GPT-4问世;LLM训练指南;纯浏览器跑Stable Diffusion
1.多模态GPT-4正式发布:支持图像和文本输入,效果超越ChatGPT
OpenAI的里程碑之作GPT-4终于发布,这是一个多模态大模型(接受图像和文本输入,生成文本)。主要能力有:
-
GPT-4可以更准确地解决难题,具有更广泛的常识和解决问题的能力: 更具创造性和协作性;可以接受图像作为输入并生成说明文字、分类和分析;能够处理超过 25,000 个单词的文本,允许长文内容创建、扩展对话以及文档搜索和分析等用例。
-
GPT-4的高级推理能力超越了ChatGPT。
-
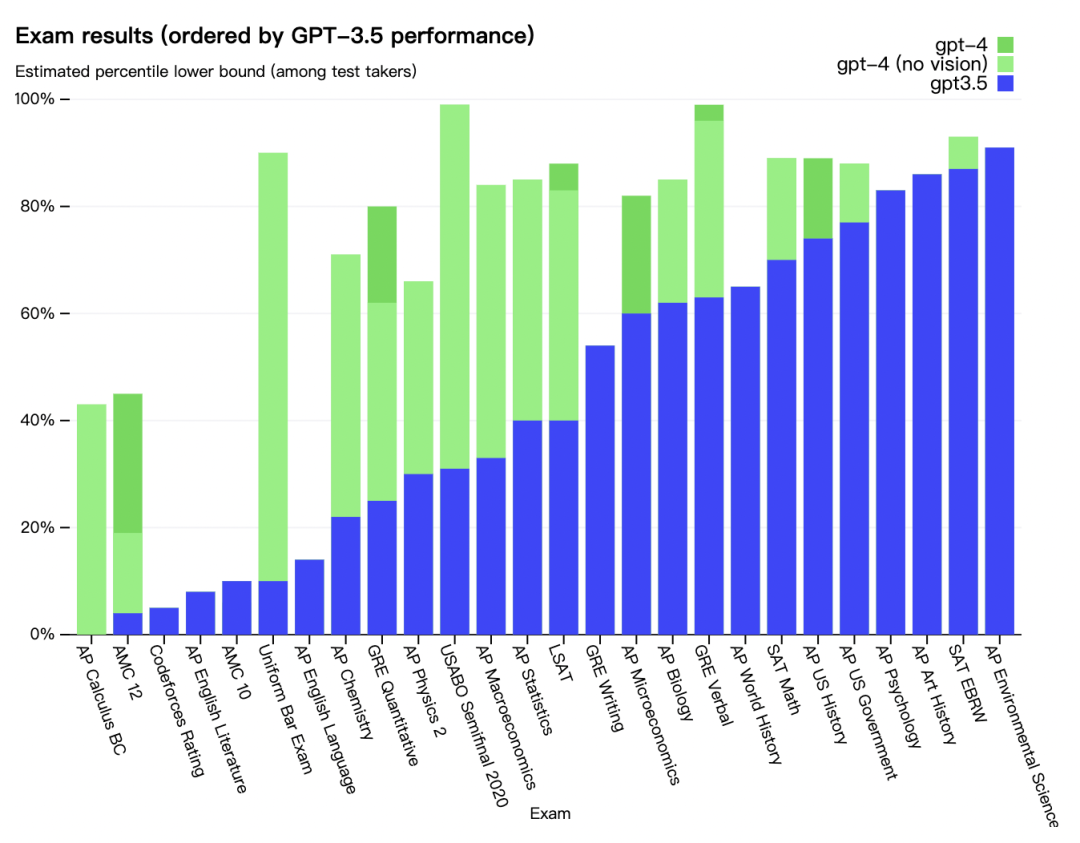
在SAT等绝大多数专业测试以及相关学术基准评测中,GPT-4的分数高于ChatGPT。

-
GPT-4遵循GPT、GPT-2和GPT-3的研究路径,利用更多数据和更多计算来创建越来越复杂和强大的语言模型(数据量和模型参数并未公布)。
-
OpenAI花了6个月时间使GPT-4更安全、更具一致性。 在内部评估中,与GPT-3.5相比,GPT-4对不允许内容做出回应的可能性降低82%,给出事实性回应的可能性高40%。
-
安全与对齐:引入了更多人类反馈数据进行训练,以改进GPT-4的行为;不断吸取现实世界使用的经验教训进行改进;GPT-4的高级推理和指令遵循能力加快的安全性研究工作。
OpenAI还开源了Evals框架(https://github.com/openai/evals),以自动评估AI模型性能,允许用户报告模型中的缺点,以帮助其改进。
OpenAI表示,GPT-4仍然有许多正在努力解决的已知局限性,例如社会偏见、幻觉和对抗性prompt。目前,OpenAI正在ChatGPT Plus上提供GPT-4,并为开发人员提供API以构建应用和服务。值得一提的是,微软的New Bing早就用上了GPT-4。
链接:
API申请:https://openai.com/waitlist/gpt-4-api;
https://openai.com/product/gpt-4;
https://mp.weixin.qq.com/s/kA7FBZsT6SIvwIkRwFS-xw
2. OpenAI发布通用人工智能路线图:AGI比想象中来得更快
在ChatGPT引爆科技圈之后,人们对于先进技术产生了更多期待,但一直有专家警告 AI 可能造成的危害。我们知道,OpenAI的使命是确保通用人工智能 —— 比人类更聪明的AI系统,能够造福全人类。近期,OpenAI发布了「AGI 路线图」,详细解释了这家前沿研究机构对通用人工智能研究的态度。
链接:
https://mp.weixin.qq.com/s/zu1a9p3nDTdk_lZ_-y8XFA
3. 超越ChatGPT:大模型的智能极限
在此前《 大型语言模型的涌现能力 》、《 ChatGPT进化的秘密 》两篇文章中,符尧剖析了大型语言模型的突现能力和潜在优势,大模型所带来的“潜在的”范式转变,并拆解了ChatGPT演进的技术路线图。
在本文中,作者以终为始分析了大模型的智能极限及其演进维度。不同于刻舟求剑式只追求复现ChatGPT的经典互联网产品思维,而是指出了OpenAI组织架构和尖端人才密度的重要性,更重要的是,分享了模型演化与产品迭代及其未来,思考了如何把最深刻、最困难的问题,用最创新的方法来解决。
链接:
https://mp.weixin.qq.com/s/PteNTHckNAP1iVq10JuONQ
4. 大型语言模型训练指南
近年来,训练越来越大的语言模型已成为常态(悟道2.0模型参数量已经到达1.75T ,为GPT-3的10倍)。但如何训练大型语言模型的信息却很少查到 。
链接:
https://zhuanlan.zhihu.com/p/611325149
5. 大模型的三个基础假设
1. 开源模型会大大降低准入门槛;2. 应用为王,模型为辅;3. 企业市场需要新的平台服务
链接:
https://mp.weixin.qq.com/s/jC-_B_arDpm1dsEmJLZYIw
6. GPT-3/ChatGPT复现的经验教训
为什么所有公开的对GPT-3的复现都失败了?我们应该在哪些任务上使用GPT-3.5或ChatGPT?对于那些想要复现一个属于自己的GPT-3或ChatGPT的人而言,第一个问题是关键的。第二个问题则对那些想要使用它们的人是重要的。
链接:
https://mp.weixin.qq.com/s/4B7wX0UhYjWGgozREa2b9w
7. ChatGPT搜索的推理成本分析
实际上,每周推理ChatGPT的成本都超过了其训练成本。目前ChatGPT每天的推理成本为700,000美元。如果直接将当前的ChatGPT集成到谷歌的每次搜索当中,那么谷歌的搜索成本将大幅上升,达到360亿美元。谷歌服务业务部门的年净收入将从2022年的555亿美元下降至195亿美元。若将“类ChatGPT”的LLM部署到搜索中,则意味着谷歌要将300亿美元的利润转移到计算成本上。
链接:
https://mp.weixin.qq.com/s/JHIUc_3nfnxv-m_4YUC1Tw
8. ChatGPT模型参数≠1750亿,有人用反证法进行了证明
本文将使用反证法来证明并支持上面的论点,只需要使用大学里学到的一些理论知识。另外需要注意,还存在相反的问题,即有人声称ChatGPT只有X亿个参数(X远远低于1750)。但是,这些说法无法得到验证,因为说这些话的人通常是道听途说。
链接:
https://mp.weixin.qq.com/s/lzIQ50GCKGEPu1Yzs-7FnQ
9. 从0到1,OpenAI的创立之路
最近,ChatGPT让国内不少精英再一次感受到落后的紧迫感,不少创业团队要打造“中国版的OpenAI”。我们不乏真正有抱负的创业者,但想象一下,如果在2015年已经有一支OpenAI团队,Sam Altman和Greg Brockman这群人很可能会去打造另一支不同于它的“DeepMind”团队,而不会称自己要去打造“硅谷版的OpenAI”,并且是为了复现ChatGPT。
链接:
https://mp.weixin.qq.com/s/E1_30D9Jw1XHBQnrrSh4NQ
10. 清华朱军团队开源首个基于Transformer的多模态扩散大模型
当前的扩散模型DALL・E 2、Imagen、Stable Diffusion等在视觉创作上掀起一场革命,但这些模型仅仅支持文到图的单一跨模态功能,离通用式生成模型还有一定距离。而多模态大模型将能够打通各种模态能力,实现任意模态之间转化,被认为是通用式生成模型的未来发展方向。
清华大学计算机系朱军教授带领的TSAIL团队近期公开的一篇论文《One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale》,率先发布了对多模态生成式模型的一些探索工作,实现了任意模态之间的相互转化。
链接:
https://mp.weixin.qq.com/s/B68hXlFxA9L5jiWiMrEEiA
11. 编译器技术的演进与变革
在现代计算机系统中,编译器已经成为一个必不可少的基础软件工具。程序员通过高级语言对底层硬件进行编程,而编译器则负责将高级语言描述转换为底层硬件可以执行的机器指令。编译器在将应用程序翻译到机器指令的过程中,还需要对程序进行等价变换,从而让程序能够更加高效地在硬件上执行。
链接:
https://mp.weixin.qq.com/s/wJxDPX-HwvhgnoksTXGyMg
12. AI开发大一统:谷歌OpenXLA开源,整合所有框架和AI芯片
如今,机器学习开发和部署受到碎片化的基础设施的影响,这些基础设施可能因框架、硬件和用例而异。这种相互隔绝限制了开发人员的工作速度,并对模型的可移植性、效率和生产化造成了障碍。通过创建与多种不同机器学习框架、硬件平台共同工作的统一机器学习编译器,OpenXLA可以加速机器学习应用的交付并提供更大的代码可移植性。
链接:
https://mp.weixin.qq.com/s/p8daMLluTQAEuj_HNzRA6Q
13. OpenAI Triton介绍
深度学习领域的新颖研究思想通常是使用原生框架运算符的组合来实现的。虽然方便,但这种方法通常需要创建许多临时张量,这可能会损害神经网络的大规模性能。这些问题可以通过编写专门的GPU内核来缓解,但由于GPU编程的许多复杂性,这样做可能会非常困难。
尽管最近出现了各种系统以简化此过程,但我们发现它们要么过于冗长、缺乏灵活性,要么生成代码的速度明显慢于我们手动调整的基线。因此,一种最新的语言和编译器由此就诞生了。
链接:
https://zhuanlan.zhihu.com/p/606435901
14. PyTorch显存分配原理:以BERT为例
为什么在nvidia-smi显示的显存和实际占用不一致?模型训练和推理显存分别占用多大?如何节约显存,提高显存利用率?Fp16有用吗?可以节省多少显存?如何估算模型占用大小?这篇文章将会解决这些问题。
链接:
https://zhuanlan.zhihu.com/p/527143823
15. OneFlow源码解析:Eager模式下的SBP Signature推导
SBP是OneFlow中独有的概念,其描述了张量逻辑上的数据与张量在真实物理设备集群上存放的数据之间的一种映射关系。SBP Signature即SBP签名,是OneFlow中独创且很重要的概念。
链接:
https://mp.weixin.qq.com/s/E2pL7OnMhcHjISJ_jcs9rA
16. 面向Web的机器学习编译突破:纯浏览器运行Stable Diffusion
本文介绍了Web Stable Diffusion。这是世界上的第一个通过深度学习编译技术将 stable diffusion 完全运行在浏览器中的项目。模型的全部一切都运行在浏览器里,无需云端服务器支持。
链接:
https://zhuanlan.zhihu.com/p/612517660
17. YOLOv5全面解析教程④:目标检测模型精确度评估
链接:
https://mp.weixin.qq.com/s/nvfAU6TwTDoZhF8zFpCaOw
其他人都在看
欢迎Star、试用OneFlow: github.com/Oneflow-Inc/oneflow/

本文分享自微信公众号 - OneFlow(OneFlowTechnology)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
|








- 上一条: 基于声网 Flutter SDK 实现互动直播 2023-03-17
- 下一条: GPT-4问世;LLM训练指南;纯浏览器跑Stable Diffusion 2023-03-17
- 35张图,直观理解Stable Diffusion 2023-01-31
- “零”代码改动,静态编译让太乙Stable Diffusion推理速度翻倍 2023-01-30
- Diffusion预训练成本降低6.5倍,微调硬件成本降低7倍!Colossal-AI完整开源方案低成本加速AIGC产业落地 2022-11-09
- 阿里云PAI-Diffusion功能再升级,全链路支持模型调优,平均推理速度提升75%以上 2023-02-08
- 刷新最快AI做图速度,最快开源Stable Diffusion出炉 2022-12-02


