看这篇就够了丨基于Calcite框架的SQL语法扩展探索
Calcite在大数据系统中有着广泛的运用, 比如Apache Flink, Apache Drill等都大量使用了Calcite,理解Calcite的原理可以说已经成为理解大数据系统中SQL访问层实现原理的必备条件之一。
但是不少人在学习Calcite的过程中都发现关于Calcite的实践案例其实很少,本文就将为大家详细介绍如何基于Calcite框架的SQL语法扩展探索使之更符合你的业务需求,以及扩展SQL在数栈产品的应用实践。
Calcite介绍及用途
Calcite介绍
Apache Calcite是一个动态的数据管理框架,本身不涉及任何物理存储信息,而是专注在SQL解析、基于关系代数的查询优化,通过扩展方式来对接底层存储。
目前Apache Calcite被应用在广泛的数据开源系统中,比如Apache Hive、Apache Phoenix、Apache Flink等。
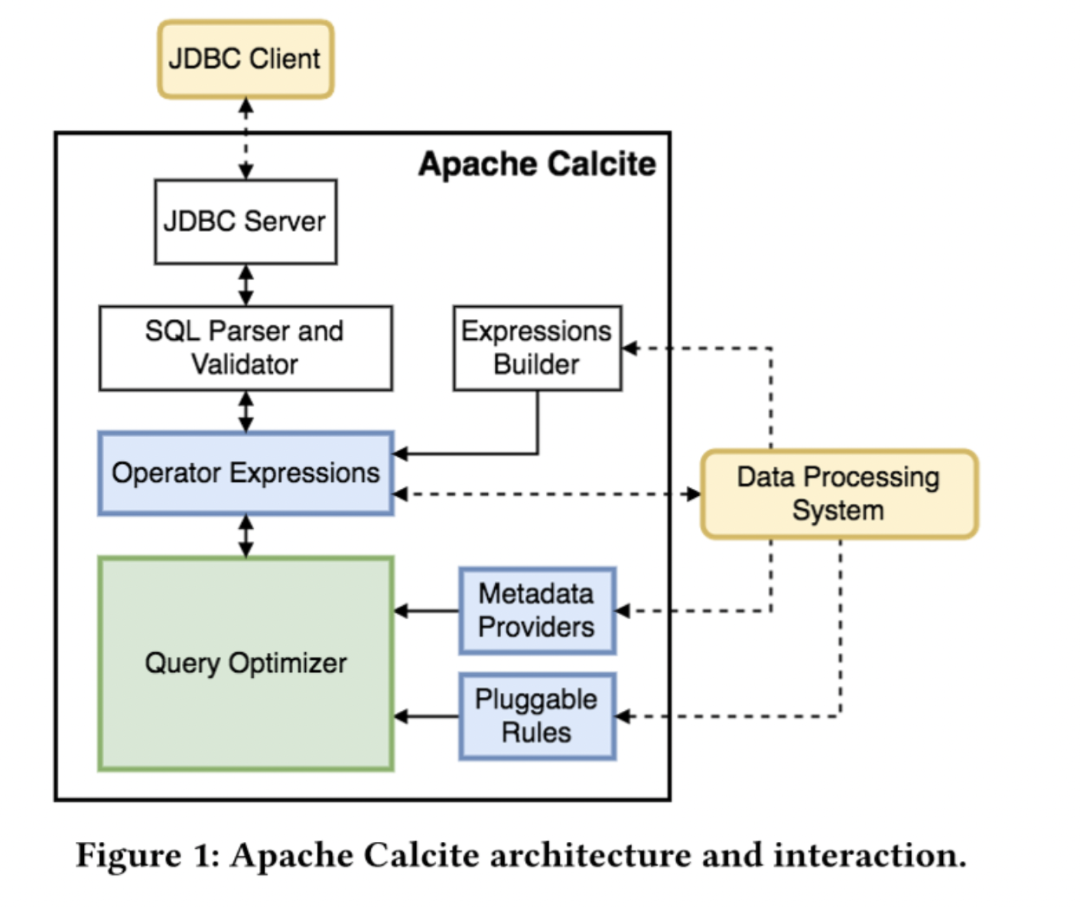
Calcite的用途
Calcite提供了ANSI标准SQL的解析,以及各种SQL 方言,针对来自于不同数据源的复杂SQL,在Calcite中会把SQL解析成SqlNode语法树结构,然后根据得到的语法树转换成自定义Node,通过自定义Node解析获取到表的字段信息、以及表信息、血缘等相关信息。
下图展示了一部分对外提供的接口信息:
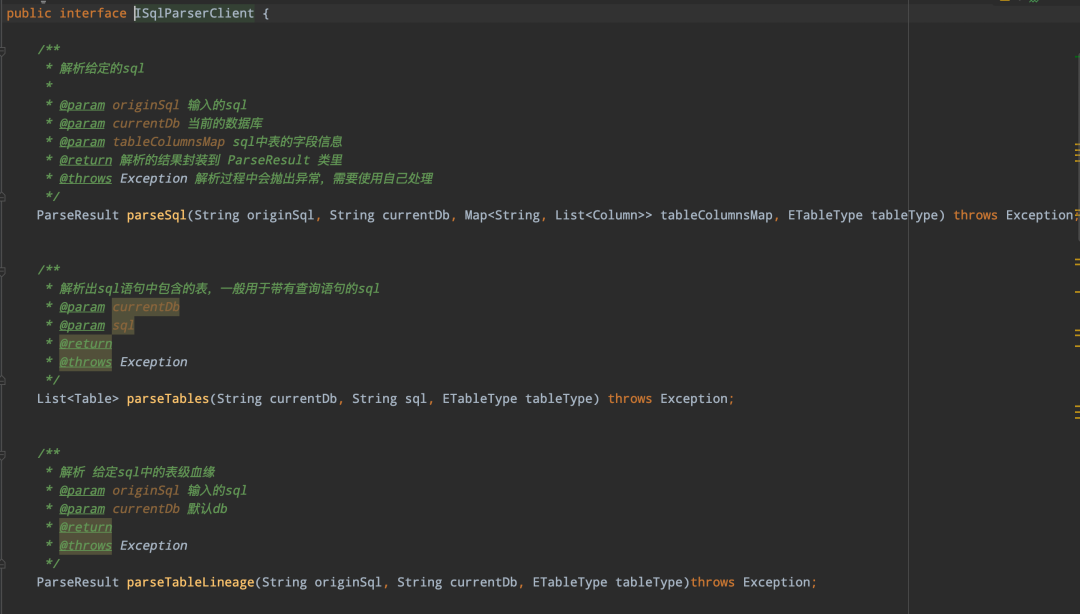
sqlparser 解析模块主要提供了以下几种功能 :
• 解析SQL包含的所有表、字段信息
• 解析SQL的udf函数
• 解析SQL的血缘信息,包括表级血缘、字段血缘
• 解析自定义SqlNode
• api服务变量解析替换
SQL语法扩展
了解完Calcite是什么以及用途后,下面为大家分享Calcite SQL语法扩展的相关内容。
SQL语法扩展背景
在 sqlparser 中进行sql解析的场景中,有两种情况需要使用到自定义扩展,一是Calcite不支持的一些语法;二是在一些场景中存在sql中带有${var}自定义变量语法。
那么针对上面的这两种情况,Calcite的自定义扩展是如何实现的呢?自定义扩展主要涉及到以下三个文件:
• Parser.jj:Parser.jj是一个Calcite核心的语法和词法文件,基于Apache FreeMaker模版,该模版包含着变量,这些变量在编译时可以被替换
• parserImpl.ftl:提供自定义SQL语句、literals、dataType的实现方法
• config.fmpp:该文件是FMPP的配置文件,提供了SQL语句、literals、dataType的接口扩展入口
Calcite使用javacc作为语法解析器,freemaker作为模版,把parserImpls.ftl、config.fmpp、Parser.jj模版合成最终的语法词法文件,最终通过javacc编译成自定义的解析器源码,整体流程如下图所示:

扩展SQL实现
● 工程目录
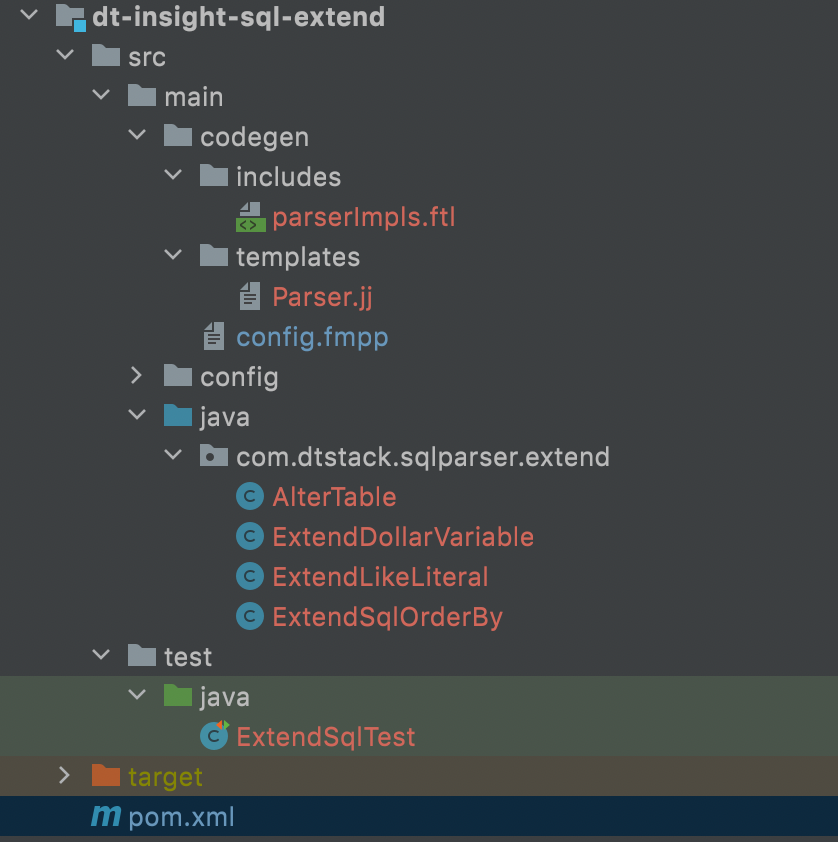
● 扩展sql实现案例
支持以下limit相关语法以及数字可以写成${var}形式:
-> limit count, limit start count
-> limit count offset start
-> offset start limit count
在原生的Calcite解析是支持limit count语法的,但是由于返回SqlOrderBy对象内部类Operator的unparse方法在SQL输出过程中对原始SQL进行了改写,因此需要使用扩展SQL得到正确的SQL。
下面介绍一个limit offset语法扩展样例,扩展SQL如下:
select id, name from test where id > 3 order by id desc limit 1 offset ${offset_val}
整体流程如下:
01
Parser.jj 定义${var}变量的token词法DOLLAR_VARIABLE:
 02
02
Parser.jj 扩展的变量方法接入,下面方法会在解析到limit、offset关键字后面的一个词时进行调用:
 03
03
Parser.jj limit offset在select语法的核心处理逻辑:
-> 定义变量
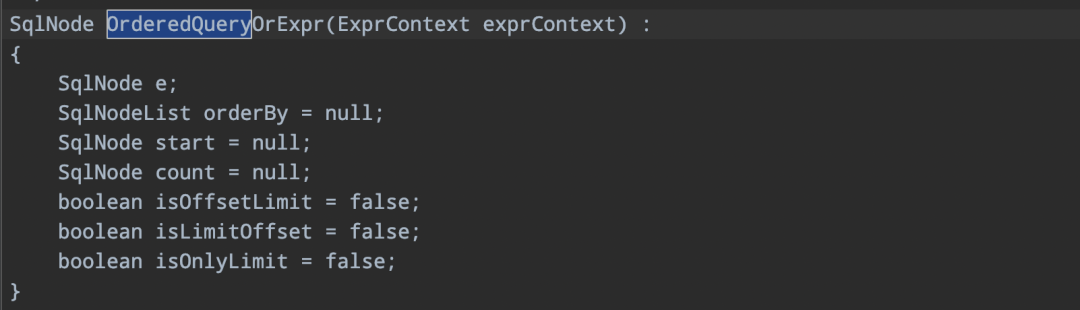 主要定义了三个boolean类型的变量,isOffsetLimit表示offset limit 语法,isLimitOffset表示limit offset语法,isOnlyLimit表示limit count、limit start count语法。
主要定义了三个boolean类型的变量,isOffsetLimit表示offset limit 语法,isLimitOffset表示limit offset语法,isOnlyLimit表示limit count、limit start count语法。
-> 定义处理逻辑
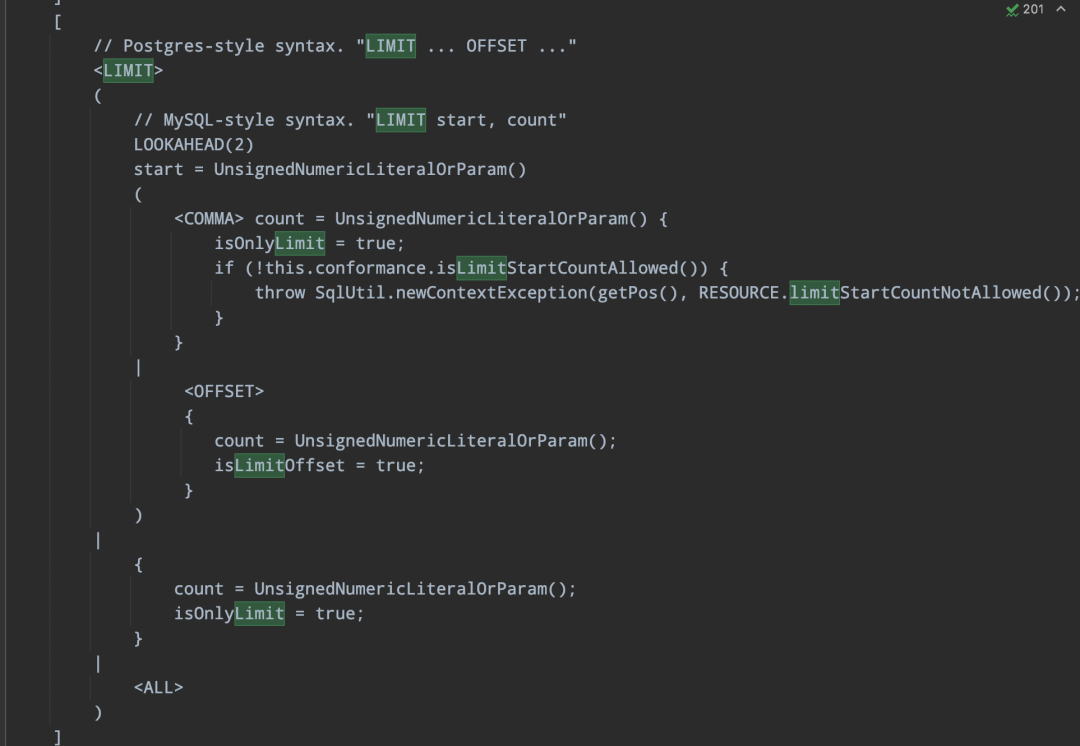
-> 返回自定义SqlNode
 针对符合上面的三个boolean条件时,使用自定义ExtendSqlOrderBy的扩展类。
针对符合上面的三个boolean条件时,使用自定义ExtendSqlOrderBy的扩展类。
04
parserImpl.ftl 定义扩展的SqlNode ExtendDollarVariable:
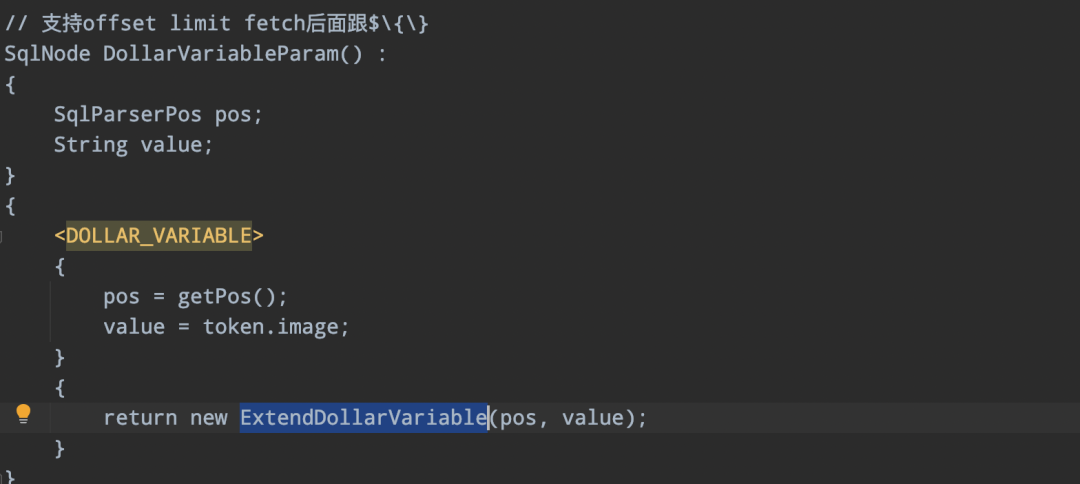 05
05
config.fmpp 定义包以及扩展实现类的import:
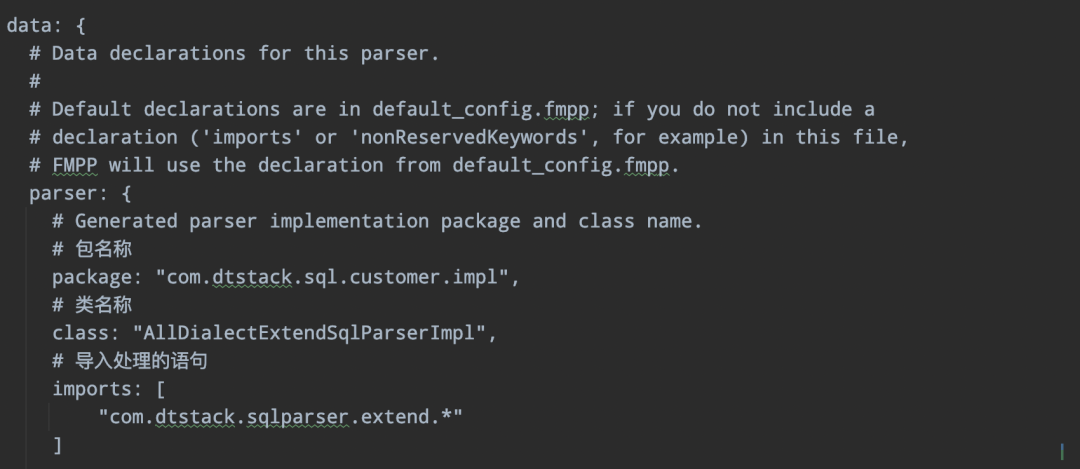 06
06
扩展SqlNode实现:
-> 变量实现sqlNode
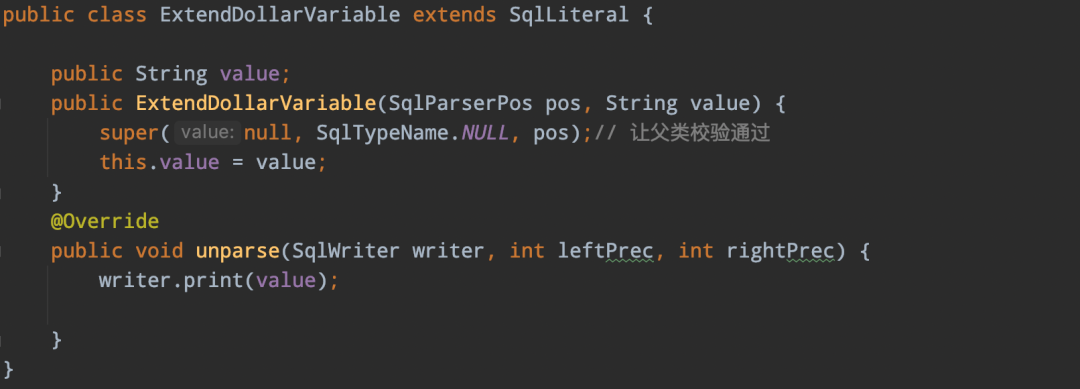
-> 扩展limit实现类ExtendSqlOrderBy,该类实现了SqlOrderBy,并在此基础扩展了limit的SqlNode,以及isOffsetLimit、isLimitOffset、isOnlyLimit三个boolean标识limit的不同语法
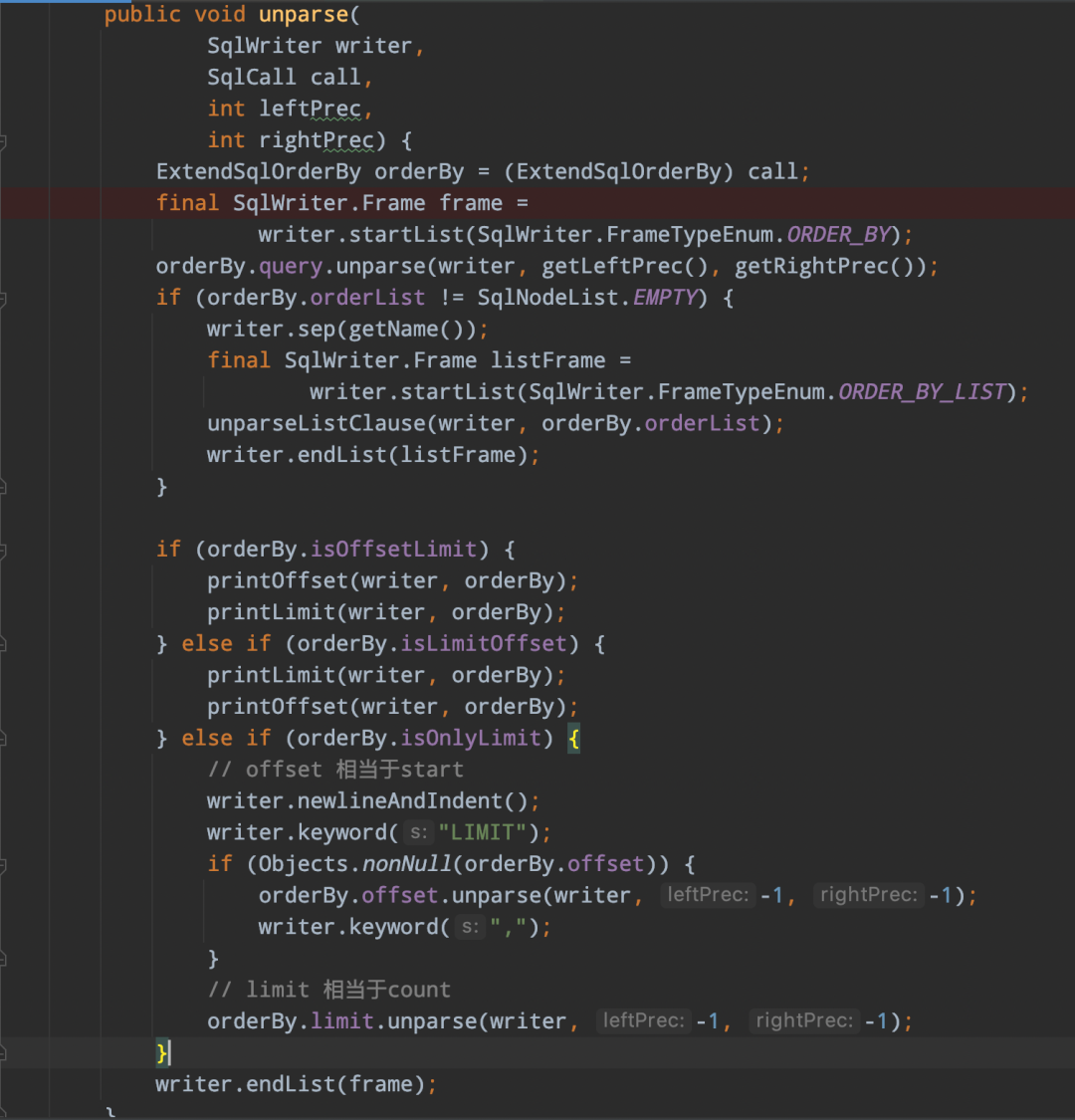
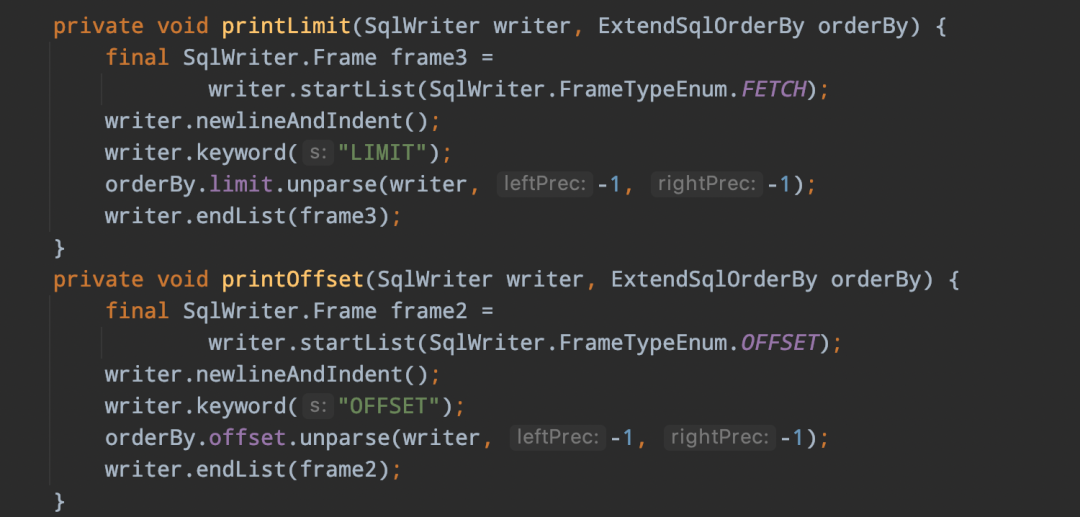
通过上面的这些步骤后,最后解析生成的SqlNode语法树如下所示:

扩展SQL在数栈的应用
目前袋鼠云的底层sqlparser sql解析涉及的子产品应用包括API数据服务、离线开发、客户数据洞察(标签)、实时开发等,虽然大部分针对Calcite的SQL语法扩展相对于上层的产品应用感知不是很明显,但是扩展SQL还是解决了一些痛点,主要如下:
• 逐渐替换底层采用了多种解析工具解析的情况,使维护更简单,减少bug的产生
• 解决一些不支持的语法,避免在上层业务层做处理或者在底层做一些特殊处理
以在API数据服务后续接入的like语法改造为例为大家进行分享,目前的API数据服务中支持like ${var}语法,在执行测试中通过传递like语法来确定执行的模糊匹配方式,例如%xx、xx%、%xx%。
收到客户提出的优化like语法场景,袋鼠云本着客户第一的原则,这种合理的优化需求是采纳的。SQL支持like%${var}、${var}%、%${var}%,这样在执行测试中就不需要输入%了,目前扩展SQL语法已经支持这种优化的like语法,预计在2023年上半年会接入进去,下面通过API数据服务展示当前like SQL和扩展后的SQL差异:
● 当前like ${var}处理
-> 生成API
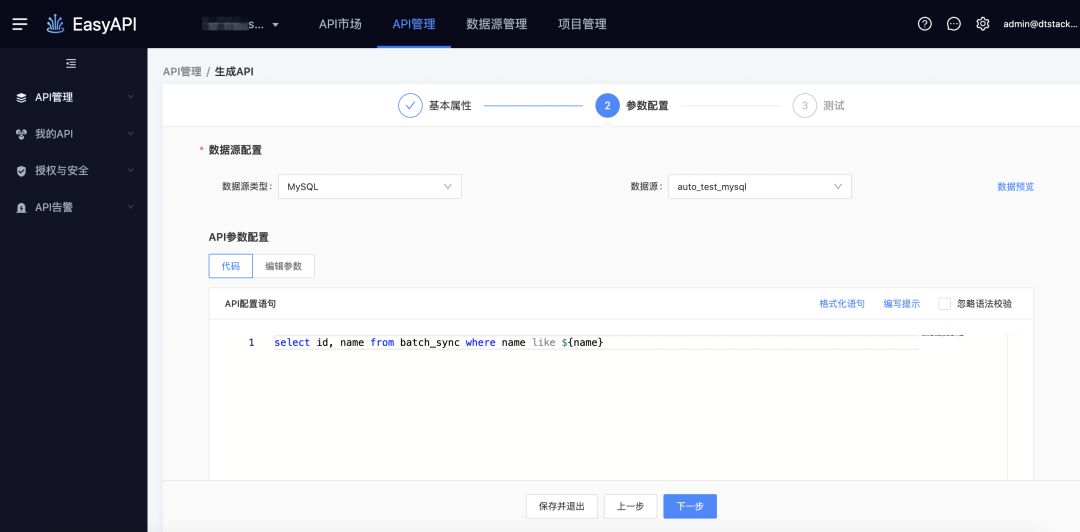
-> 测试执行,模糊匹配需要输入%
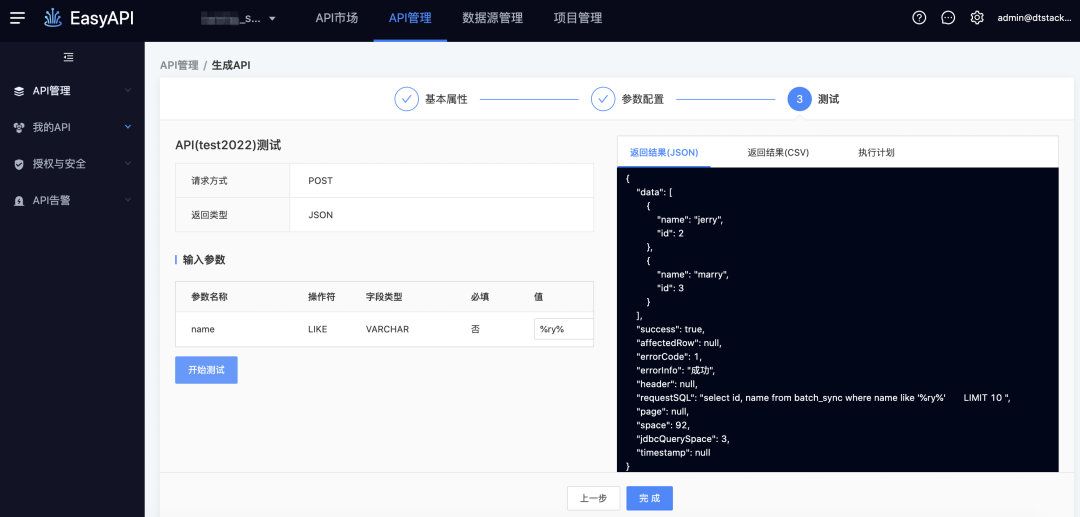
● 扩展like %${var}%
-> 生成API
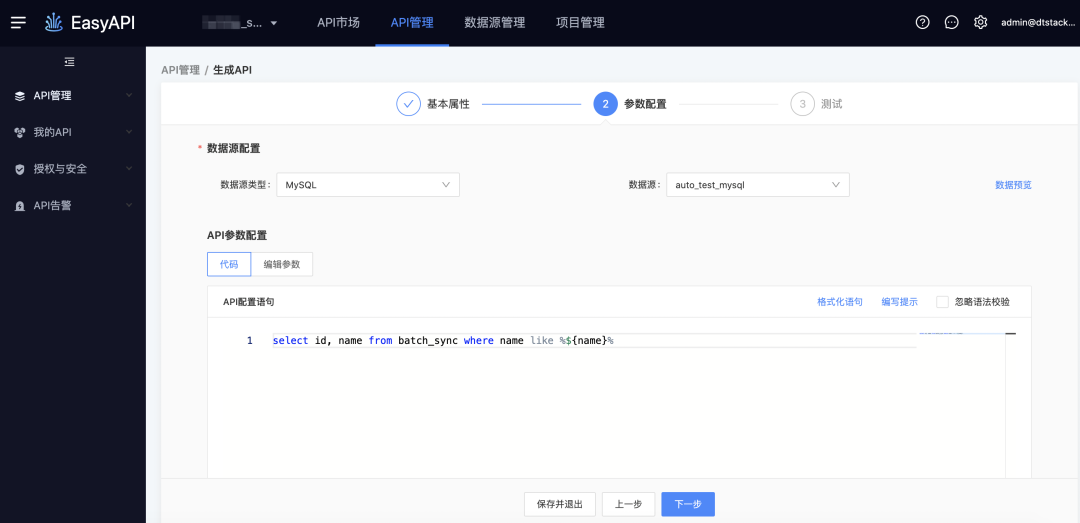
-> 测试执行,由于在SQL阶段已经写了模糊匹配方式,因此可以直接输入值
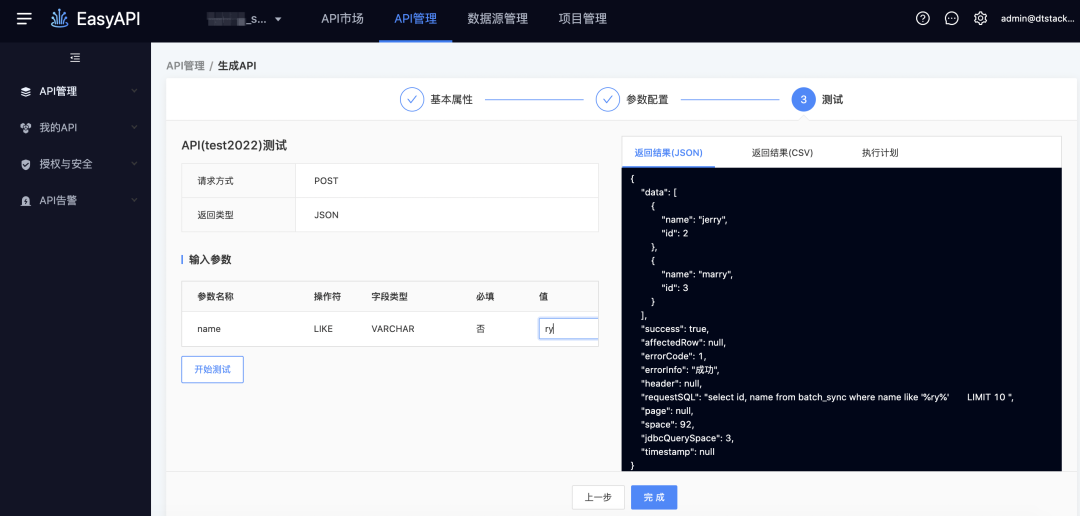
总结规划
相信通过上面的案例后,大家对于Calcite扩展SQL语法的流程应该有了大致的了解,目前在袋鼠云的业务场景中已经扩展了许多语法,在未来还有一些工作需要进行优化:
• 丰富SQL语法,实现不同数据源扩展SQL语法的隔离
• 逐渐通过SQL语法扩展替换掉底层Calcite和druid共同解析的场景,避免维护多套相同的解析,减少线上问题产生
最后如果是初步接触Calcite SQL语法扩展的同学们,建议先熟悉javacc语法。
地址:https://javacc.github.io/javacc/
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
|








- 上一条: 别催了,别催了,这篇文章我一次性把Shell的内容说完 2023-01-13
- 下一条: 看这篇就够了丨基于Calcite框架的SQL语法扩展探索 2023-01-13
- 关于DevOps CI/CD Pipeline,看这篇就够了 2022-01-11
- 搞透IOC,Spring IOC看这篇就够了! 2022-09-26
- SQL 查询并不是从 SELECT 开始的 2021-07-16
- 从来都没有理解JavaScript闭包? 今天非把你教会不可! 看这一篇就够了,全程大白话! 2022-02-22
- 必须知道的SQL语句不走索引时的排查利器 2021-07-11


