解读重要功能特性:新手入门 Apache SeaTunnel CDC
引言
点亮 ⭐️ Star · 照亮开源之路
https://github.com/apache/incubator-seatunnel

为什么说 CDC 是SeaTunnel平台中的一个重要功能特性?今天这篇文章跟大家分享一下 CDC 是什么?目前市面上的 CDC 工具现有的痛点有哪些?SeaTunnel面对这些痛点设计的架构目标是什么?另外包括社区的展望和目前在做的一些事情。
总体来说,市面上已经有这么多 CDC 工具了,我们为什么还要重复去造一个轮子?
带着这个疑问,我先给大家简要介绍下 CDC 是什么! CDC 的全称是 Change Data Capture,它就是一个数据变更捕获。变更数据捕获 (CDC) 使用 Server 代理来记录应用于表的插入、更新和删除活动。 这样,就可以按易于使用的关系格式提供这些更改的详细信息。 将为修改的行捕获列信息以及将更改应用于目标环境所需的元数据,并将其存储在镜像所跟踪源表的列结构的更改表中。
CDC的使用场景
异构数据库之间的数据同步或备份 / 建立数据分析计算平台
在 MySQL,PostgreSQL,MongoDB 等等数据库之间互相同步数据,或者把这些数据库的数据同步到 Elasticsearch 里以供全文搜索,当然也可以基于 CDC 对数据库进行备份。而数据分析系统可以通过订阅感兴趣的数据表的变更,来获取所需要的分析数据进行处理,不需要把分析流程嵌入到已有系统中,以实现解耦。
微服务之间共享数据状态
在微服务大行其道的今日,微服务之间信息共享一直比较复杂,CDC 也是一种可能的解决方案,微服务可以通过 CDC 来获取其他微服务数据库的变更,从而获取数据的状态更新,执行自己相应的逻辑。
更新缓存 / CQRS 的 Query 视图更新
通常缓存更新都比较难搞,可以通过 CDC 来获取数据库的数据更新事件,从而控制对缓存的刷新或失效。
而 CQRS 是什么又是一个很大的话题,简单来讲,你可以把 CQRS 理解为一种高配版的读写分离的设计模式。举个例子,我们前面讲了可以利用 CDC 将 MySQL 的数据同步到 Elasticsearch 中以供搜索,在这样的架构里,所有的查询都用 ES 来查,但在想修改数据时,并不直接修改 ES 里的数据,而是修改上游的 MySQL 数据,使之产生数据更新事件,事件被消费者消费来更新 ES 中的数据,这就基本上是一种 CQRS 模式。而在其他 CQRS 的系统中,也可以利用类似的方式来更新查询视图。
现有CDC组件
| 开源组件 | Canal | Debezium | Flink CDC |
|---|---|---|---|
| 支持数据库 | 仅支持MySQL | 支持MySQL、Postgre SQL、Oracle 等 | 支持MySQL、Postgre SQL、Oracle 等 |
| 同步历史数据 | 不支持 | 单并行锁表 | 多并行无锁 |
| 输出端 | Kafka、RocketMQ | Kafka | Flink Connector |
Canal
数据库它仅支持MySQL,不支持同步历史数据,只能同步增量数据,输出端除了支持 canal client/adapter(适配工作量很大),还支持了的Kafka 和 RocketMQ。
Debezium
支持的数据库比较多,不仅支持MySQL,PG,Oracle,还支持其它 Mongo DB 等数据库,同时支持同步历史数据,不过历史数据读取方式是:一个快照读整个表,如果你表很大,就会像sqoop一样读特别久。如果中途失败了,需要从头开始读,这样会出现一些问题。而且输出端上支持的就更加少,仅仅支持通过 Kafka 输出。
Flink CDC
Flink CDC 和前两个定位上就不一样。它实际就是 Flink 生态的 connector,就是连接器组。目前也支持比较多的数据库,像 MySQL PG,Oracle, Mongo 这些数据库都是支持的。
相对于前面的开源组件,它持一个多边形无锁的算法。当然它也是参考到 Netflix DBLog 的无锁算法。因为它是基于 Flink 生态的,所以它输出端就比较多。只要是 Flink 生态有的connector,支持Upsert的Connector都是可以使用的。当然它也会存在很多问题,这个问题就是后面我会提到的。
现有组件存在的痛点
单表配置
如果用过Flink CDC 的朋友就会发现,我们需要对每一个表进行配置。比如我们想同步 10 张表,就要写 10 个 source 的SQL, 10 个 sink 的 SQL,如果你要进行 transform,就还要写 transform 的 SQL 。
这个情况下,小数量的表手写还可以应付,如果数量大可能就出现类型映射错误的问题,或者参数配置错误的问题,就会产生很高的运维成本(配置麻烦)。而 Apache SeaTunnel 定位就是一个简单易用的数据集成平台,我们期望解决这个问题。
不支持 Schema Evolution
支不支持 schema 的变更。实际上像Flink CDC 和 Debezium,两者支持 DDL 事件发送,但是不支持发送到Sink,让 Sink 做同步变更。或者 Fink CDC能拿到事件,但是无法发送到引擎中,因为引擎不能基于 DDL 事件去变更 transform 的 Type information ,Sink 没办法跟着 DDL 事件进行变更。
持有链接过多
如果有 100 张表,因为 Flink CDC 只支持一个 source 去同步一张表,每一张表都会使用一个链接,当表多的时候,使用的链接就特别多,就会对源头的 JDBC 数据库造成了很大的连接压力,并且会持有特别多的Binlog,也会像 worker 这种,也还会造成重复的日志解析。
SeaTunnel CDC架构目标
SeaTunnel CDC是基于市面上现有的 CDC 组件的优缺点,以及相关痛点问题做的架构设计。
- 支持基础的CDC
- 支持无锁并行快照历史数据
- 支持日志心跳检测和动态加表
- 支持分库分表和多结构表读取
- 支持Schema evolution
支持增量日志的读取,还至少要能够支持无锁并行快照历史数据的能力。
我们期望能够减少用户的运维成本,能够动态的加表,比如有时候想同步整个库,后面新增了一张表,你不需要手动去维护,可以不用再去改Job配置,也不用停止Job再重启一遍,这样就会减少很多麻烦。
支持分库分表和多结构表的读取,其实这也是我们最开始提到的每个表单独配置的问题。并且还支持 Schema evolution, DDL 的传输,还有在引擎中能支持 schema evolution 的变更,能够变更到 Transform 和 Sink 上面去。
CDC 基本流程
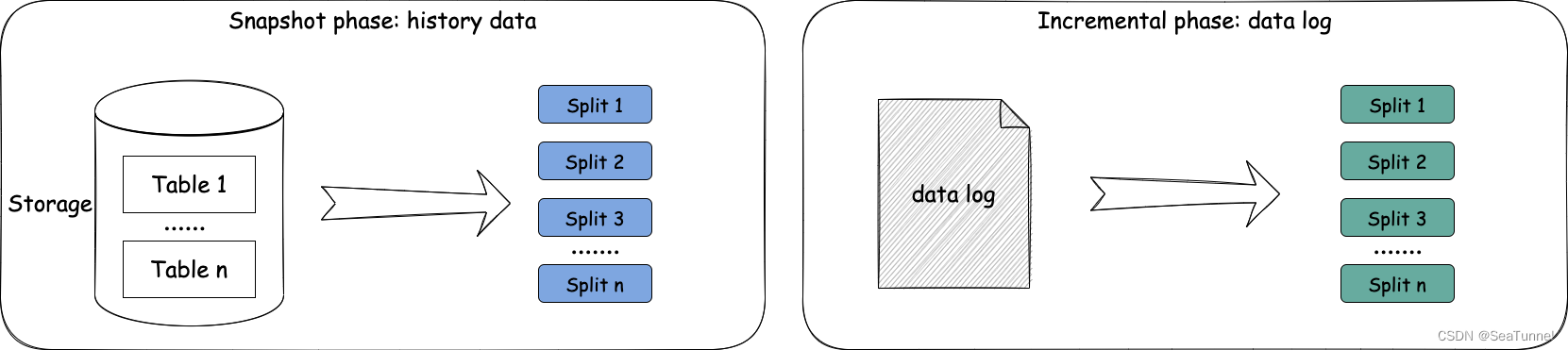
CDC基础流程包含:
-
快照阶段:用于读取表的历史数据
- 最小Split粒度:表的主键范围数据
-
增量阶段:用于读取表的增量日志更改数据
- 最小Split粒度:以表为单位
快照阶段
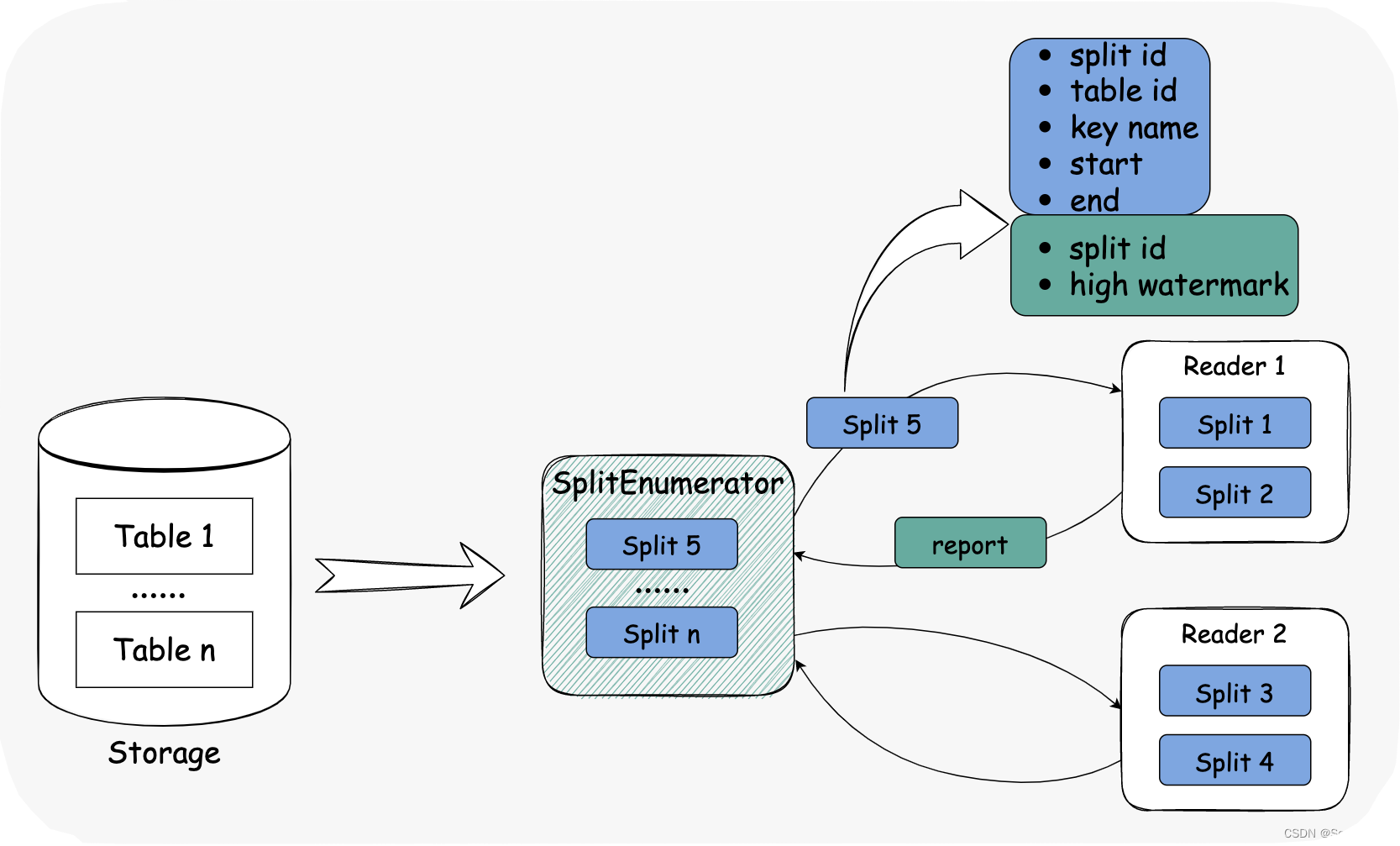
枚举器生成一个表的多个 SnapshotSplit,并将它们分配给 reader。
// pseudo-code.
public class SnapshotSplit implements SourceSplit {
private final String splitId;
private final TableId tableId;
private final SeaTunnelRowType splitKeyType;
private final Object splitStart;
private final Object splitEnd;
}
当 SnapshotSplit 读取完成时,读取器将拆分的高水位线报告给枚举器。当所有 SnapshotSplit 都报告高水位线时,枚举器开始增量阶段。
// pseudo-code.
public class CompletedSnapshotSplitReportEvent implements SourceEvent {
private final String splitId;
private final Offset highWatermark;
}
快照阶段 - SnapshotSplit 读取流程
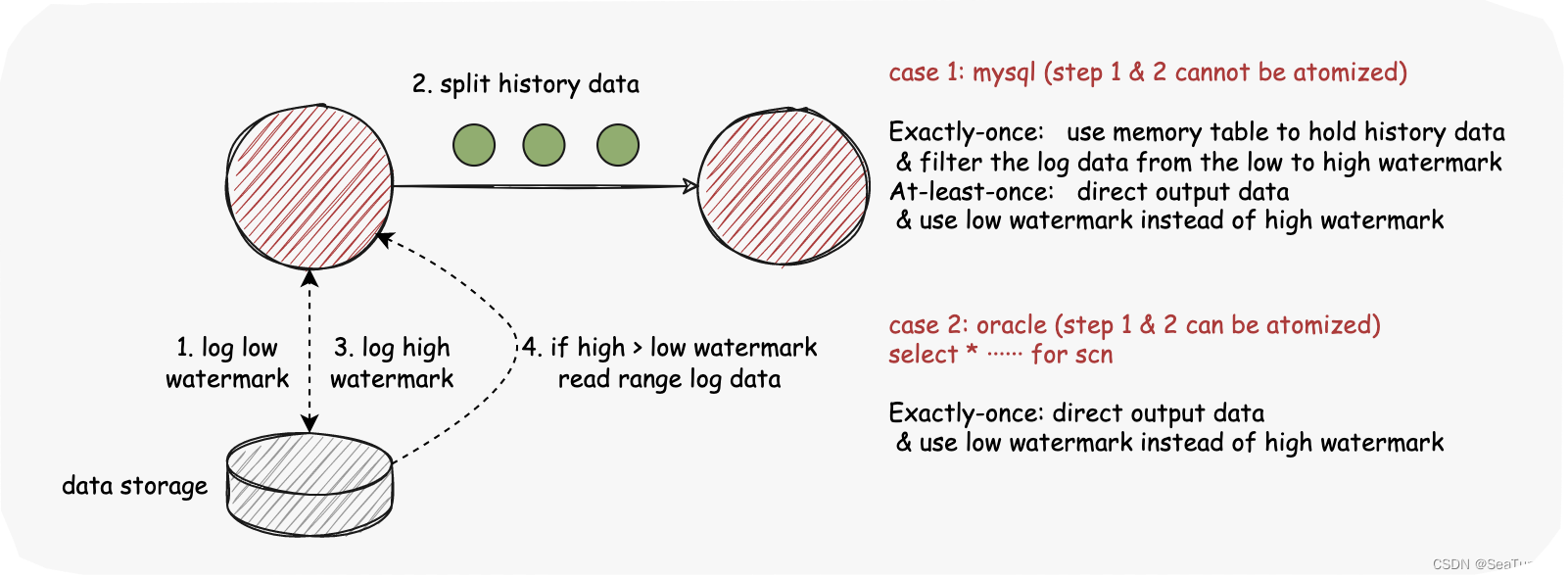
有4个步骤:
- 日志低水位线:读取快照数据前获取当前日志偏移量。
- 读取 SnapshotSplit 数据:读取属于split 的数据范围,这里分为两种情况
-
-
案例1:步骤1&2不能原子化(MySQL)
因为我们不能加表锁,也不能加基于低水位线的区间锁,所以第 1 步和第 2 步不是孤立的。
-
exactly-once:使用内存表保存历史数据 & 过滤日志数据从低水位线到高水位线
-
At-least-once:直接输出数据并使用低水位线而不是高水位线
-
案例 2:步骤 1 和 2 可以原子化(Oracle)
可以使用 for scn 来保证两步的原子化
-
Exactly-Once:直接输出数据并使用低水位线而不用去获取高水位线
-
- 加载高水位线数据:
- 步骤 2 中案例 1 & Exactly-Once:读取快照数据后获取当前日志偏移量。
- 其他:使用低水位线代替高水位线
- 如果高水位线>低水位线,读取范围日志数据
快照阶段—MySQL Snapshot Read & Exactly-once
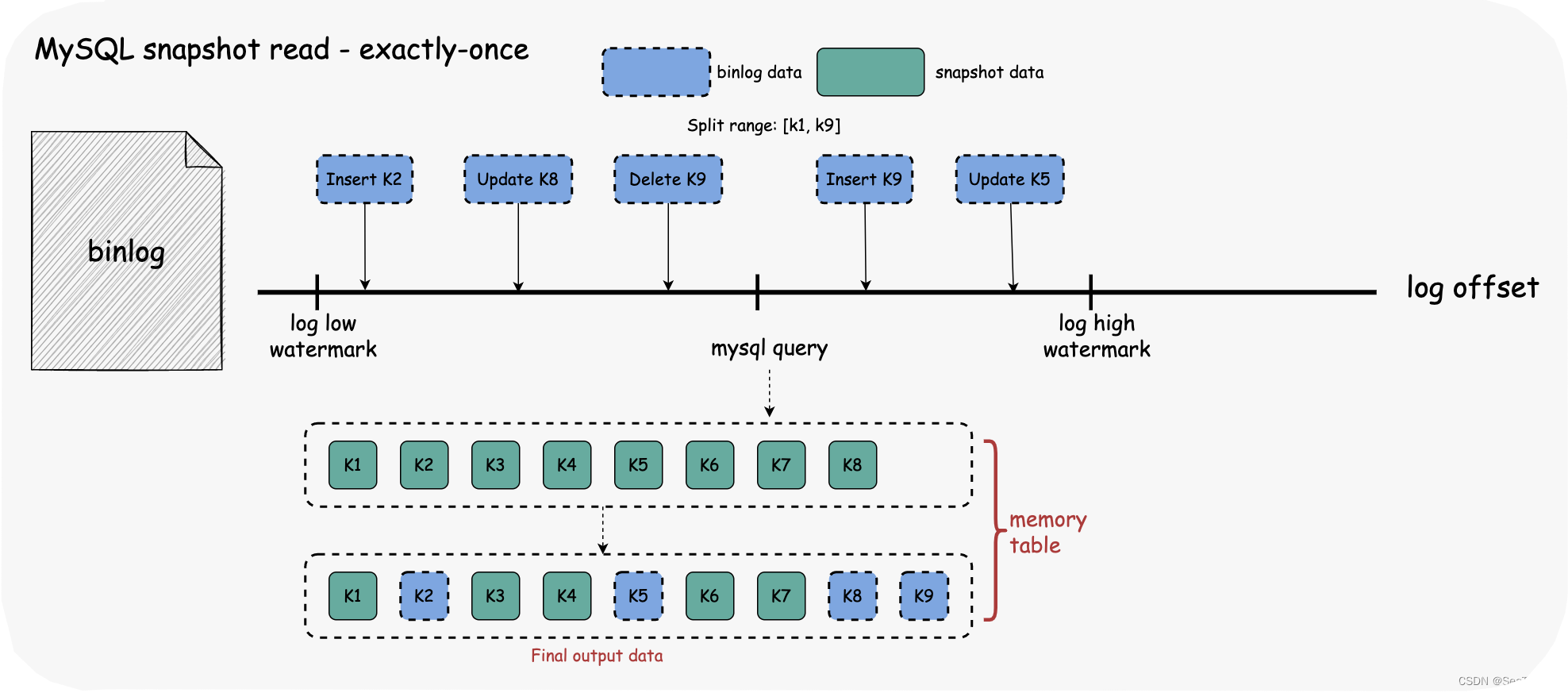
因为我们无法确定查询语句在高低水位之间执行的位置,为了保证数据的 exactly-once,我们需要使用内存表来临时保存数据。
- 日志低水位线:读取快照数据前获取当前日志偏移量。
- 读取 SnapshotSplit 数据:读取属于 split 的范围数据,写入内存表。
- 日志高水位线:读取快照数据后获取当前日志偏移量。
- 读取范围日志数据:读取日志数据并写入内存表
- 输出内存表的数据,释放内存使用量。
增量阶段
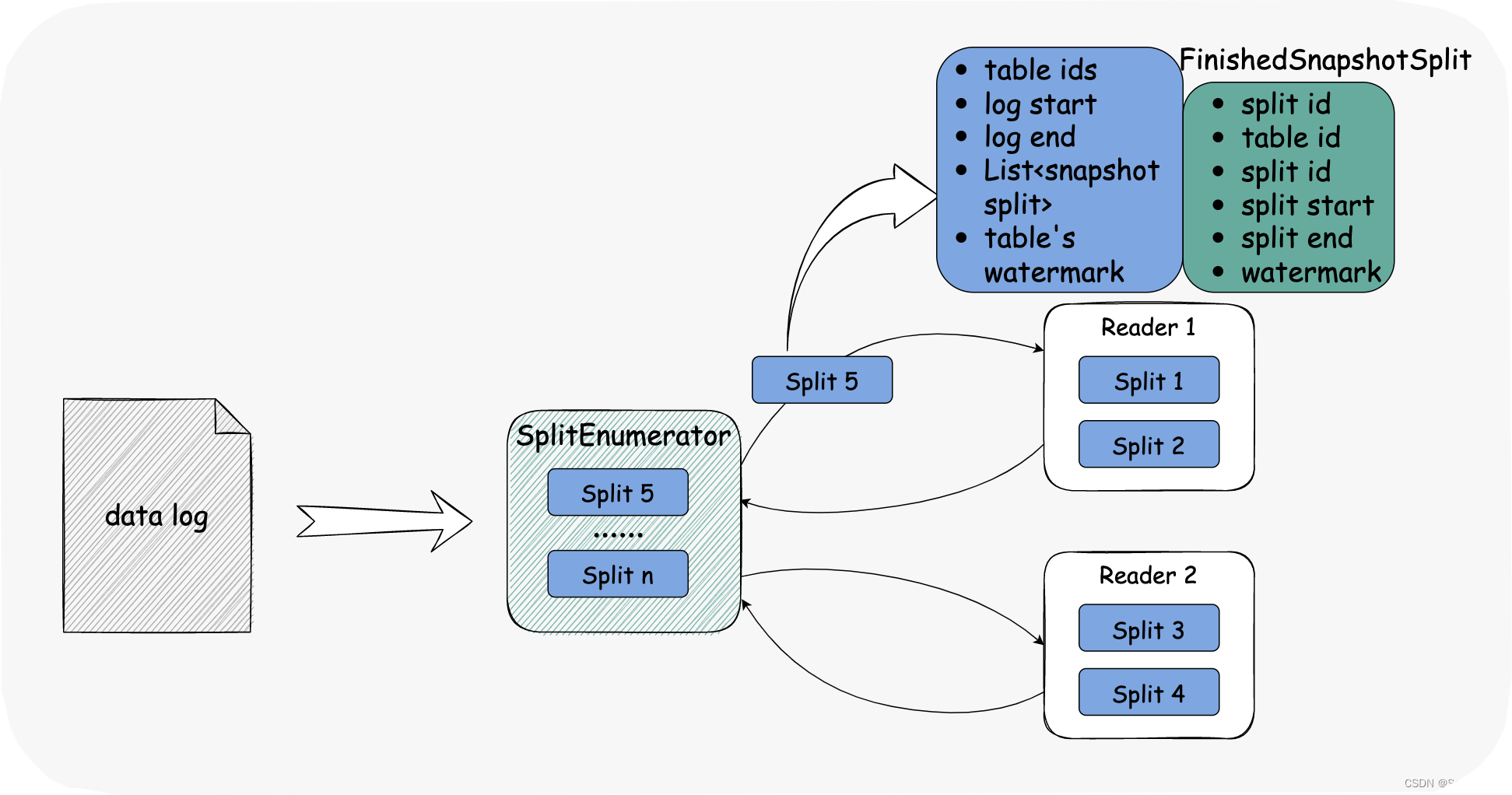
当所有快照拆分报告水位时,开始增量阶段。
结合所有快照拆分和水位信息,获得 LogSplits。
我们希望最小化日志连接的数量:
- 增量阶段默认只有一个 reader 工作,用户也可以根据需求去配置选项指定数量(不能超过 reader 数量)
- 一个 reader 最多获得一个连接
// pseudo-code.
public class LogSplit implements SourceSplit {
private final String splitId;
/**
* All the tables that this log split needs to capture.
*/
private final List<TableId> tableIds;
/**
* Minimum watermark for SnapshotSplits for all tables in this LogSplit
*/
private final Offset startingOffset;
/**
* Obtained by configuration, may not end
*/
private final Offset endingOffset;
/**
* SnapshotSplit information for all tables in this LogSplit.
* </br> Used to support Exactly-Once.
*/
private final List<CompletedSnapshotSplitInfo> completedSnapshotSplitInfos;
/**
* Maximum watermark in SnapshotSplits per table.
* </br> Used to delete information in completedSnapshotSplitInfos, reducing state size.
* </br> Used to support Exactly-Once.
*/
private final Map<TableId, Offset> tableWatermarks;
}
// pseudo-code.
public class CompletedSnapshotSplitInfo implements Serializable {
private final String splitId;
private final TableId tableId;
private final SeaTunnelRowType splitKeyType;
private final Object splitStart;
private final Object splitEnd;
private final Offset watermark;
}
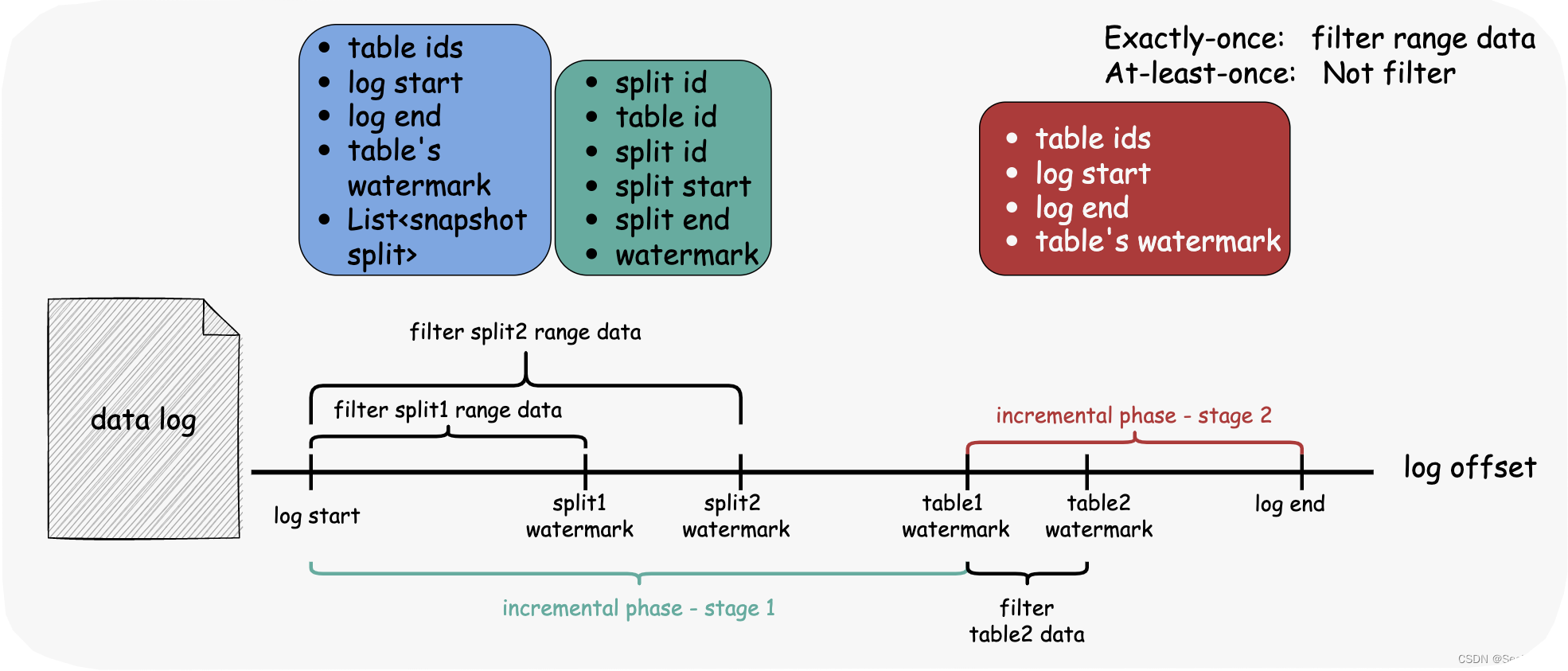
Exactly-Once:
- 阶段 1:在水印数据之前使用 completedSnapshotSplitInfos 过滤器。
- 阶段2:表不再需要过滤,在 completedSnapshotSplitInfos 中删除属于该表的数据,因为后面的数据需要处理。
At-Least-Once:无需过滤数据,且 completedSnapshotSplitInfos 不需要任何数据
动态发现新表
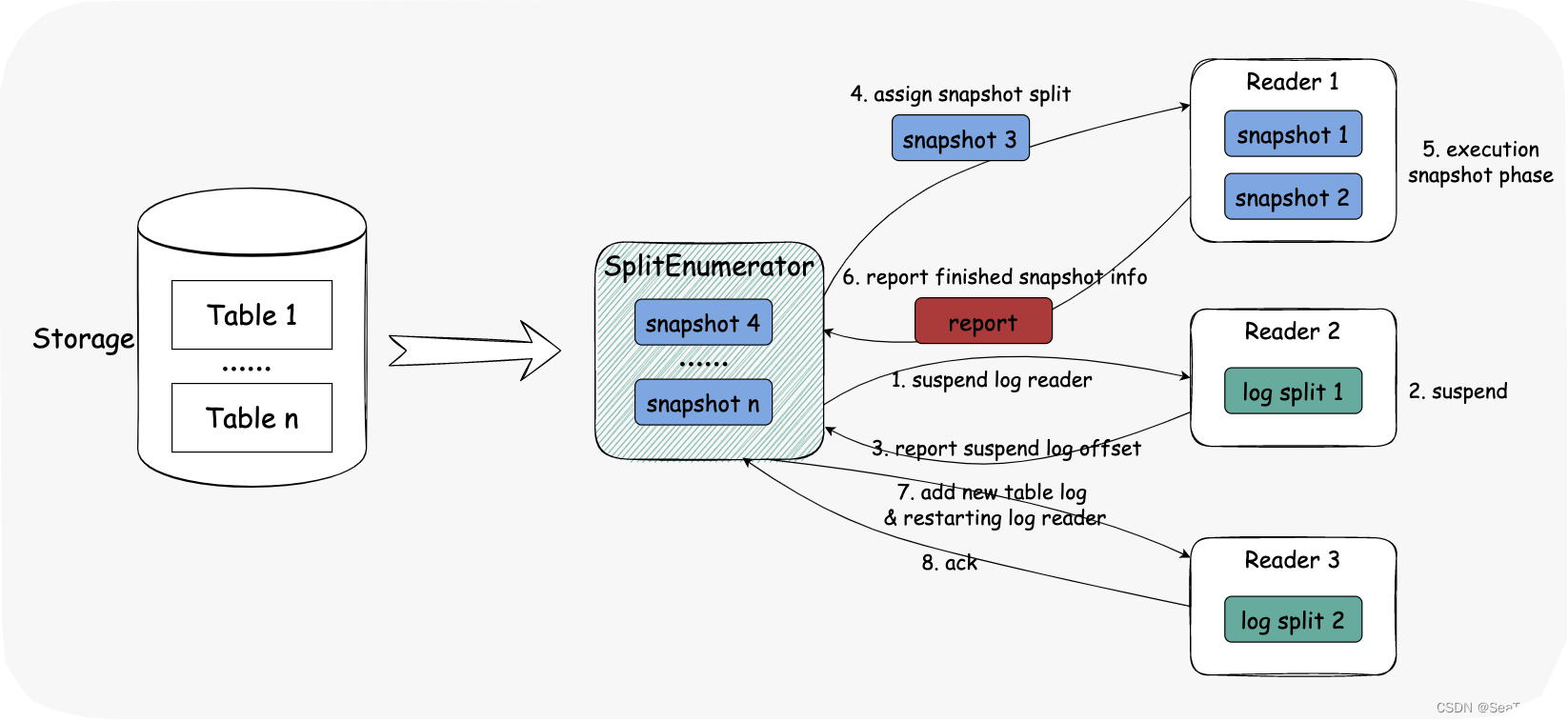
场景 1:发现新表时,枚举器处于快照阶段,直接分配新的 split。
场景 2:发现新表时,枚举器处于增量阶段。
在增量阶段动态发现新表。
- 暂停 LogSplit reader。
- Reader 暂停运行。
- Reader 报告当前日志偏移量。
- 将 SnapshotSplit 分配给阅读器。
- Reader 执行快照阶段读取。
- Reader 报告所有 SnapshotSplit 水位。
- 为 Reader 分配一个新的 LogSplit。
- Reader 再次开始增量读取并向枚举器确认。
多结构表同步
多结构表是为了解决连接器实例过多,配置过于复杂的问题。比如你只需要去配表的一个正则,或者配多个表名,不需要对每一个表去做配置。
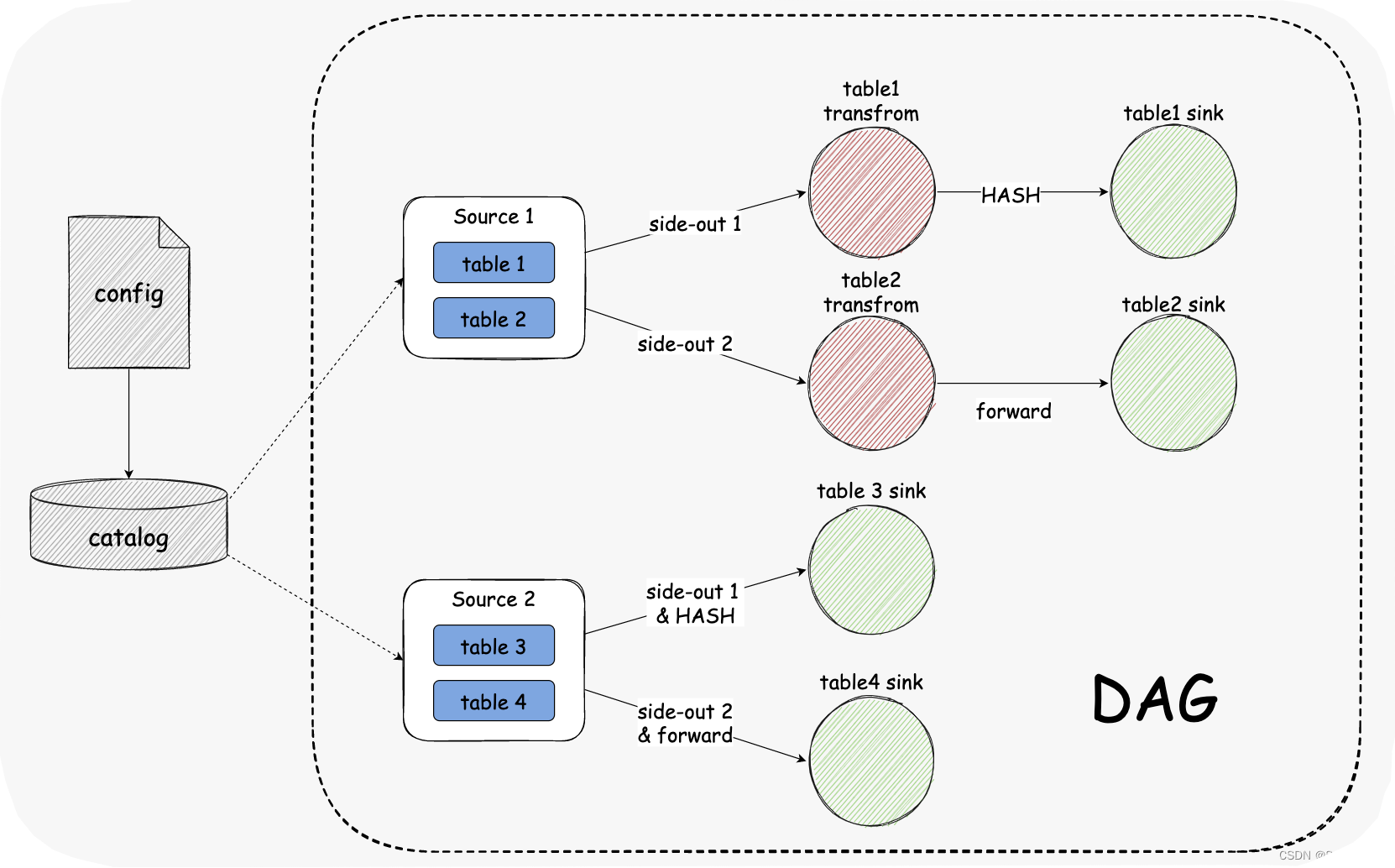
- 优点:占用数据库连接少,减少数据库压力
- 缺点:在 SeaTunnel Engine 中,多个表会在一个管道中,容错的粒度会变大。
这个特性允许Source支持读取多个结构表,再使用侧流输出与单表流保持一致。Sink 如果也去支持多表,可能涉及改动比较多。所以第一阶段的目标只是让 Source 去支持多结构表,这里配置的逻辑可能会和原来的不一样,会通过 catalog 去读每一个 config 里面到底配了哪些表,再把表塞到 Source Connector 中,这里多表结构的 API 已经在 SeaTunnel 的 API 之中,但是还没有做相关的适配。
SeaTunnel CDC现状
目前开发完成的是 CDC 的基础能力,能够支持增量阶段和快照阶段, MySQL 也已经支持了,支持实时和离线。 MySQL 实时已经测试完成了,离线的测试还没有完成。 Schema 因为要涉及到Transfrom 和Sink 的变更,目前还没有支持的。动态发现新表还没有支持,多结构表目前已经预留了一些接口出来,但是适配的工作量比较大,可能等到 2023 年 Q1 季度可能会做这个事情。
Apache SeaTunnel 展望
作为一个Apache 孵化项目,Apache SeaTunnel 社区迅速发展,在接下来的社区规划中,主要有四个方向:
-
扩大与完善 Connector & Catalog 生态
支持更多 Connector & Catalog,如TiDB、Doris、Stripe等,并完善现有的连接器,提高其可用性与性能等;
支持CDC连接器,用于支持实时增量同步场景;
对连接器感兴趣的同学可以关注该Umbrella:https://github.com/apache/incubator-seatunnel/issues/1946
-
支持引擎的更多版本
如Spark 3.x, Flink 1.14.x等
对支持Spark 3.3 感兴趣的同学可以关注该PR:https://github.com/apache/incubator-seatunnel/pull/2574
-
支持更多数据集成场景 (SeaTunnel Engine)
用于解决整库同步、表结构变更同步、任务失败影响粒度大等现有引擎不能解决的痛点;
对engine感兴趣的同学可以关注该Umbrella:https://github.com/apache/incubator-seatunnel/issues/2272
-
更简单易用(SeaTunnel Web)
提供Web界面以DAG/SQL等方式使操作更简单,更加直观的展示Catalog、Connector、Job等;
接入调度平台,使任务管理更简单;
对Web 感兴趣的同学可以关注我们的Web子项目:https://github.com/apache/incubator-seatunnel-web
Apache SeaTunnel
Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线 & 实时)同步和转化的数据集成平台
仓库地址: https://github.com/apache/incubator-seatunnel
网址:https://seatunnel.apache.org/
Proposal:https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelPro
Apache SeaTunnel (Incubating) 下载地址:https://seatunnel.apache.org/download
衷心欢迎更多人加入!
我们相信,在 「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「** 多样性与共识决策」** 等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
提交问题和建议:https://github.com/apache/incubator-seatunnel/issues
贡献代码:https://github.com/apache/incubator-seatunnel/pulls
订阅社区开发邮件列表 : dev-subscribe@seatunnel.apache.org
** 开发邮件列表:**dev@seatunnel.apache.org
加入 Slack:https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1cmonqu2q-ljomD6bY1PQ~oOzfbxxXWQ
关注 Twitter: https://twitter.com/ASFSeaTunnel
|








- 上一条: 贴吧低代码高性能规则引擎设计 2023-01-05
- 下一条: 解读重要功能特性:新手入门 Apache SeaTunnel CDC 2023-01-05
- Apache SeaTunnel (Incubating) 2.1.0 发布,内核重构、全面支持 Flink 2022-03-22
- 可视化任务编排&拖拉拽 | Scaleph 基于 Apache SeaTunnel的数据集成 2022-07-05
- 应用实践 | Apache Doris 整合 Iceberg + Flink CDC 构建实时湖仓一体的联邦查询分析架构 2022-06-23
- 马蜂窝毕博:分析完这9点工作原理,我们最终选择了 Apache SeaTunnel! 2022-11-04
- SeaTunnel 在天翼云数据集成平台的探索实践 2022-12-26