OpenPie 和 ChatGPT 聊聊云上数据计算的那些事儿
要说时下科技圈最火的新技术话题,那就非 ChatGPT 莫属了。由它引发的各类“人工智能(AI)能否取代人工”的讨论狂飙不停,抛开法律和道德层面的争议,ChatGPT 确实可以准确地回答用户大部分的通用知识问题。那么大家是否会好奇,ChatGPT 是依靠什么获得了这样“无所不知”的超能力呢?
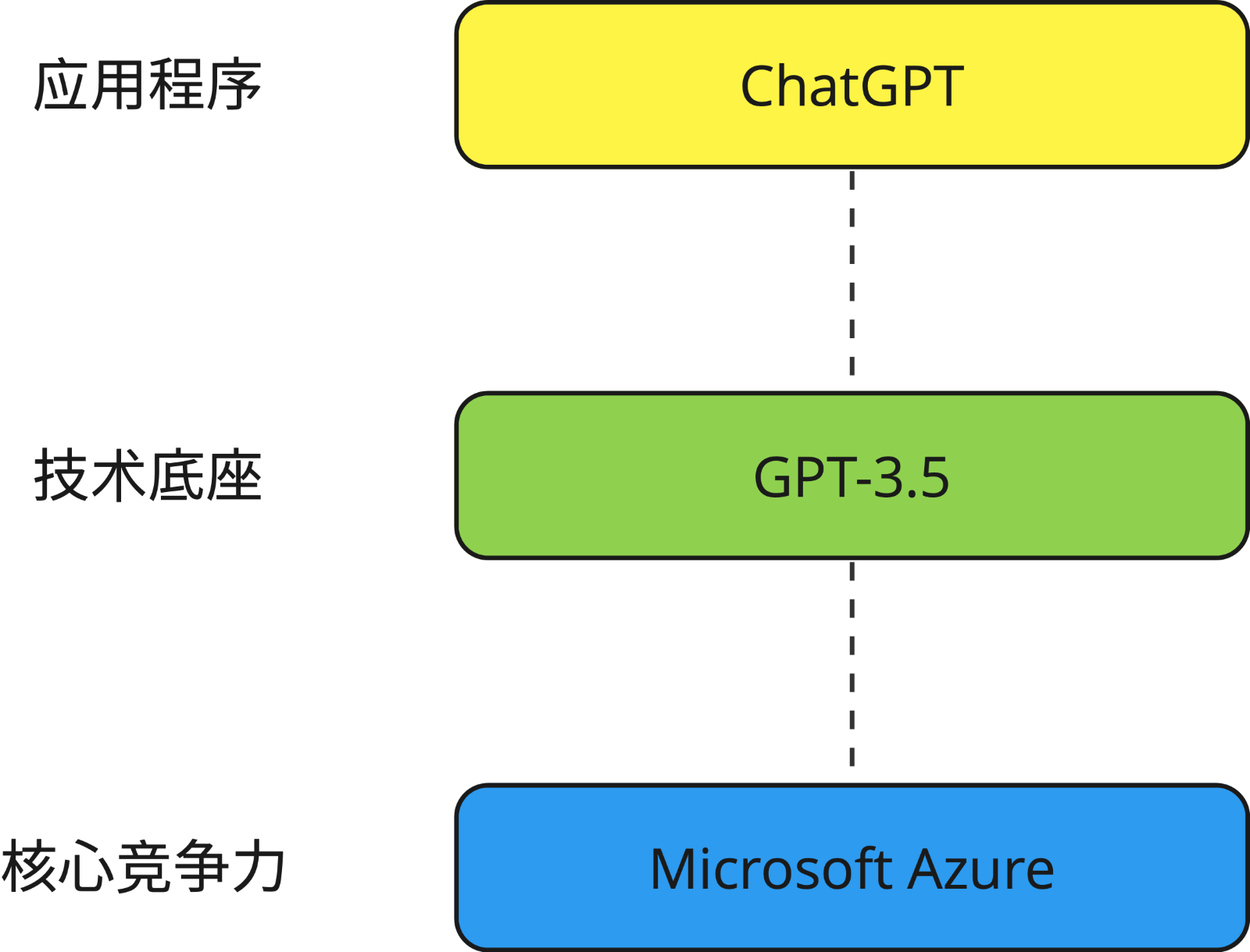
作为一款交流机器人,ChatGPT 的全称是 Chat Generative Pre-trained Transformer(生成式预训练转换器),由 OpenAI 公司研发,并于2022年11月发布。ChatGPT 使用了基于 GPT-3.5 (最新开放版本)架构的大型语言模型,并通过强化学习在 Microsoft Azure 的超级计算机上进行训练,然后通过近端策略优化算法进行微调,参数量多达1750亿个。用一句话来概括:ChatGPT 的背后,技术底座是大型语言模型,核心竞争力是算力。
ChatGPT 对算力的需求之大可以通过这样一组数据呈现,GPT-3.5的训练使用Microsoft专门建设的 AI 计算系统,由1万个 V100 GPU 组成的高性能网络集群,总算力消耗约3640 PF-day,即假如每秒计算一千万亿次,需要计算3640天。于此同时,ChatGPT 的算力消耗也在不断扩张,其大型语言模型经历了三次迭代,GPT、GPT-2和GPT-3的参数量从1.17亿增加到1750亿,预训练数据量从5GB增加到45TB,其中GPT-3训练单次的成本就已经高达460万美元。以实际场景为例,我们每问 ChatGPT 一个问题,它就需要花费几美分来计算。所以对于 OpenAI 而言,如何持续不断地获得算力支持并控制高昂的计算成本是至关重要的。目前 ChatGPT 和 Microsoft 提供的系统是强绑定的关系,OpenAI 也表示:无论现在还是将来,Microsoft Azure 都会是 ChatGPT 唯一指定的云计算供应商。这么一来,Microsoft 的投资逻辑也就不言而喻了,我先借资金和算力给你,日后再靠你不断扩张的算力需求来赚钱,Microsoft非常清楚地意识到了数据计算背后的商机。

换言之,哪怕获得了这个复杂大模型的代码,也不是谁都可以跑得起来的。所以,ChatGPT 的成功不仅是复杂算法的功劳,更是依赖了云计算服务的支撑,OpenAI 从 Microsoft 获得的不只是资金层面的支持,更是技术层面的系统优化,其中包括但不限于计算、存储、数据库和网络等方面的资源配置。对于 ChatGPT 来说,借助云的特点在 Microsoft Azure 上实现高性能计算、数据存储和处理、全球可用性、弹性管理资源、成本效益是系统正常运行的基础。比如近日 ChatGPT 身处舆论的风口浪尖,全球各地访问网站的流量激增,Microsoft Azure 可以自动为模型提供更多资源(如 CPU 和内存),以处理增加的负载。相反,当流量下降时,它也可以缩减配置资源以节省成本。与此同时,ChatGPT 也不需要建立自己的数据中心,可以从 Microsoft Azure 云计算服务那里租用所需的资源,按需付费,还省去了运维费用,将成本效益最大化。
ChatGPT 的爆火反映的不只是 AI 技术领域的突破,更是大数据在行业应用的发展趋势。数据计算上云、资源租赁代替购买是大方向,处理庞大数据时能实现弹性伸缩资源,让企业降本增效,这正是 PieCloudDB Database 的设计初衷。

* 此回答仅供参考,请以官方产品描述为准
利用云计算的技术变革,云原生数据库 PieCloudDB Database 可以实现 IT 系统从购买到租赁的转变,真正交付在PC机时代未能交付的大数据承诺。举个例子,对于一类脉冲式场景(如双十一),当天可能需要平日上百倍的算力来支持,PC 结构的设计迫使客户不得不投入上百倍的机器,并且只为一年365天中的某几天。这种情况下,客户有两种选择,一是放弃脉冲式场景的数据计算,二是在前期投入庞大的资金,这也使得客户的投入产出比下降、错失了一些套利机会。尤其对于像 ChatGPT 这样资源消耗极高的场景,如何平衡网站流量激增或下降时的资源需求,是保障公司有效利用资源、控制总体支出的必要前提。
在 PieCloudDB 里,存储和计算各自作为两个独立变量,各自在云端弹性伸缩。用户可以在云端传输海量数据,云中的存储也会随之自动增加,这个伸展过程无需用户烦恼,PieCloudDB 可以自动实现。如果用户需要更大的算力,只需开启更多的虚拟机或者容器,PieCloudDB 会瞬间扩容。在用户完成脉冲计算以后,可以关闭和缩小计算的集群,从而节约在云中的计算费用。通过计算与存储的解耦合,得以实现资源的池化。用户从而可以通过租赁的方式来使用池中的资源,按使用量进行付费。PieCloudDB 让用户可以专注于使用,无需考虑运维和升级等工作。
在这样一个系统中,用户会持续将所有数据存储在云上,让已有的应用和未来的应用真正实现数据共享,PieCloudDB 从而帮助用户真正实现大数据愿景(Big Data Promises finally Come True)。

|








- 上一条: 云原生成为数据库产品的重要演进方向 2023-02-20
- 下一条: 体验AI乐趣:基于AI Gallery的二分类猫狗图片分类小数据集自动学习 2023-02-21
- 拥抱开放|OpenPie引领PostgreSQL中国代码贡献力 2022-09-13
- ChatGPT数据集之谜 2023-02-17
- 我在京东做研发 | 京东云算法科学家解析爆火的ChatGPT 2023-01-06
- ChatGPT 加图数据库 NebulaGraph 预测 2022 世界杯冠军球队 2022-12-08
- ChatGPT:让程序开发更轻松 2023-02-10


