精准测试之分布式调用链底层逻辑
作者:京东工业 宛煜昕
概要: 1. 调⽤链系统概述; 2. 调⽤链系统的演进; 3. 调⽤链的底层实现逻辑; 4. Span内容组成。
⼀、分布式调⽤链系统概述
客户打电话给客服说:“优惠券使⽤不了”。 -客服告诉运营⼈员 --运营打电话给技术负责⼈ ---技术负责⼈通知会员系统开发⼈员 ----会员找到营销系统开发⼈员 -----营销系统开发⼈员找到DBA ------DBA找到运维⼈员 -------运维⼈员找到机房负责⼈ --------机房负责⼈找到⼀只⽼⿏ ,因为就是它把⽹线咬断了。
分布式架构所带来的问题
定位⼀个问题怎么会如此复杂?竟然动⽤了公司⼀半以上的职能部⻔。但其实这只是当我系统变成分布式之后,当我们把服务进⾏细粒度的拆份之后的⼀⼩部分问题,更多问题在哪⾥?⽐如: 1. 开发成本增加。 2. 测试成本增加。 3. 产品迭代周期将变⻓。 4. 运维成本增加。
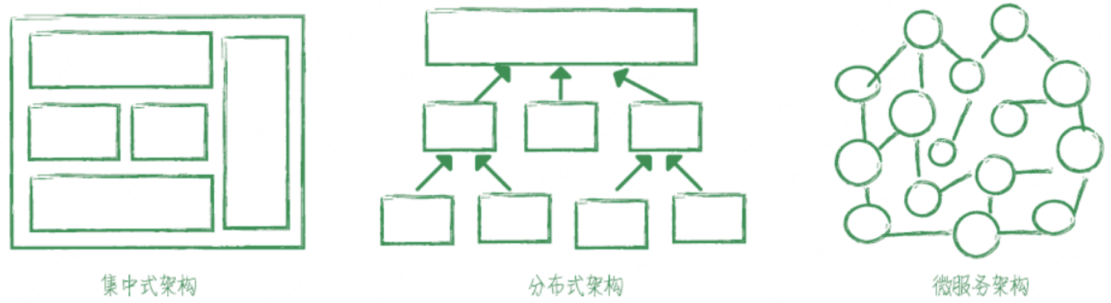
问题产⽣原因
在传统制造业,分⼯越精细,专业化程度越⾼,产能就越⾼。⽐如⼀台汽⻋平均将近3万个零部件,来⾃全球各个供应商,最后再由汽⻋⼚商统⼀拼装检测出⼚。不仅⼤件是精细分⼯完成,⼩件也是如此,在浙江温州 有⼀个打⽕机村,⼀个⼩⼩的打⽕机⽣产,是由20多个⼚家协作完成,有的做打⽕机燃料有的做点⽕器。
反观软件⾏业,这种精细分⼯很难实现, 你⻅过哪家某个系统是由⼗⼏家企业协作完成的么?你觉得淘宝的电商系统可以让⽇本⼈去开发 购物⻋模块、让法国⼈实现评论模块、让印度⼈去实现下单功能、美国⼈实现商品模块,最后在由中国⼈拼装整合?究期原因再于三个字:“标准化”,刚说的汽⻋3万个零件,每个都有其标准化规格,所以才能够顺利的拼装成品,但软件组成很难标准,就连开发个接⼝都没有指定标准,就连⼀个规范都难于推⾏。没有标准化,不能分⼯协作,那怎么实现软件的⼤规模⽣产呢?就是⽤更多的⼈,更多⼯作时⻓去冲抵。软件开发就此成为⼀个劳动密集型产业,新⽣代信息化农⺠⼯群体诞⽣。这对企业⽽⾔是不利的,因为它要为信息化付出更多的成本。所以相应管理办法与开发⼯具都要升级,管理办法是类似于敏捿开发、⼯程师⽂化建设、开发形为准则。另外⼀个就是⼯具:⾃动化构建、⾃动化部署、⾃动化运维、⾃动化扩容等、线上链路监控等等。
分布式链路监控的作用
1. 定位线上问题; 2. 分极性能问题; 3. 降纸软件复杂度; 4. 提供决策数据⽀持。
⼆、调用链系统的演进

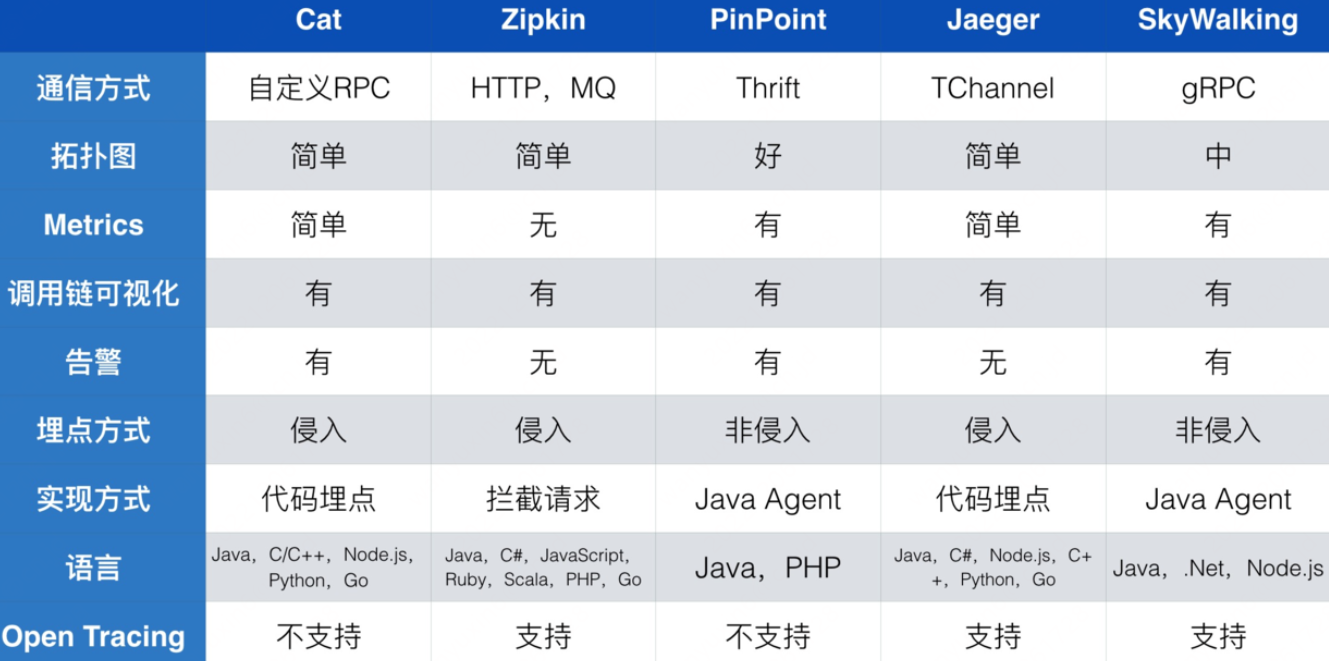
⼀般我们认为链路监控产品是从 2010 年 Google 发表名为 《Dapper⼤规模分布式系统的跟踪系统》论⽂开始流⾏起来的。之后出现的很多开源或者闭源的产品都是以 Dapper 为理论基础。下表列出已知的链路监控系统。
链路监控系统列表
| 公司 | 系统名称 |
|---|---|
| Dapper | |
| 阿里巴巴 | 鹰眼 |
| 腾讯 | 天机 |
| 百度 | 凤睛 |
| 京东 | CallGraph,hydra |
| 美团点评 | CAT(Central Application Tracking) |
| 美团 | MTRace |
| 链家 | LTrace |
| 苏宁易购 | Hiro |
| Uber | Jaeger |
| Zipkin | |
| 网易 | Pylon |
| 个人开源 | PinPoint |
| Apache | Apache SkyWalking |
淘宝鹰眼 鹰眼界面
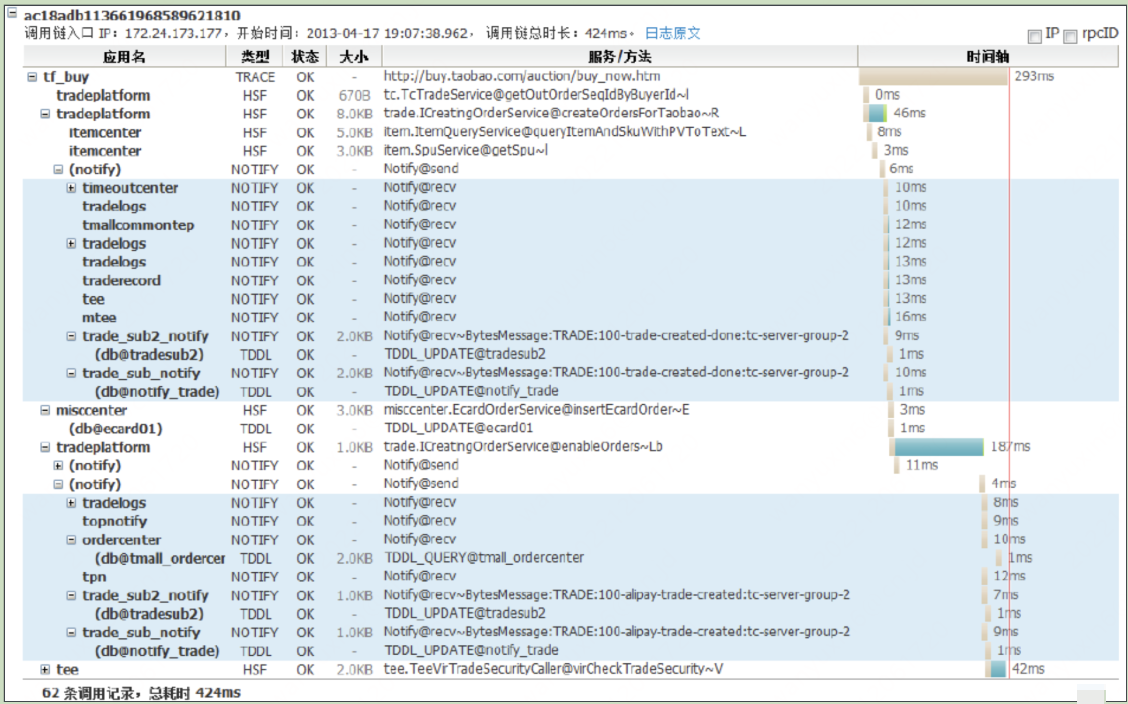
鹰眼架构
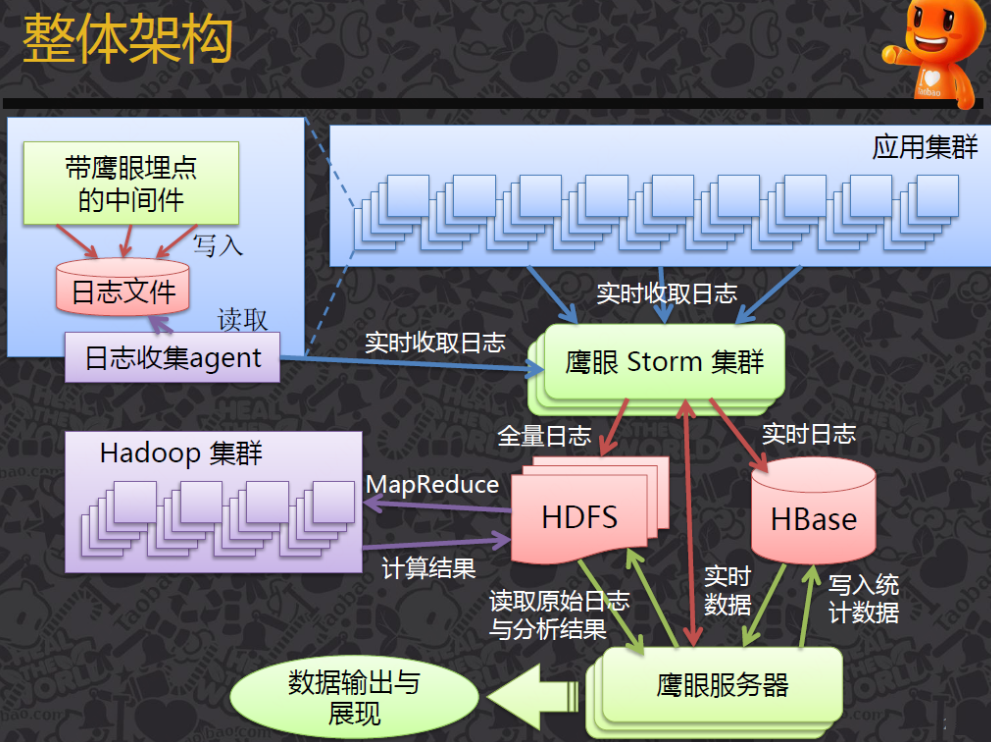
Google Dapper
Dapper 界⾯
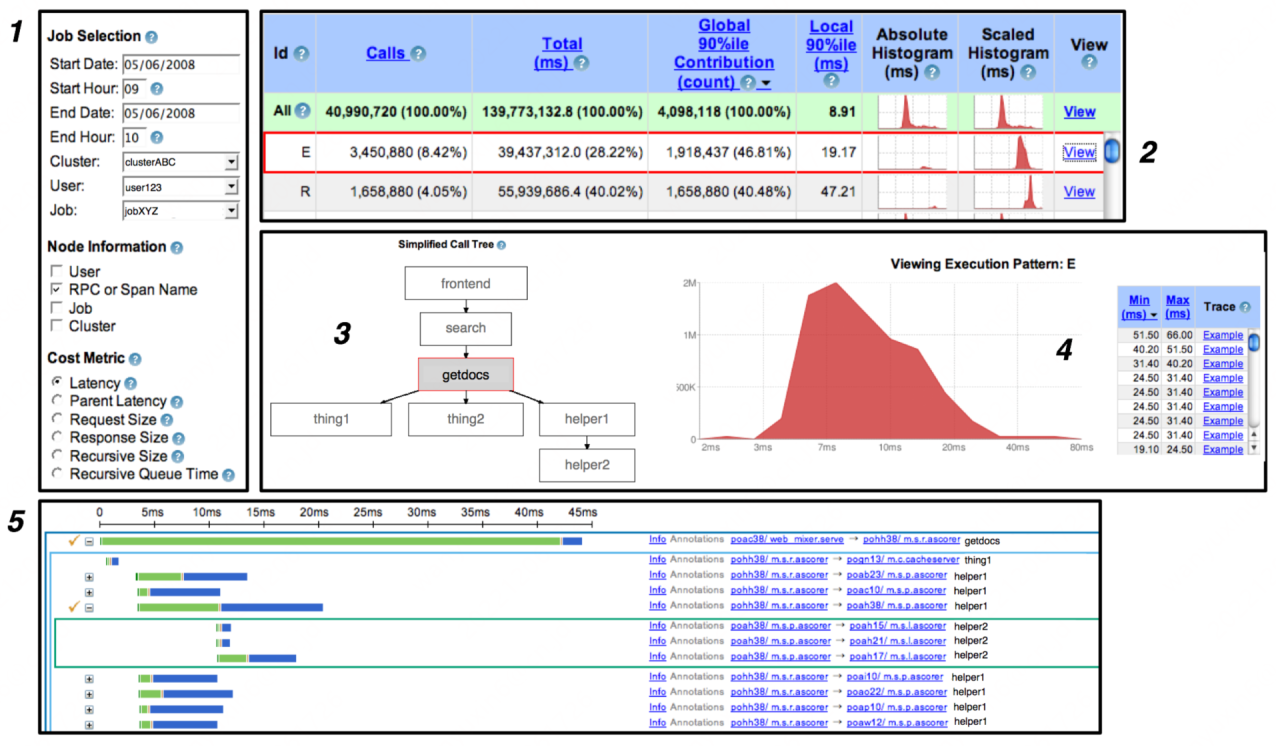
Dapper架构图
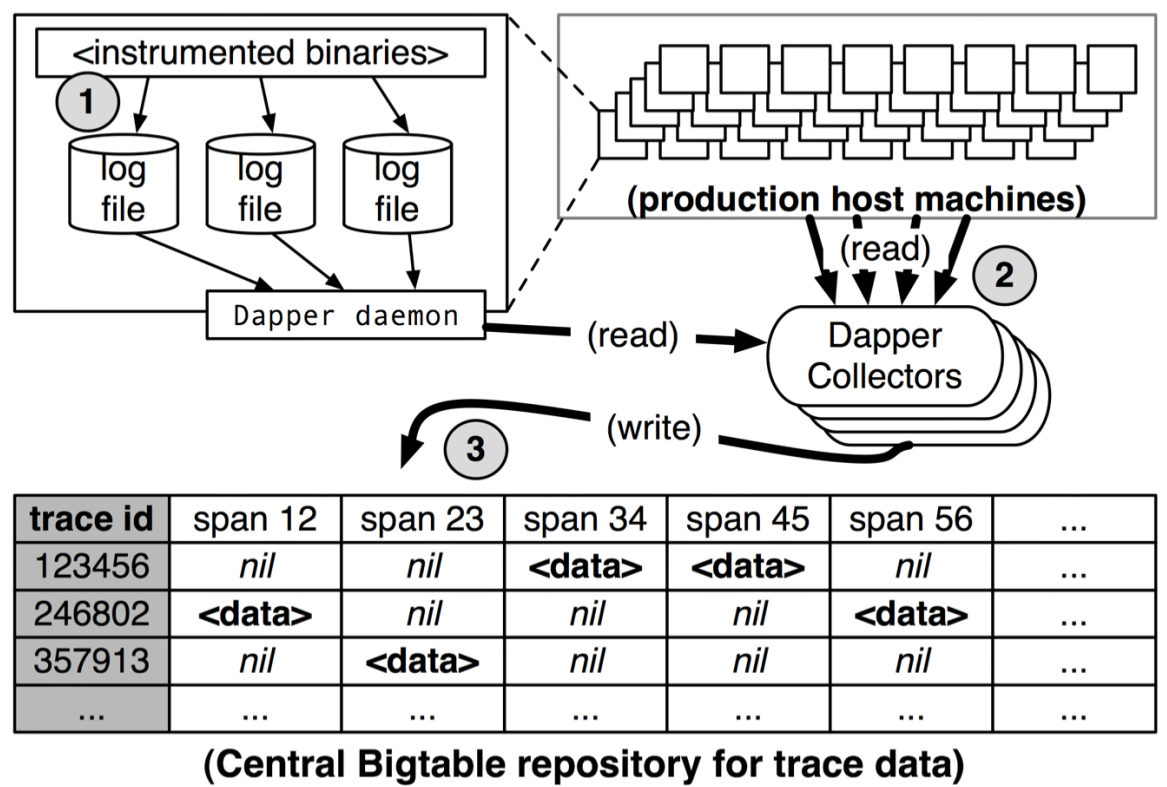
开源链路监控
三、调用链系统的底层实现逻辑
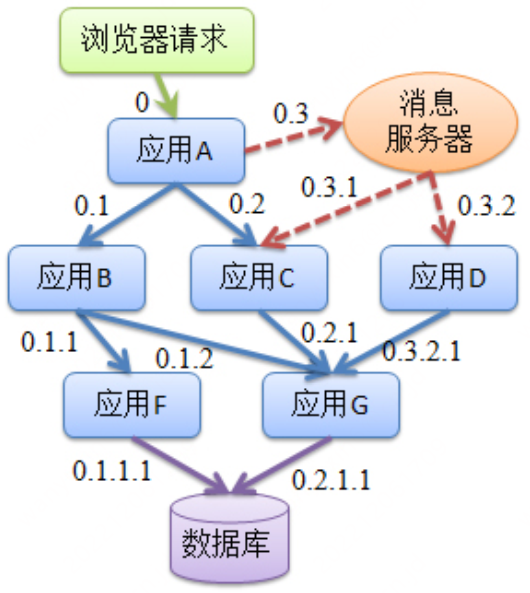
调用链系统的本质
⼀张⽹⻚,要经历怎样的过程,才能抵达⽤户⾯前?
⽹络传输层


负载均衡层
系统服务层
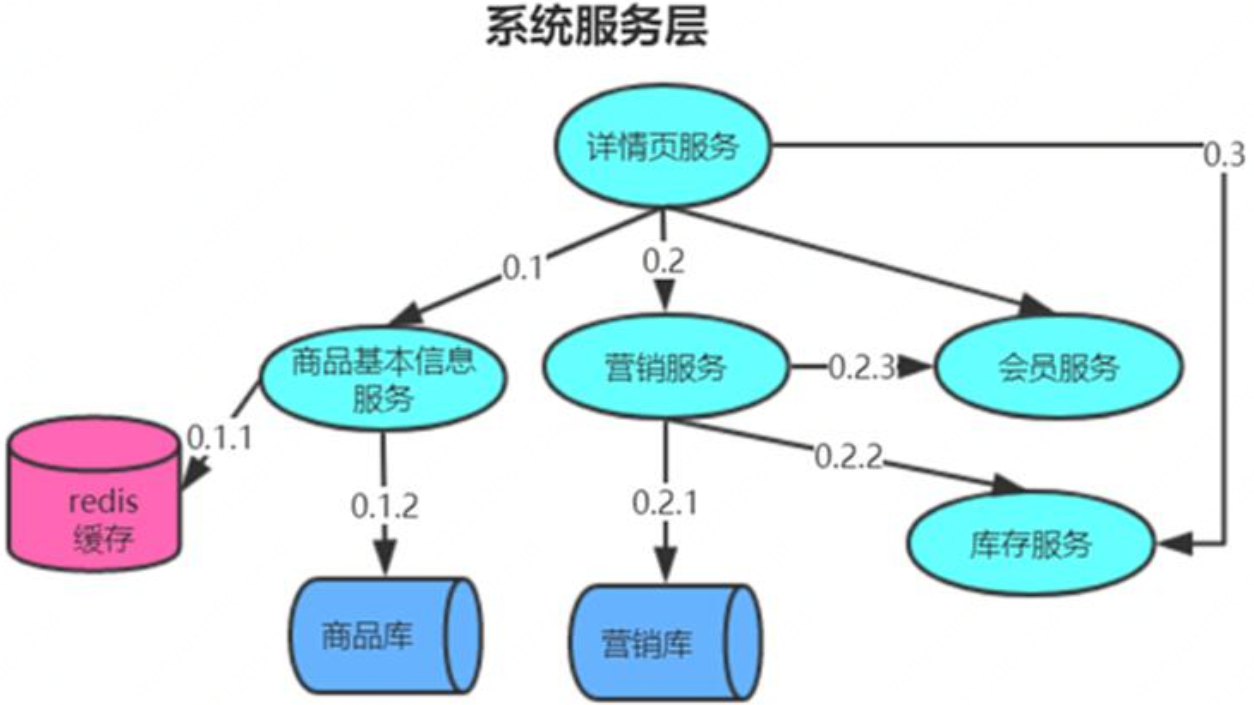
调用链基本元素
-
事件:请求处理过程当中的具体动作。
-
节点:请求所经过的系统节点,即事件的空间属性。
-
时间:事件的开始和结束时间。
-
关系:事件与上⼀个事件关系。
调⽤链系统本质上就是⽤来回答这⼏问题:
-
什么时间?
-
在什么节点上?
-
发⽣了什么事情?
-
这个事情由谁发起?
事件捕捉
-
硬编码埋点捕捉
-
AOP埋点捕捉
-
公开组件埋点捕捉
-
字节码插桩捕捉
事件串联
事件串联的⽬的:
-
所有事件都关联到同⼀个调⽤
-
各个事件之间层级关系
为了到达这两个⽬的地,⼏乎所有的调⽤链系统都会有以下两个属性:
traceID:在整个系统中唯⼀,该值相同的事件表示同⼀次调⽤。
spanD:在⼀次调⽤中唯⼀、并展出事件的层级关系
1、怎么⽣成TraceID
2、怎么传递参数
3、怎么并发情况下不允响传递的结果
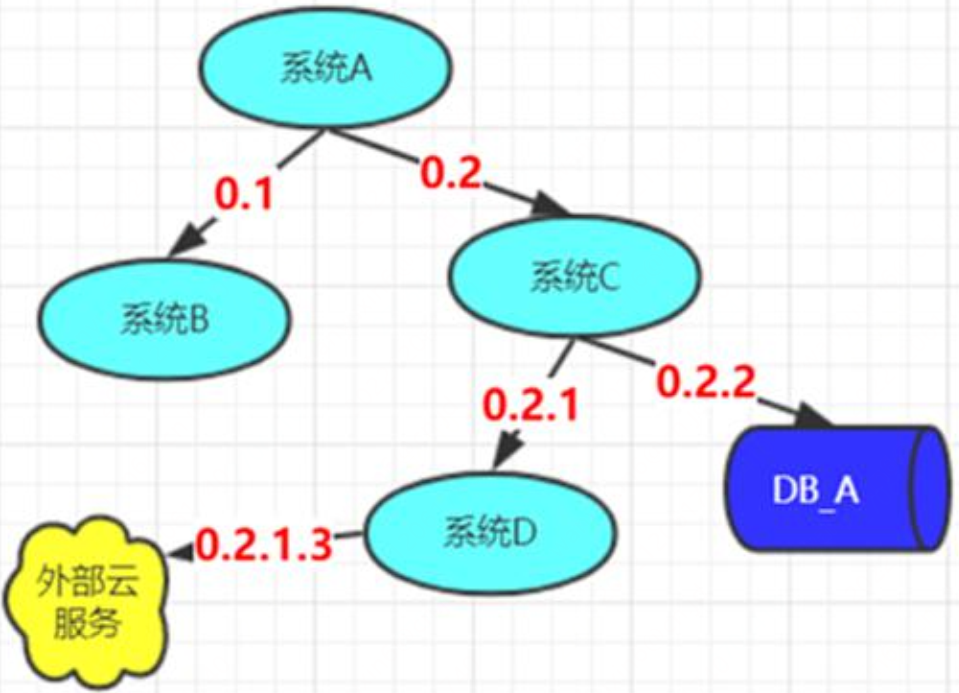
串联的过程:
-
由跟踪的起点⽣成⼀个TraceId, ⼀直传递⾄所有节点,并保存在事件属性值当中。
-
由跟踪的起点⽣成初始SpanId,每捕捉⼀个事件ID加1,每传递⼀次,层级加1。
trackId与SpanId 的传递

SpanId ⾃增⽣成⽅式
我们的埋点是埋在具体某个实现⽅法类,当多线程调⽤该⽅法时如何保证⾃增正确性?

解决办法是每个跟踪请求创建⼀个互相独⽴的会话,SpanId的⾃增都基于该会话实现。通常会话对象的存储基于ThreadLocal实现。
事件的开始与结束
我们知道⼀个事件是⼀个时间段内系统执⾏的若⼲动作,所以对于事件捕捉必须包含开启监听和结束监听两个动作?如果⼀个事件在⼀个⽅法内完成的,这个问题是⽐较好解决的,我们只要在⽅法的开始创建⼀个Event对象,在⽅法结束时调⽤该对像的close ⽅法即可。

但如果⼀个事件的开始和结束触发分布在多个对象或⽅法当中,情况就会变得异常复杂。
⽐如⼀个JDBC执⾏事件,应该是在构建 Statement 时开始,在Statement 关闭时结束。怎样把这两个触发动作对应到同⼀个事件当中去呢(即传递Event对象)?在这⾥的解决办法是对返回结果进⾏动态代理,把Event放置到代理对象的属性当中,以达到付递的⽬标。当这个⽅法只是适应JDBC这⼀个场景,其它场景需要重新设计Event 传递路径,⽬前还没有通⽤的解决办法。

上传
上传有两种⽅式
-
基于RPC直接上传
-
打印⽇志,然后在基于Flume或Logstash采集上传。
第⼀种相对简单,直接把数据发送服务进⾏持久化,但如果系统流量较⼤的情况下,会影响系统本身的性能,造成压力。
第⼆种相对复杂,但可以应对⼤流量,通常情况下会采⽤第⼆种解决办法。
四、Span内容组成
Span基本内容
在调⽤链中⼀个Span,即代表⼀个时间跨度下的行为动作,它可以是在⼀个系统内的时间跨度,也可能是跨多个服务系统的。下图即是Dapper中关于Span的描述。
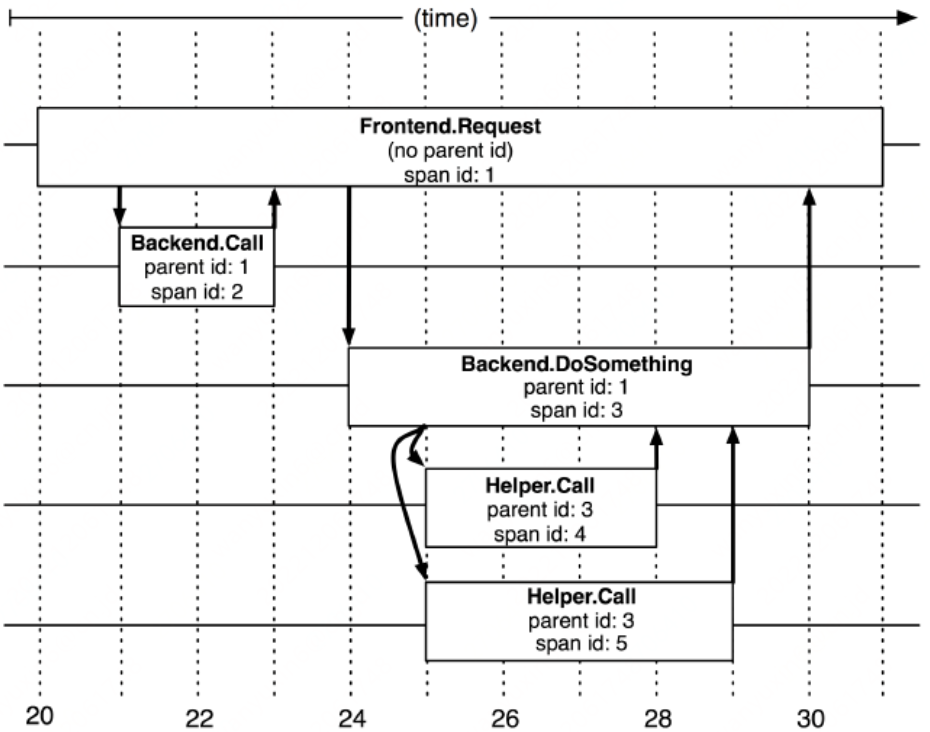
通常情况下⼀个Span组成包括: 1. 名称:即操作的名称,必须简单可读性⾼,它应该是⼀个抽像通⽤的标识,不能太具体。 2. SpanId:当调⽤中唯⼀ID 3. ParentId:表示其⽗Span 4. 开始与结束时间
端到端Span
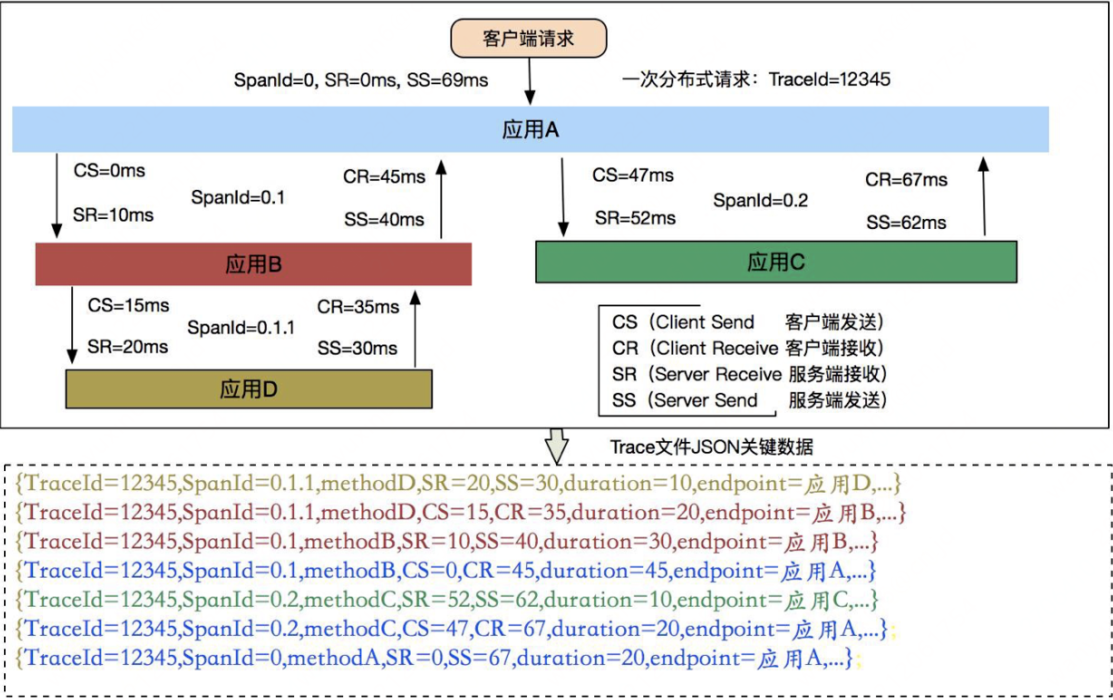
一次远程调用需要记录几个Span呢?
我们需要在客户端和服务端分别记录Span信息,这样才能计在两个端的视角分别记录信息。比如计算中间的网络IO。
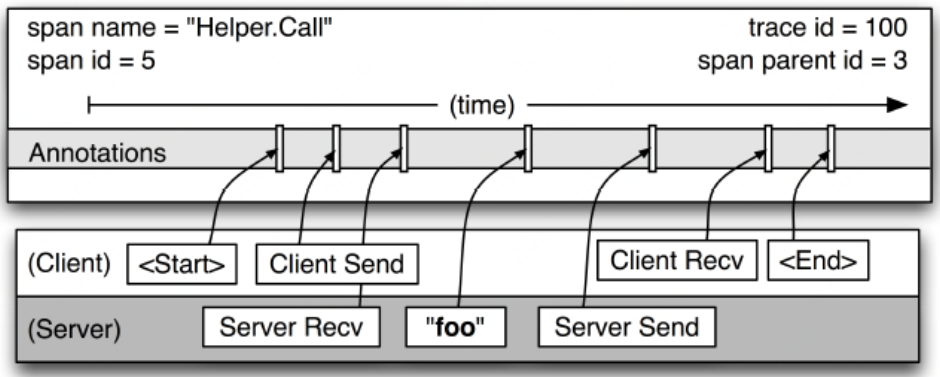
在Dapper 中分布式请求起码包含如下四个核⼼埋点阶段:
-
客户端发送 cs(Client Send):客户端发起请求时埋点,记录客户端发起请求的时间戳
-
服务端接收 sr(Server Receive):服务端接受请求时埋点,记录服务端接收到请求的时间戳
-
服务端响应 ss(Server Send):服务端返回请求时埋点,记录服务端响应请求的时间戳
-
客户端接收 cr(Client Receive):客户端接受返回结果时埋点,记录客户端接收到响应时的时间戳
通过这四个埋点信息,我们可以得到如下信息:
客户端请求服务端的网络耗时:sr-cs
服务端处理请求的耗时:ss-sr
服务端发送响应给客户端的网络耗时:cr-ss
本次请求在这两个服务之间的总耗时:cr-cs
以上这些埋点在 Dapper 中有个专业的术语,叫做 Annotation。如果 Dapper 论⽂中的图示你还没有看太懂的话,那么可以再看看下⾯这张图,⽐较清楚的展示出整个过程。
参考
Dapper论文:https://research.google/pubs/pub36356/
Dapper大规模分布式系统跟踪基础设施论文:https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36356.pdf
|








- 上一条: 一种异步延迟队列的实现方式 2023-03-21
- 下一条: 复杂度分析:如何分析、统计算法的执行效率和资源消耗 2023-03-21
- 分布式事务的十大神坑 2021-07-18
- 每一个程序员,都渴望成为一名分布式系统架构师 2021-07-11
- 灵活运用分布式锁解决数据重复插入问题 2021-07-27
- OpenHarmony HarmonyOS-面向全场景的分布式操作系统 2021-06-27
- Android 调用链——自动化精准测试 2021-11-19


