InstructPix2Pix: 动动嘴皮子,超越PS
摘要:InstructPix2Pix提出了一种使用文本编辑图像的方法:给定输入图像和编辑指令,告诉模型要做什么,模型将遵循这些指令来编辑图像。
本文分享自华为云社区《InstructPix2Pix: 动动嘴皮子,超越PS》,作者:杜甫盖房子。
InstructPix2Pix: Learning to Follow Image Editing Instructions
InstructPix2Pix提出了一种使用文本编辑图像的方法:给定输入图像和编辑指令,告诉模型要做什么,模型将遵循这些指令来编辑图像,如:

我们在ModelArts中发布了一个notebook方便大家玩一玩,同时也将对模型的实现方法进行简单介绍:

方法概览
在InstructPix2Pix中,作者通过有监督的方法来实现文本编辑图像。方法主要包括两部分:
- 数据集生成:作者整合了语言模型GPT-3和文生图模型Stable Diffusion,生成了一个用于图像编辑的数据集;
- 模型训练:作者使用生成的数据集训练了一个条件扩散模型来实现文本编辑图像:

在推理时,图像在模型forward过程中被编辑,不需要微调,因此推理速度很快,可玩性较高。
数据准备
在数据准备时,首先通过GPT-3生成一些文本编辑指令,之后通过Stable Diffusion和Prompt-to-Prompt生成编辑前后文本图像对。
生成文本编辑指令
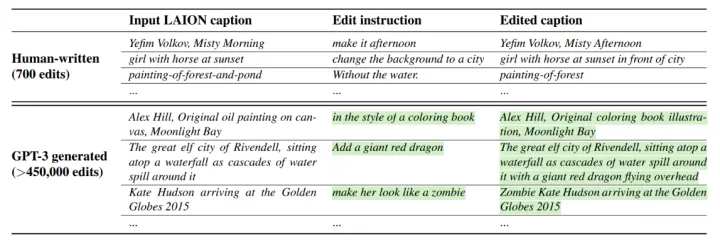
作者使用了700条人工标注的文本编辑指令三元组微调GPT-3,之后使用微调过的GPT-3生成大规模的文本三元组。如下图,文本三元组包括(1)输入描述;(2)编辑指令;(3)编辑后的描述。
在使用GPT-3生成数据集时只需提供输入描述,高亮的编辑指令与输出描述都由GPT-3生成,这样可以保证描述指令的多样性。
生成图像对
在得到描述对后,作者使用Stable Diffusion将编辑前与编辑后的描述转换成图像对。在这个过程中面临了一个挑战:即使输入提示只有微小的不同,生成的图像也无法保证内容的一致性,如分别使用“photograph of a girl riding a horse”和“photograph of a girl riding a dragon”为提示生成图像,会得到下图内容:

为了解决此问题,作者使用了Prompt-to-Prompt方法。该方法通过在扩散过程中注入原始图像的注意力图来控制编辑图像的注意力映射,实现了内容一致的图像生成。使用该方法与相同的提示词,会得到下图内容:

作者共生成 454,445 个样本,生成的数据可以通过开源脚本下载。
条件扩散模型
InstructPix2Pix通过训练条件扩散模型来实现根据输入图像和文本指令来编辑图像的功能。作者使用预训练的Stable Diffusion对模型进行初始化,同时在第一个卷积层增加了额外的条件通道来支持图像编辑。在训练时模型将输入图像xx编码为隐向量z=E(x)z=E(x),在扩散过程中将噪声tt添加到编码向量zz中得到隐噪声变量ztzt,其中噪声等级随时间提升。
训练一个网络ϵθϵθ来预测在给定的图像条件cIcI和文本指令cTcT下的噪声tt,目标函数:
为了平衡扩散模型生成的样本的质量和多样性,作者在InstructPix2Pix中引入了Classifier-free Guidance方法。当我们使用一个条件来生成图像时,我们希望生成的图像与该条件有较高的相关性,Classifier-free Guidance利用一个隐式分类器 pθ(c∣zt)pθ(c∣zt) 来对生成的样本进行评分。其中,ztzt是一个编码图像的潜在表示,cc是一个条件,可以是一个文本描述或者其他图像。这个分类器会对每个样本分配一个相应的分数,表示该样本与给定条件的相关性。训练时,会通过噪声引导使概率偏向那些隐式分类器得分高的数据点上,从而提高生成的样本与给定条件的相关性。
对于文本编辑图像任务,作者设计了评分网络 eθ(zt,cI,cT)eθ(zt,cI,cT),对于图像条件cIcI和文本指令cTcT设计了指导尺度sIsI和sTsT,可以调整网络对输入图像和编辑指令的遵循程度:
针对不同的指导尺度作者给出了示例实验结果:

更多实验结果与局限性讨论可以在Project Page中查看。
案例介绍
上文提到,为了方便大家玩一玩,我们ModelArts中发布了一键运行的notebook,除了可以免去复杂的环境适配步骤外,还可以享受免费GPU资源
开源模型下载好慢好慢,体贴的我也为大家将资源转存到OBS中:
此外,预训练模型只支持英文,哪里有英语废,哪里就有翻译,翻译模型也准备好了,惊不惊喜,意不意外:
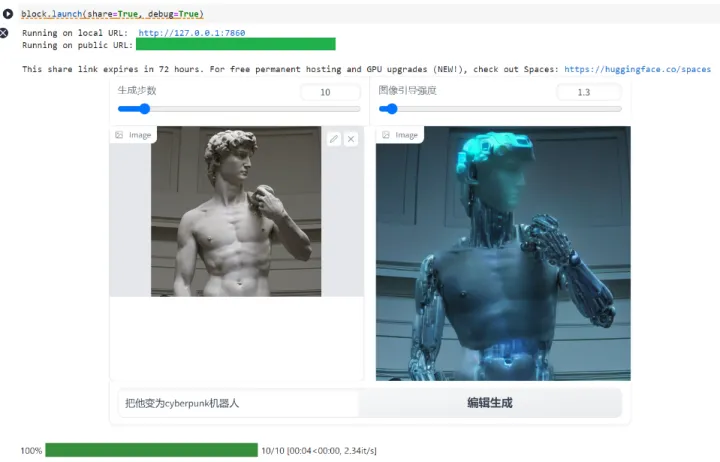
案例使用gradio搭建了一个小小的应用,一键运行后直接在应用框输入图片与中文编辑命令生成结果即可:
使用结束后不要忘记关闭哦:
|








- 上一条: GPT-4 来了!这些开源的 GPT 应用又要变强了 2023-03-17
- 下一条: 带你掌握如何查看并读懂昇腾平台的应用日志 2023-03-17
- 组图:杨超越扎双马尾俏皮灵动 天真烂漫充满青春活力 2021-08-29
- ModelBox姿态匹配:抖抖手动动脚勤做深呼吸 2022-11-03
- 华为云企业级Redis揭秘第16期:超越开源Redis的ACID"真"事务 2022-02-21
- vue3,对比 vue2 有什么优点? 2021-09-16
- 第2章 计算机系统的硬件·2.5 计算机的整机结构 2021-07-10


