字节跳动 Flink 大规模云原生化实践
本文整理自字节跳动基础架构工程师刘畅,在 Flink Forward Asia 生产实践专场的分享。字节跳动拥有业界领先的 Flink 流式计算任务规模。随着云原生时代的到来,我们开始探索将线上的 Flink 任务从 Hadoop 迁移到 Kubernetes,使得作业云原生化运行。本篇主要从字节跳动 Flink 大规模云原生化实践背景、解决方案、生产实践、未来展望四个方向展开介绍。
一、背景介绍
资源管理演进

字节跳动的大数据资源管理架构,以及 Flink 的部署演进,大致可以分为三个阶段。
第一阶段,完全基于 YARN 的离线资源管理。大规模使用 YARN 管理的大数据集群,有效提升了 Flink 的资源使用率,并降低了资源运营、运维等方面的成本。于此同时,针对 Flink 的特性,对 YARN 做了大量定制研发,如支持 Gang 调度等。在此阶段,Flink集群已经达到了相当大的规模。
第二阶段,离线资源混部阶段。通过构建 YARN 和 K8s 混合部署集群,进一步提升在线和离线的整体资源使用率。并通过混部技术方案,使集群/单机资源利用率都得到显著提升。更高的单机利用率,意味着需要更完整的隔离手段,因此逐步开始推进 Flink 的容器化部署并获得了相应成效。
第三阶段,彻底的云原生化部署。在线负载和离线负载不再使用不同的架构进行管理,真正实现了技术栈统一和资源池统一,Flink 的云原生化也在逐步构建完善。
云原生的优势

云原生化几乎是业界一致的发展趋势,那么为什么要选择云原生 K8s 作为统一的资源管理底座呢?
- 高效运维。K8s 提供敏捷的负载创建和管理,无论是在线负载还是 Flink 大数据负载,都能够便捷实现持续开发、集成和部署。
- 资源共池。统一的云原生底座减少了基础设施开销,也进一步提升了资源流转效率。在春节、双11等大型活动场景下,在离线资源可以高效、灵活地相互转换;在资源利用率方面,整个数据中心的利用率可以得到更全面、充分的提升,降本增效。
- 生态繁荣。K8s 拥有几乎最活跃的生态圈,它通过提供标准化的接口定义,促进了各个层次的生态发展,无论是基础运维设施、上层应用管理还是底层的网络、存储等管理中都有非常多的可选方案,Flink 的云原生化也为未来的方案使用提供了便利。
Flink 业务规模

字节跳动拥有业界领先的 Flink 业务规模,目前 Flink 每天运行的作业数有数百万个,占有资源量数百万核,总的集群规模节点也达到了上万台,如此大规模的 Flink 负载意味着彻底的 Flink 云原生化并不是一件轻松的事情,关于关键问题的思考请浏览下面的内容。
关键问题

Flink 的大规模云原生化有几个关键问题需要思考。
- Flink 作业的部署管理,是 Standalone 的静态部署还是 K8s Native 动态部署,是否使用 Operator ?
- 在 K8s 上如何实现 Flink 作业的租户级别资源管控,在作业提交时进行管控,还是在 Pod 创建时进行管控?
- 如何支持 Flink 的调度需求?在 Flink 作业提交或重启时,大量的 Pod 创建是否引起调度瓶颈?
- 大规模作业的架构迁移,周边能力如何建设,需要另起炉灶,还是尽可能复用?
二、解决方案
部署方案
关键问题:Flink 如何在 K8s 上运行?
第一种,Standalone 部署模式。这种模式下,Flink 作业依赖的所有资源,都由作业提交用户发起创建。其原理和使用比较简单,但存在资源利用效率低,Failover 成本高等问题。
第二种,Kubernetes Native 部署模式。这是目前社区比较推荐的部署模式,Jobmanager 可以根据作业的需求自主创建 Taskmanager Pod,但完全的 Native 部署模式依然存在一些问题:
- 没有完整的生命周期状态描述和管理;
- 批调度对接成本高;
- 缺少全局视角,不容易进行一些全局的调控。
除此之外,Flink 部署也可以搭配使用 Operator,目前 Operator 通常针对负载单独定制,未来进行多种负载混部时,就需要部署多套 Operator,这无疑加大了运维上的成本。
部署方案

为了更方便的管理 Flink 等大数据负载,字节自研了一个统一的大数据 Operator Arcee。如图所示,Arcee 运行在 K8s 底座之上,向上可以同时支持 Flink 的流式和批式作业。Arcee 的核心能力主要包括作业生命周期管理、作业资源管理和一些引擎的定制功能等。

Arcee 的核心设计思路是,两级作业管理。Arcee 借鉴了 YARN 的两级管理模式,即中心管理服务 AM,主要负责创建和维护大数据作业,再由 AM 创建维护计算 Worker。对应到 Flink 作业中就是由 Arcee 创建 JM,JM 创建所需的 TM。这种管理模式,一方面可以有效管理和表达大数据作业状态,定制作业管理策略。另一方面也可以确保计算引擎对计算作业运行有充分的掌握能力,有能力按需调整资源使用。
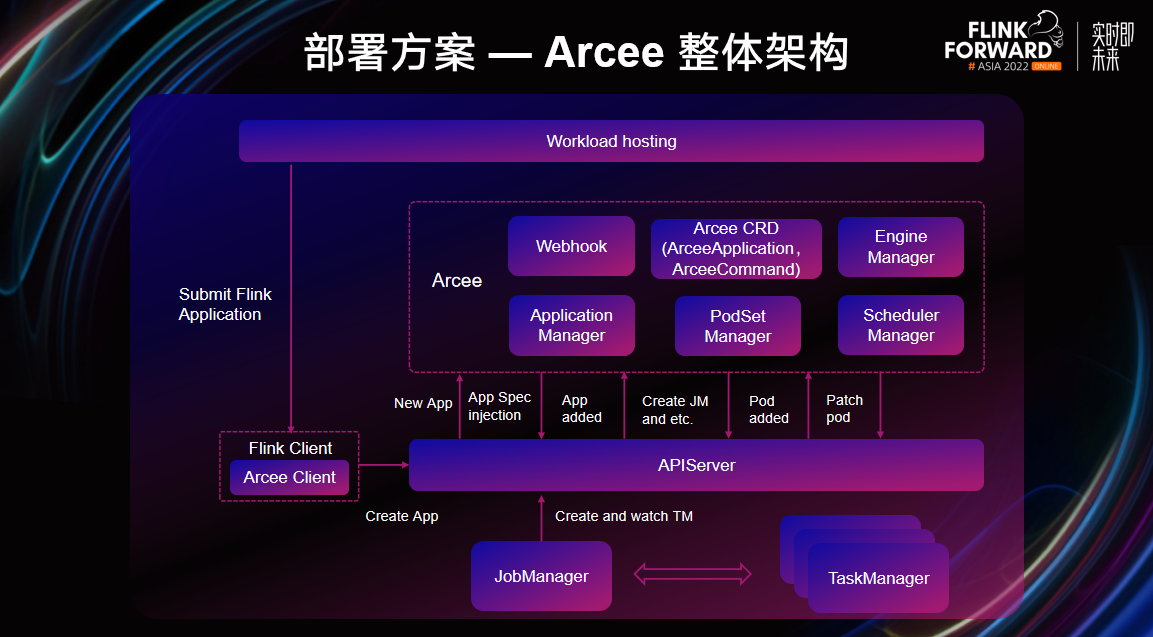
Arcee 整体架构
如图所示,Arcee Operator 内部包含了六个模块:
- Arcee CRD,Arcee 定义了 ArceeApplication 和 ArceeCommand 两种资源类型。ArceeApplication 用于描述具体的作业,ArceeCommand 描述用于作业的操作;
- Webhook 模块,主要用于 Application / Pod 的配置注入和校验;
- Application Manager 负责作业的生命周期管理;
- PodSetManager 是作业资源管理;
- EngineManager 是引擎管理,用于实现一些引擎定制能力;
- Schedulermanager 是调度器对接层,用于完成 Flink 等大数据作业与批调度器的对接。
基于这幅图,作业完整的提交流程是当上层发起 Flink 作业提交时,作业提交平台调用 Flink Client,并填上所需的参数向 K8s 提交作业。在 Arcee 模式下,Flink Client 使用内置的 Arcee Client 创建 Flink Arceeapplication,由 Webhook 预处理后提交到 Apiserver。接下来,由 Arcee Controller 收到 Application 的创建事件,Arcee applicationManager 生成对应的作业状态,并根据 Application 内的描述创建 JM,并由 JM 根据 Job 创建所需的 TM,Arcee 会持续监听所有 TM 的创建,同样也会进行相关配置的注入。Application 内 JM、TM 的所有 Pod 都会维护在 Arcee 的 PodsetManager 中,用于资源使用统计,并向其他模块提供相关信息。

以上可以发现,Flink 使用 Arcee 的部署模式和 K8s Native 部署模式有相似之处。Flink on Arcee 在一定程度上可以认为是 Flink Native 部署模式的改进。具体的区别如下:
- Jobmanager 的创建和生命周期管理,由 JobManager Development 负责完成。JM 启动后,Resource Manager模块可以直接和 K8s API Server 进行通讯,完成 TaskManager Pod 的创建和销毁工作。在这种架构下,对于 K8s 来说,JM 和 TM 几乎是完全独立两部分资源。
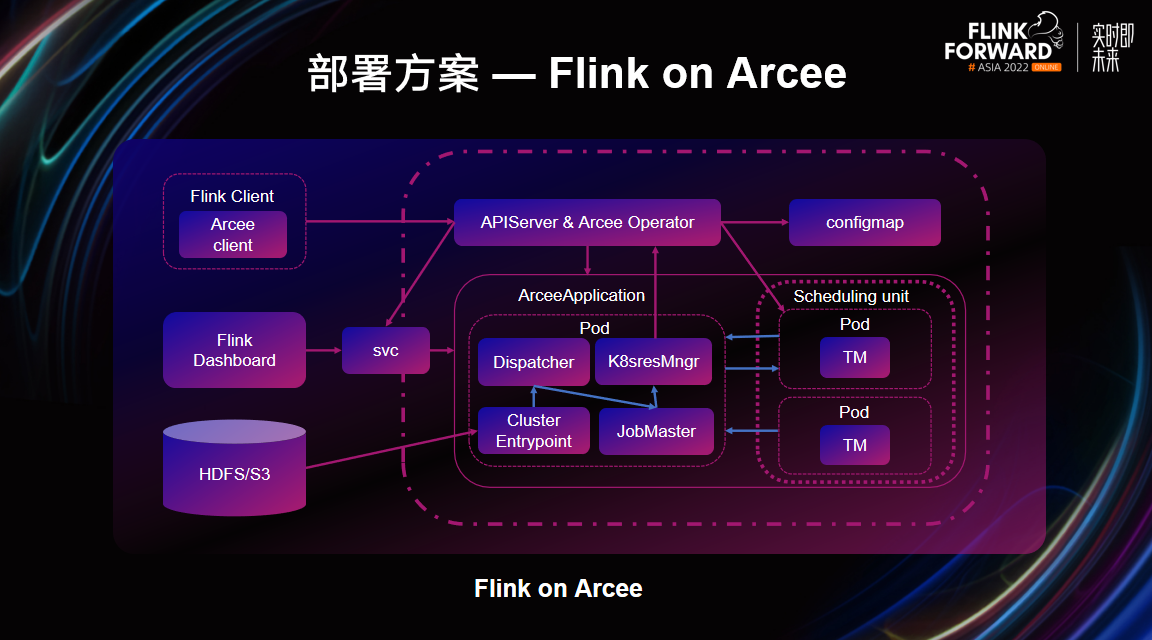
Flink on Arcee 的架构有如下不同:
- Flink Client 中的 K8s Client 替换成 Arcee Client;
- 负责管理 JM 负载的组件由 Controller Manager 变成 Arcee Operator;
- 负责拉起 Jobmanager 的 Deployment 变成了Arcee Application;
- JM 和 TM 从各自独立变成拥有统一的 Application 进行维护。
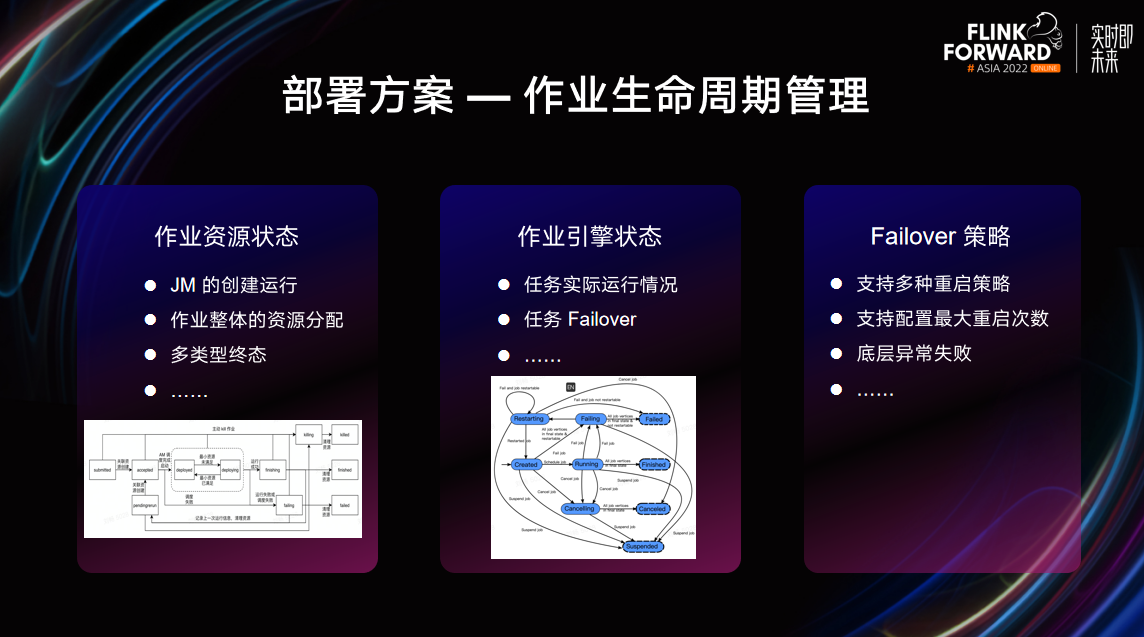
Arcee 提供的具体功能
- 作业生命周期管理:Arcee 提供了一个细粒度的作业状态机叫做作业资源状态。通过作业资源状态,可以知道作业的资源创建处于什么阶段,此外也可以反映作业的运行终态及 Flink 的内部状态。Arcee 也提供了多种 Failover策略,用户可以根据状态定制重启策略,目前可以支持 Never、Always、Onfailure 多种重启策略,支持配置最大重启次数,支持底层异常失败探查。

- 调度屏蔽:对于 Flink 大数据作业来说,往往需要搭配使用批调度器。批调度器与普通的调度器不同的点在于,批调度器使用的时候 需要额外创建批调度单元,并持续观察批调度端元的状态。目前,业界没有给出一个标准的批调度处理模式。Arcee 屏蔽了底层调度细节,计算引擎自身不需要关心调度器的接入方式,Arcee 的作业资源管理模块可以完成调度对接。
资源管理方案
关键问题:如何实现 Flink 作业的租户资源管控?如何实现高性能的批调度?

租户的资源管控最核心的能力是集群资源的公平分配。此外还需要提供租户内的高/低优作业排队与抢占。Flink 的大数据负载和在线负载的不同点在于在线负载中 Pod 的创建几乎完全是用户发起的,创建所需资源量也是创建前明确的。但可动态调整的大数据负载不同,一是 Pod 的创建时间不确定,二是所需资源量不确定。这也就需要提前为用户划分资源并进行管控,防止某个作业占满集群。
除此之外,批调度能力也是 Flink 云原生需要解决的重要问题。首先,Flink 流式作业通常需要 All-or-Nothing 的调度能力,否则可能会出现资源死锁。其次,大量的 Pod 创建要求调度器具备很高的调度吞吐能力。最后,字节跳动内部,Flink 过去在 YARN 上有很多调度定制能力,如真实负载平均,全局黑名单等。这些都是经过实践能有效优化 Flink 运行的策略,迁移至 K8s 后依然保留了下来。
资源管理方案
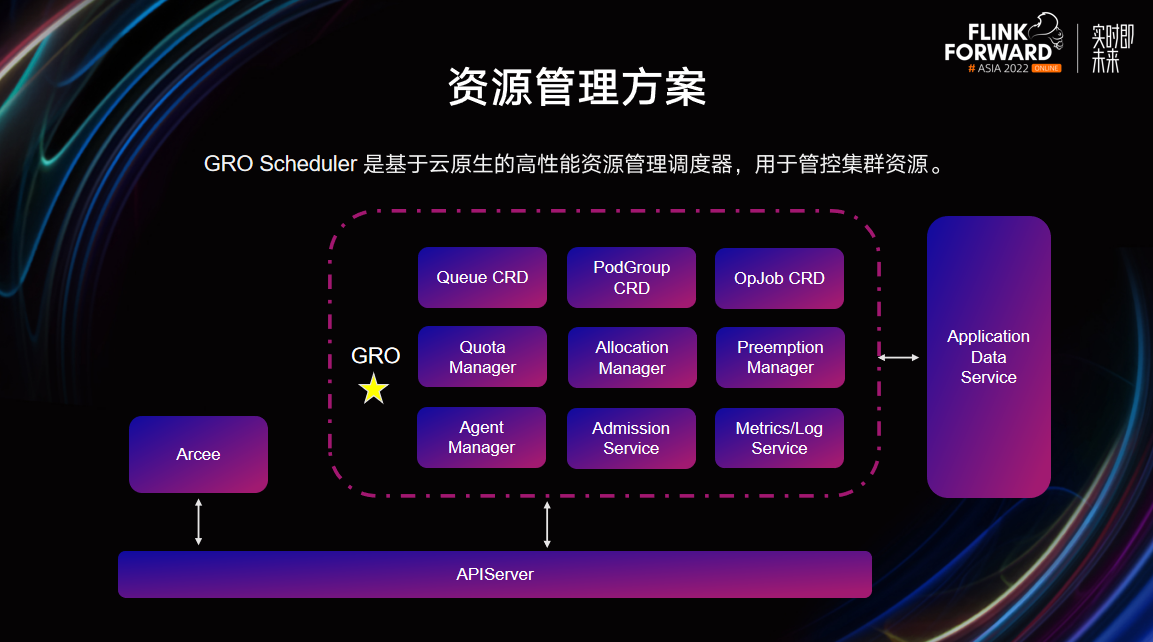
为了解决租户资源管控问题和批调度相关问题,通过研发一个基于云原生的高性能资源管理调度器—— GRO 调度器,实现集群资源的管控。
GRO 在 K8s 上增加了“队列”和“作业”的定义,其中队列对应了 Queue CRD,是 Quota 资源配额的抽象;作业对应了 PodGroup CRD,描述了一个“作业”调度单元,标识多个 Pod 属于同一个集合。另外 GRO 还提供了一个作业信息统计定义-OpJob CRD,用于提供细粒度的作业资源计量及状态信息。

在问题介绍部分提到了 Flink 负载的两个特点—— Pod 创建时间不确定、所需资源量不确定。在这两个特点下,调度器是最适合做租户管控的组件。
GRO Scheduler 参考 YARN 等大数据调度器,在 Pod 放置的基础上增加了 Quota 管控。首先,GRO 会通过所有队列的 Min(保障资源)、Max(资源上限)属性将集群资源公平地分配给各个队列。接下来,再根据不同调度策略(优先级调度、Gang 调度等),将队列资源分配给队列内的各个调度单元,再进一步分配给作业内的各 Pod,通过以上调度流程就可以在 K8s 上实现较细致的租户资源管控。
调度器的本质工作是资源调度,GRO Scheduler 具备 Flink 负载所需要的批调度能力。首先,GRO 支持 Gang 调度,能够提供 All-or-Nothing 调度语义,并在此基础上实现了调度快速失败功能,用于防止Flink作业长时间等待。其次,GRO具备高调度吞吐能力,在支持复杂调度策略的前提下,调度吞吐性能仍然可以达到每秒上千 Pod。最后,GRO 拥有丰富的放置能力。除了支持大部分原生功能外,还支持真实负载平均、GPU 共享、微拓扑调度等大数据场景的高级策略。
平台方案
关键问题:不同架构下作业&队列管理如何切换?

无论底层使用的是什么资源管理架构,作业和队列的基本管理操作在用户和上层平台看来大体是一致的。主要包括作业查询/ Kill,队列的创建/扩缩容等。此外,作业的 Webshell 登录、日志查询等周边服务,在不同架构下使用不同的组件实现对应功能。但一些依赖上层元数据实现的功能如权限控制等,在架构迁移前后也需要对应实现。那么就需要基于新架构,考虑将上层平台进行重新接入还是复用原有架构的数据和能力,打平前后接入差异?显然,如果能打平差异,做到上层业务平台的无感接入是最优的方案。
平台方案

为了实现前后架构基础管理和周边能力的打平,构建了一套前后复用的资管架构平台方案——Megatron 离线调度用户平台,主要是为了方便多业务平台查询接入,缓解底层 YARN 的查询压力。以上的定位和功能设计使 Megatron 成为最适合做架构屏蔽的平台。不仅为多种业务平台提供统一的接口,也具备较完整的作业和队列管理能力。其中,主要功能有作业同步、队列管理、数据查询、权限管控等。因此,Megatron 针对新的云原生底座进行了适配,成为了一个为 YARN 和 Kubernetes 同时提供简单便捷且统一的离线计算资源及作业管理平台。
三、生产实践

Flink 云原生化在字节跳动的生产实践情况。目前,流式通道任务,Streaming SQL,Streaming Java 等流式任务,都已完成云原生构架的适配。包括抖音、电商、推荐在内的几乎所有 Flink 业务,都已实现了新架构的接入。此外,这一整套架构也已实现了产品化的进程。
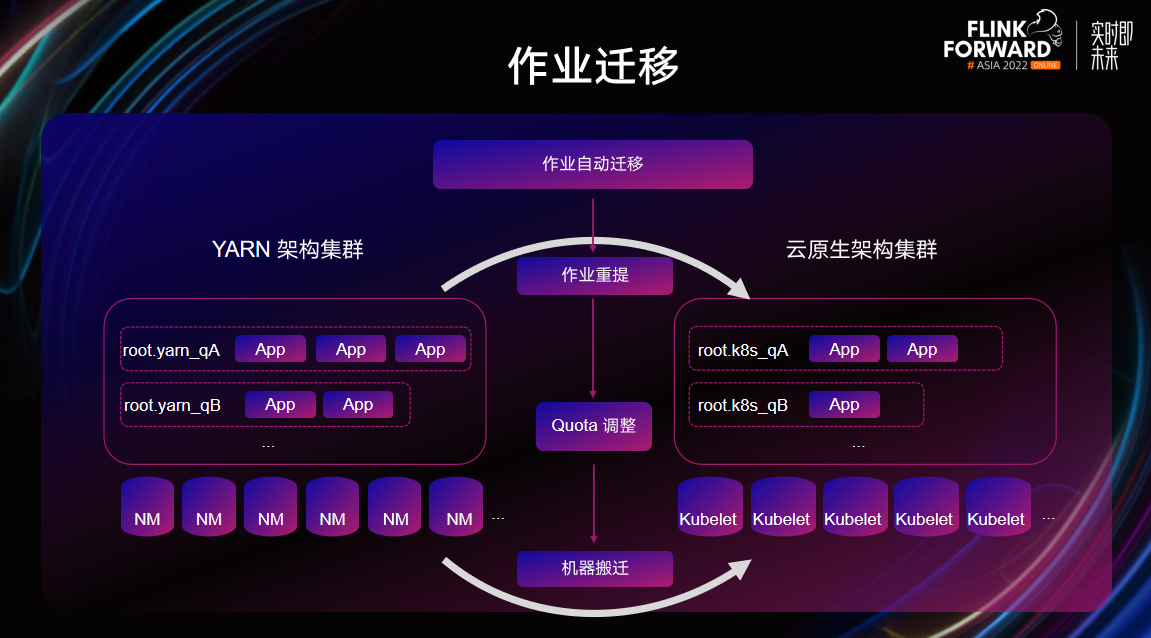
在作业迁移方面的实践,对于上层用户来说,作业的架构迁移看起来就是一次队列切换。作业提交服务会通过 Megatron 查询队列的属性,并自动生成对应的提交参数。Arcee 层面也尽可能的为用户屏蔽环境因素,此外 Flink 引擎在前后架构适配上,也做了非常多的改造工作,包括 Classloader 的差异兼容等。
为了加快公司内架构迁移的进展,构建了一套自动迁移流程。通过定期梳理待迁移的作业列表,并按照一定频率触发作业的队列切换重启,Quota 平台会相应的进行迁移前队列的缩容和后续队列的持续扩容,机器就会从老架构集群搬迁至新架构集群。在实际的迁移过程中,自动化迁移可以达到接近 1000 /天的作业迁移速度。
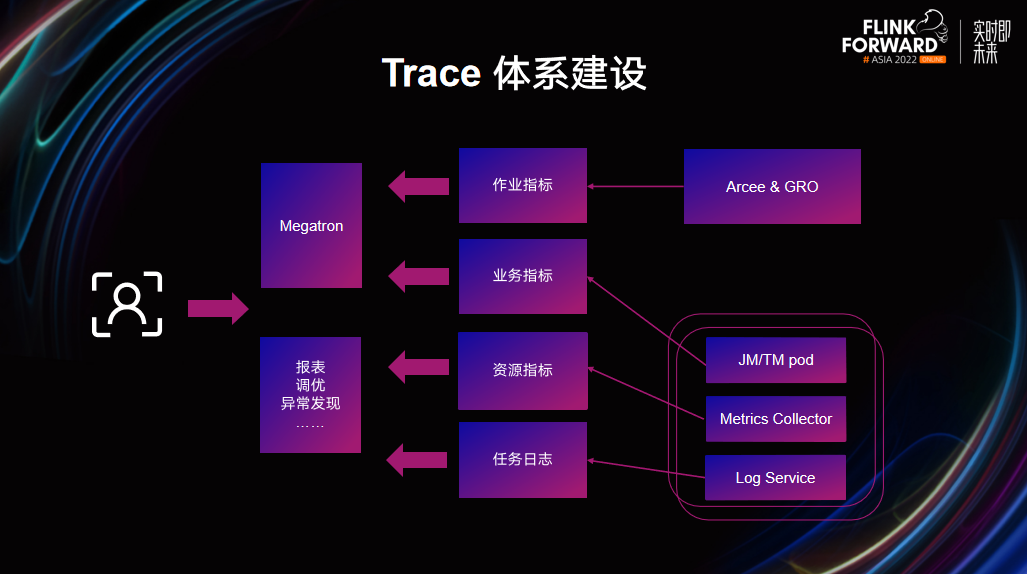
在 Flink on K8s 的环境中,日志和监控指标也是非常重要的,它可以帮助我们观察整个集群、容器、任务的运行情况,根据日志和监控快速定位问题并及时处理。所以也在 Flink 云原生化的过程中逐步构建了一套 Trace 体系。Flink 提供了业务指标,单机的 Metrics Collector 组件提供了物理机指标和容器指标。在日志方面,通过每个 Node 上运行的 Log Agent 采集指定路径的日志自动上传至日志平台进行解析查询。所有的指标和日志,都可以基于 Megatron 的平台化实时查询,也提供了具体的数据表,用户可以根据需求进行更高阶的查询,比如制作报表,作业调优,作业异常发现等。

在上量过程中,除了能力的构建也进行了生产上的优化。可以分为针对控制面的管控优化和 Flink 运行的运行优化。在管控优化方面,对 K8s Client 进行了拆分和参数调优,避免不同的 Apiserver 操作相互干扰。使用异步多线程处理方式提升系统本身作业的处理吞吐,通过优化与 Apiserver 的交互频率,尽可能减少不必要的资源操作。
在压测中,我们发现与 Apiserver 的交互是作业处理流程中开销最大的一环。通过交互优化,一方面减小了 Apiserver 的压力,另一方面也减少了 Apiserver 交互带来的处理开销。在运行优化方面,构建起了 Region 级别的唯一性检测,用来避免 Flink 作业的双跑。在远端资源下载方面,通过使用 P2P 进行下载加速,此外还参考 YARN 实现了资源的共享复用,减轻整体的下载压力。云原生的部署方案使得 Flink 可以使用更高阶的隔离能力,通过引入 Sidecar 的部署模式,将资源消耗较大的组件集成在 Flink Pod 中,用来避免这些组件对机器上的其他作业产生影响。
四、未来展望

未来的工作将主要围绕三个方面。
- 多云架构的设计落地和基于多云的容灾能力构建;
- 资源的弹性混部,同时进行资源调优,在保障 Flink 运行质量的同时进一步提升资源利用率;
- 性能和集群规模上的持续提升,未来将不断提升 Controller、调度器等的处理能力,用于支持像容灾类的极高吞吐要求场景,并支持更大规模的集群。
|








- 上一条: 利用自动化平台可以做的那亿点事 |得物技术 2023-03-31
- 下一条: 虚拟云网络系列 | Antrea 应用于 VMware 方案功能简介(四) 2023-03-31
- Flink 在字节跳动数据流的实践 2022-01-11
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化 2022-03-21
- 字节跳动 YARN 云原生化演进实践 2022-11-17
- 字节跳动 Flink 基于 Slot 的资源管理实践 2022-09-05
- 字节跳动数据湖技术选型的思考与落地实践 2022-01-24