百度内容理解推理服务FaaS实战——Punica系统
 作者 | 百度内容生态研发团队
作者 | 百度内容生态研发团队
导读
内容理解推理服务是内容理解数据流上的多个推理服务的集合,对来自百家号、好看、全民、直播等多个发文方的文本、图片、视频等内容进行理解,并标记内容标签,为百度Feed信息流、搜索等C端用户提供内容。长期的业务迭代,积累了近千推理服务,存量服务的运维管理和新增服务的高效接入,是非常有挑战性的工作,本文基于实际工作经验分享Punica系统是如何提升业务迭代效率和服务稳定性的。
全文5106字,预计阅读时间13分钟。
01 背景
内容理解服务是对百家号、好看、全民、直播等多个发文方的文本、图片、视频等内容进行理解,并标记内容标签,为百度Feed信息流、搜索等C端用户提供内容,例如,自媒体用户在百家号提交了一篇关于美食的文章,经过内容理解的推荐策略服务,会进行理解并标记美食标签,然后Feed信息流会基于内容标签和浏览用户的爱好进行匹配推荐。
内容理解服务是架构统一微服务推理框架,不同业务自建服务App,在架构平台上注册和管理,基于PaaS进行调度,共有近千的CPU和GPU类型的服务App。在业务接入、迭代、运维过程中存在如下问题:在开发阶段,推理框架参数多、配置成本高,且推理服务封装后性能降低;在测试阶段,测试数据构造成本高,测试资源不足,且每次补充测试资源均需要创建一个单实例的App,补充成本高;在上线阶段,业务同学需要学习厂内多个PaaS平台的应用创建流程,监控&报警添加繁琐,新服务接入需要操作多个平台,协调等待线上资源,正常情况下完成上线需要两周,而策略迭代频繁,平均每个月要新增数十策略服务,服务接入存在较高的人力消耗;在部署&运维阶段,由于服务部署依赖较多较大lib包下载,新实例部署耗时20+分钟,服务存在低弹性、扩容止损慢等问题,另外存量服务有近千App,架构升级成本高,架构框架、云原生改造等均需要操作大量App;另外服务的资源利用率低,存在较大的资源浪费,业务成本高且新服务上线资源准备成本高。
02 整体思路
为了解决上述问题,我们考虑如何提升业务接入、迭代、维护的效率,同时提升资源利用效率,降低业务成本,主要从两个方面展开:一站式+无人值守。
2.1 一站式平台
平台加一减N:将多个平台统一至Punica平台,减少用户学习和使用成本,无需创建PaaS服务,提供一站式推理服务接入、迭代、测试、上线、运维等功能。
提升服务迭代速度:将服务参数配置平台化,提供推荐参数配置,测试期间支持快速修改验证;测试资源快速补充,无需创建PaaS服务;提供自动化测试任务,用户仅需提交测试任务,由Punica系统自动调配闲时资源,自动调节压测参数,用户只需关注最终测试结果;支持业务快速小流量验证,使用系统内的冗余资源先行小流量验证效果;对于新服务上线,可以自动增加监控、报警,减少用户操作成本。
降低业务资源成本:在支持通用性&易用性的Python微服务推理框架的同时,还支持高性能C++微服务推理框架;支持多种GPU卡,例如T4、P4、A10、A30以及高性价比的昆仑卡, 通过联合厂内GPU同学,基于CGPU、MPS、MIG等机制,支持小规格(半卡、1/4卡等)的GPU卡配额;在调度层面,可以自动调度多模型在GPU卡上混部;同时,Punica还集成了PaddlePaddle的模型性能优化流程,从模型层面降低业务资源成本。
通过一站式平台,用户将训练好的模型以及前后置处理代码提交到模型仓库和代码仓库,在Punica平台注册服务、测试、上线,减少了跨平台操作、测试环境准备、等待资源投产等耗时,整体上线周期从两周降低到一周,减少用户学习成本。
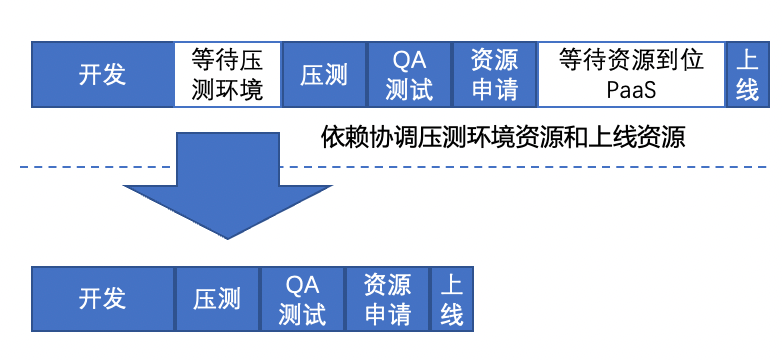
2.2 无人值守
Punica在服务部署上解耦推理服务部署包与推理框架、Python、Cuda、Cudnn等lib包,lib包可提前预下载,实际部署时仅需下载推理服务部署包,因此推理FaaS服务具备高弹性能力。
资源自动调度:资源定期回收,通过监控资源利用率,低利用率服务资源回收定期通知;资源分时复用,在一定范围内对服务进行自动扩缩容,在服务间腾挪资源,支持业务小流量、测试、历史数据回溯等,对于线上高优服务容量问题,可以临时腾挪低优资源保障高优服务稳定性。
服务自愈巡检系统:通过实例自愈,基于业务/容器/机器指标自动决策、处置单实例故障;通过服务成功率巡检&online率巡检,及时发现服务线上稳定性问题;基于算子拓扑的故障决策树,定位服务故障根因。
降低维护成本:PaaS App减少1个数量级,对于服务云原生改造、监控添加/调整等工作,减少人力开销;算子接入时即可满足准入要求,算子代码库、接口人、监控等关键信息齐全;架构升级成本低,无需逐个App进行上线操作,只需灰度发布,更新算子依赖框架版本即可。
服务自愈巡检系统会监测各个服务模块实例级/服务级的业务/容器/机器的指标健康度,通过决策树判定单服务故障类型,并将故障信息反馈到服务拓扑上,然后再通过决策树判定服务的故障根因。接下来通过一个案例来介绍:一个下游服务存在故障实例,导致上游服务成功率降低,触发入口服务的重试,导致请求流量翻倍,进而引发服务雪崩。对于该案例,服务自愈巡检系统会在下游服务出现单实例故障时感知并进行单实例故障处置,进而阻止故障严重;如果出现服务重试导致流量翻倍情况,自愈系统会快速判定系统容量不足进行容量补充,防止服务雪崩。
在容量管理方面,服务的频繁迭代会带来众多问题,例如:新旧服务切换,旧服务没有及时下线,导致资源浪费;服务容量评估不准确,线上服务存在容量风险或者资源浪费;业务流量变化频繁,服务拓扑结构复杂,人工调整成本高。针对这类问题,从几个方面进行了容量治理:低利用率服务资源回收,解决服务下线、容量评估不准确导致的资源浪费问题;基于服务资源负载的容量自动扩缩,解决服务容量风险问题,减少人工操作成本;基于服务流量预测的分时伸缩,形成一定的闲时资源池,供给给闲时任务使用。另外,也通过多模型混部、GPU混部等技术解决小卡服务以及极限利用率较低的模型的资源利用率问题。
03 技术方案
首先给大家介绍一下Punica系统中用到的云原生概念:IaaS,基础设施即服务,容器服务如docker;PaaS,平台即服务,容器调度系统如EKS、Kubernetes;FaaS,函数即服务,Punica系统中推理模型即服务。
我们从FaaS角度,重新定义推理服务,建设一站式平台和无人值守机制,隔离业务与PaaS部署,让业务更轻量、更简洁。通过隔离业务与PaaS基础环境,解耦了业务与基础环境,架构可以对基础环境进行统一管理和收敛,提升服务部署速度,使业务服务具备高弹性。
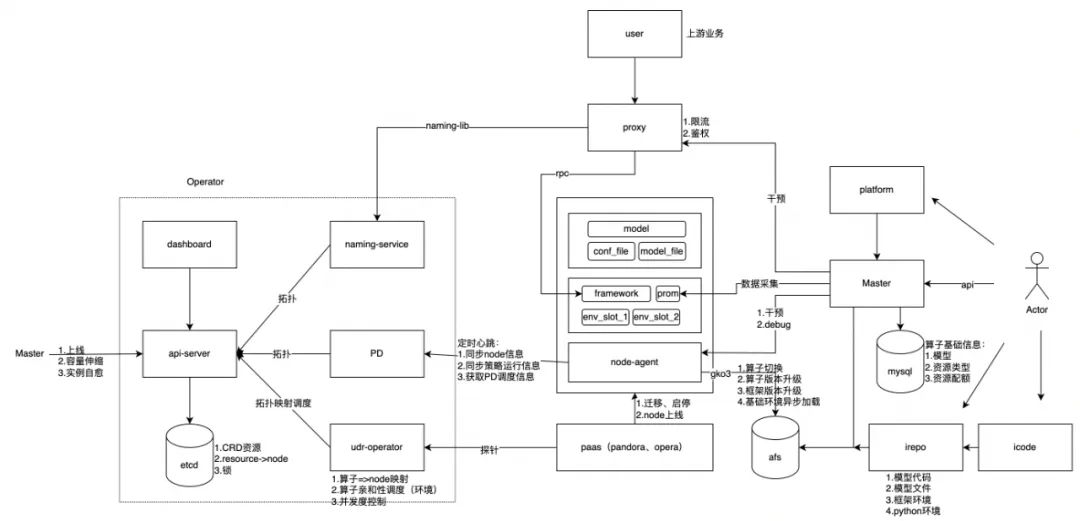
整体架构如下图所示,主要包括四部分:FaaS系统,包括容器框架、调度系统、Proxy 网关模块,提供推理服务高弹性部署与调度;平台前端,提供统一的推理服务接入、测试、上线、管理页面,资源报表展现,伸缩&自愈事件展现等;平台后端,提供对应页面的后端功能,同时支持OpenAPI调用,提供FaaS服务管理、服务测试迭代、资源管理等;服务治理,提供FaaS服务自愈巡检、容量伸缩等。
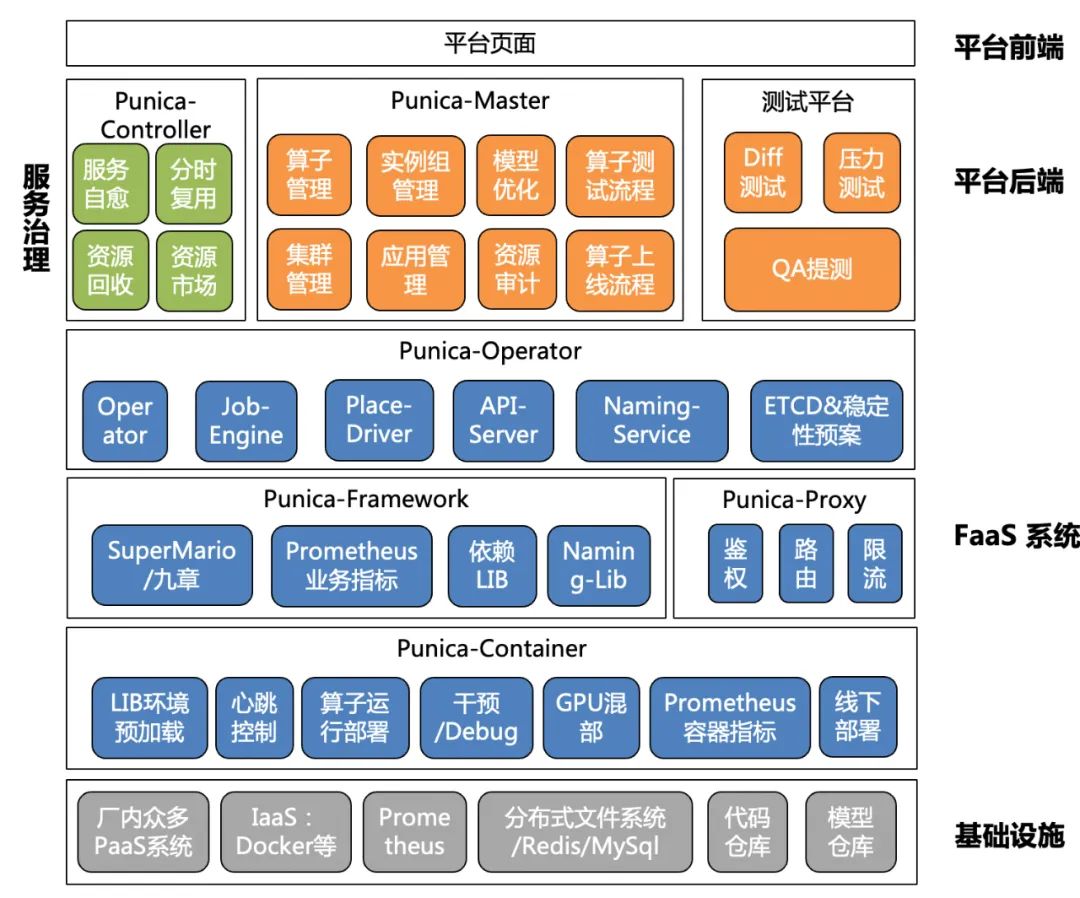
其中平台前/后端作为Punica系统的服务接入、系统管理平台。下面主要介绍FaaS系统和服务治理机制。
3.1 服务部署
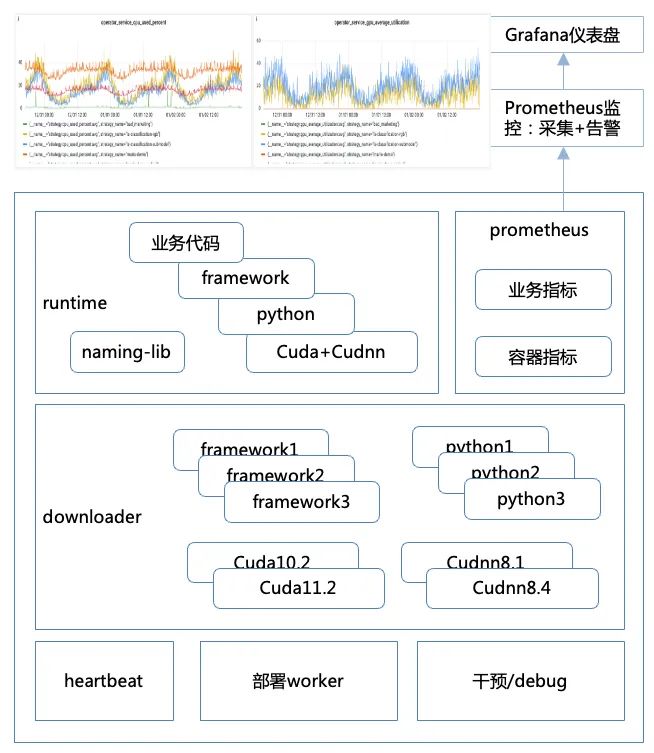
建设Punica容器框架,对接并改造推理微服务框架,将业务环境与基础环境分离,对基础环境进行托管,同时收敛基础环境的版本;从框架层对接Prometheus监控,将容器、机器、业务指标上报,由百度云Prometheus团队提供统一的监控视图和报警。
下面简单介绍下容器框架的功能点:心跳机制,提供探活能力,上报调度系统该节点是否正常运行以及该节点上部署的推理服务信息&状态,同时接收调度系统下发的服务更新、创建、删除等命令;部署能力,支持服务的创建、更新、重启、删除、停止等功能,同时可以配置lib预下载,提前下载相关lib包,服务部署仅需下载模型包即可;干预机制,支持停止心跳、屏蔽流量、屏蔽心跳命令的干预接口;Debug机制,支持节点信息查询,包括节点部署路径、部署服务信息等;线下部署能力,支持线下单独部署,用于本地测试。
3.2 服务调度
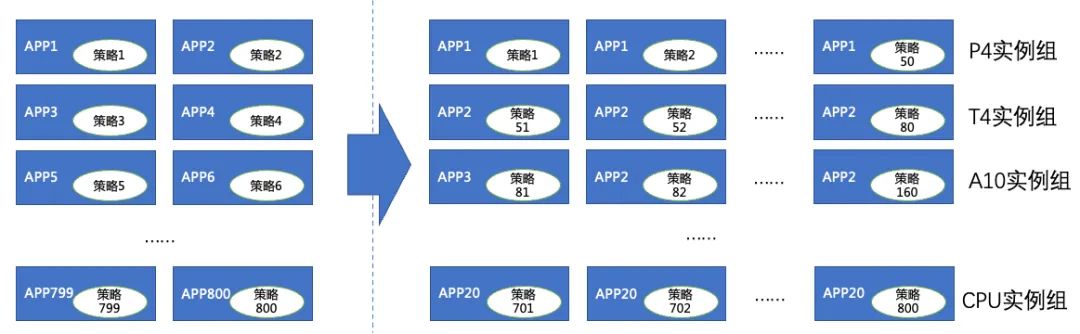
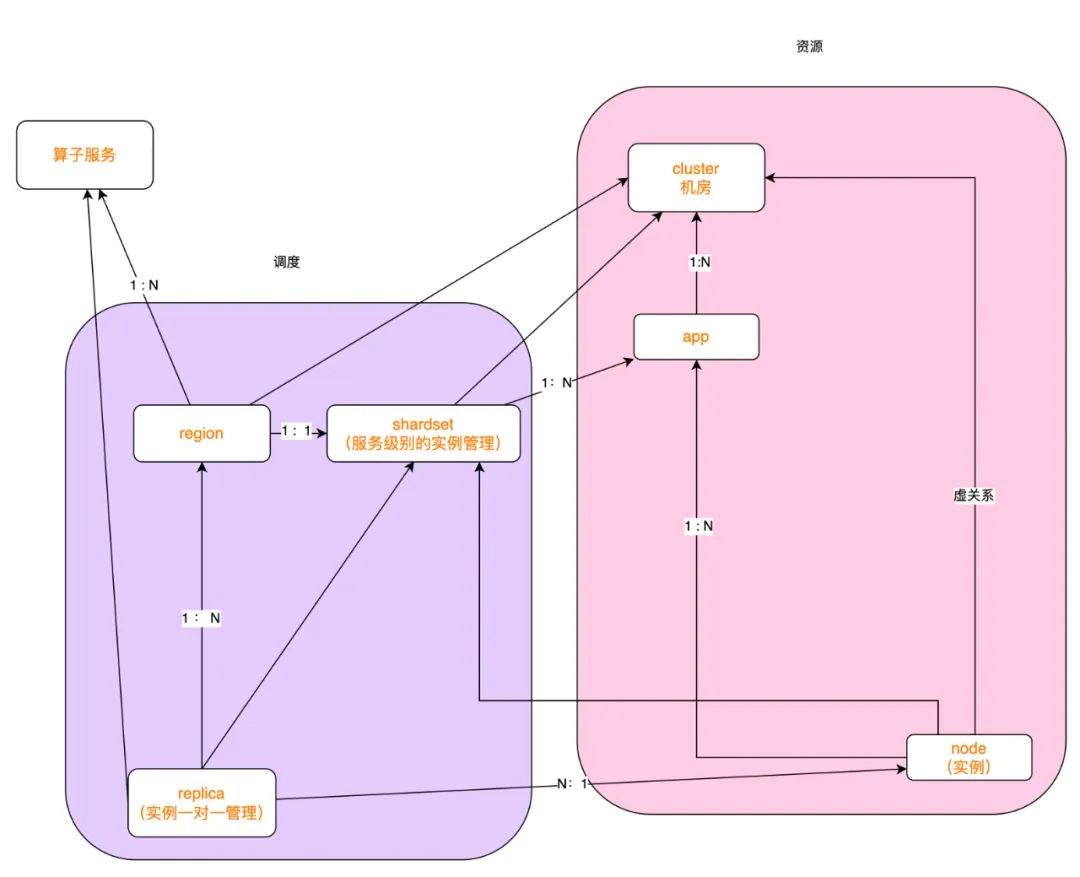
在调度系统中,我们结合推理服务与PaaS服务的部署情况,定义了推理服务到PaaS服务的部署映射关系。PaaS服务在一个Cluster中部署的一组副本(Node)称之为一个部署组(App),推理服务在一个Cluster中部署的一组副本(Replica)称之为一个实例组(Resource),一个Node具备了Replica部署所需的基础环境,只需要加载对应的模型文件和业务前后置代码即可。
基于此,我们对当前推理服务的运行环境进行归类整理,根据硬件环境分为CPU、GPU,其中GPU又根据卡类型具体分为T4、P4、A10、A30、昆仑卡。针对不同硬件环境,Node节点会提前预置好相关运行环境。
调度系统完成了推理服务的Resource到PaaS App、Replica到Node的映射,通过映射关系,实现了推理服务的容量伸缩、实例迁移、版本更新等机制。
3.3 服务发现
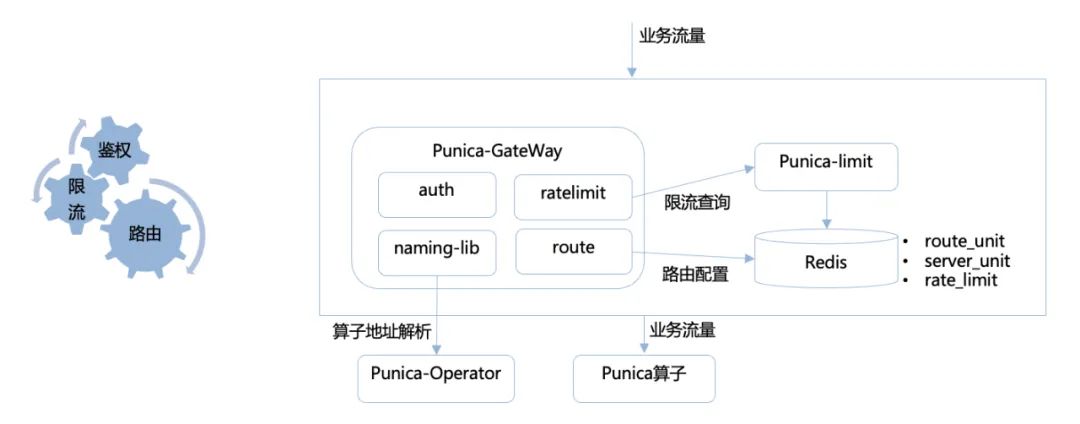
在PaaS上部署的App一般是通过百度统一名字服务来做服务发现的。对于部署在Punica中的推理服务,我们需要提供统一的服务发现机制。
首先来介绍一下Punica中推理服务部署的拓扑信息如何获取,上面讲到了调度系统完成了推理服务到PaaS App的映射,因此调度系统可以提供推理服务每一个Replica部署所在容器的IP、Port。对于一个推理服务,我们就可以通过查询调度系统来获取该推理服务部署在Punica中的节点访问地址列表。
通过调度系统,我们可以获取到指定服务的地址列表,为了降低用户的使用成本,同时支持限流和鉴权功能,我们建设了推理服务统一网关模块。网关模块定义了用户名、token、特征id,由这三个字段定义一组路由配置,具体包括服务地址、鉴权配置、限流配置。通过自定义baidu-rpc的naming插件,查询 Punica服务地址,实现路由能力;通过请求中的用户名、token、特征id进行鉴权;根据用户名、token、特征id增加限流配置。
3.4 策略控制器
我们希望通过服务治理策略尽量实现无人值守,减少策略同学、架构同学的运维成本。主要从以下几个方面进行建设:服务巡检自愈,通过定期&报警回调检测服务关键指标,根据经验决策树+服务拓扑结构进行根因定位,支持机器级别故障、实例级别故障&热点、服务级别故障识别与自动解决;分时/自动扩缩容,通过在一定范围内对服务容量动态扩缩,保障高优服务的容量水位,同时供给出部分闲时资源;服务资源低利用率定期回收,通过定期检测服务长期利用率情况,对资源利用率长期处于较低水位的服务进行缩容或下线处理;资源市场,维持系统内整体资源的容量水位,对资源供给与消费统一管控;闲时任务,支持历史数据回溯、自动化测试任务等闲时资源使用。
3.5 Punica系统内部交互
用户将业务代码上传至代码仓库、模型上传至模型仓库,在Punica平台注册服务,填写服务的业务背景、接口人、代码库、运行环境等基础信息,然后发起准入测试任务,Punica平台会根据用户填写的服务信息拉取服务的代码和模型,并生成推理服务部署包,通过Operator模块为用户准备测试环境,当用户测试完成后,本次测试的推理服务部署包会被分配一个版本号并固化在afs上;用户在平台新建实例组或者对已有实例组更新服务版本时,可以选择已经发布的推理服务部署包进行上线更新,Operator模块会控制服务副本滚动更新,容器框架在接收到Operator模块的调度信息后,会根据服务的版本信息更新本地的部署版本;Proxy网关模块会承接所有业务流量,并对流量进行鉴权、限流、负载均衡,然后将流量路由至对应的推理服务副本。
04 总结
我们从业务迭代、资源提效出发,结合当前推理服务开发、部署、运维现状,尝试了从FaaS角度来建设Punica系统,提升业务迭代效率,平台加一减N,新服务上线效率提升100%,保障线上服务的稳定性,服务扩容速度提升5倍,降低业务的资源成本,目前已累计回收400+张GPU卡,已经投产到新业务的迭代发展。
——END——
推荐阅读:
|








- 上一条: 百度内容理解推理服务FaaS实战——Punica系统 2023-03-30
- 下一条: 没有了
- 百度搜索中台新一代内容架构:FaaS化和智能化实战 2022-01-13
- 百度短视频推荐系统的目标设计 2021-09-08
- BaikalDB在百度统计的应用实践 2021-09-25
- 百度交易中台之资产系统架构浅析 2022-09-22
- 百度交易中台之钱包系统架构浅析 2022-06-22


