Skywalking分布式追踪与监控:起始篇
Skywalking是由国内开源爱好者吴晟(原OneAPM工程师,目前在华为)开源并提交到Apache孵化器的产品,它同时吸收了Zipkin/Pinpoint/CAT的设计思路,支持非侵入式埋点。是一款基于分布式跟踪的应用程序性能监控系统。另外社区还发展出了一个叫OpenTracing的组织,旨在推进调用链监控的一些规范和标准工作。
OpenTracing
近年各种调用链监控产品层出不穷,呈现百花齐放的态势,为了避免碎片化,促进互操作性,社区诞生了一个叫做OpenTracing的标准化组织。
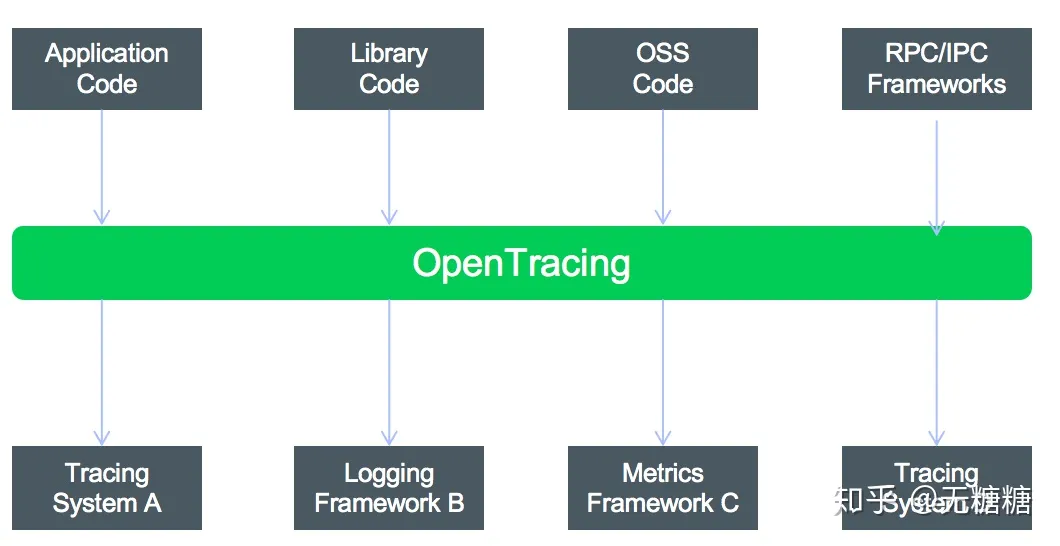
如上图所示:OpenTracing旨在标准化Trace数据结构和格式,其目的是:
- 不同语言开发的Trace客户端的互操作性,Java/.Net/PHP/Python/NodeJs等语言开发的客户端,只要遵循OpenTracing标准,就都可以对接OpenTracing兼容的监控后端。
- Tracing监控后端的互操作性,只要遵循OpenTracing标准,企业可以根据需要替换具体的Tracing监控后端产品,比如从Zipkin替换成Jaeger/CAT/Skywalking等后端。
OpenTracing初衷和方向是好的,但是目前还不明朗,不少调用链监控产品并未明确支持OpenTracning标准。对其后续走势我们可以持续关注。
在构建监控系统时,大家往往在Metrics,Tracing和Logging几个名词和方式之间纠结。 总体说来,我们是在一些通用的名词间纠结。可以通过图表来定义监控的作用域,使各名词的作用范围更明确。比如通过维恩图(Venn diagram)来描述Metrics, tracing, logging三个概念的定义:

Metric的特点是,它是可累加的:他们具有原子性,每个都是一个逻辑计量单元,或者一个时间段内的柱状图。 例如:队列的当前深度可以被定义为一个计量单元,在写入或读取时被更新统计; 输入HTTP请求的数量可以被定义为一个计数器,用于简单累加; 请求的执行时间可以被定义为一个柱状图,在指定时间片上更新和统计汇总。
Logging的特点是,它描述一些离散的(不连续的)事件。 例如:应用通过一个滚动的文件输出debug或error信息,并通过日志收集系统,存储到Elasticsearch中; 审批明细信息通过Kafka,存储到数据库(BigTable)中; 又或者,特定请求的元数据信息,从服务请求中剥离出来,发送给一个异常收集服务,如NewRelic。
Tracing的最大特点就是,它在单次请求的范围内,处理信息。 任何的数据、元数据信息都被绑定到系统中的单个事务上。 例如:一次调用远程服务的RPC执行过程;一次实际的SQL查询语句;一次HTTP请求的业务性ID。
在OpenTracing中,有几个基本概念我们需要提前了解清楚:
1、Trace(追踪):
在广义上,一个trace代表了一个事务或者流程在(分布式)系统中的执行过程。在OpenTracing标准中,trace是多个span组成的一个有向无环图(DAG),每一个span代表trace中被命名并计时的连续性的执行片段。
2、Span(跨度):一个span代表系统中具有开始时间和执行时长的逻辑运行单元。span之间通过嵌套或者顺序排列建立逻辑因果关系。
3、Logs:每个span可以进行多次Logs操作,每一次Logs操作,都需要一个带时间戳的时间名称,以及可选的任意大小的存储结构。
4、Tags:每个span可以有多个键值对(key:value)形式的Tags,Tags是没有时间戳的,支持简单的对span进行注解和补充。
其中单个Trace和各个Span之间的关系:

一个span可以和一个或者多个span间存在因果关系。OpenTracing定义了两种关系:ChildOf 和 FollowsFrom。这两种引用类型代表了子节点和父节点间的直接因果关系。
Skywalking可以理解为实现了OpenTracing规范,同时提供了更加现代化、酷炫的UI,供人们可以对应用更加的直观的监控。
接下来,我们将结合Skywalking的界面来了解如何查看单个Trace:
首先,在Skywalking中,官方针对Java应用封装了一个Segment概念,实质上就是Span数组的封装,为的是更好的表示Java中跨线程间的调用(后续文章将会详细讲到),因此,在Skywalking里面,一次完整的追踪所包含的数据结构应该是:
- Trace = Segment1 + Segment2 + ...... + SegmentN
- 其中每个Segment所包含的数据:Segment = Span1 + Span2 + ...... + SpanN
通过一张官方的截图来讲解:

图中蓝色部分是一个进程调用,代表的是Kafka/test-trace-topic/Consumer这个服务为调用入口,紧随着下面的白色长块则代表跨进程或跨线程的调用块,点击进去并通过浏览器查看返回的数据:
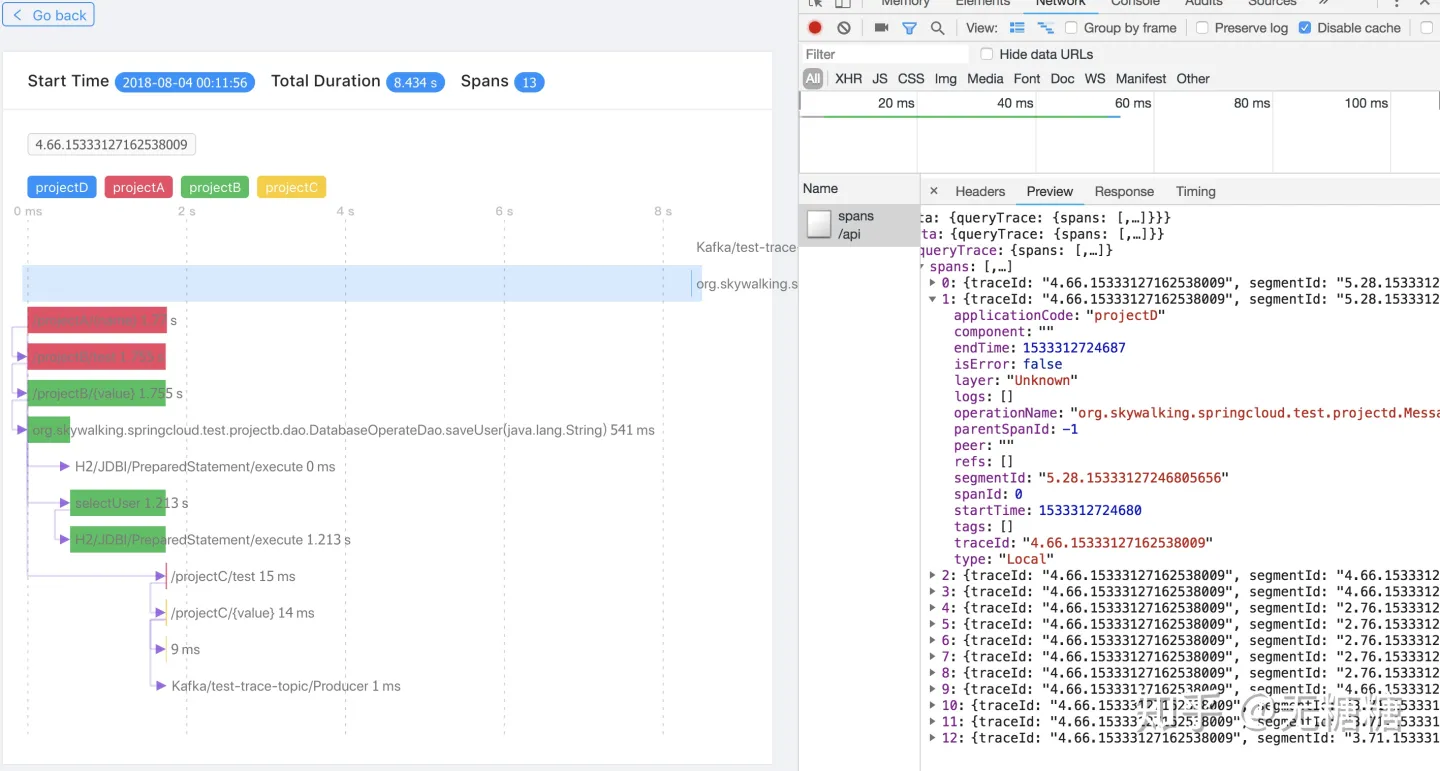
我们可以看到右侧有一组spans数组,数组中每一组数据中都带有traceId,segmentId,parentSegmentId,refs数组,spanId,parentSpanId,type等数据。Skywalking界面上那些层级关联关系就是根据这些数据来进行展示的,比如:
在同一个Segment中,spanId最顶层数值为-1,默认从0开始自增,依次代表层级。即Span与Span时间通过parentSpanId表示关系。Segment与Segment之间通过refs数组中的parentSegmentId表示关系
好了,其实最后一段才是我想表达的东西,顺带将整个东西理清楚记录一下,使用过程中碰到的问题会陆续记录到这里。
文章转自:https://zhuanlan.zhihu.com/p/41252484
如有侵权,将第一时间删除文章内容。
|








- 上一条: JVM参数:带你认识-X和-XX参数 2023-02-07
- 下一条: 百度工程师带你了解Module Federation 2023-02-07
- 分布式事务的十大神坑 2021-07-18
- 每一个程序员,都渴望成为一名分布式系统架构师 2021-07-11
- 灵活运用分布式锁解决数据重复插入问题 2021-07-27
- OpenHarmony HarmonyOS-面向全场景的分布式操作系统 2021-06-27
- 解读Go分布式链路追踪实现原理 2022-07-12


