『Postgres.Live 技术沙龙回顾』揭秘 PieCloudDB Database eMPP 架构设计
2月1日,拓数派参与了由开源软件联盟PostgreSQL分会组织的 Postgres.Live 线上系列沙龙活动。拓数派产品及推广总监吴疆发表主题演讲《PieCloudDB:基于 PostgreSQL 的 eMPP 云原生数据库》。相关视频回放欢迎访问拓数派B站链接,PPT欢迎前往官网链接获取。本文由演讲内容整理而成。
随着计算机技术的发展,”云计算”、”云平台”、”云技术”已经成为行业里的热词。无论是业务系统或是基础架构都在往”上云”的道路前进。大家如此热衷于云的最主要原因,正是由于云计算实现了IT系统从购买到租赁的转变。也就是说用户不再需要购买 IT 系统,而是可以选择采用租赁的方式,按使用量或区域来进行付费,更加灵活和节约成本。
为了满足这一需求,云平台技术实现的一个主要功能是存储和计算的解耦。云平台可以提供分布式存储或对象存储,来实现了存储的解耦。借助于云上虚拟化技术或由该技术实现的IaaS,可以实现计算的解耦。通过计算与存储的解耦合,得以实现资源的池化。用户从而可以通过租用的方式来使用池中的资源,按使用量进行付费。云平台让用户可以专注于使用,将运维、升级等工作交给 IaaS/SaaS 等云厂商。
上云和云原生的区别是什么?
虽然”上云” 作为口号已经被喊了很多年。但直到近年,才出现”云原生”的概念。那么,”上云” 和 “云原生“ 的区别是什么?
在最早的单机软件系统年代,系统被部署在一台服务器上,随着业务的发展,这台服务器将无法满足业务的需求。此时,企业会买一台更好的服务器,配上更多的 CPU,更大的内存,更快的存储和更快的网络。
然而,随着互联网技术的发展,这种扩容方式无法满足业务需求。于是, ”Scale-Out” 的概念被提出,即使用多台服务器组成一个集群,来满足日益增长的业务需求。这种方式下,存储资源和计算资源是紧密耦合的。当扩充计算资源时,也需要扩充存储资源。这样的系统的弹性较弱,只能 Scale Out,却无法 Scale In。当业务量下降时,无法及时释放资源。
云平台诞生后,实现了计算和存储的解耦合,可根据需求动态的扩充或缩容计算和存储资源,做到真正的弹性。因此,弹性计算是云原生的一个基本特征。
另一个特征是多租户,随着云原生平台让用户完成了购买到租赁的转换,云平台也需要实现可以满足多个租户同时租用平台,且按使用量付费的架构。此外,云平台也需要提供智能化运维系统,让用户能够更加方便的运维业务系统,减少运维负担。
因此,如果要做到真正的”云原生”,需要让应用充分利用云平台的特征。与云原生相对的一个概念是”上云”。业务系统虽然被部署到云平台上,但本质上,其部署结构和被部署到数据中心的方式是一样的,用户无法享受云平台提供的这些优势。因此,系统上云并不等于云原生。
作为一款基础软件,数据库的诞生是在云平台之前。因此,目前业界的大部分数据库都是非云原生的。传统的分布式MPP架构存在一系列痛点,包括缺乏弹性(业务使用不灵活)、成本高昂(根据系统的最大负载配置集群,集群固定,资源利用率低)、木桶效应(数据库的性能由最短板的服务器决定,扩容难)、数据孤岛(多个集群承担着不同的业务,元数据和用户数据跨集群访问困难)和运维成本(DBA需同时管理多个集群,运维成本高昂)。因此用户急需一款云原生架构的数据库,来解决这些痛点。
PieCloudDB 的设计理念是什么?
PieCloudDB Database 是一款云原生eMPP架构的分布式数据库。在设计这款数据库时,我们遵循了几个理念:
- 打造真正的云原生数据库:PieCloudDB 要打造成为包括多租户、弹性计算、云原生运维平台基本特点的实时的数据库;
- eMPP架构的实现:MPP,即大规模并行计算处理。借助MPP架构,PieCloudDB 可以实现海量数据的并行处理能力。前面的 “e” 是指 ”elastic”,弹性。PieCloudDB 要实现一个弹性的 MPP 架构,即可以横向和纵向灵活扩、缩容,及时满足用户的业务需求;并能够在不同的集群之间做到用户数据和元数据的共享。
- 安全可靠:对于数据库,特别是一款云上数据库而言,数据安全是至关重要的,PieCloudDB需要能够保证用户的数据不丢失、不泄露、不被没有授权的人非法看到。
- 使用简单:PieCloudDB 要减少用户使用数据库的成本,提供智能的运维平台,降低使用门槛。
- 功能齐全:PieCloudDB 需要具备完备的数据库功能,能够支撑大部分的业务应用场景;提供包括完备的事务支持、完善的SQL标准、友好的用户接口、生态组件的兼容等功能;
- 性能极致:数据库作为一款基础软件,性能是最关键的要素之一。PieCloudDB 需要做到能够为用户的业务场景提供一个安全可靠、性能优越的底座。
PieCloudDB 的架构有什么特点?
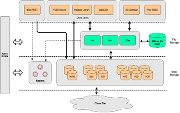
在上述设计理念的基础上,PieCloudDB 的系统架构被分为三个层次。其中最底层的是云平台。云平台可以是私有云、公有云、也可以是混合云、行业云、专有云。PieCloudDB 在系统设计过程中,充分考虑了多云的方案,做到了云中立。最上层,是搭建在 PieCloudDB 之上的用户的业务平台,可以支持多个租户的使用场景,因此企业的生产部、销售部、财务部等部门可以作为不同的租户接入到 PieCloudDB 中。
中间层的 PieCloudDB 本身的架构也被分为了三个层次,最上面是元数据层;中间是计算层,其中每一个虚拟数仓作为最小的计算单元,为用户提供实时数据分析的服务。底层是共享存储层, 提供了用户数据的存储。

PieCloudDB 核心架构特点主要包括四个部分:元数据服务、eMPP分布式引擎、用户数据存储和查询优化器。
元数据服务
元数据即 catelog 数据。PieCloudDB 实现了多租户,即多个租户可以同时使用 PieCloudDB 平台,同时可以创建多个虚拟数仓来进行数据分析业务。此时,元数据就不能和用户数据耦合在一起。因此,PieCloudDB 实现了元数据和计算资源以及存储资源的分离,被称为元数据服务。
PieCloudDB 在进行元数据服务的设计时考虑到了四个因素:
- 高可用和多集群的支持。为了提高性能的可用性,需要提供Multi-master,即当出现一个节点失效时,系统仍然可以提供对外的服务。
- 实现多节点共同访问的数据存储
- 实现分布式锁
- 事务上,实现多机并发访问和分布式环境下的多版本(MVCC)
在元数据服务的实现上,PieCloudDB 将系统中的元数据的元组以 key-value 的形式存储到苹果公司开发并开源的 FoundationDB,打造了 mStore(meta data store)。元数据实现了基于 MVCC 的事务隔离级别,并使用FoundataionDB Key的自然排序实现了索引。PieCloudDB 实现了全新的基于Key-value的存储方式来存放系统表,将元数据存储在系统表中,因此用户看到的元数据实际上是一个个系统表。
eMPP 分布式引擎
PieCloudDB 的 eMPP 分布式引擎除了具有高性能并行计算功能,还添加了计算资源的动态扩缩容特性。具体可以被分为三个层面:
- 计算
PieCloudDB 分布式引擎首先是一个 MPP 引擎, 可以将单一的数据分析在集群中并行处理。与传统的MPP 引擎不同的是,PieCloudDB 做到了真正的弹性,可以进行集群大小、集群类型、集群数量的弹性伸缩。同时,PieCloudDB 支持多租户,多用户、多集群,系统中同时可能存在多个计算集群在运行,因此保证不同租户和集群实现隔离性是至关重要的,不同租户和集群不会互相影响,避免用户量的上升导致系统性能的下降,保证了高并发和高可用性。在集群不需要使用的情况下,可以将集群暂停,帮助用户节约成本。
- 存储
PieCloudDB在设计分布式引擎时,还需要考虑到用户数据的存储。用户数据存储的设计上,PieCloudDB 考虑到了多租户的隔离,计算引擎在读取用户数据时,要根据容量和带宽对存储的访问进行独立的伸缩。PieCloudDB 的存储服务也需要保证按使用量付费,做到高可用,支持跨多数据中心复制数据。PieCloudDB 也需要保证数据的一致性,在全局存储一份数据,通过共享存储来实现数据共享,避免拷贝和维护多份数据副本。
- 事务
事务上,PieCloudDB 分布式引擎需要支持包括:
- ACID:支持两种隔离级别(Read Committed 和 Repeatable Read)
- 扩展性:事务管理器无单点性能瓶颈,随着计算节点的增加,系统处理的性能会有近似于线性的提升
- 隔离性:不同租户之间的事务管理器是完全隔离的,避免租户之间的互相影响。当一个租户在进行某个非常耗性能的查询时,也不会影响到其他租户的性能。
- 容错性:当基础设施出现例如CPU、内存、网络等故障时,系统需要做到自动容错,不会出现系统不可用的情况。
用户数据存储
在设计存储引擎时,PieCloudDB 充分考虑到了云平台的特点。这里提到的云平台,不仅仅是公有云平台,还包括私有云、混合云、专有云、容器云等。PieCloudDB 存储引擎的设计还充分考虑到对对象存储的支持,HDFS、本地磁盘等多种存储环境的兼容,以及对不断发展的现代的硬件和存储技术(包括CPU/GPU的高速缓存的访问、数据的局部性优化(SIMD)等)的支持等。
基于这些考虑,PieCloudDB 的存储引擎的设计包括以下几点目标:
- 数据分布的弹性
PieCloudDB 的计算引擎是 eMPP 架构的,存储引擎也需要能够满足计算引擎的动态的扩容与缩容。用户数据以分布式的方式被存储在各个不同的存储单元中,针对不同的云平台,存储单元也略有不同。为了提高查询的效率,从存储资源读取数据时需要避免云存储访问的延时,PieCloudDB的计算资源需要对云存储的数据进行缓存,缓存一部分的本地数据来提高系统查询的速度。
在设计本地数据的缓存时,当进行扩缩容时,需要尽量避免数据移动。例如当计算节点从 4 个扩到 8 个,需要对数据进行再平衡,此时需要尽可能减少在节点间进行大量的数据传输。
- 数据安全性
为了保证数据的安全性,PieCloudDB 通过透明数据加密技术,利用三级密钥来对数据进行实时的加解密。PieCloudDB 的存储引擎实现了行列混存的存储形式。如此设计主要考虑到两个方面:
- 用户的存储成本
用户在云平台上存储大量的数据,会造成存储成本。PieCloudDB 自动选取适用类型的编码,提高压缩效率,减少对象存储的访问开销。
- OLAP 性能
为了避免查询性能的影响,PieCloudDB不仅设计了行列混存的存储引擎,还设计了多级缓存,包括重新定义了数据在内存和存储中的存储格式,避免数据从内存到外存,或从外存到内存读取数据时进行数据的转换。很多数据库都实现了 Analyze 命令,用来收集系统中的统计信息。PieCloudDB 在存储数据时,在文件级别,进行了数据的统计分析。PieCloudDB 智能Analyze可以更好的收集统计信息,帮助查询优化器生成更好的查询计划。
查询优化
作为一款基础软件,数据库在实现分布式化后,查询优化的难度成指数级上升。PieCloudDB 的查询优化器对于云原生环境进行了大量的创新,可以为海量数据集上的复杂 OLAP 查询在有限的时间内提供最优的查询计划。PieCloudDB的查询优化器主要有三个特点:
- 一款分布式优化器
作为一个分布式系统,PieCloudDB 查询优化器充分考虑到了分布式架构的特点,在计算和收集节点间执行时间的基础上进行优化,生成的查询计划可以在计算节点间并行执行。分布式查询优化器可以将执行计划分布到多个更小的计划单元中,提高查询效率。
- 能够处理复杂OLAP查询
作为一款分析型数据库,PieCloudDB 针对复杂OLAP查询进行了多种查询优化。实现了包括OLAP查询中最困难的多表连接的最优顺序查询、针对分析型查询中常见的聚集函数的多阶段聚集优化、利用分区规则进行分区表的静态和动态裁剪优化、针对低效的子查询的提升转换优化、让分布式下的CTE语句可以高效执行的CTE和递归CTE的优化。
- 一款云原生优化器
PieCloudDB 针对云环境的特征,PieCloudDB 提供了更多高阶的优化。包括通过将聚集函数尽量推到查询计划最下层减少执行器处理数据量的聚集下推、以及以及可以在查询时自动跳过一些不需要访问的block来提高查询性能的文件查询裁剪 (block skipping)等。
PieCloudDB 2.1 新版本有哪些新特性?
PieCloudDB 将发布2.1全新版本,新版本主要进行了三个方面的增强:
安全性增强
数据库上云后,数据的安全性是用户最关心的话题之一。PieCloudDB 在2.1版本中将进行大量的数据安全性增强。
通过三级密钥加密技术,加密用户数据,避免被未经许可的人员读取。用户可以通过KMS等密钥管理系统生成主密钥。PieCloudDB 会根据主密钥生成租户密钥,再根据租户密钥生成表密钥。表密钥被用来加密表数据。当数据被写入数据文件中时,PieCloudDB 会针对每个数据页面生成页密钥,从而保证数据存储做到了完全的加密。在进行数据查询时,PieCloudDB 会使用不同的密钥对数据进行解密。透明加密做到了用户无感知,不会影响到用户业务,加解密对性能影响小。加密技术和流程合规,符合数据安全和业务的审计要求。
此外,在云原生安全方面,PieCloudDB 在传输层和缓存数据都进行了加密。在元数据的持久化存储以及用户数据的多副本加密存储上,PieCloudDB 都进行了加强。在计算安全方面,当出现集群失效时,不会影响用户数据,避免用户数据的丢失,无泄漏,同时也保证了事务的完整性。
全链路优化
PieCloudDB 通过全新的存储引擎简墨(JANM)实现了全链路优化。简墨的名称起源于”竹简墨书”,形象的描述了PieCloudDB存储引擎行列混存的架构。列存储实现了更好的压缩比,而行存储保证了每一列的数据不会太大,从而可以将很多数据加载至内存中,从而提高Cache命中率,降低CPU使用率。新的版本中,JAMN 实现了智能 Analyze,可生成更为精确的查询规划统计信息,查询时可以生成更优的查询计划,完成了分布式处理的增强以及动态分配读取文件增强 Dispatch 功能
除了存储引擎简墨(JANM)的重新设计,PieCloudDB 的分布式引擎和查询优化器也做了大量的优化,实现和提升了前文提到的聚集下推、文件查询裁剪(Block Skipping) 的优化性能。
生态建设
PieCloudDB 的 2.1 版本加大了生态建设,增加了对更多云平台的支持,实现了 FDW(Foreign Data Wrapper),使用户可以访问包括但不限于HDFS、MySQL等数据源,同时支持用户自行开发模块来访问新的存储数据源。支持了Kafka 流式数据的导入。并兼容了众多生态组件,包括开源Apache Madlib,PostGIS等。
关于2.1版本的更多特性,很快将在PieCloudDB官网上进行揭秘,欢迎大家的关注。也欢迎大家前往 www.openpie.com/product 申请试用。

|








- 上一条: Excel连接openGauss数据库实操 2023-02-10
- 下一条: 浅析 SeaweedFS 与 JuiceFS 架构异同 2023-02-10
- 【DTCC 2022】云原生数据库PieCloudDB全新eMPP架构是如何炼成的 2023-01-09
- PieCloudDB Database实现云上数据的「坚不可破」 2022-12-02
- PieCloudDB Database 云上商业智能的最佳实践 2023-02-03
- 直播技术干货分享:千万级直播系统后端架构设计的方方面面 2022-04-13
- 大规模业务技术架构设计与战术 2021-10-29