【DTCC 2022】云原生数据库PieCloudDB全新eMPP架构是如何炼成的
12月14-16日,第十三届中国数据库技术大会(DTCC 2022)在线上隆重召开。拓数派赞助并参与了数据库盛会DTCC,在会议中,拓数派CTO 郭罡分享了《云原生数据库 PieCloudDB eMPP架构设计与实现》的主题演讲。在演讲中,郭罡分析了传统分布式MPP架构的痛点,介绍了云原生数据库PieCloudDB的eMPP架构的设计背景与重要功能组件。本文整理自现场演讲内容。
相关PPT欢迎访问拓数派官网链接进行预览和下载。演讲视频欢迎访问B站链接。
传统分布式MPP架构痛点
MPP(Massive Parallel Processing,大规模并行处理),一直被誉为当今数据库的主流架构,被广泛用于众多数据库产品中,包括Greenplum、Teradata、Vertica等。MPP分析型数据库针对分析工作负载进行了大量优化,以满足用户聚合和处理大型数据集的需求。它会将任务并行的分布到多个服务器和节点上,并在完成计算后,将结果返回并汇总,从而完成对海量数据的分析处理。
然而,传统分布式MPP架构存在很多瓶颈,我们将客户的真实生产场景中遇到的问题进行归纳,总结出5个痛点:
- 缺乏弹性
传统数据仓库的计算和存储是紧密耦合的,计算资源和存储资源按某一比例强绑定,因此用户在扩容时,必须同时扩容计算资源和存储资源,在扩容、运维、迁移上都存在一定的挑战。当企业遇到负载高峰时刻或需要紧急得到某个报表结果时,传统数据仓库无法及时扩资源,导致大数据系统无法弹性、快速的分析业务数据,错失了充分挖掘数据价值所带来的商业机会。
- 成本高昂
传统数据库价格高昂的软硬件、开发运维人员的高昂薪资需要企业进行巨大的前期投入。在我们与客户接触的过程中,经常发现客户的生产环境资源利用率,无论是存储或是计算资源往往不尽人意。随着存储和工作负载需求的日益增长,面临数据库的扩容和升级时,由于传统数据库架构存储和计算的紧密耦合,往往需要企业花费巨大的运维和时间成本,且操作繁琐;
- 木桶效应
传统MPP数据库架构存在”木桶效应”,数据库集群整体执行速度取决于最”短板”节点的性能。因此,一个节点的表现往往会”拖垮”整个集群的性能,导致查询速度变慢。 虽然理论上可以针对这一情况进行优化,但往往都是”治标不治本”。随着时间的推移,业务的增长,企业往往需要在1-2年后对集群增加计算节点,此时,无论新的计算节点性能如何优异,集群总体性能都会受制于老的节点。因此真实生产环境中,我们常常见到客户在需要扩容时,采取重新新建集群的方式。
- 数据孤岛
随着业务的发展,数据量的增加,和信息化建设的需求,企业会为不同部门建设相应的业务信息化系统。我们在很多真实客户生产环境中,常常看到企业有成百上千个集群,但这些集群的元数据往往都是一样的。这种情况下,很多元数据在不同集群间会存在不一致的版本信息。如果企业需要做跨集群的访问,往往非常困难,会造成数据孤岛的存在。
- 运维成本
对于传统MPP数据库,企业往往会需要配备运维人力,且对运维、开发人员要求高,需要相关人员掌握复杂的技术栈,技术的更新迭代迅速,需相关人员保持积极的知识更新。相关人才市场较小,人才匮乏。高昂的学习成本造成用户使用过程中性能差、故障率高、故障修复时间长等问题;
正是因为传统分布式MPP架构的这些痛点,我们认为企业急需一款全新的eMPP云原生数据库。
云解决了什么?
随着数据量和计算能力的爆发式增长,云计算技术的迅猛发展,基础软件尤其是数据库软件上云已大势所趋, 那么云为数据库软件解决了什么问题呢?
借助于云上分布式存储,数据库软件可以实现解耦存储;通过KVM等虚拟化技术,以及构建之上的IaaS系统,数据库可以实现计算层的解耦,让用户可以做到按需启动虚拟机。在存储和计算解耦后,资源可以完成池化,按需使用。云计算让用户能够专注于使用,将运维等工作交给IaaS/SaaS厂商。
上云≠云原生
虽然数据库上云已经是大势所趋,但上云并不等于云原生。业界经常会对上云和云原生两个概念有所混淆, 我们认为:如果仅仅是将数据库在云上进行部署,并不是真正的云原生。云原生需要满足以下几个条件:
- 计算和存储弹性:业界经常提到”存算分离”,在实现存算分离后,存储资源和计算资源都要做到弹性伸缩,按需付费。但这只是实现计算和存储弹性的第一步,
- 多租户隔离:云上存储资源和计算资源需要做到彼此隔离,保证数据安全。
- 智能化云原生平台:一款云原生数据库,除了底层架构,一款云原生数据库的用户操作也需要是”云原生”的。智能化可视化平台可以简化用户的操作,让用户得以用云原生的思维操作数据库。
为什么选择PieCloudDB
基于这样的设计思路,全新的云原生数据库 PieCloudDB Database 诞生了。PieCloudDB是一款全新的eMPP分布式云原生分析型数据库,通过重新打造云上的数据库内核,突破了PC时代计算平台的限制,实现云上存算分离。在云上,计算资源可按需启动,对计算模型以更低成本提供存储和计算资源,帮助企业的业务模型发现新的洞察或提高精准度,从而建立竞争壁垒。
PieCloudDB 重要特点如下:
eMPP
PieCloudDB Database 重新打造了全新的eMPP分布式架构,继承了传统MPP架构分布式、海量数据并行处理的优势,解决了前文提到的MPP传统架构的痛点。
这里的”e”是指elastic,弹性。PieCloudDB 做到了计算资源的横向和纵向的弹性伸缩。这里的”横向”是指节点数的增多,而”纵向”是指虚拟机规格的提升。除了计算资源上的弹性,PieCloudDB 还实现了第三个弹性维度:多集群。由于用户数据和元数据都是共享的,用户数据被存储在对象存储上,而元数据被分布式KV存储管理,PieCloudDB 做到了真正的 ”serverless” 无状态。
全面的SQL兼容度
PieCloudDB 高度兼容SQL:2016标准,完全支持SQL:1992标准、大部分的SQL:1999和部分SQL:2003标准(主要支持其中的OLAP 特性),支持包括窗函数、汇总、立方和各种其他表达功能。此外,PieCloudDB 实现了友好的用户接口,完全支持和认证标准数据库接口(PostgreSQL、 SQL、ODBC、JDBC 等) 。
云原生,云中立
PieCloudDB 实现存算分离,用户数据被存储在对象存储中,支持按需付费。PieCloudDB 实现了云中立,没有和任何一款云平台绑定,为用户提供更大的灵活性,可以按用户需求被部署在行业云、私有云、公有云、混合云等云平台上。 此外,PieCloudDB 也支持HDFS,NAS等文件系统。
完备的事务支持
PieCloudDB实现了完备的事务支持,兼具数据仓库的标准SQL、ACID、和数据湖的大规模异构数据存储等功能,并具备了RR和RC的隔离级别。
安全可靠
PieCloudDB开发团队早在设计初期就将数据安全作为重要的设计目标,通过透明加密、可视化角色与权限管理、SQL标准和标准数据库接口的兼容等多种安全技术全方位保证数据安全,实现了「Unbreakable」(坚不可破),做到了真正的安全可靠。此外,PieCloudDB 分布式对象存储多副本多可用区进一步保证数据安全,整个数据库只有一份数据,有效避免了数据不一致。
PieCloudDB在整个架构设计上充分考虑到了各个节点的高可用,避免单点故障,用户使用上感觉更可靠。
很快,PieCloudDB 将支持Time Travel(时间溯回)功能,用户借助该功能可以查询”回收站”数据,为用户的数据安全“添砖加瓦”。
完善的生态
PieCloudDB 原生支持PostgreSQL/Greenplum 生态组件,兼容包括 PostGIS、in Database AI 组件 MADlib、JSON、Text 等。PieCloudDB 对各种外表数据源联邦查询组件天然支持,实现了高性能的实时ETL/ELT功能,原生支持Kafka数据导入和查询,在PieCloudDB 侧导入实现exactly once 语义。
PieCloudDB也在打造自己的生态体系,通过创建生态工具、建立合作伙伴生态网络、打造活跃的技术和用户社区等举措,为用户带来更便捷的使用体验。
PieCloudDB:云原生数据库的设计与打造
PieCloudDB的内核架构简介优雅,从上而下被分为元数据层、弹性计算层和共享存储层。内核主要组件如下:
元数据管理
PieCloudDB的元数据以key-value的形式被存储在开源数据库 FoundationDB 中。FoundationDB是一个开源的 NoSQL 的KV数据库,PieCloudDB 利用 FoundationDB Key的自然排序实现索引。同时,基于MVCC,PieCloudDB 也实现了RR和RC的事务隔离级别。
PieCloudDB 的多个集群(虚拟数仓)共享一份元数据,是PieCloudDB 得以实现存算分离的很重要的一个原因。 PieCloudDB 借助FoundationDB 的KV特性、可串行事务、watcher机制等特性,将除元数据以及将包括锁、事务等在内的临时状态存储在了 FoundationDB 中。FoundationDB 具有高可用和备份恢复设计,保证了元数据的可靠性和可用性。
为了避免元数据被存储在远端会造成 FoundationDB 集群负担,避免网络延迟,加速查询优化, PieCloudDB 以 Postgres 原生的元数据缓存概念为基础,优化重构实现了适用于多集群架构的元数据层全新的缓存阶段,有效减少了访问元数据服务器带来的网络通信开销和元数据服务器的负载。有效提高元数据访问的速度,从而提高了数据库系统性能。
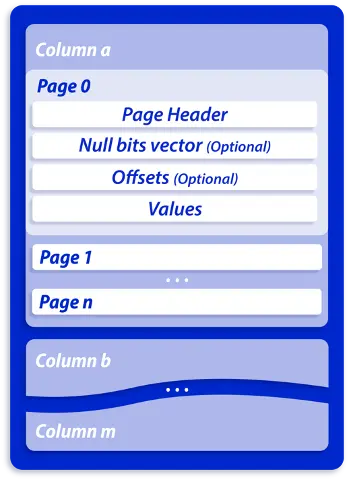
用户数据存储引擎
PieCloudDB 的用户数据以PAX(行列混存)的数据格式被存储在对象存储中。在一个page中,数据按列存储,从而得以配以高效的压缩,节省存储空间。同时,PieCloudDB 以 block 文件为一个存储单位。这同时也是一个 MVCC 的单位,即一个 block 对于一个事务的状态是可见与不可见二选一的,不存在中间状态。
此外,PieCloudDB database 的存储中存在大量辅助信息,可被用于计算优化,在设计之初,我们充分考虑了高效和精准的统计信息收集、存储和计算成本、以及包括SIMD,Cache Line,Data Skipping,预聚集等计算优化的实现等多个方面,期望能打造一个优质的用户数据存储引擎。
很多用户可能会对”将数据放在远程,是否会影响对PieCloudDB的性能”产生疑问。PieCloudDB 在设计之初,充分考虑到了远程访问数据性能和成本的平衡。为了解决这一问题,PieCloudDB 做了大量的工作:
- 数据和/或辅助信息缓存,同时一致性Hash减少数据移动。
- 读取优化:例如并行、异步等,避免网络延迟对性能造成影响
- 计算优化:PieCloudDB实现了并将持续进行大量计算优化,包括聚集下推、Block Skipping、预计算等
- 复杂的OLAP查询:如果不是IO瓶颈,并不会受制于数据被存储在远程或本地。
计算引擎
PieCloudDB 实现了MPP弹性计算引擎,做到了用户的按需付费、租户隔离、高可用、高并发等功能。
此外,PieCloudDB 打造了基于 eMPP 架构的云原生分布式优化器,为海量数据集上的复杂OLAP查询提供最优的查询计划。在优化器的打造时,PieCloudDB 针对分布式、复杂OLAP、和云原生场景做了大量的思考和设计,实现了包括多表连接的最优顺序、多阶段聚集、分区表的静态和动态裁剪、相关子查询的提升转换、CTE和递归CTE的优化等查询优化。
此外,PieCloudDB还实现了大量的针对复杂OLAP查询的高阶优化,以聚集下推为例,PieCloudDB通过把聚集操作下推到连接操作之前去执行,从而极大的减少连接操作需要处理的数据量,使得查询性能显著提升。在某些场景下,可以得到百倍千倍的性能提升。
以下面两个表join后聚集运算为例。正常情况下,处理顺序是将两个表做完join后,通过where 条件过滤,在做完 group 分组后再做聚集。但如果这么处理,两个表的join做聚集会涉及很大的数据量。通过聚集下推后,聚集被下推至最下面的a表上,此时和b表做join的是已经完成聚集操作的数据,数据量会被大大减少,从而大大提高查询性能。
SELECT a.i, SUM(a.j) FROM agg_pushdown_t a, agg_pushdown_t b WHERE a.i = b.i GROUP BY 1;
QUERY PLAN
---------------------------------------------------------------------------
Gather Motion 3:1 (slice1; segments: 3)
-> Finalize HashAggregate
Group Key: a.i
-> Redistribute Motion 3:3 (slice2; segments: 3)
Hash Key: a.i
-> Hash Join
Hash Cond: (b.i = a.i)
-> Seq Scan on agg_pushdown_t b
-> Hash
-> Broadcast Motion 3:3 (slice3; segments: 3)
-> Partial HashAggregate
Group Key: a.i
-> Seq Scan on agg_pushdown_t a
PieCloudDB团队正在不断迭代产品,更多高阶计算功能将很快与用户见面:
- Block Skipping
PieCloudDB 将在下一版本中实现 Block Skipping 的优化机制,在数据库运行查询语句时,通过预计算每个块(block)中列聚集信息,在执行期间跳过非必要的数据块,减少数据读取量提高查询性能。
- 预计算
PieCloudDB 将很快支持预计算功能。在查询的过程中,PieCloudDB 可以根据企业查询的特点预先计算一些重要的查询结果,从而避免在查询过程中的计算,提高查询效率。
更多计算引擎的工作也正在研发中,包括SIMD,runtime filter,late materization等,相信会给用户带来更多惊喜。
智能化云原生平台
作为一款云原生数据库,PieCloudDB在设计智能化云原生平台之初,就希望这款数据服务平台可以提供云原生的使用体验,降低用户、运维和管理的使用门槛。
面向用户,PieCloudDB 云原生平台通过简介清晰的UI,清晰的功能引导和明确的信息组织分层,为用户提供了丰富的数据洞察能力,做到了开箱即用,让用户离数据分析更近,离繁琐的操作更远。
面向运维,PieCloudDB 云原生平台全面拥抱容器化技术,可以适配多种环境。已支持私有信创环境和多云环境,既实现私有环境离线部署,也可充分利用公有云技术设施。可以降低了部署门槛,做到数据库维护平台托管,让PieCloudDB 在不同的基础设施都能发挥实力。
面向管理,PieCloudDB 云原生平台支持快速启动集群,随时可以关停,随时可以回收,结合集群操作记录,用户可以用最低的成本完成数据分析。通过可视化界面让管理更轻松,让数据分析运行更透明。
PieCloudDB 团队正在不断迭代产品,自10月24日推出社区版和企业版后,很快将推出新的版本,希望能让用户专注于应用,打造可靠、高效、简单、完备的SQL数据平台。
|








- 上一条: 一站式云原生体验|龙蜥云原生ACNS + Rainbond 2023-01-09
- 下一条: 【DTCC 2022】云原生数据库PieCloudDB全新eMPP架构是如何炼成的 2023-01-09
- DTCC 2021 黄东旭:从 DB 到 DBaaS,数据库技术的当前和未来 2021-10-27
- DTCC 干货分享:Real Time DaaS - 面向TP+AP业务的数据平台架构 2021-10-21
- PieCloudDB Database实现云上数据的「坚不可破」 2022-12-02
- 人物 | 陈兴振:58同城机器学习平台资源使用率优化实践 2022-01-11
- 2022年10月国产数据库大事记-墨天轮 2022-11-04