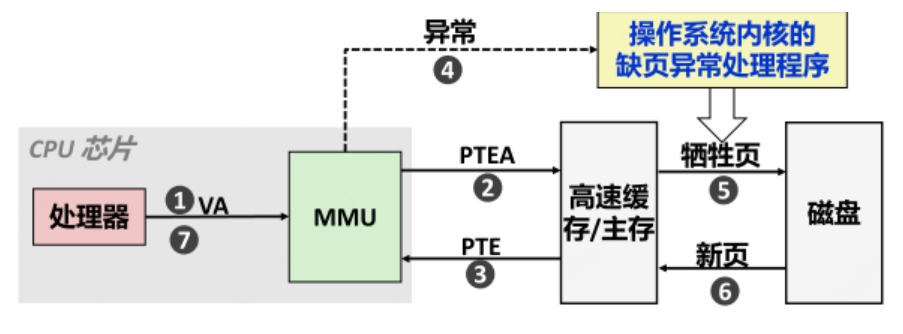
简单解释一下这个流程:
如果不加载任何MappedFile数据至内存中的话,按照最坏的影响,1GB的CommitLog需要发生26w多次缺页中断。所以通过代码设计,减少缺页的情况出现,会大大提升应用响应效率。 2)我们再来看第二个问题,为什么循环次数是4K,为什么往ByteBuffer中写0?
传统HDD扇区单位一直习惯于512Byte,有些文件系统默认保留前63个扇区,也就是前512 * 63 / 1024 = 31.5KB,假设闪存Page和簇(OS读写基本单位)都大小为4KB,那么一个Page对应着8个扇区,用户数据将于第8个Page的第3.5KB位置开始写入,导致之后的每一个簇都会跨两个Page,读写处于超界处,这对于闪存会造成更多的读损及读写开销。
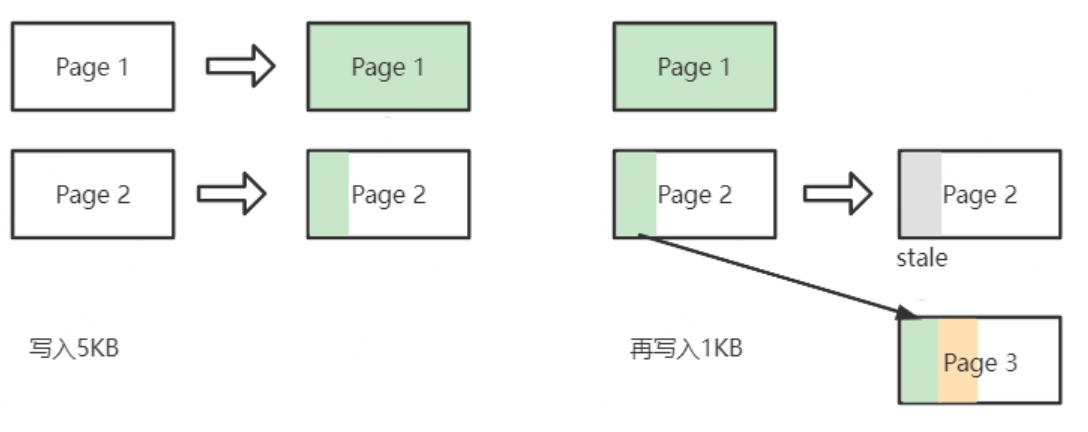
除了OS层的4K对齐至关重要以外,在文件写入过程中仍然需要关注4K对齐的问题。假设Page大小仍然为4KB,向一个空白文件写入5KB数据,此时需要2个Page来存储数据,Page 1写满了4KB,而Page2只写入1KB,当再次向文件顺序写入数据时,需要将Page2数据预先读出来,然后与新写入数据在内存中合并后再写入新的Page 3中,之前的Page 2则标记为 stale 等待被GC。这种带来的开销被称为写入放大WA(Write Amplification)。为了防止写入放大的情形出现,我们会提前将Page空间,用0填充写满。
3)最后,我们再来看第三个问题,为什么Thread.sleep代码块,注释上写着:prevent gc?
这段程序表达的意思很容易理解,每执行1000次循环,执行一次Thread.sleep(0)语句。但背后的目的确没那么明显。即Thread.sleep(0)可以让线程进入 Safepoint,从而触发GC。
这就得了解一下安全点(Safepoint),用户程序执行时,并非在代码指令流的任意位置都能够停顿下来,开始垃圾收集,而是强制要求必须执行到达安全点后才能够暂停。意思就是在可数循环(Counted Loop)的情况下,HotSpot 虚拟机有一个优化,就是等循环结束之后,线程才会进入安全点。代码中int类型就属于可数循环,当然Long类型属于不可数循环。
总结一下,这段代码的目的就是,在预热数据的时候,每写入1000个字节,让该线程立即从运行阶段进入就绪队列,释放CPU时间,可以让操作系统切换其他线程来执行,比如GC线程的执行。这也侧面的反映出系统设计者对数据响应效率的追求,通过人工介入GC频率,防止出现超长时间GC情况的出现,影响瞬时的吞吐效率。
小结
程序编写,按照不同的维度视角,有很各种各样的原则和建议。其本质还是以下两个方面:
清楚的认识到程序本质,是能够进行创新的基础。
最后,通过一个实际案例,简单的展现了一下如何阅读代码,以及如何从别人的代码中学习程序设计,其核心还是要有刨根问底的好奇心,拥有举一反三的思考与沉淀。
五 重构出来的代码
认识重构
重构(Refactoring)就是通过调整程序代码改善软件的质量、性能,使其程序的设计模式和架构更趋合理,提高软件的扩展性和维护性。更广义的理解,就是打破原有的组织形式,按照新的标准进行重新组合。
从理论和实际经验来讲,系统或代码的重构往往是个人能力实现快速提升的良好契机。相同条件下,有重构经验的同学和没有重构经验的同学,对很多概念和规则的理解深度会有很大区别。这就是典型的习得性经验,通过教学很难掌握。生活场景中的游泳,骑自行车就是习得性经验的代表。
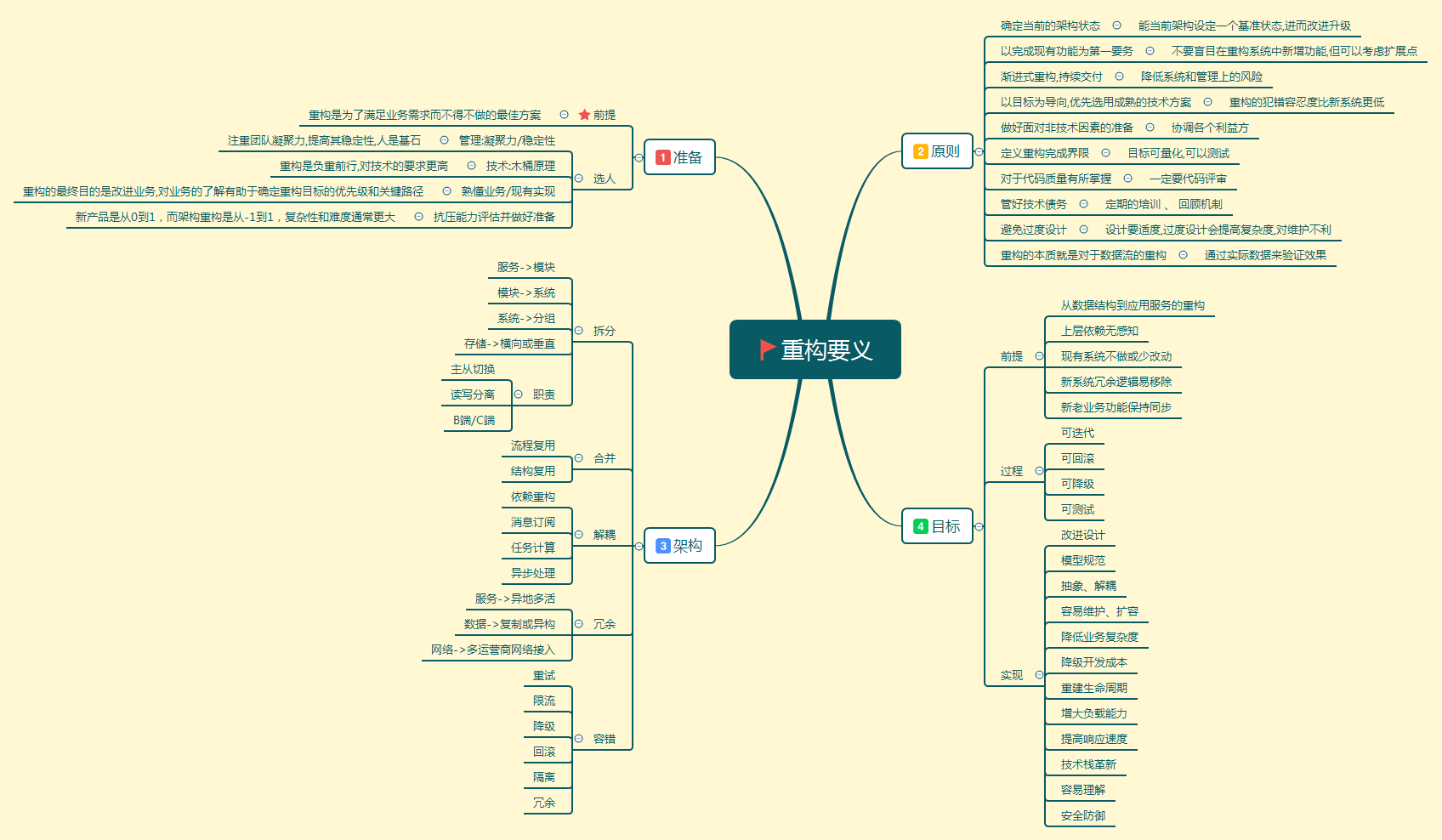
关于重构相关的要点,以思维导图的方式呈现,如下图:
独当一面
现实情况中,整个团队梯队建设一般是金字塔型的,即高中低职级的同学一起对项目负责。不同职级的同学,对技术的要求和标准也不一样,要都按照高标准来执行,对低职级的同学显然是不公平的,反之也是一样。所以如何解决这个矛盾,是我们不得不面对的问题。
抓大放小,就是要按照业务区分核心和非核心,流程区分上游和下游,系统区分0级和n级......,重要的尽量按照高标准来执行,一般的按照普通标准来执行,并投入与之相匹配的资源。举个例子,比如,B端的某些运营工具,我们对它的QPS,可用率要求和C端用户的是不一样的,影响决策的依据是边际成本和收益。
所谓“甲之蜜糖,乙之毒药”。对于某款产品,稳定性,高吞吐就是其立身之本,直接影响着市场份额和收益,那么投入精力去做性能优化就是划算的。如果你的产品是一个提效工具,对代码的性能和扩展性,往往就没有那么高的要求,过于苛求反而没有必要。
小结
重构虽然对个人和业务都是有莫大好处,但考虑到实际成本问题,很多重构都是没有必要的。总结一下重构的要点:
“知道自己知道”,就会对技术会有一些自己的思考和创新,不容易的人云亦云,能够基于现状和目标,做出决策,即所谓的独当一面。
六 总结
本文主要从如何快速学习掌握编码技能展开,强调了认知对学习的重要性,提出了选择方向,树立榜样,学以致用等学习路径。同时针对成长过程中遇到的困惑和职业发展方向,做了阐述,借事成长,择时出发,避免进入一些认知误区。以代码阅读案例,直观的展现了如何在代码阅读中学习和思考。最后,介绍了重构的意义和部分原则。总体上,是按照学习成长路线来进行阐述的,希望能够减少我们路上,那些成长的烦恼!
注:本文部分图片和案例来自网上
|








- 上一条: JSF预热功能在企业前台研发部的实践与探索 2023-04-06
- 下一条: ChatGPT 时代工程师何去何从 :Google 专家也焦虑 2023-04-06
- 如何成为一名架构师? 2021-08-10
- 架构师日记-为什么数据一致性那么难 2023-04-04
- 架构师日记-软件高可用实践那些事儿 2023-03-13
- 【高手问答汇总】 vivo 系统架构师解答 vivo 如何打造千万级 DAU 活动中台 2022-02-25
- StoneDB 首席架构师李浩:如何选择一款 HTAP 产品? 2022-12-06