深入分析 OpenJDK G1 FullGC 原理
导读
本文主要从代码层面介绍 OpenJDK G1(garbage first) FullGC 的工作原理,基于 OpenJDK 从 GC(garbage collection) 入口处开始分析整个 FullGC 原理的核心代码与执行过程;并对比 OpenJDK8 与 OpenJDK11 中单线程与多线程实现 FullGC 的异同。希望帮助大家更深入地理解 G1 FullGC 原理,并了解代码中可能导致 GC 时间长的对象分配方式。
阅读本文需要对 JVM、JDK、java对象、对象内存分配、垃圾回收等概念有一定了解,没有 JVM 基础的同学可参考《深入理解Java虚拟机》,《The Garbage Collection Handbook》等。本文涉及源码可参考openjdk github source code
G1 GC的知识回顾
为了帮助大家更全面地理解 FullGC 的逻辑和前因后果,我们先整体简单介绍下 G1 GC 。GC 主要指在程序运行过程中,对象不再使用后,由 JVM 提供的程序将对象销毁并回收内存,将该内存再加入到可用内存中;而 G1GC,是 JVM 提供的一种垃圾回收器,可以通过多 worker 并行回收,并且通过 CMS 并发标记,此外通过 region 的分代回收,可以较好的控制单次回收的暂停时间,并且有效的抑制碎片化的问题。但 G1 并不是完美的回收器,相比于 CMS GC,G1GC CPU 负载相对较高;吞吐量在小内存上可能相对较弱,但 G1GC 整体在回收时间和效率上都表现较为优秀,是当前 java 业务中使用较为频繁的垃圾回收器。但随着使用场景的变换,为了在业务中更好地完成垃圾回收调优,可以更多地了解下这项技术的基础知识。
-
G1 将整个 JVM 运行时堆分为若干个 region,region 大小在运行之初设定,且一经设定不可改变;每个 region 都可能被作以下分别:包括 Eden,Survivor,Old,Humongous 和 Free 等区域,其中 Eden region 指年轻代,一般对象(大小小于 region 的一半)对象分配的默认选择区域,并且为每次内存空间不足时的优先回收区;从一次垃圾回收存活下来的对象会被 copy 到 survivor region,经过几轮回收后,依然存活的对象太多,则这些对象会被移动到 Old region;当对象大小大于region 一半会被直接分配到 Humongous region,只有在 Full GC 或者 CMS 后才有机会回收。
-
回收包含 4 部分 YoungGC(Pause)、MixGC、Concurrent Marking 和 FullGC
YoungGC:选择全部年轻代(Eden),根据暂停时间要求决定回收年轻代的数量。
- stop the world(stw)暂停所有应用线程,G1 创建回收集 Collection Set(cset)
- 扫描 root,从栈、classloader、JNIHandle 等出发,扫描标记直接引用的对象
- 基于要回收的 region 的 rset 来扫描标记对应 region 的存活对象
- 然后将活对象 copy 到新 region
- 处理其他引用
Concurrent Marking Cycle: JVM 内存使用比例超过一定阈值,会触发全局并发标记,包括 clean up 阶段(这里会清理出部分大对象)
MixGC:选择全部年轻代和部分老年代,会按照垃圾占比高低来排序,优先回收垃圾多的 set,G1也得名于此(Garbage first),回收过程同 YoungGC 一样。
FullGC: MixGC 来不及回收或回收不掉,分配内存仍失败,就会触发全局回收,包括所有年轻代、老年代,大对象以及少量其他的 JVM 管理的内存,过程总体同 YoungGC 一样。不过扫描 root 过程会将整个堆完全扫描完。对于有些高流量的业务程序而言,适当的 FullGC 可以更好的调整整个内存,但一般情况而言,因为回收暂停时间较长,我们应当尽量避免 FullGC。
-
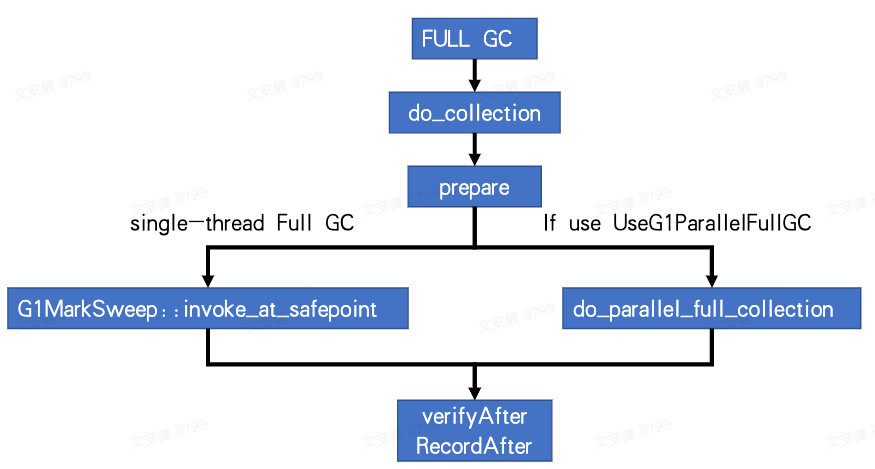
G1 FullGC 回收流程图简图如下

G1 FullGC入口(触发条件)
触发 FullGC 的条件主要分两大类,第一类是在对象分配时发现内存不足导致分配失败,会触发回收逻辑,在 young gc/mix gc 尝试回收后,都不能释放足够内存时,便会触发 FullGC;第二类为业务代码中主动调用回收内存函数,比如 System.gc。两类最终都会调用到 do_collection(),此处不涉及 parallel,OpenJDK8 和 OpenJDK11 入口相同
// 各种分配失败时的调用入口
G1CollectedHeap::mem_allocate
VM_G1CollectForAllocation::doit()
G1CollectedHeap::satisfy_failed_allocation()
G1CollectedHeap::do_collection()
// System.gc()和 metadata回收
G1CollectedHeap::collect(GCCause::Cause cause)
VM_G1CollectFull::doit()
G1CollectedHeap::do_full_collection()
G1CollectedHeap::do_collection()
G1 FullGC回收前准备——prepare_collection
从 do_collection 调入后,对于 OpenJDK8,以 G1MarkSweep::invoke_at_safepoint 函数为边界,该函数前为回收准备,之后为收尾工作;而 OpenJDK11 则将整个 prepare_collection、collect 和 complete 三步都用 g1FullCollector 类进行封装,逻辑更加清晰。
准备过程两者相似,可简单分为三类
- 数据信息检查及记录:包括计时器,trace、safepoint 检查、日志打印等数据处理部分
- concurrent_mark 相关操作和暂停:包括 concurrent_mark 的 abort,cm discovery 禁用等
- 回收准备:heap 集合整理清除、policy 策略更新、开启 stw discovery、处理对象偏向锁等
// openjdk11
void G1FullCollector::prepare_collection() {
_heap->g1_policy()->record_full_collection_start();
_heap->print_heap_before_gc();
_heap->print_heap_regions();
// 终止并发标记,禁用cm discovery
_heap->abort_concurrent_cycle();
_heap->verify_before_full_collection(scope()->is_explicit_gc());
// 预处理当前堆
_heap->gc_prologue(true);
_heap->prepare_heap_for_full_collection();
...
// 保存偏向锁的markword并进行初始标记
BiasedLocking::preserve_marks();
clear_and_activate_derived_pointers();
}
void BiasedLocking::preserve_marks() {
...
Thread* cur = Thread::current();
for (JavaThread* thread = Threads::first(); thread != NULL; thread = thread->next()) {
if (thread->has_last_Java_frame()) {
RegisterMap rm(thread);
for (javaVFrame* vf = thread->last_java_vframe(&rm); vf != NULL; vf = vf->java_sender()) {
GrowableArray<MonitorInfo*> *monitors = vf->monitors();
if (monitors != NULL) {
int len = monitors->length();
// Walk monitors youngest to oldest
for (int i = len - 1; i >= 0; i--) {
MonitorInfo* mon_info = monitors->at(i);
if (mon_info->owner_is_scalar_replaced()) continue;
oop owner = mon_info->owner();
if (owner != NULL) {
markOop mark = owner->mark();
if (mark->has_bias_pattern()) {
_preserved_oop_stack->push(Handle(cur, owner));
_preserved_mark_stack->push(mark);
}
}
}
}
}
}
}
}
上述代码为垃圾回收前准备过程的封装,OpenJDK8和OpenJDK11整体过程基本一致(可进入调用函数与 OpenJDK8 对照,此处不展开),区别在于 OpenJDK11 会在 g1FullCollector 初始化过程中,根据 parallel 的使用情况对 preserve_stack、oop_stack、arrayOop_stack、compaction_points 等数据结构按照并行的线程数进行切分,初始化并用数组保存,为 parallel 回收做准备,服务于并行 FullGC。
// openjdk11
G1FullCollector::G1FullCollector(G1CollectedHeap* heap, GCMemoryManager* memory_manager, bool explicit_gc, bool clear_soft_refs) :
_heap(heap),
_scope(memory_manager, explicit_gc, clear_soft_refs),
_num_workers(calc_active_workers()),
_oop_queue_set(_num_workers),
_array_queue_set(_num_workers),
_preserved_marks_set(true),
_serial_compaction_point(),
_is_alive(heap->concurrent_mark()->nextMarkBitMap()),
_is_alive_mutator(heap->ref_processor_stw(), &_is_alive),
_always_subject_to_discovery()
{
assert(SafepointSynchronize::is_at_safepoint(), "must be at a safepoint");
_preserved_marks_set.init(_num_workers);
_markers = NEW_C_HEAP_ARRAY(G1FullGCMarker*, _num_workers, mtGC);
_compaction_points = NEW_C_HEAP_ARRAY(G1FullGCCompactionPoint*, _num_workers, mtGC);
for (uint i = 0; i < _num_workers; i++) {
_markers[i] = new G1FullGCMarker(i, _preserved_marks_set.get(i), mark_bitmap());
_compaction_points[i] = new G1FullGCCompactionPoint();
_oop_queue_set.register_queue(i, marker(i)->oop_stack());
_array_queue_set.register_queue(i, marker(i)->objarray_stack());
}
}
G1 FullGC回收核心逻辑——collect
回收核心过程基本分为4步如下,包括标记阶段(phase1_mark_live_objects),复制和回收准备阶段(phase2_prepare_compaction),调整指针阶段(phase3_adjust_pointers)和压缩清理阶段(phase4_do_compaction):
// openjdk11
void G1FullCollector::collect() {
phase1_mark_live_objects();
phase2_prepare_compaction();
phase3_adjust_pointers();
phase4_do_compaction();
}
OpenJDK11 中,这4步骤被封装成 4个 task ,继承自 AbstractGangTask,都保存有 monitor 和可执行的 GangWorker,利用 run_task 来根据 worker 数目分多线程执行 task,而执行逻辑封装在 task 的 work 函数中,每个 task 中会传入 worker_id,操作时根据 worker_id 来利用 G1FullCollector 的数据结构来进行操作。
void G1FullCollector::phase1_mark_live_objects() {
GCTraceTime tm("Phase 1: Mark live objects", G1Log::fine(), true, scope()->timer(), scope()->tracer()->gc_id());
// Do the actual marking.
G1FullGCMarkTask marking_task(this);
run_task(&marking_task);
...
}
void G1FullCollector::run_task(AbstractGangTask* task) {
...
_heap->workers()->run_task(task);
...
}
1. phase1_mark_live_objects
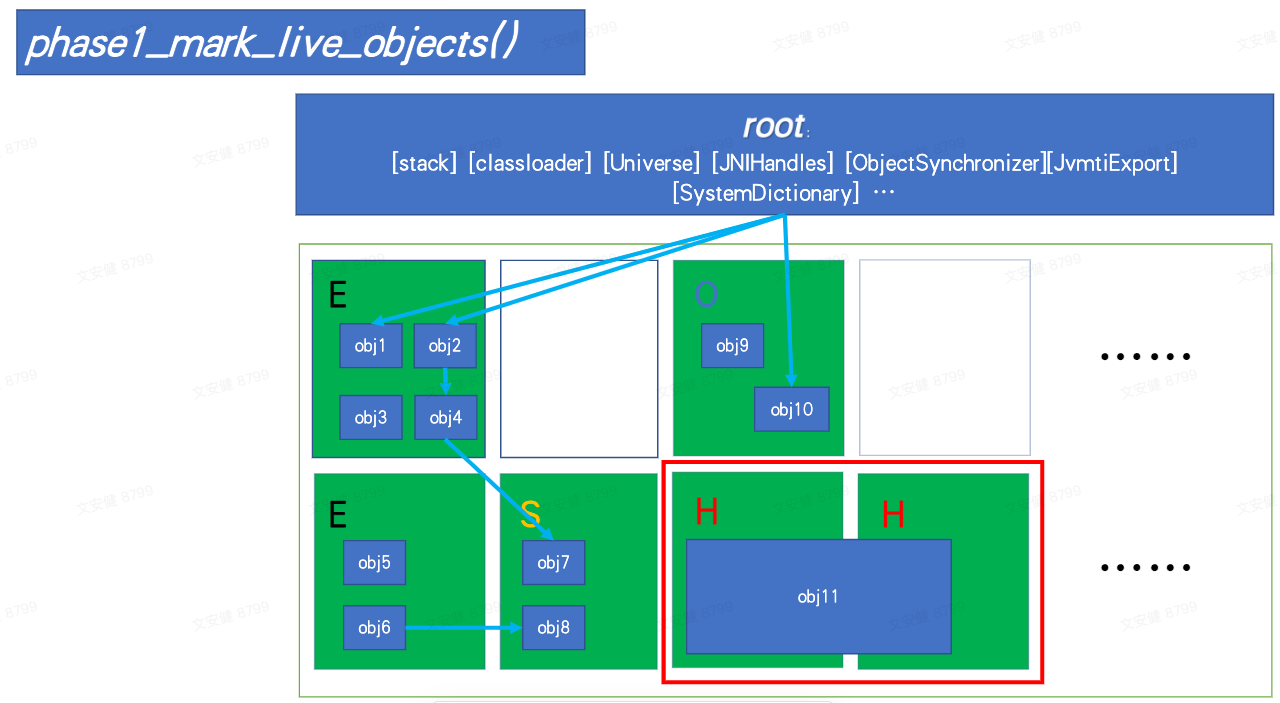
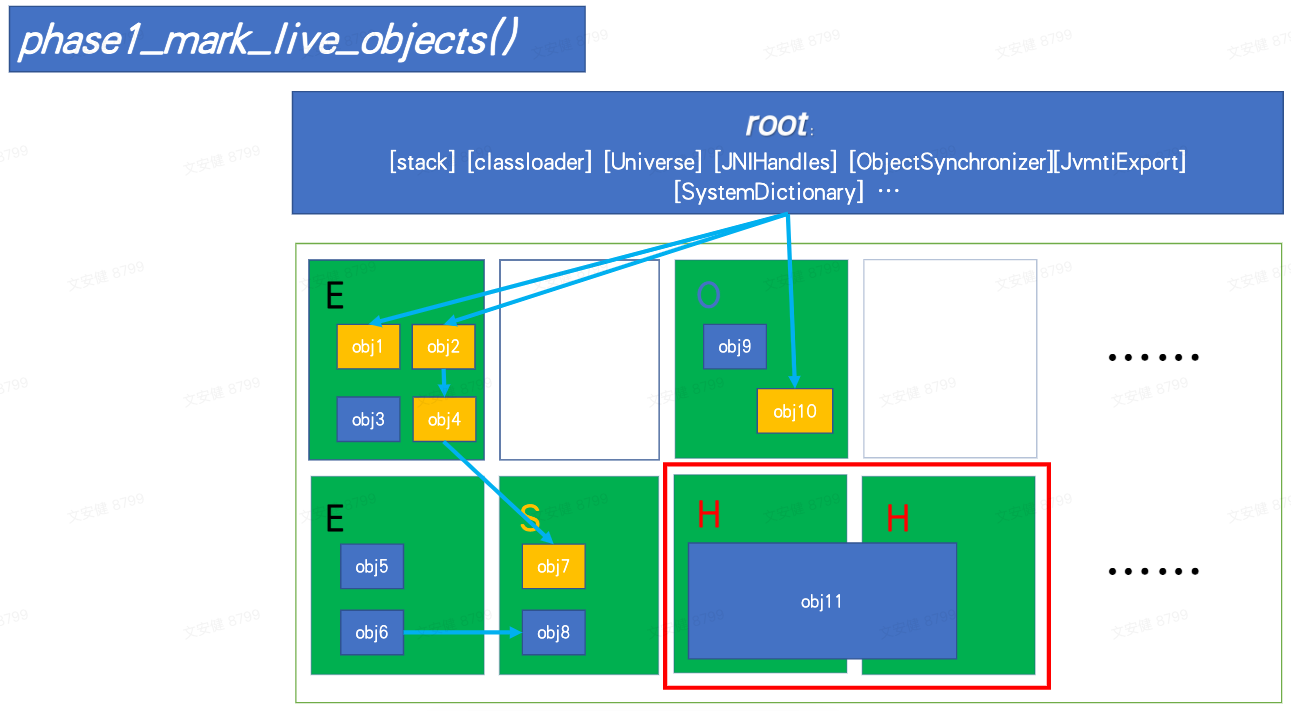
以 marker 过程为例,第 5 行根据 worker_id 取到 collector 中准备好的数据结构,通过root_processor 来来执行三个闭包函数,最后会一路调用到每个 OOP 的 mark_and_push,对整个堆进行标记,此过程与 OpenJDK8 基本一致。
// openjdk11
void G1FullGCMarkTask::work(uint worker_id) {
Ticks start = Ticks::now();
ResourceMark rm;
G1FullGCMarker* marker = collector()->marker(worker_id);
MarkingCodeBlobClosure code_closure(marker->mark_closure(), !CodeBlobToOopClosure::FixRelocations);
if (ClassUnloading) {
_root_processor.process_strong_roots(
marker->mark_closure(),
marker->cld_closure(),
&code_closure);
} else {
_root_processor.process_all_roots_no_string_table(
marker->mark_closure(),
marker->cld_closure(),
&code_closure);
}
// Mark stack is populated, now process and drain it.
marker->complete_marking(collector()->oop_queue_set(), collector()->array_queue_set(), &_terminator);
// This is the point where the entire marking should have completed.
assert(marker->oop_stack()->is_empty(), "Marking should have completed");
assert(marker->objarray_stack()->is_empty(), "Array marking should have completed");
}
void G1RootProcessor::process_strong_roots(OopClosure* oops,
CLDClosure* clds,
CodeBlobClosure* blobs) {
process_java_roots(oops, clds, clds, NULL, blobs, NULL, 0);
process_vm_roots(oops, NULL, NULL, 0);
_process_strong_tasks.all_tasks_completed();
}
void G1RootProcessor::process_vm_roots(OopClosure* strong_roots,
OopClosure* weak_roots,
G1GCPhaseTimes* phase_times,
uint worker_i) {
{
G1GCParPhaseTimesTracker x(phase_times, G1GCPhaseTimes::UniverseRoots, worker_i);
if (!_process_strong_tasks.is_task_claimed(G1RP_PS_Universe_oops_do)) {
Universe::oops_do(strong_roots);
}
}
// 各类可能的roots
...
}
bool SubTasksDone::is_task_claimed(uint t) {
assert(0 <= t && t < _n_tasks, "bad task id.");
uint old = _tasks[t];
if (old == 0) {
old = Atomic::cmpxchg(1, &_tasks[t], 0);
}
bool res = old != 0;
...
return res;
}
template <class T> inline void G1FullGCMarker::mark_and_push(T* p) {
T heap_oop = oopDesc::load_heap_oop(p);
if (!oopDesc::is_null(heap_oop)) {
oop obj = oopDesc::decode_heap_oop_not_null(heap_oop);
if (mark_object(obj)) {
_oop_stack.push(obj);
assert(_bitmap->isMarked((HeapWord*) obj), "Must be marked now - map self");
} else {
assert(_bitmap->isMarked((HeapWord*) obj), "Must be marked by other");
}
}
}
补充多线程实现思路
以 mark 过程为例,简单说明下多线程回收思路。
1)首先在 java 程序执行时,可以通过添加 -XX:ParallelGCThreads=8 指定具体回收时的线程数;在启动后,SharedHeap 对象的初始化时,会调用 WorkGang::initialize_workers(),初始化 8 个 GC 线程(一般是以 GangWorker 实现,继承自 WorkerThread,也被称为工人线程)。随后线程开始执行会调用到 GangWorker 的 run 函数,调到 loop,进入 wait 阶段等待唤醒来执行任务,这个循环等待会持续整个 java 程序运行过程。
void GangWorker::run() {
initialize();
loop();
}
void GangWorker::loop() {
...
Monitor* gang_monitor = gang()->monitor();
for ( ; /* !terminate() */; ) {
WorkData data;
int part; // Initialized below.
{
MutexLocker ml(gang_monitor);
gang()->internal_worker_poll(&data);
for ( ; /* break or return */; ) {
// Check for new work.
if ((data.task() != NULL) &&
(data.sequence_number() != previous_sequence_number)) {
if (gang()->needs_more_workers()) {
gang()->internal_note_start();
gang_monitor->notify_all();
part = gang()->started_workers() - 1;
break;
}
}
// Nothing to do.
gang_monitor->wait(/* no_safepoint_check */ true);
gang()->internal_worker_poll(&data);
...
data.task()->work(part);
...
}
}
}
}
2)所有的 XXXTask 继承自 AbstractGangTask,会实现 work 方法;在回收过程执行时,会将待执行的 task 传给 heap 的 workers 来执行,即会调用到 Sharedheap 中提前保存好的 FlexibleWorkGang 的 run_task。而 FlexibleWorkGang 继承自 WorkGang,run_task 方法实现如下,会唤醒所有GC线程,并等待所有线程执行结束后返回。
// workgroup.cpp
void FlexibleWorkGang::run_task(AbstractGangTask* task) {
WorkGang::run_task(task, (uint) active_workers());
}
void WorkGang::run_task(AbstractGangTask* task, uint no_of_parallel_workers) {
task->set_for_termination(no_of_parallel_workers);
MutexLockerEx ml(monitor(), Mutex::_no_safepoint_check_flag);
...
monitor ()-> notify_all ();
// Wait for them to be finished
while (finished_workers() < no_of_parallel_workers) {
if (TraceWorkGang) {
tty->print_cr("Waiting in work gang %s: %d/%d finished sequence %d",
name(), finished_workers(), no_of_parallel_workers,
_sequence_number);
}
monitor()->wait(/* no_safepoint_check */ true);
}
...
}
3)task 开始执行后,会通过 processor 执行器执行到每个 task 的 work 方法,并根据执行线程传入worker_id,比如 G1FullGCMarkTask 的 _root_processor.process_strong_roots 函数,调用关系的其中一条分支如下,每一个 workgang 都会通过 ALL_JAVA_THREADS 来顺序遍历所有的 java 线程来执行 mark 操作,若已经执行过或正在执行就跳过,保证执行完所有线程,包括一个 VMThread,其中 mark 过程传入的 OopClosure、CLDClosure 为对应 worker_id 的 mark_closure、cld_closure,执行时会调用每个 marker 准备好的 oopStack 等数据结构来执行,都执行结束后所有的 GangWorker继续进入等待任务的过程中,直到下一个 run_task。
// process_strong_roots
// -> process_java_roots
// --> Threads::possibly_parallel_oops_do
void Threads::possibly_parallel_oops_do(OopClosure* f, CLDClosure* cld_f, CodeBlobClosure* cf) {
SharedHeap* sh = SharedHeap::heap();
bool is_par = sh->n_par_threads() > 0;
assert(!is_par ||
(SharedHeap::heap()->n_par_threads() ==
SharedHeap::heap()->workers()->active_workers()), "Mismatch");
int cp = SharedHeap::heap()->strong_roots_parity();
ALL_JAVA_THREADS(p) {
if (p->claim_oops_do(is_par, cp)) {
p->oops_do(f, cld_f, cf);
}
}
VMThread* vmt = VMThread::vm_thread();
if (vmt->claim_oops_do(is_par, cp)) {
vmt->oops_do(f, cld_f, cf);
}
}
2. phase2_prepare_compaction
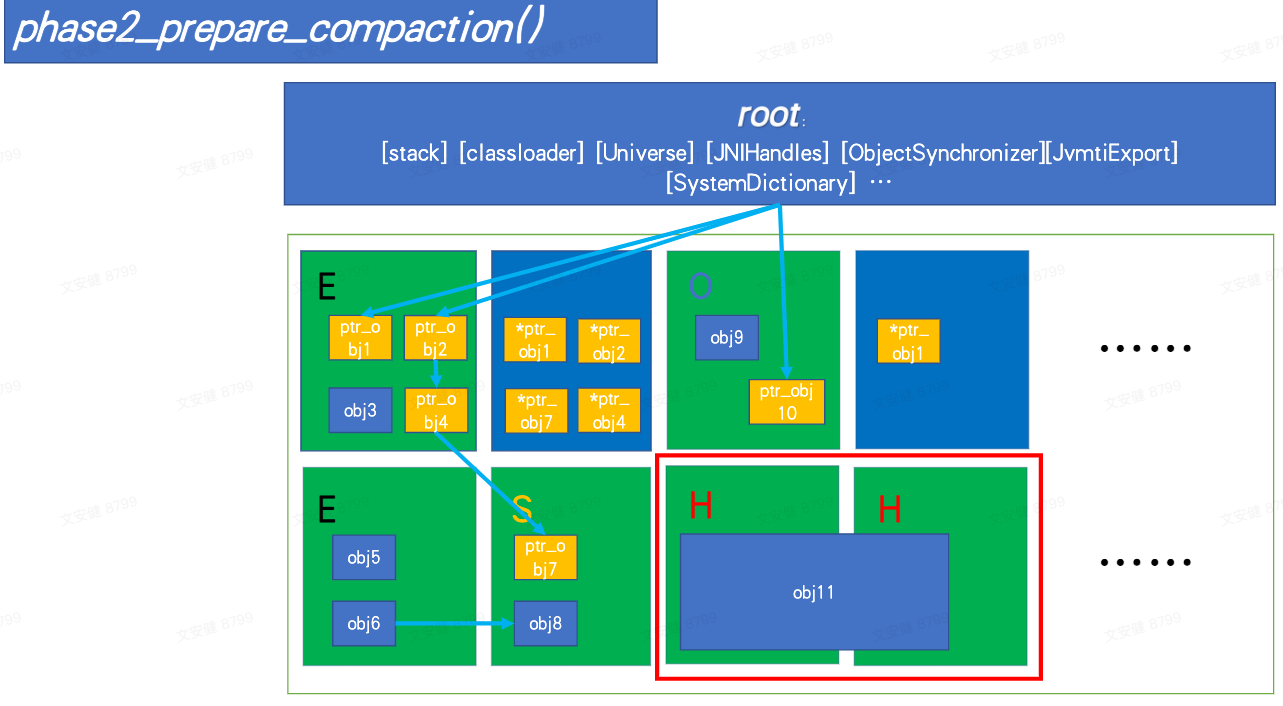
标记过后,准备压缩清理,根据标记情况计算地址,详细逻辑在 G1CalculatePointersClosure 实现如下;根据标记结果,通过 doHeapRegion 遍历含有存活对象的 region,并将存活对象复制到新的 region 内,copy 同时将对象头指向旧对象,为调整指针和清理旧 region 做准备。
// openjdk11
void G1FullGCPrepareTask::work(uint worker_id) {
...
G1FullGCCompactionPoint* compaction_point = collector()->compaction_point(worker_id);
G1CalculatePointersClosure closure(collector()->mark_bitmap(), compaction_point);
G1CollectedHeap::heap()->heap_region_par_iterate_from_start(&closure, &_hrclaimer);
...
}
void G1CollectedHeap::heap_region_par_iterate_from_start(HeapRegionClosure* cl, HeapRegionClaimer *hrclaimer) const {
_hrm.par_iterate(cl, hrclaimer, 0);
}
void HeapRegionManager::par_iterate(HeapRegionClosure* blk, HeapRegionClaimer* hrclaimer, const uint start_index) const {
const uint n_regions = hrclaimer->n_regions();
for (uint count = 0; count < n_regions; count++) {
const uint index = (start_index + count) % n_regions;
...
HeapRegion* r = _regions.get_by_index(index);
if (hrclaimer->is_region_claimed(index)) {
continue;
}
if (!hrclaimer->claim_region(index)) {
continue;
}
bool res = blk->do_heap_region(r);
if (res) {
return;
}
}
}
bool G1FullGCPrepareTask::G1CalculatePointersClosure::doHeapRegion(HeapRegion* hr) {
if (hr->isHumongous()) {
oop obj = oop(hr->humongous_start_region()->bottom());
if (_bitmap->isMarked((HeapWord*) obj)) {
if (hr->startsHumongous()) {
obj->forward_to(obj);
}
} else {
free_humongous_region(hr);
}
} else if (!hr->isHumongous()) {
prepare_for_compaction(hr);
}
reset_region_metadata(hr);
return false;
}
3. phase3_adjust_pointers

此步骤和phase2类似,遍历存活对象region,通过对象头记录的地址,将 live 的对象引用指向重新计算的地址。由 phase2 和 phase3 两个步骤可见,同样大小的内存占用,在 GC 过程中,存活对象数量越多会引起更多的复制和调整指针工作,导致更长的总回收时间。
// openjdk11
void G1FullGCAdjustTask::work(uint worker_id) {
...
// Needs to be last, process_all_roots calls all_tasks_completed(...).
_root_processor.process_all_roots(
&_adjust,
&adjust_cld,
&adjust_code);
...
// 在此步骤前adjust掉weak,preserved string等等, // 此步骤adjust pointers region by region
G1AdjustRegionClosure blk(collector()->mark_bitmap(), worker_id);
G1CollectedHeap::heap()->heap_region_par_iterate_from_worker_offset(&blk, &_hrclaimer, worker_id);
log_task("Adjust task", worker_id, start);
}
4. phase4_do_compaction
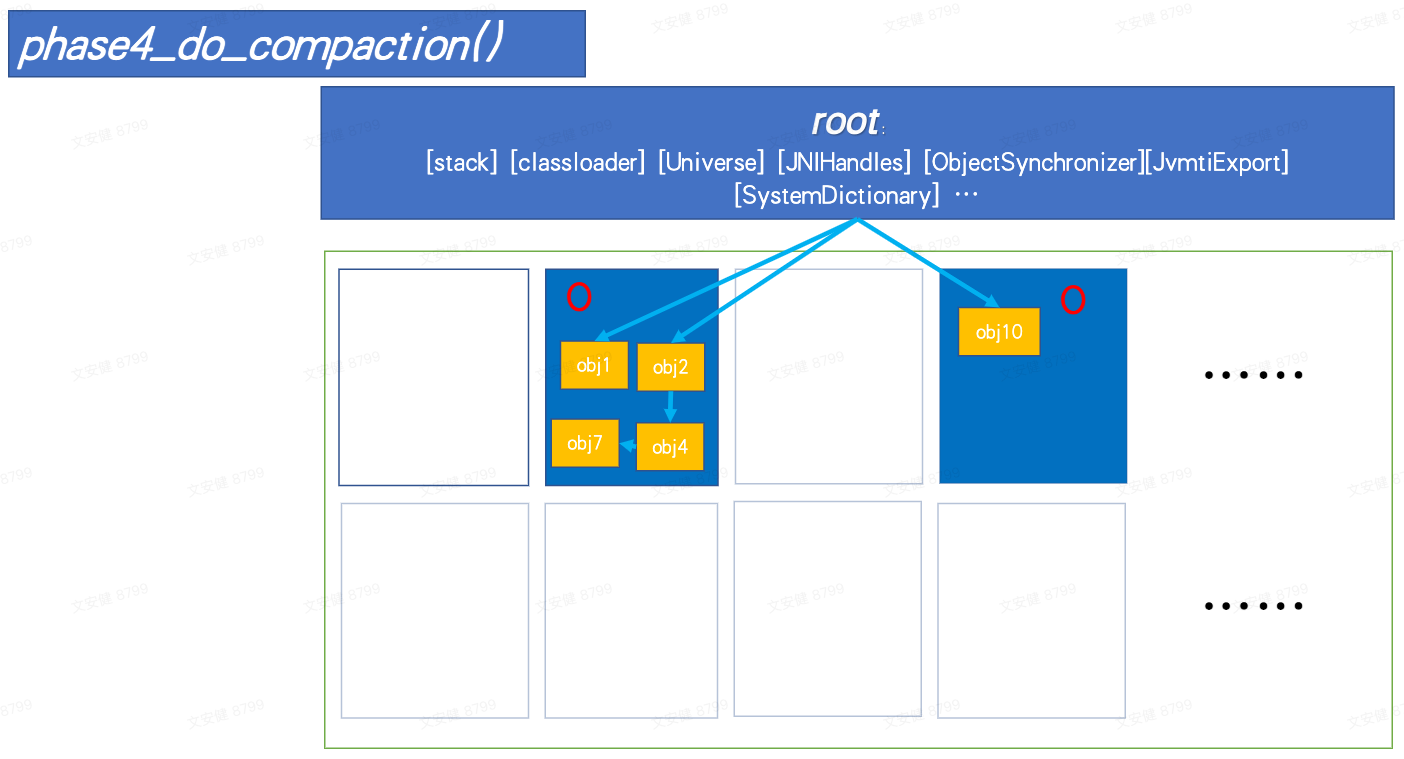
最后逐个 region 进行处理,若没有存活对象,清理掉 region;若有存活对象,则将对象按之前计算copy 到新地址,将旧 region 重置。
// openjdk11
void G1FullGCCompactTask::work(uint worker_id) {
Ticks start = Ticks::now();
GrowableArray<HeapRegion*>* compaction_queue = collector()->compaction_point(worker_id)->regions();
for (GrowableArrayIterator<HeapRegion*> it = compaction_queue->begin();
it != compaction_queue->end();
++it) {
compact_region(*it);
}
G1ResetHumongousClosure hc(collector()->mark_bitmap());
G1CollectedHeap::heap()->heap_region_par_iterate_from_worker_offset(&hc, &_claimer, worker_id);
...
}
void G1FullGCCompactTask::compact_region(HeapRegion* hr) {
...
G1CompactRegionClosure compact(collector()->mark_bitmap());
hr->apply_to_marked_objects(collector()->mark_bitmap(), &compact);
if (!hr->is_empty()) {
MemRegion mr(hr->bottom(), hr->top());
collector()->mark_bitmap()->clearRange(mr);
}
hr->complete_compaction();
}
size_t G1FullGCCompactTask::G1CompactRegionClosure::apply(oop obj) {
size_t size = obj->size();
HeapWord* destination = (HeapWord*)obj->forwardee();
if (destination == NULL) {
return size;
}
HeapWord* obj_addr = (HeapWord*) obj;
assert(obj_addr != destination, "everything in this pass should be moving");
Copy::aligned_conjoint_words(obj_addr, destination, size);
oop(destination)->init_mark();
assert(oop(destination)->klass() != NULL, "should have a class");
return size;
}
inline void HeapRegion::complete_compaction() {
...
if (used_region().is_empty()) {
reset_bot();
}
...
if (ZapUnusedHeapArea) {
SpaceMangler::mangle_region(MemRegion(top(), end()));
}
}
G1 FullGC回收收尾——complete
在整个回收结束前,需要进行一些收尾工作,此处并无 parallel 区分。在 prepare_heap_for_mutators中,会包括重建 region 集合,将空的 region 加入 free_list;为每个 region 重建 strong root 列表;删除已卸载类加载器的元空间,并清理 loader_data 图;准备 collection set;重新处理卡表信息以及一些验证和信息打印等。
// openjdk11
void G1FullCollector::complete_collection() {
。。。
restore_marks();
BiasedLocking::restore_marks();
CodeCache::gc_epilogue();
JvmtiExport::gc_epilogue();
_heap->prepare_heap_for_mutators();
...
}
总结
相比于 YoungGC 和 Concurrent Marking Cycle 等,G1 回收器中 FullGC 过程更为独立、完整,但涉及面也更广,涉及到 JVM 对整个堆的管理细节,包括 OOP 对象结构,region 块,bitmap 标记管理,起始 root 管理,甚至GC线程后台运行情况,多线程同步,stw机制等等,每一部分的设计都很巧妙,值得我们深入代码中一探究竟,相信大家一定会有所收获。
|








- 上一条: 原来除了 Chromium 和 Firefox,还有这么多开源的浏览器 2023-02-19
- 下一条: 深入分析 OpenJDK G1 FullGC 原理 2023-02-20
- 🍃【Spring专题】「原理系列」(1)全方面解析SpringFramework的Bean对象的深入分析和挖掘指南 2021-10-29
- JVM面试必问:G1垃圾回收器 2021-07-17
- g1源码之youngGC技术细节探究 2021-07-15
- G1 垃圾收集器是如何对待我们 JVM 2021-09-28
- g1源码从写屏障到Rset全面解析 2021-08-02