JRC Flink流作业调优指南
作者:京东物流 康琪
本文综合Apache Flink原理与京东实时计算平台(JRC)的背景,详细讲述了大规模Flink流作业的调优方法。通过阅读本文,读者可了解Flink流作业的通用调优措施,并应用于生产环境。
写在前面
Apache Flink作为Google Dataflow Model的工业级实现,经过多年的发展,如今已经成为流式计算开源领域的事实标准。它具有高吞吐、低时延、原生流批一体、高一致性、高可用性、高伸缩性的特征,同时提供丰富的层级化API、时间窗口、状态化计算等语义,方便用户快速入门实时开发,构建实时计算体系。
古语有云,工欲善其事,必先利其器。要想让大规模、大流量的Flink作业高效运行,就必然要进行调优,并且理解其背后的原理。本文是笔者根据过往经验以及调优实践,结合京东实时计算平台(JRC)背景产出的面向专业人员的Flink流作业调优指南。主要包含以下四个方面:
- TaskManager内存模型调优
- 网络栈调优
- RocksDB与状态调优
- 其他调优项
本文基于Flink 1.12版本。阅读之前,建议读者对Flink基础组件、编程模型和运行时有较深入的了解。
*01 TaskManager内存模型调优
1.1 TaskManager内存模型与参数
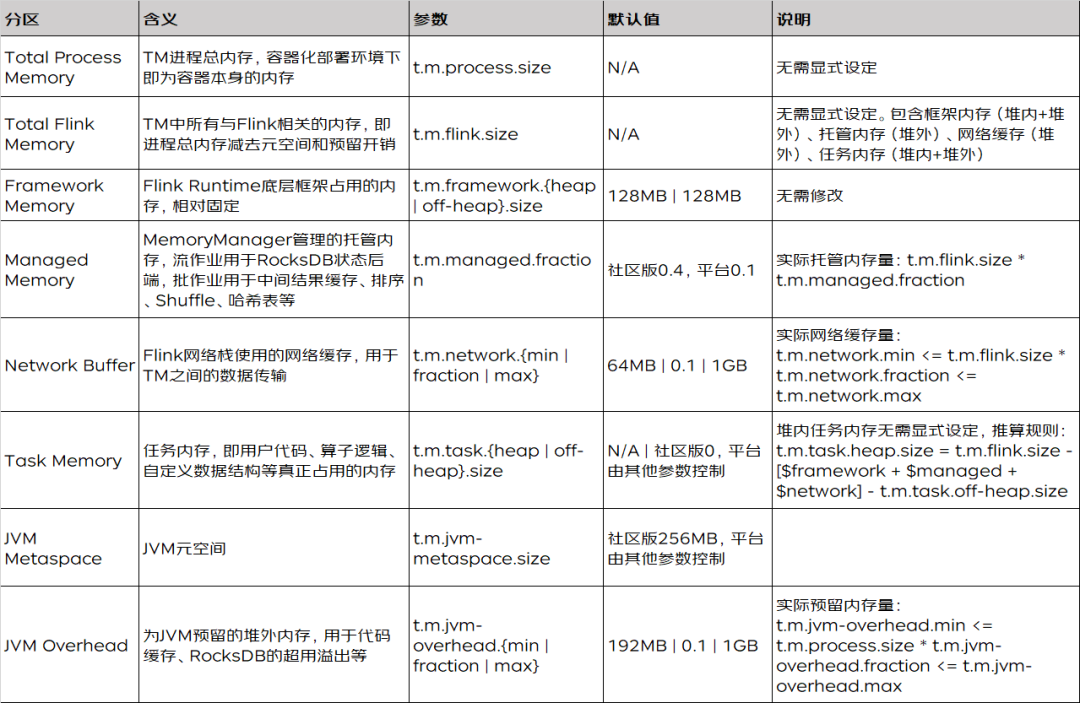
目前的Flink TaskManager内存模型是1.10版本确定下来的,官方文档中给出的图示如下。在高版本Flink的Web UI中,也可以看到这张图。

图1 TaskManager内存模型
下面来看图说话,分区域给出比官方文档详细一些的介绍。t.m.即为taskmanager. memory.前缀的缩写。
1.2 平台特定参数
除了TaskManager内存模型相关的参数之外,还有一些平台提供的其他参数,列举如下。

1.3 TM/平台参数与JVM的关系
上述参数与TaskManager JVM本身的参数有如下的对应关系:
- -Xms | -Xmx → t. m. framework. heap. size + t. m. task. heap. size
- -Xmn → -Xmx * apus. taskmanager. heap. newsize. ratio
- -XX: Max Direct Memory Size → t. m. framework. off- heap. size + t. m. task. off- heap. size + $network
- -XX: Max Metaspace Size → t. m. jvm- metaspace. size
另外,还可以通过env.java.opts.{jobmanager | taskmanager}配置项来分别设定JM和TM JVM的附加参数。
1.4 内存分配示例
下面以在生产环境某作业中运行的8C / 16G TaskManager为例,根据以上规则,手动计算各个内存分区的配额。注意有部分参数未采用默认值。
t.m.process.size = 16384
t.m.flink.size
= t.m.process.size * apus.memory.incontainer.available.ratio
= 16384 * 0.9 = 14745.6
t.m.jvm-metaspace.size
= [t.m.process.size - t.m.flink.size] * apus.metaspace.incutoff.ratio
= [16384 - 14745.6] * 0.25 = 409.6
$overhead
= MIN{t.m.process.size * t.m.jvm-overhead-fraction, t.m.jvm-overhead.max}
= MIN{16384 * 0.1, 1024} = 1024
$network
= MIN{t.m.flink.size * t.m.network.fraction, t.m.network.max}
= MIN{14745.6 * 0.3, 5120} = 4423.68
$managed
= t.m.flink.size * t.m.managed.fraction
= 14745.6 * 0.25 = 3686.4
t.m.task.off-heap.size
= t.m.flink.size * apus.taskmanager.memory.task.off-heap.fraction
= 14745.6 * 0.01 = 147.4
t.m.task.heap.size
= t.m.flink.size - $network - $managed - t.m.task.off-heap.size - t.m.framework.heap.size - t.m.framework.off-heap.size
= 14745.6 - 4423.68 - 3686.4 - 147.4 - 128 - 128 = 6232.12
与Web UI中展示的内存配额做比对,可发现完全吻合。
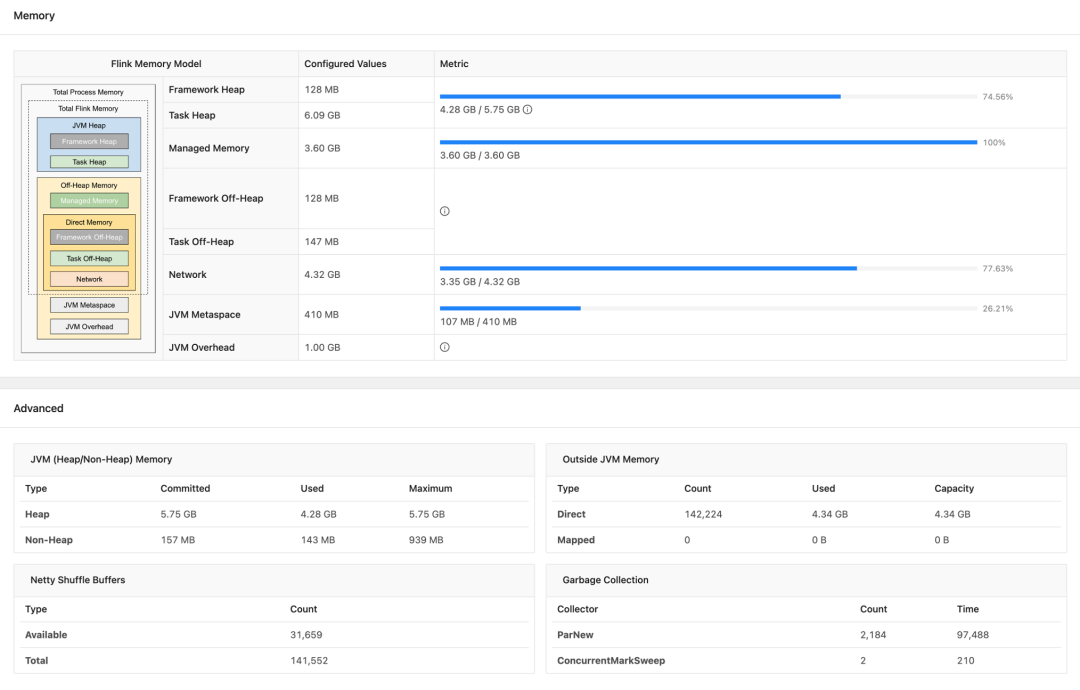
图2 Web UI展示的内存分配情况
1.5 调优概览
理解TaskManager内存模型是开展调优的大前提,进行调优的宗旨就是:合理分配,避免浪费,保证性能。下面先对比较容易出现问题的三块区域做简要的解说。
1.关于任务堆外内存
平台方的解释是有些用户的作业需要这部分内存,但从Flink Runtime的角度讲,主要是批作业(如Sort-Merge Shuffle过程)会积极地使用它。相对地,流作业很少涉及这一部分,除非用户代码或用户引用的第三方库直接操作了DirectByteBuffer或Unsafe之类。所以一般可以优先保证堆内存,即尝试将
apus.t.m.task.off-heap.fraction再调小一些(如0.05),再观察作业运行是否正常。
2.关于托管内存
如果使用RocksDB状态后端,且状态数据量较大或读写较频繁,建议适当增加t.m.managed.fraction,如0.2~0.5,可配合RocksDB监控决定。如果不使用RocksDB状态后端,可设为0,因为其他状态后端下的本地状态会存在TaskManager堆内存中。后文会详细讲解RocksDB相关的调优项。
3.关于网络缓存
需要特别注意的是,网络缓存的占用量与并行度和作业拓扑有关,而与实际网络流量关系不大,所以不能简单地以作业的数据量来设置这一区域。粗略地讲,对简单拓扑,建议以默认值启动作业,再观察该区域的利用情况并进行调整;对复杂拓扑,建议先适当调大t.m.network.fraction和max,保证不出现IOException: Insufficient number of network buffers异常,然后再做调整。另外,请一定不要把t.m.network.min和max设成相等的值,这样会直接忽略fraction,而这种直接的设定往往并不科学。下一节就来详细讲解Flink网络栈的调优。
02 网络栈调优
2.1 网络栈和网络缓存

图3 Flink网络栈
Flink的网络栈构建在Netty的基础之上。如上图所示,每个TaskManager既可以是Server(发送端)也可以是Client(接收端),并且它们之间的TCP连接会被复用,以减少资源消耗。
图中的小色块就是网络缓存(NetworkBuffer),它是数据传输的最基本单位,以直接内存的形式分配,承载序列化的StreamRecord数据,且一个Buffer的大小就等于一个MemorySegment的大小(t.m.segment-size,默认32KB)。TM中的每个Sub-task都会创建网络缓存池(NetworkBufferPool),用于分配和回收Buffer。下面讲解一下网络缓存的分配规则。
2.2 网络缓存分配规则
Flink流作业的执行计划用三层DAG来表示,即:StreamGraph(逻辑计划)→ JobGraph(优化的逻辑计划)→ ExecutionGraph(物理计划)。当ExecutionGraph真正被调度到TaskManager上面执行时,形成的是如下图所示的结构。
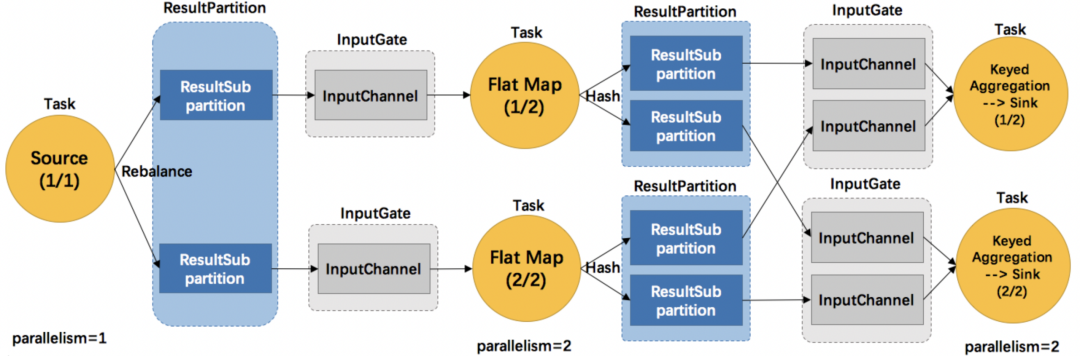
图4 Flink物理执行图结构
每个Sub-task都有一套用于数据交换的组件,输出侧称为ResultPartition(RP),输入侧称为InputGate(IG)。另外,它们还会根据并行度和上下游的DistributionPattern(POINTWISE或ALL_TO_ALL)划分为子块,分别称为ResultSubpartition(RS)和InputChannel(IC)。注意上下游RS和IC的比例是严格1:1的。网络缓存就是在ResultPartition和InputGate级别分配的,具体的分配规则是:
- #Buffer-RP = #RS + 1 && #Buffer-RS <= t.network.m.max-buffers-per-channel (10)
- #Buffer-IG = #IC * t.network.m.buffers-per-channel (2, exclusive) + t.network.m.floating-buffers-per-gate (8, floating)
<!---->
翻译一下:
- 发送端RP分配的Buffer总数为RS的数量+1,且为了防止倾斜,每个RS可获得的Buffer数不能多于taskmanager.network.memory.max-buffers-per-channel(默认值10);
- 接收端每个IC独享的Buffer数为taskmanager. network. memory. buffers- per- channel(默认值2),IG可额外提供的浮动Buffer数为taskmanager. network. memory. floating- buffers- per- gate(默认值8)。
多说一句,上图这套机制也是Flink实现Credit-based流控(反压)的基础,想想诊断反压时会看的**PoolUsage参数就明白了。反压是比较基础的话题,这里就不再展开。
再重复上一节的那句话:网络缓存的占用量与并行度和作业拓扑有关,而与实际网络流量关系不大。特别地,由于ALL_TO_ALL分布(如Hash、Rebalance)会产生O(N^2)级别的RS和IC,所以对Buffer的需求量也就更大。当然,我们基本不可能通过用肉眼看复杂的拓扑图来计算Buffer数,所以最好的方法是快速试错,来看一个例子。
2.3 网络缓存调优示例
本节以测试环境中的某作业(下称“示例作业”)为例。
该作业有54个8C / 16G规格的TM,并行度400,运行4330个Sub-tasks,且包含大量的keyBy操作。初始设定t.m.network.fraction = 0.2 & t.m.network.max = 3GB,报IOException: Insufficient network buffers异常;再次设定t.m.network.fraction = 0.3 & t.m.network.max = 5GB,作业正常启动,实际分配4.32GB,占用率73%~78%之间浮动(参见之前的Web UI图)。这个分配情况相对于原作业的fraction = 0.5 & min = max = 8GB显然是更优的。
有的同学可能会问:空闲的Network区域内存不能挪作他用吗?答案是否定的。在作业启动时,Network区域的全部内存都会初始化成Buffer,并按上一节所述的配额分配到RP和IG,Web UI中Netty Shuffle Buffers → Available一栏的Buffer基本可以认为被浪费了。所以,当作业遇到瓶颈时,盲目增大网络缓存对吞吐量有害无益。
2.4 容易忽略的缓存超时
网络缓存在发送端被Flush到下游有三种时机:Buffer写满、超时时间到、遇到特殊标记(如Checkpoint Barrier)。之所以要设计缓存超时,是为了避免Buffer总是无法写满导致下游处理延迟。可以通过 StreamExecutionEnvironment#setBufferTimeout方法或者execution.buffer-timeout参数来设置缓存超时,默认100ms,一般无需更改。

图5 缓存的填充与发送
但是,考虑大并行度、大量ALL_TO_ALL交换的作业,数据相对分散,每个ResultSubpartition的Buffer并不会很快填满,大量的Flush操作反而会无谓地占用CPU。此时可以考虑适当增大缓存超时,降低Flush频率,能够有效降低CPU Usage。以前述作业为例,将缓存超时设为500ms,其他参数不变,稳定消费阶段TM的平均CPU Usage降低了40%,效果拔群。当然这仍是以下游延迟作为trade-off的,故时效性极敏感的作业不适用于此优化。
2.5 网络容错
平台采用Flink on Kubernetes的部署方式,但是Kubernetes网络虚拟化(Calico、Flannel等)会损失网络性能,故对于大流量或复杂作业,务必提高网络容错性。以下是三个相关的参数。
1.taskmanager.network.request-backoff.max
默认值10000(社区版)/ 60000(平台),表示下游InputChannel请求上游ResultSubpartition的指数退避最大时长,单位为毫秒。如果请求失败,会抛出
PartitionNotFoundException: Partition xx@host not found,应适当调大,如240000。注意此报错与Kafka Partition无关,切勿混淆。
2.akka.ask.timeout
默认值10s(社区版)/ 60s(平台),表示Akka Actor的Ask RPC等待返回结果的超时。如果网络拥塞或者拓扑过于复杂,就会出现AskTimeoutException: Ask timed out on Actor akka://xx after xx ms的信息,应调大此值,如120s。注意长时间GC也可能导致此问题,留心排查。
3.heartbeat.timeout
默认值50000,表示JobManager和TaskManager之间心跳信号的发送/接收超时,单位为毫秒。与akka.ask.timeout同理,若出现TimeoutException: Heartbeat of TaskManager with id xx timed out,建议适当调大。
03 RocksDB与状态调优
3.1 Flink中的FRocksDB
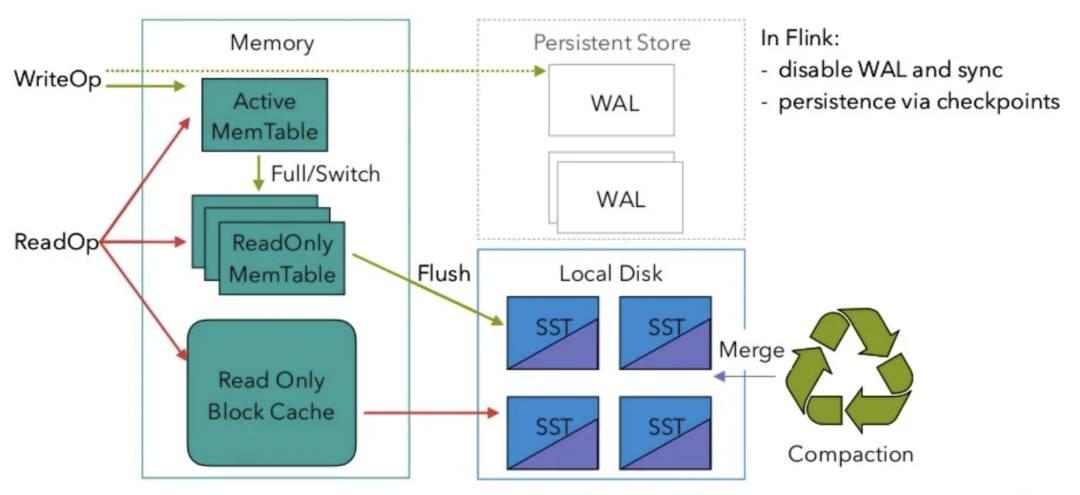
图6 FRocksDB读写流程
Flink RocksDB状态后端采用的是名为FRocksDB的分支版本,由Ververica维护。它的读写流程与原版基本相同,如上图所示,MemTable和BlockCache分别就是读写缓存和读缓存。特别地,由于Flink在每个Checkpoint周期都会将RocksDB的数据快照持久化到文件系统,所以不需要写预写日志(WAL)。
TM中的每个Slot都拥有一个RocksDB实例,且传统方式下每个列族(CF)都对应一套MemTable、BlockCache和SST。而在Flink作业中申请的一个StateHandle——即Runtime Context# get... State (State Descriptor) ——就对应一个取StateDescriptor名称的列族。显然,同一作业内StateDescriptor的名称不能重复。
3.2 RocksDB托管内存机制
上述传统方式有个明显的缺点,即RocksDB的内存几乎不受控(因为Flink并不限制用户能申请多少个StateHandle)。因此,Flink在1.10版本借助RocksDB 5.6+提出的WriteBufferManager和LRUCache协同机制,实现了全托管的RocksDB内存管理,如下图所示。

图7 全托管RocksDB内存管理
托管内存机制默认启用(state. backend. rocksdb. memory. managed = true),此时TM会将整块Managed Memory区域作为所有RocksDB实例共用的BlockCache,并通过WriteBufferManager将MemTable的内存消耗向BlockCache记账(即写入只有size信息的dummy块),从而BlockCache能够感知到全部的内存使用并施加限制,避免OOM发生。SST索引和Bloom Filter块则会进入BlockCache的高优先级区。需要注意,由于历史原因以及Iterator-pinned Blocks的存在,BlockCache在少数情况下不能严格限制内存,故有必要配置一些JVM Overhead作为兜底。
托管内存默认在各个Slot之间平均分配,用户也可以通过
s.b.r.memory.fixed-per-slot参数来为每个Slot手动设定托管内存配额,但一般不推荐。除此之外,可调整的两个参数如下。
- s.b.r.memory.write-buffer-ratio:MemTable内存占托管内存的比例,默认值0.5;
<!---->
- s.b.r.memory.high-prio-pool-ratio:高优先级区内存占托管内存的比例,默认值0.1。
剩余的部分(默认0.4)就是留给数据BlockCache的配额。用户一般不需要更改它们,若作业状态特别重读或重写,可适当调整,但必须先保证托管内存充足。
3.3 其他RocksDB参数
**
1.s.b.r.checkpoint.transfer.thread.num(默认1)**
每个有状态算子在Checkpoint时传输数据的线程数,增大此值会对网络和磁盘吞吐量有更高要求。一般建议4~8,1.13版本中默认已改为4。
**
2.s.b.r.timer-service.factory(社区版默认ROCKSDB,平台默认HEAP)**
Timer相关状态存储的位置,包含用户注册的Timer和框架内部注册的Timer(如Window、Trigger)。若存储在堆中,则Timer状态做CP时无法异步Snapshot,所以Timer很多的情况下存在RocksDB内更好。但美中不足的是,设置为ROCKSDB会有一个极偶发的序列化bug,导致无法从Savepoint恢复状态,若不能接受,建议HEAP。
**
3.s.b.r.predefined-options(默认DEFAULT)**
社区提供的预设RocksDB调优参数集,有4种:DEFAULT、SPINNING_DISK_OPTIMIZED、
SPINNING_DISK_OPTIMIZED_HIGH_MEM、FLASH_SSD_OPTIMIZED(名称都很self-explanatory)。该参数容易忽略,但强烈建议设置,比起默认值均有不错的性能收益。若单个Slot的状态量达到GB级别,且托管内存充裕,设为SPINNING_DISK_OPTIMIZED_HIGH_MEM最佳。其他情况设为SPINNING_DISK_OPTIMIZED即可。
除了上述参数之外,原则上建议遵循RocksDB Wiki的忠告("No need to tune it unless you see an obvious performance problem"),不再手动调整RocksDB高级参数(如s.b.r.{block | writebuffer | compaction}.*),除非出现了托管内存机制无法解决的问题。笔者也将部分高级参数列出如下,供参考。
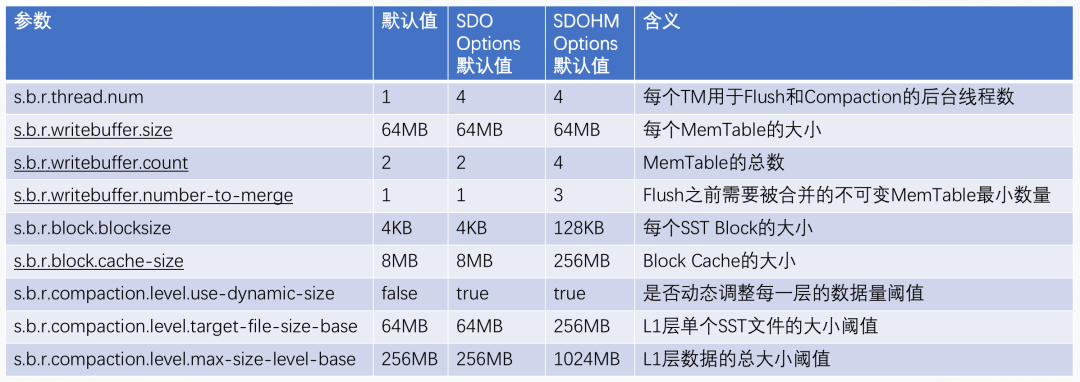
图8 RocksDB高级参数
注意划线的项会被托管内存机制覆盖掉。如果经过慎重思考,必须fine tune RocksDB,则需要将s.b.r.memory.managed设为false,同时用户要承担可能的OOM风险。
3.4 RocksDB监控 & 调优示例
在大状态作业正式上线之前,应打开一部分必要的RocksDB监控,观察是否有性能瓶颈。开启监控对状态读写性能有一定影响,一般建议如下6项:
- s.b.r.metrics.{block-cache-capacity | block-cache-usage | cur-size-all-mem-tables | mem-table-flush-pending | num-running-flushes | num-running-compactions} = true
观察完毕并解决问题后,请务必关闭它们。
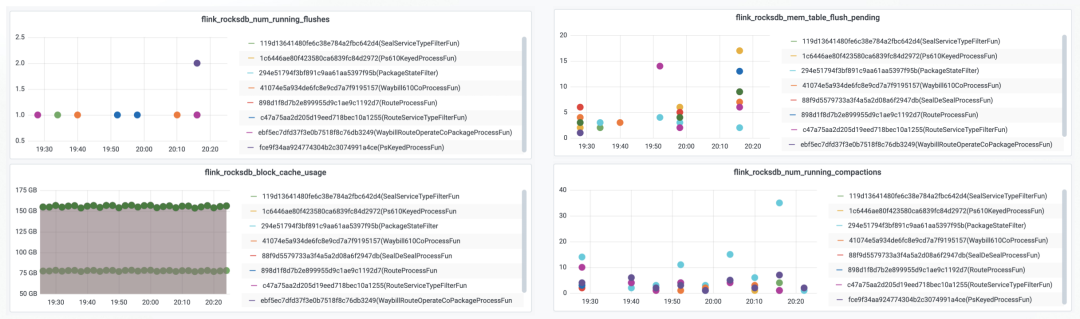
图9 示例作业RocksDB监控
上图是示例作业的部分RocksDB Metrics图表,比较正常。如果在稳定消费阶段,Flush和Compaction等重量级操作特别频繁,以至于图中的点连成线,一般就提示RocksDB遇到了瓶颈。但是托管内存(即BlockCache)占用100%是正常现象,基本不必担心。
作为参考,该作业的增量Checkpoint大小在15G左右,每日摄入数十亿条状态数据,设置参数为:t. m. managed. fraction = 0.25(实际分配托管内存3.6G),s. b. r. predefined- options = SPINNING_ DISK_ OPTIMIZED,s. b. r. checkpoint. transfer. thread. num = 8。表现良好。而调优前作业的t. m. managed. fraction是默认的0.1,并且还对RocksDB高级参数做了一些无谓的修改,性能表现不佳。
3.5 状态TTL
RocksDB的状态TTL需要借助CompactionFilter实现,如下图所示。
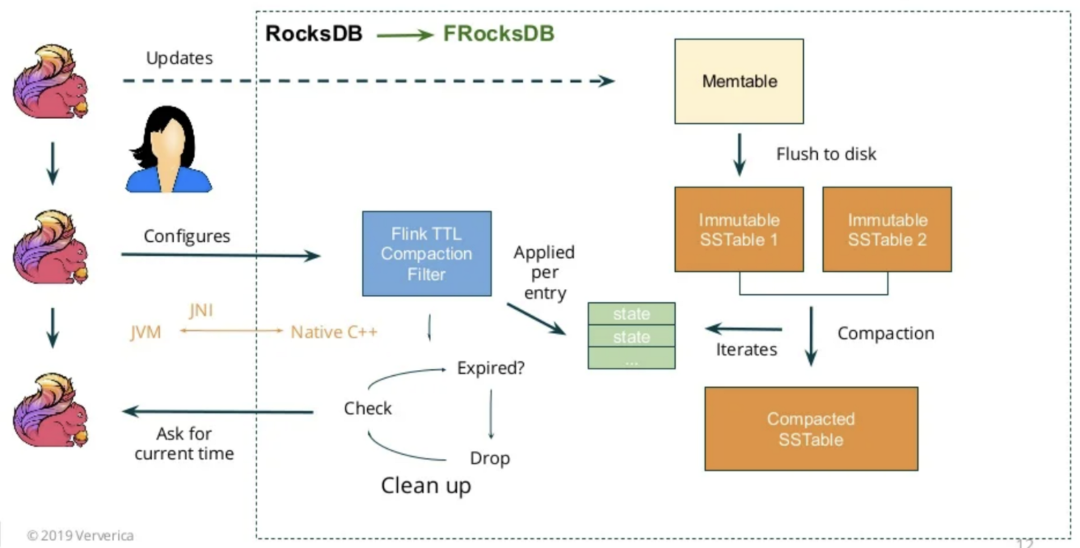
图10 状态TTL原理
用户调用State Ttl Config# cleanupIn Rocksdb Compact Filter (N)方法,就可以设定在访问状态N次后,更新CompactionFilter记录的时间戳。当SST执行Compaction操作时,会根据该时间戳检查状态键值对是否过期并删除掉。注意若访问状态非常频繁,N值应适当调大(默认仅为1000),防止影响Compaction性能。
3.6 状态缩放与最大并行度
当作业的并行度改变并从CP / SP恢复时,就会涉及状态缩放的问题。Flink内Keyed State数据以KeyGroup为单位组织,每个key经过两重Murmur Hash计算出它应该落在哪个KeyGroup中,同时每个Sub-task会分配到一个或多个KeyGroup。如下图所示,并行度变化只会影响KeyGroup的分配,可以将状态恢复的过程近似化为顺序读,提高效率。
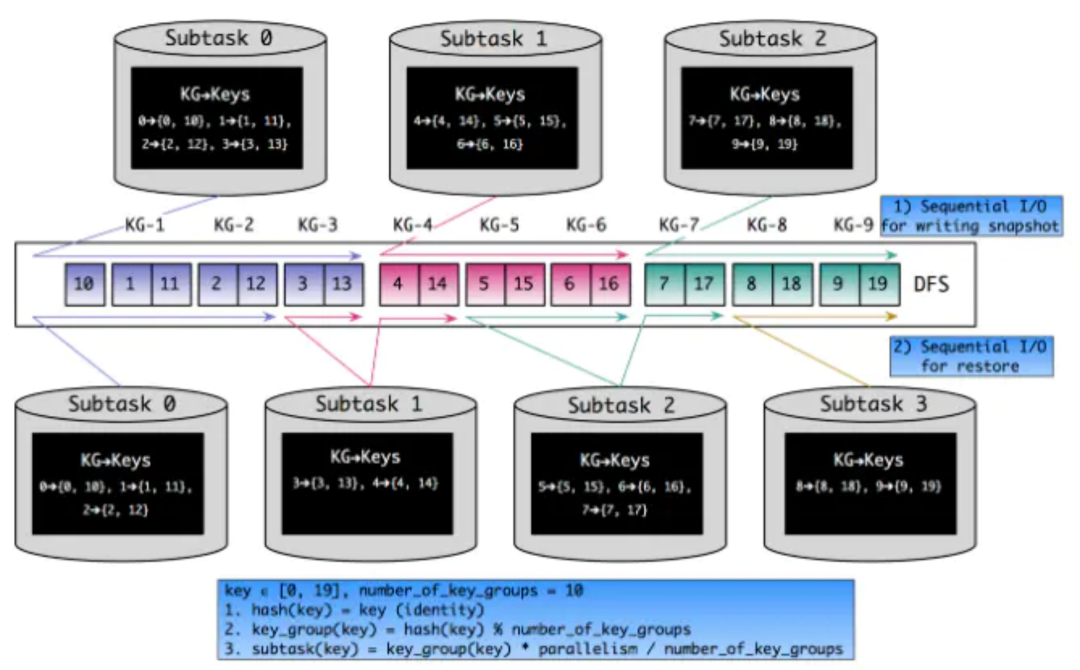
图11 Keyed State的缩放
KeyGroup的数量与最大并行度相同,而最大并行度改变会导致作业无法从CP / SP恢复,所以要谨慎设定。如果用户没有显式设置,就会根据以下规则来推算:
128 <= round Up To Power Of Two (operator Parallelism * 1.5) <= 32768
显然这并不安全。假设一个作业的并行度是200,推算的最大并行度是512;若将其并行度提升至400,推算的最大并行度就会变成1024。所以总是推荐显式设置合理的最大并行度。
3.7 状态本地恢复
状态本地恢复默认关闭,可以通过设置
state.backend.local-recovery = true启用,但它只能作用于Aligned Checkpoint和Keyed State。启用后,每次CP产生两份快照:Primary(远端DFS)和Secondary(本地磁盘),且Secondary CP失败不会影响整个CP流程。作业恢复时,首先尝试从有效的Secondary快照恢复状态,能显著提高恢复速度。如果Secondary快照不可用或不完整,再fallback到Primary恢复。如下图所示。

图12 状态本地恢复
状态本地恢复会引入额外的磁盘消耗:非增量CP会导致磁盘占用量翻倍;增量CP由于原生存在引用计数机制,不会多消耗空间,但因为数据比较分散,IOPS会相应增加。
04 其他调优项
4.1 Checkpoint相关
读者应该很熟悉Checkpoint相关的配置项了,这里只提两点:一是checkpointTimeout根据作业特性设置,但不要过长,防止CP卡死掩盖作业本身的问题(如数据倾斜);二是一定要设置
minPauseBetweenCheckpoints,避免算子一直处在CP过程中导致性能下降。示例作业的设置是:checkpointInterval = 3min / checkpointTimeout = 15min / minPauseBetweenCheckpoints = 1min。
另外,在大状态作业中碰到一种常见的现象,即Checkpoint全部ack之后卡在IN_PROGRESS,经过1~3分钟左右才会变成COMPLETED,如下图所示。
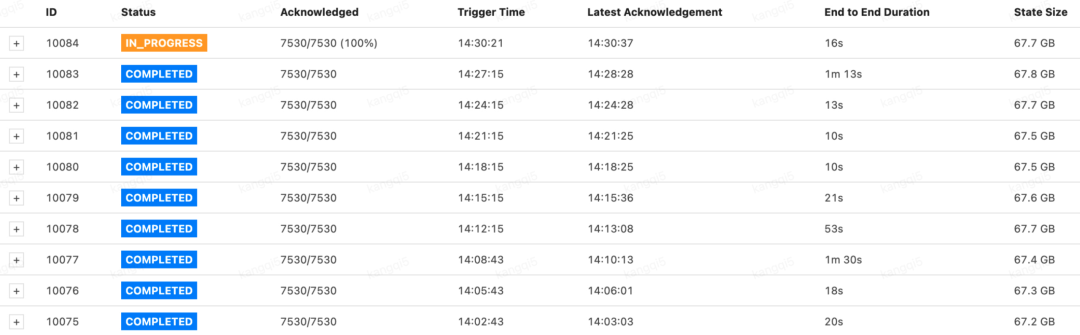
图13 Checkpoint卡在IN_PROGRESS状态的现象
这是因为TaskManager和HDFS之间通信不畅,或者是HDFS本身的压力导致数据块写入失败。而Flink必须保证Checkpoint的完整性,即重试到所有快照数据都成功写入才能标记为COMPLETED。读者可在TM日志中发现形如Exception in createBlockOutputStream: Connect timed out的异常信息。
4.2 对象重用
对象重用在Flink配置中不是很起眼,但却相当有用。Flink在生成JobGraph时会将符合一定条件的算子组合成算子链(OperatorChain),所有chain在一起的Sub-task都会在同一个TM Slot中执行。而对象重用的本质就是在算子链内的下游算子中直接使用上游算子发射对象的浅拷贝。
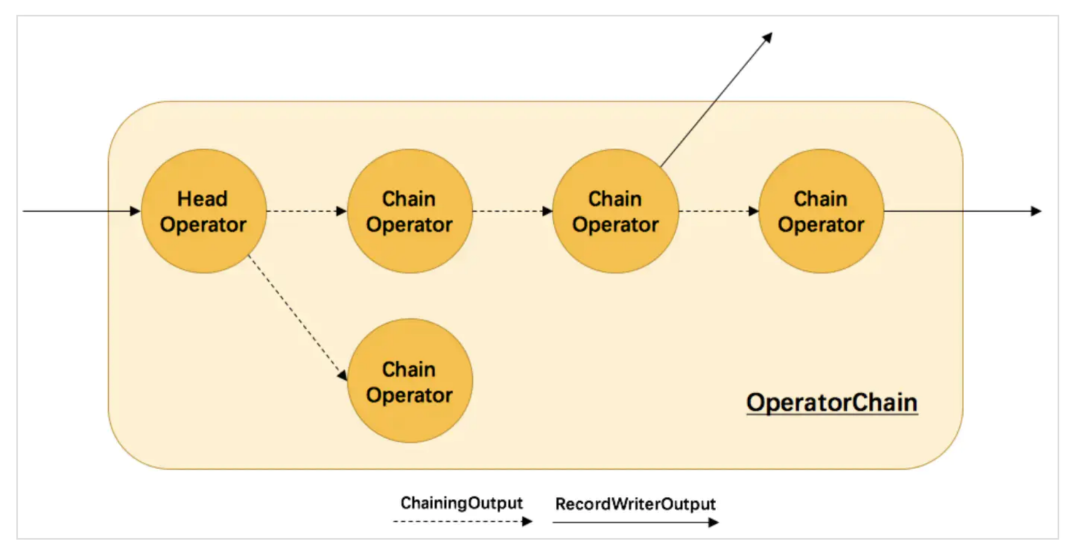
图14 算子链示意
如图所示,若不启用对象重用,算子链中的虚线默认是CopyingChainingOutput(深拷贝)。通过ExecutionConfig#enableObjectReuse()或者pipeline.object-reuse = true启用对象重用,CopyingChainingOutput就会被替换为ChainingOutput(浅拷贝)。下图示出了两者之间的差异。
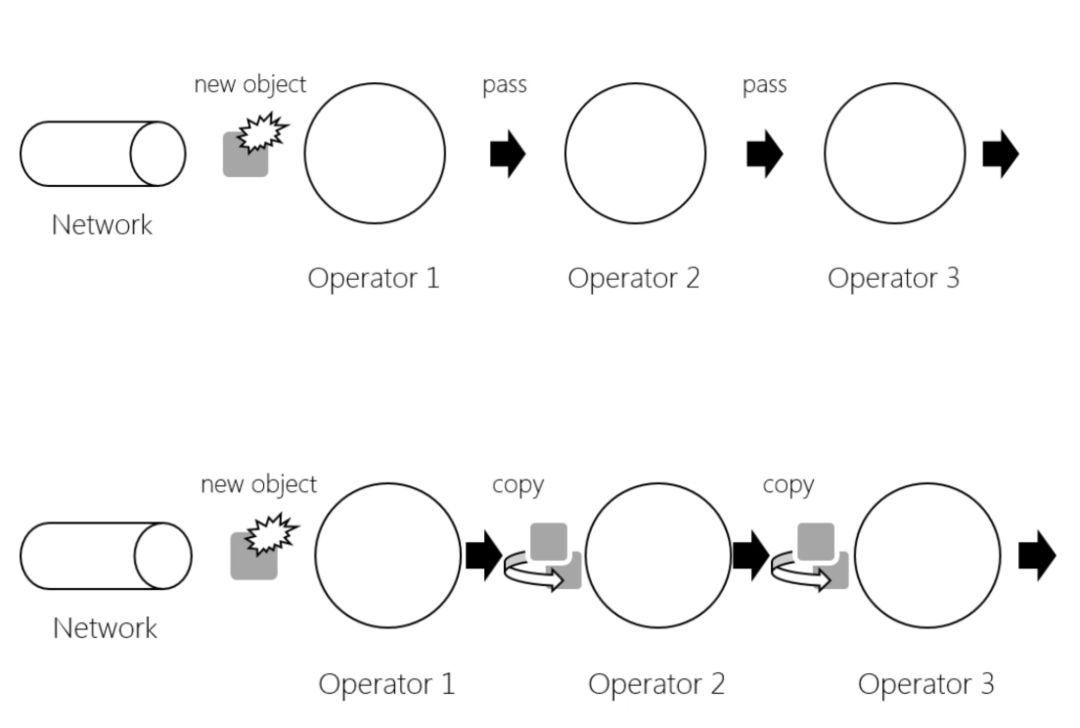
图15 是否重用对象的区别
DataStream API作业一般不建议开启对象重用,除非十分确定不存在下游算子直接修改上游算子发射的对象的情况。并且DataStream API作业开启对象重用的收益不高,仅当其中有复杂数据类型定义时,才会有20%左右的性能提升。
但是SQL作业强烈建议开启,因为Flink SQL的类型系统与DataStream API有差异,StringData、MapData等的深拷贝成本很大,并且Flink SQL的代码生成器能够保证可变对象的安全性。测试结果表明,对象重用的SQL作业平均可获得翻倍的性能提升。
4.3 别忘了JobManager
相对于TaskManager,JobManager的配置往往比较省心,似乎随便给个2C / 4G的配置就可以高枕无忧了。实际上JobManager内部维护的组件很多,如:作业DAG即{Job | Execution}Graph、SlotPool & Scheduler、<TaskManagerLocation, TaskExecutorGateway>的映射关系、CheckpointCoordinator、HeartbeatManager、ShuffleMaster、PartitionTracker等。
所以,如果作业Slot / Sub-task多,Checkpoint比较大,或者是重Shuffle的批作业,一定要适当增加JobManager的资源。最近作者部门有两个作业频繁出现ResourceManager leader changed to new address null的异常信息,就是因为JM压力过大、GC时间太长,导致ZooKeeper Session失效了。以示例作业的JM(4C / 8G)为例,其内存分配如下。

图16 示例作业JobManager内存分配
4.4 其他小Tips
- 从Flink 1.12开始,默认的时间语义变成了事件时间。如果作业是处理时间语义,可以禁用水印发射,即:
Execution Config# set Auto WatermarkInterval (0)。 - 设置metrics.latency.interval(单位毫秒)可以周期性插入LatencyMarker,用于测量各算子及全链路的延迟。处理LatencyMarker会占用资源,因此不需要特别频繁,60000左右比较合适。
- 用户注册的Timer会按照<key, timestamp>去重,并在内部以最小堆存储。所以要尽量避免onTimer风暴,即大量key的Timer在同一个时间戳触发,造成性能抖动。
- 如果需要交换Flink原生没有Serializer支持的数据类型(如HyperLogLog、RoaringBitmap),应在代码中注册自定义的Serializer,避免fallback到Kryo导致性能下降。
- POJO类型支持状态Schema变化,增删字段不会影响恢复(新增的字段会以默认值初始化)。但是切记不能修改字段的数据类型以及POJO的类名。
05 References
|








- 上一条: 文盘Rust -- 安全连接 TiDB/Mysql 2023-03-15
- 下一条: @Transaction注解的失效场景 2023-03-15
- RocketMQ调优心得总结 2021-07-23
- openGauss数据库性能调优概述及实例分析 2022-05-09
- 人体调优不完全指南「GitHub 热点速览 v.22.22」 2022-05-30
- 网络性能总不好?网络调优专家AOE帮你来“看看” 2023-03-02
- 一文教会你数据库系统调优 2022-05-12


