后疫情时代,数据科学赋能旅游行业服务质量提升
通宵灯火人如织,一派歌声喜欲狂。新冠“乙类乙管”的实施加上春节假期的到来,使得人们的出行热情空前高涨。根据中国旅游研究院的调查显示,23年春节假期全国国内旅游出游达到了3.08亿人次,同比增长23.1%,期间旅游收入达3758.43亿元。以杭州西湖景区为例,该景区在春节期间招待游客292.86万人次,数量近上年的4倍。各大景区热闹非凡、游客络绎不绝的新闻也成为了人们对23年春节独特的回忆。
由于先前的新冠风控,许多景区在财政和园区管理方面经历了难熬的两年。在游客反馈方面,由于人次过少,景区非常容易陷入无法对游客需求进行准确判断的困境。了解游客的真实感受和评价,并根据这些信息对景区硬件、软件、管理等进行升级,是景区应对暴涨的游客需求和期待最有效的解决方案之一。
面对后疫情时代下,旅游行业逐渐迈向复苏,景区该如何把握机会,通过提升服务来满足游客需求呢?基于以上背景,我们决定建立这样一个实验性项目,让数据来告诉大家答案。
项目背景与结构
全球旅游业权威研究机构 PhoCusWright 指出,大众对于景区的点评值得被加以分析与运用,可以为旅游企业带来巨大的价值。很多景区管理部门由于对游客需求的误解、信息技术的落后、或是相关反馈部门的缺失,对于网络上的评论并未做到有效的收集与分析。在进入大数据时代后,一些适应了新型数据平台的景区管理部门通过在网络上收集与景区相关的评论,并对这些数据进一步分析来重点调整、升级景区中让游客在意的部分。其中就涉及了对各大旅游点评网站中景点评论的归纳总结,包括对游客类别的统计和评论文本信息的建模与分析。
旅游网站的种类众多,但商业价值的侧重点会有所不同。猫途鹰(TripAdvisor)是一款侧重于记录用户旅行数据的国际性旅游网站,拥有着数十亿条国内外真实旅行者的点评和建议。许多游客在出行前会在该平台查询目的地酒店、餐厅和景点的相关点评,多而全的点评信息不仅能帮助旅客做出出游决定,也是景区收集游客反馈的好渠道。
本项目以热门景点“上海外滩”为例,采集猫途鹰网站上与该景点相关的评论,查看随着时间与出行政策的变化,国内外游客在出游方式和态度上的转变,结合 NLP(自然语言处理)技术,挖掘评论中值得借鉴的意见和建议,寻找游客对景点需求的趋势。总体的解决方案结构如下:
- 确定数据来源
- 数据采集
- 数据入库
- 数据清洗
- 探索性数据分析
- 数据建模
- 数据洞察
项目步骤解析
1. 确定数据来源
首先,我们确定使用来自猫途鹰中文版网站(www.tripadvisor.cn)和国际版网站(www.tripadvisor.com)截至2023年2月20日的数据。重点关注旅游者对“上海外滩”这个景点的中英文评论,收集来自世界各地的评论有助于提升景区的分析维度,让决策更具包容性,这也是我们选择猫途鹰这个国际化旅游平台的原因。
2. 数据采集
在对网页抓取工具做了深度评估、对网页数据和结构的初步了解后,我们决定使用 Selenium 进行网页文本数据的抓取。根据评论格式的特点,我们可以抓取的信息如下:
- 用户
- 用户所在地
- 评分
- 点评标题
- 到访日期
- 旅行类型
- 详细点评
- 撰写日期
注意,对于中文评论的抓取,我们把用户所在地锁定至城市,而对于英文评论,用户所在地的抓取会详细至国家和城市。最终,我们执行的网页抓取程序大致可以分成两个步骤:
- 第一步:发送请求,使用 Selenium 操作浏览器找到指定景点的评论页面
- 第二步:进入评论页面,抓取评论数据
由于中文评论的数量远少于英文评论,为了保持数据总量的一致性,我们采集了中文评论的全量数据(1710条,时间跨度2009-2022年)和英文评论的部分数据(2000条,时间跨度2018-2022年)。如果大家想从完整的时间线维度对比中英文评论,可以自行获取更多英文评论数据,在本项目中我们就不多加赘述了。
3. 数据入库
在采集完毕评论数据后,我们可以将数据存进数据库,以便数据分享,进行下一步的分析与建模。以 PieCloudDB Database 为例,我们可以使用 Python 的 Postgres SQL 驱动与 PieCloudDB 进行连接。在《PieCloudDB Database 云上商业智能的最佳实践》中,我们详细介绍了 PieCloudDB 的外部连接方式,如有需求请参考这篇技术博文。
我们实现数据入库的方式是,在获取了评论数据并整合为 Pandas DataFrame 结构后,借助 SQLAlchemy 引擎将该数据通过 psycopg2 上传至数据库。由于中英文的文本分析技巧略有不同,所以我们将中英文数据存放在两张表中。最终,我们可以在 PieCloudDB 中查看如下两张源数据表结构:
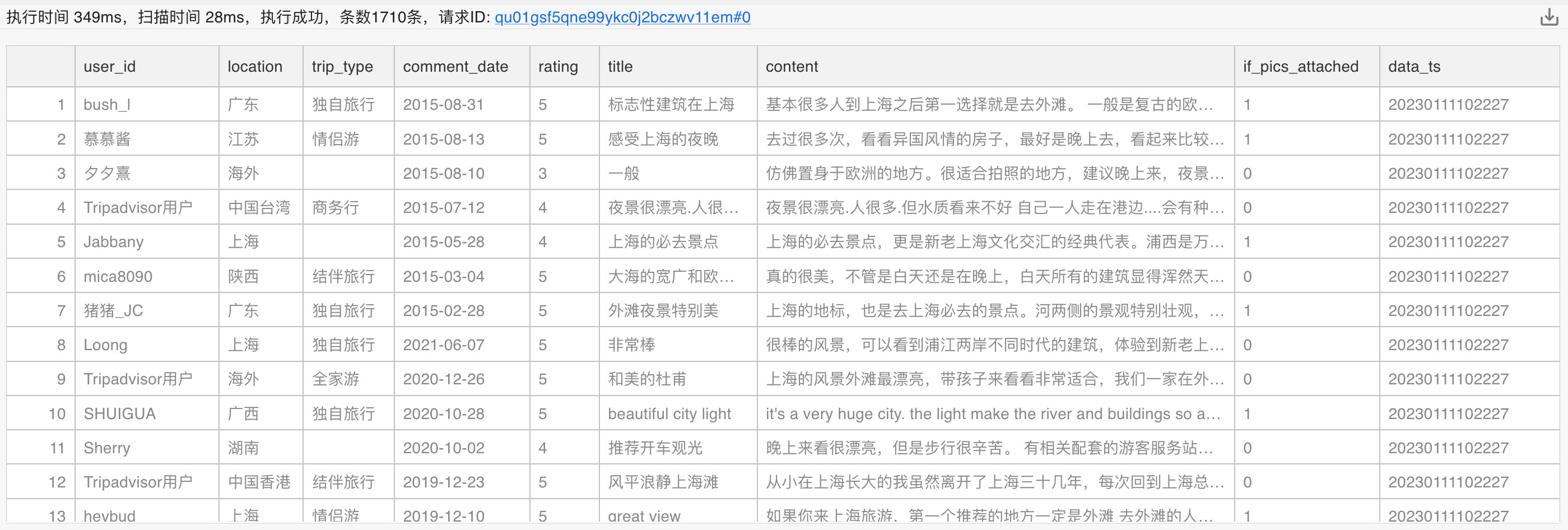
中文表
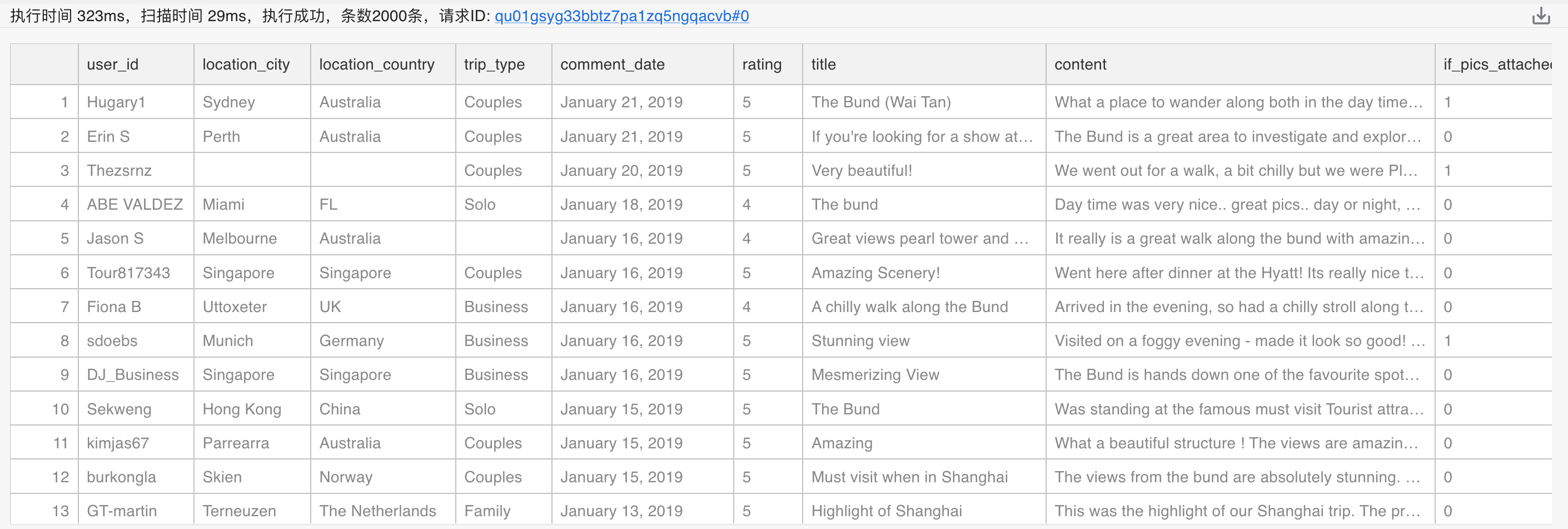
英文表
4. 数据清洗
数据清洗是指对重复或多余的数据筛选和清除,同时完整地补充丢失的数据,纠正或删除错误的数据,最后整理成我们可以进一步处理和使用的数据。在这里,我们会对数据进行空值填充和类型转换。
- 空值填充:中文表中的 trip_type(旅行类型)这一列存在807个空值,我们使用“未知”文本填充;英文表中trip_type(旅行类型)的405个空值也是同样的操作,而对于 location_city(所在地城市)和 location_country(所在地国家)这两个变量,我们通过手动检索来识别误填、漏填和错位的情况,然后修正或补齐信息。
- 类型转换:中文表中的 rating(评分)这一列数据类型不匹配,我们将其转换成便于后续计算的 int 类型。
因为数据是按照规范的数据结构采集的,所以数据清洗部分相对简单。接下来,我们就可以用初步清洗后的数据做一些探索性分析。
5. 探索性数据分析
我们使用 BI 工具 Tableau 外部接入 PieCloudDB,具体步骤请参考这里。为了将中英文评论数据可视化,我们绘制了如下两张动态化的仪表板:

中文仪表板

英文仪表板
以中文评论仪表板为例,我们可以通过右侧的评论时间筛选器来调节整个仪表板的数据使用范围,上图就是显示了近十年的中文评论数据情况。我们将评分划分了三个等级:好评(4-5分)、中评(3分)和差评(1-2分),并将评论数量的分布细分至每一年的每个季度。通过探索性数据分析,我们总结了以下几点可用信息:
- 自疫情(2019年底)以来,评论数量急剧下降,说明疫情对游客的出行影响重大。
- 使用该平台的用户所在地主要集中在上海、中国台湾、中国香港、江苏等地区,也正是参观上海外滩景点的主要华人游客来源。
- 近十年来,大家更倾向于结伴旅行,独自旅行的占比也在逐年增加。
- 各地区对上海外滩这个景点的评价总体很高,来自重庆的游客评价相对偏低。
- 我们认为 trip_type(旅行类型)存在大量空值的原因大概率是平台的升级,在2013年6月左右给用户增加了旅行方式的选择功能。因为通过调节时间筛选器,我们发现在2013年6月以前,所有评论均为未知旅行类型,在此之后才有其它旅行类型的出现。
- 旅游从业者可以重点关注出现差评的年份和季度,将差评的评论单拉出来,进行深度分析。
英文评论仪表板的信息提炼方式也非常类似,这里就不重复赘述了。对比中英文语言使用者的游客,我们发现了一个明显的差异点:参观上海外滩的英文游客更倾向于情侣游(couples),国内游客更倾向于结伴旅行(friends)和独自旅行(solo)。
6. 数据建模
在对数据有个初步的了解后,我们就可以进行更高阶的建模分析了。这里,我们尝试了多种分析方法:emoji 分析、分词关键词、文本情感分析、词性词频分析、主题模型文本分类。对于模型而言,文字并非有效输入,我们需要将文本信息数字化,再将数字化结果传递给模型,输出结果。注意,由于中英文的自然语言处理是两种体系,所以我们会选择各体系中更为成熟的工具去使用。
· emoji 分析
首先,我们发现有些评论中会夹杂多种语言,当分析重点是中文评论时,我们以句为单位,筛选掉非中文的文本。同样,侧重点是英文评论时,也是类似的操作。与此同时,评论中还会夹杂emoji表情,因为年轻用户的emoji使用频率越来越高,所以我们决定把这类文本从评论文本中分离出来,从中文评论中得到这样一个emoji的列表:

从英文评论中又得到了以下emoji的列表:

之后,我们会结合评论的正负向情感对emoji进一步分析。
· 分词关键词
其次,我们需要对每个文本进行分词,并对词性进行标注。中文评论部分使用的 Python 库为 jieba,是最受欢迎的中文分词组件之一,包含使用 Viterbi 算法新词学习的能力。它拥有多种分词模式,其中 paddle 模式利用了 PaddlePaddle 深度学习框架,训练序列标注(双向GRU)网络模型实现分词。为了判断哪类分词方式更适合,我们选取数据中的评论样本进行测试,最终我们选定了精准模式来做分词。
举个例子,“外滩矗立着52幢风格迥异的古典复兴大楼,素有外滩万国建筑博览群之称,是中国近现代重要史迹及代表性建筑,上海的地标之一,1996年11月,中华人民共和国国务院将其列入第四批全国重点文物保护单位。”评论经过分词处理后,返回如下结果:外滩/ 矗立/ 着/ 52/ 幢/ 风格/ 迥异/ 的/ 古典/ 复兴/ 大楼/ ,/ 素有/ 外滩/ 万国/ 建筑/ 博览/ 群之称/ ,/ 是/ 中国/ 近现代/ 重要/ 史迹/ 及/ 代表性/ 建筑/ ,/ 上海/ 的/ 地标/ 之一/ ,/ 1996/ 年/ 11/ 月/ ,/ 中华人民共和国国务院/ 将/ 其/ 列入/ 第四批/ 全国/ 重点/ 文物保护/ 单位/ 。
Jieba 中包含两种更高阶的用来计算关键词的算法:TF-IDF 和 TextRank。其中 TF-IDF 作为词袋模型(Bag of Word)也经常被用来作为将文字内容数字化的算法之一。由于这两种算法自带清理模块,我们直接使用了原文本而并非去除了停用词的语料。
基于TF-IDF和TextRank算法的前20个关键词分别如下,可以看到关键词的权重排序上略有不同:

英文 NLP 中最领先的平台之一便是 NLTK(Natural Language Toolkit)。NLTK 拥有50个语料库和词汇资料,开发了多种如分词、情感分析、标记、语义推理等语言处理功能。因此在处理英文评论时,我们选择 NLTK 来处理英文语料。在分词的过程中,各个词会同步进行词性标注。
· 文本情感分析
主流的中文文本情感分析模型有两种:使用经典机器学习贝叶斯算法的 SnowNLP 和使用 RNN 的 Cemotion。SnowNLP 和 Cemotion 的返回值都在0-1之间。SnowNLP 返回值越接近0则越负向,越接近1则越正向;而 Cemotion 返回的是文本是正向的概率。在测试过程中,我们发现 SnowNLP 在计算速度上更快,但精确度有限;Cemotion 虽然速度慢,但精准度更高。因此,结合我们的数据量,在本项目中我们将保留 Cemotion 的结果。注意,两种算法都包含了分词等功能,只需输入文本信息即可获得情感倾向结果。最后,在1710条中文评论中,负向情感倾向的评论有117条(占比7.19%),正向情感的有1593条(占比92.81%)。
对于英文评论的情感分析,也是类似的操作,但我们选择了更适合英文语料的工具 TextBlob(NLTK 的包装器模式)。最终,在2000条英文评论中,负向情感倾向的评论有50条(占比2.5%),正向情感的有1950条(占比97.5%)。
· 词性词频分析
在中文分词的基础上,我们还做了词性的标注,以名词为例,jieba 会将名词进一步细分为普通名词、地名、人名和其他专名。我们按照以下方式将 jieba 分词后的词语归类为名词、动词和形容词三类:
- 名词(n):n,nr,ns,nt,nz
- 动词(v):v,vn
- 形容词(a):a
和中文评论类似,我们按照以下方式将 nltk 分词后的英文单词做了如下归类:
- 名词(n):NN,NNS,NNP,NNPS,FW
- 动词(v):VB,VBD,VBG,VBN
- 形容词(a):JJ,JJR,JJS
然后,从多个维度对词语进行词频统计,分别是:情绪倾向、词性、评论年份、评论月份。在这过程中,为了进一步了解游客们对上海外滩的讨论内容,我们将中英文语料中的名词、动词和形容词分别制作了词频词云。从下图可以看到,无论是中文还是英文的语料,占比较高的词在意义上非常相近,两种语言的词云结果很类似。

中文

英文
· 主题模型文本分类
为了丰富文本分析的层次,我们还使用主题模型(Topic Modelling)对语料进行无监督学习,根据语义将类似的文本划为一组,对评论进行分类。主题模型主要有两类:pLSA(Probabilistic Latent Semantic Analysis)和 LDA(Latent Dirichlet Allocation),LDA 是基于 pLSA 算法的延伸,使得模型可以适应新的文本。这里,我们使用了 Python 的 Genism 工具库来识别中英文文本的语意主题。
以LDA为分类器的2类主题的中文单词分布为:
(0, '0.012*"夜景" + 0.011*"建筑" + 0.011*"人" + 0.010*"都" + 0.009*"去" + 0.009*"很" + 0.009*"晚上" + 0.008*"非常" + 0.006*"黄浦江" + 0.006*"地方"')
(1, '0.021*"很" + 0.021*"去" + 0.019*"人" + 0.015*"都" + 0.012*"夜景" + 0.010*"晚上" + 0.010*"建筑" + 0.008*"看" + 0.007*"感觉" + 0.007*"很多"')
我们可以看出,结果并没有太大区别。事实上,在建模过程中,很多模型的表现并不会像人们预期的一样好。不过由此也可以看出,基本上中文评论并没有突出的类别,游客基本以游览景观和建筑为主,并且游览时间大多为晚上。
同样的,我们也对英文评论进行了主题模型的文本分类,与中文评论类似,英文评论的分类并没有很突出的类别。从最后的分类结果中可以看出,英文评论大致可以分成三类:夜景与建筑、夜景与黄浦江风光、夜景与灯光秀,游客对上海外滩的关注重点是夜景。
以LDA为分类器的3类主题的英文单词分布为:
(0, '0.027*"view" + 0.020*"night" + 0.019*"building" + 0.017*"river" + 0.015*"walk" + 0.014*"great" + 0.011*"beautiful" + 0.010*"see" + 0.010*"place" + 0.009*"light"')
(1, '0.025*"view" + 0.022*"night" + 0.016*"place" + 0.016*"river" + 0.015*"see" + 0.013*"walk" + 0.013*"building" + 0.012*"light" + 0.011*"visit" + 0.010*"day"')
(2, '0.022*"night" + 0.021*"view" + 0.017*"light" + 0.016*"building" + 0.015*"see" + 0.014*"river" + 0.013*"place" + 0.011*"day" + 0.011*"must" + 0.011*"great"')
7. 数据洞察
在数据建模的基础上,针对中文评论,我们将情感倾向、emoji、评论时间、词性、评分和旅行类型这些变量的关系可视化,绘制了如下动态化的仪表板:

我们可以通过右侧的评论时间、情感倾向、词性筛选器来调节整个仪表板的数据使用。从仪表板的六张图中,我们产生了很多数据洞察和建议,希望对于旅游行业的工作者来说,也有一定的借鉴意义:
- emoji 的使用也是衡量情感倾向的一个指标,可以反映一些被忽视的情况,比如就上海外滩这个景点来说,“⛈” 和 “🍃” 反映了下雨刮风对游客评价的影响。
- 2021年的负向情感占比最高,建议着重查看负向情感占比高的时期,甚至可以细分到季度和月份。
- 各类词语(名词、形容词、动词)的使用频率与情感倾向也有关,比如产生负向情绪时通常会使用哪些词语,从中可以发现景点设施、服务的一些问题。
- 不同旅行类型(独自旅游、结伴旅行、商务行等)的游客对景点评价的情感倾向也略有不同,建议景点可以照顾到各种类游客的需求。
- 最后也是最重要的一点,可以关注评分和情感倾向严重不符的例子,虽然情感倾向的判断不是100%准确,但在某种意义上可以反映评价的客观程度。
举个例子,对于以下这条评论,虽然评分只有1,但是模型判断的情感倾向是正向的。经过仔细阅读,发现确实是一条赞扬景点的评论,游客的打分与评论不匹配,说明评分低不一定是景点的问题,可能是游客的评分不够客观。

再举一个例子,对于以下评论,虽然给出了5分的高分,但情感倾向识别为负向。我们查看点评后发现,游客对于人太多、使用婴儿推车不方便等方面进行了反馈,确实存在一些负向情绪,说明游客打高分的同时也可能提出问题。
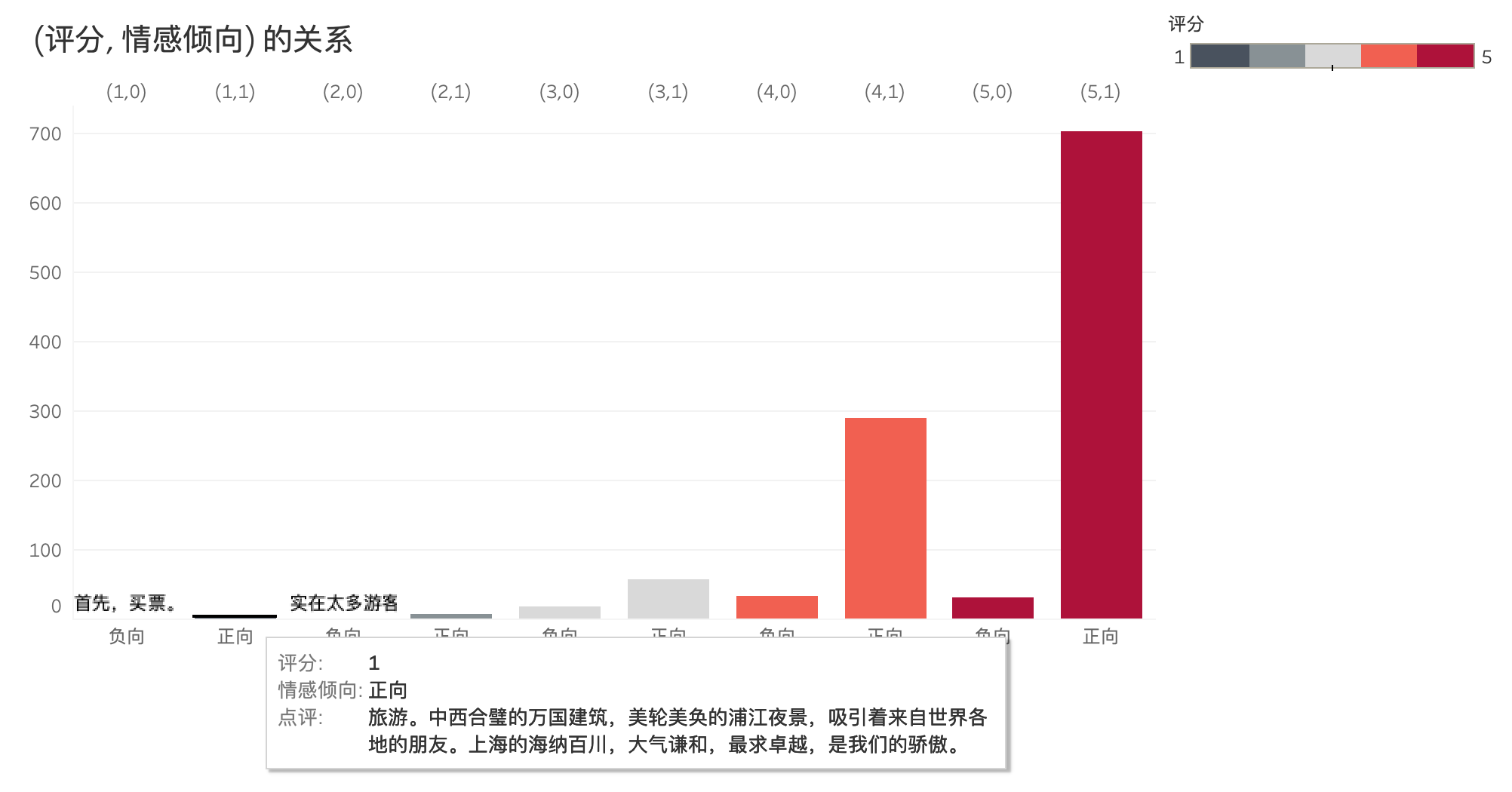
对于英文评论的建模结果,我们也可以使用类似的可视化分析流程,这里就不重复赘述步骤了。最后,我们还综合对比了中英文评论。整体而言,中外游客对于上海外滩的游览印象趋同,景色、建筑、灯光秀等关键词都频繁地出现在评论中,但从细节上来对比,中外游客的评论还是有以下这些差异:
- 外国游客中,除未提供旅行类型信息的人外,以情侣或结伴的多人出游为主,而国内游客近年来独自旅行的占比会更高。
- 外国游客对景点的整体评分会比中国游客高,并且模型判定的情感倾向也更正向。
- 外国游客对上海外滩的风光与建筑留下了深刻印象,由此衍生的评论大多数是好评,但和中文评论相比,对于人文方面的评论(如物价、设施、与当地人或服务业接触的感受)要少许多。
- 中文评论会非常直接地指出除风景、建筑以外的感受,如公共卫生、便利设施、服务质量等问题。
- 中文评论更偏爱使用 emoji,且会出现在各种情感倾向中,而外国游客使用 emoji 绝大多数是为了表达正向情感。
项目结论
在上述数据科学的流程中,探索性分析步骤带领我们了解和可视化数据,而数据建模步骤则在此基础上,将文本数据抽丝剥茧,协助我们发现数据深层的含义。如果我们只看统计的指标性数据,而忽略了文本中常带有发表者的个人情感倾向,就会使最终分析的结果不够客观,继而损失了很多发表者的宝贵意见。数据建模在整个解决方案中不是必需项但却是加分项,可以极大程度地提升数据分析的深度,挖掘数据内在的价值,形成有用的数据洞察从而辅助决策。如果大家对本项目中数据采集、数据清理和数据建模的原理和代码实现感兴趣,可以关注 Data Science Lab 的后续博文。

参考资料:
- 戴斌 | 春节旅游市场高开 全年旅游经济稳增
- 西湖景区春节接待游客292.86万人次
- Scrapy Vs Selenium Vs Beautiful Soup for Web Scraping
- Extract Emojis from Python Strings and Chart Frequency using Spacy, Pandas, and Plotly
- Topic Modeling with LSA, PLSA, LDA & lda2Vec
本文中部分数据来自互联网,如若侵权,请联系删除
|








- 上一条: 百度工程师漫谈视频理解 2023-02-28
- 下一条: 解密游戏推荐系统的建设之路 2023-02-28
- 拥抱"后疫情时代",远程办公如何建设和管理团队,迈向成功? 2022-04-15
- 微服务时代组件化和服务化的抉择 2021-07-11
- 行业方案|数字化疫情防控运行保障解决方案 2022-10-19
- 数据科学,为企业创造更大的数据价值 2022-12-13
- 素质教育新模式:后疫情时代教育 OMO 模式如何切实落地? 2021-08-23