从100w核到450w核:字节跳动超大规模云原生离线训练实践
本文整理自字节跳动基础架构研发工程师单既喜在 ArchSummit 全球架构师峰会上的演讲,主要介绍字节跳动离线训练发展的三个阶段和关键节点,以及云原生离线训练中非常重要的两个部分——计算调度和数据编排,最后将结合前两部分分享字节跳动在实践中沉淀的4个案例。
作者|单既喜-字节跳动基础架构研发工程师
业务背景
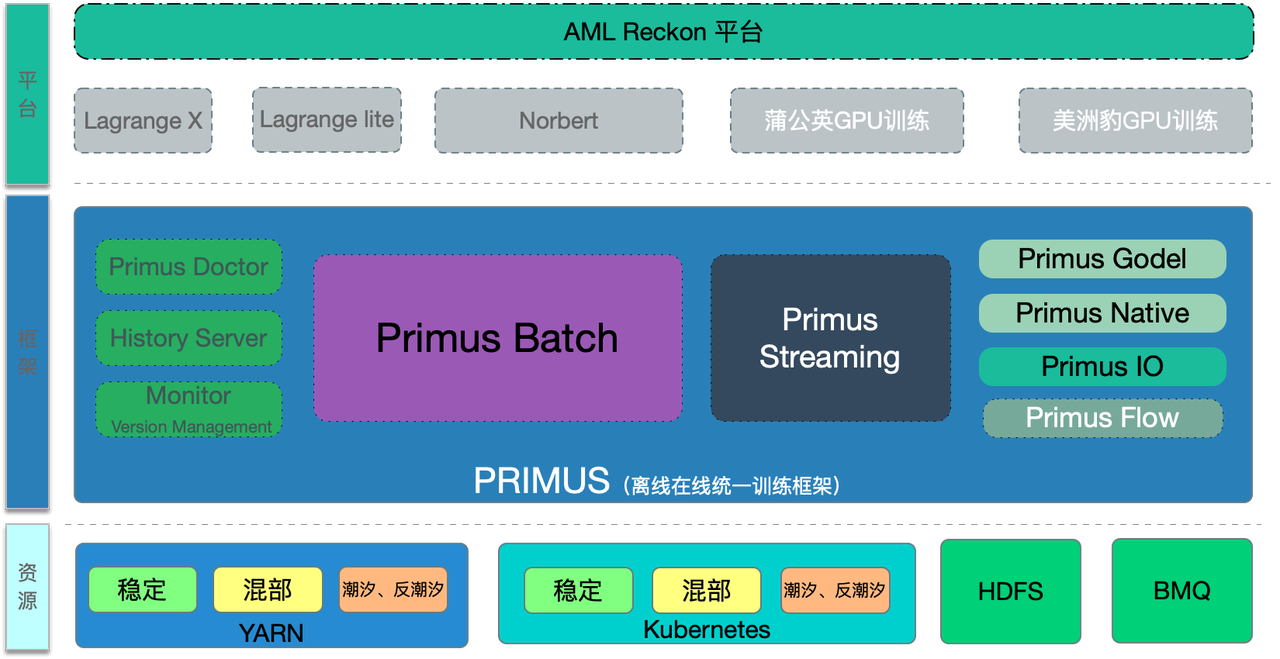
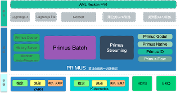
云原生离线训练框架支撑了字节跳动内部“推荐”“广告”“搜索”等场景,如头条推荐、抖音视频推荐、穿山甲广告、千川图文广告、抖音搜索等业务的超大规模深度学习训练——以上场景的机器学习训练均是基于 Primus 训练框架完成。
整个机器学习生态从上到下分为“平台层”“框架层”“资源层” 3个部分。字节跳动算法工程师使用 Reckon 训练平台完成了模型编写、训练、上线的全部过程。Reckon 训练平台中包含基于 TF 深度优化定制的 4 大深度学习框架——Lagrange 框架、Lagrange-Lite、蒲公英、美洲豹,这4个框架均通过 Primus 框架进行托管。
在托管观察中,Primus 作为分布式机器学习调度与数据融合框架,实现了云原生训练框架部署、分布式训练数据读取的全部过程,Primus 框架以云原生的方式运行在 YARN 和 Kubernetes 调度系统中,并通过 HDFS、FeatureStore 等方式获取训练数据交给 TF Worker 进行训练
字节跳动在离线训练方向的发展历程
云原生计算是软件开发中的一种方法,它利用云计算“在现代动态环境(例如公共云、私有云和混合云)中构建和运行可扩展的应用程序”。通过声明性代码部署的容器、微服务、无服务器功能和不可变基础设施等技术是这种架构风格的常见元素。
字节跳动在云原生离线训练方向的发展大概分为三个阶段:单角色云原生训练 1.0,多角色云原生训练 2.0,云原生训练 3.0 三个阶段。
单角色云原生训练 1.0
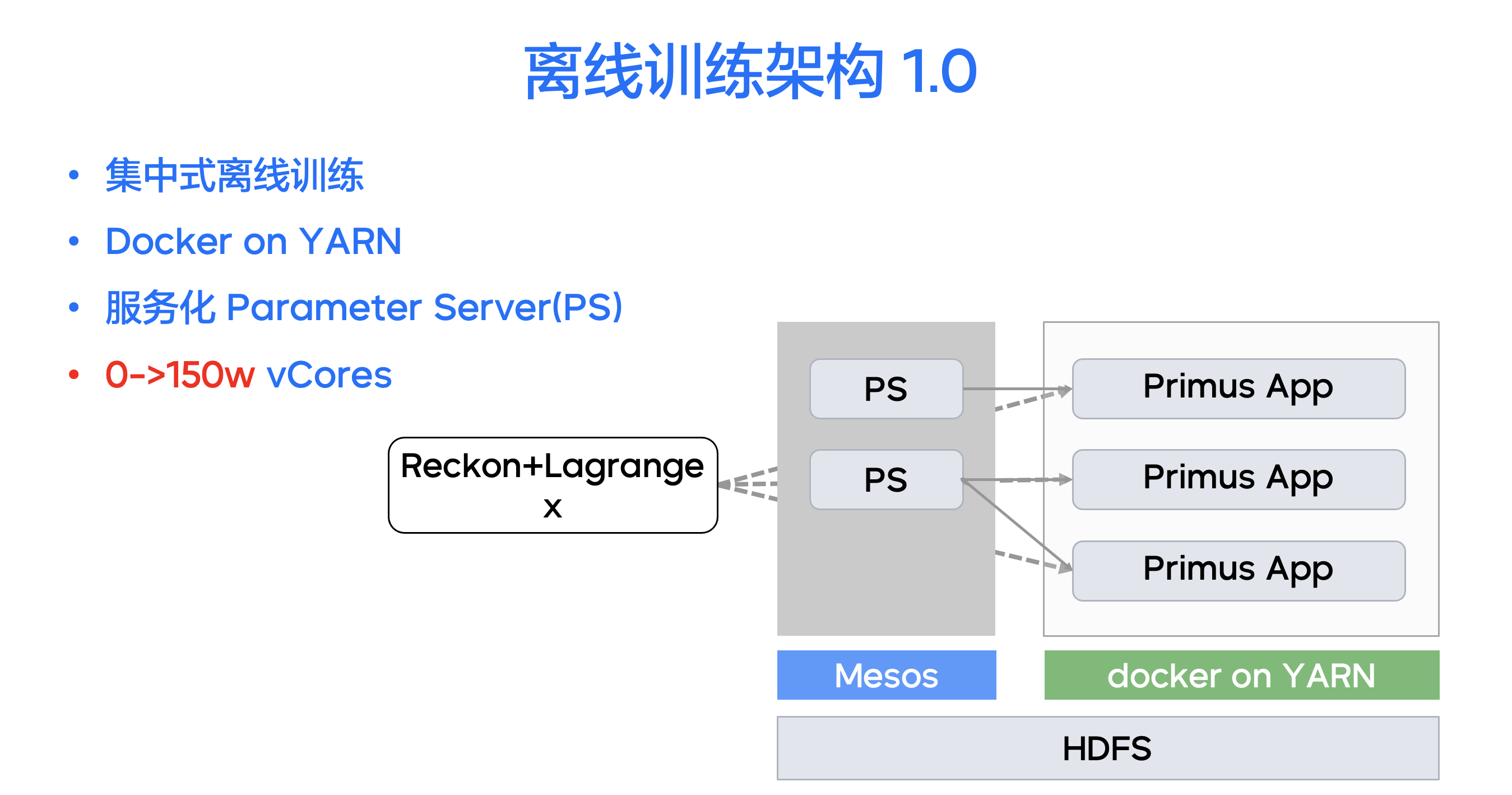
离线训练框架 1.0 系统诞生于2015年10月(内部代号 Zion)。
离线训练 Zion 框架是基于 Hadoop Streaming 架构在深度学习场景下的深度定制,每个训练作业对应一个 Hadoop YARN 上的 Zion 任务,具有(PS-Worker)架构分布式训练器、多数据格式多数据源混合训练、HDFS 样本读取、训练训练进度 Checkpoint 功能。
(PS-Worker)架构分布式训练器基于 Google 的 Tensorflow 框架深度定制,主要采用 Worker-PS 架构进行训练。此架构分为 PS 端与 Worker 端两个部分——其中 PS(ParameterServer) 是参数服务器,主要功能是存储并更新参数;Worker 是模型训练器,按训练数据分片,主要功能是读数据,对变量求梯度。
离线训练框架 1.0 对每个模型创建一套 Worker 实例,每个实例 Worker 和预部署在 Mesos 上的服务化 PS 完成通讯、读取样本、计算梯度、模型 Dump 的全过程。
离线训练框架 1.0 于 2019 年进行了系统级重构,新一代离线训练框架 2.0 增加了“多角色弹性调度”“多角色 Failover 能力”“训练进度增量 Checkpoint ”等功能,提供“灵活”“高效”“易用”的模型训练能力。
多角色云原生训练 2.0
在 “云原生训练 1.0” 实施过程中,我们发现了很多影响系统稳定性、易用性、维护性的问题。
问题1:训练作业调度集中化问题
字节跳动所有的离线训练作业管理都是基于集中式的训练调度服务(对应开源系统的 TF-Extend)。这个调度服务通过轮训的方式,完成每个训练作业的 PS 资源和 YARN 资源申请,如 PS 模型加载、YARN 训练任务创建、PS 模型保存等整个训练声明周期的各项工作,因此随着训练作业的增加,集中式调度出现了性能瓶颈,且调度服务的升级与不稳定等影响了较多的训练作业运行。
问题2: PS 资源与 Worker 资源匹配问题
离线训练 1.0 阶段,公司所有的 PS 均通过服务化的方式申请使用。采用服务化的方式是为了解决 PS 分片修复、服务扩容、分片 Reshard 等需要复杂运维操作的问题。同时,通过服务化方式也可以实现多个训练作业 PS 资源共享,提高物理机资源利用率。
但是,随着业务量的增长,服务化 PS 逐渐暴露出了与训练 Worker 难匹配的问题:
- 资源不匹配:新增的训练物理资源需要分别充值到 PS 服务端并上线,同时充值到 YARN 服务中才能进行训练;
- 网络不匹配:需要解决服务化 PS 与 YARN 训练资源之间的跨机房、跨网段导致的通讯开销。
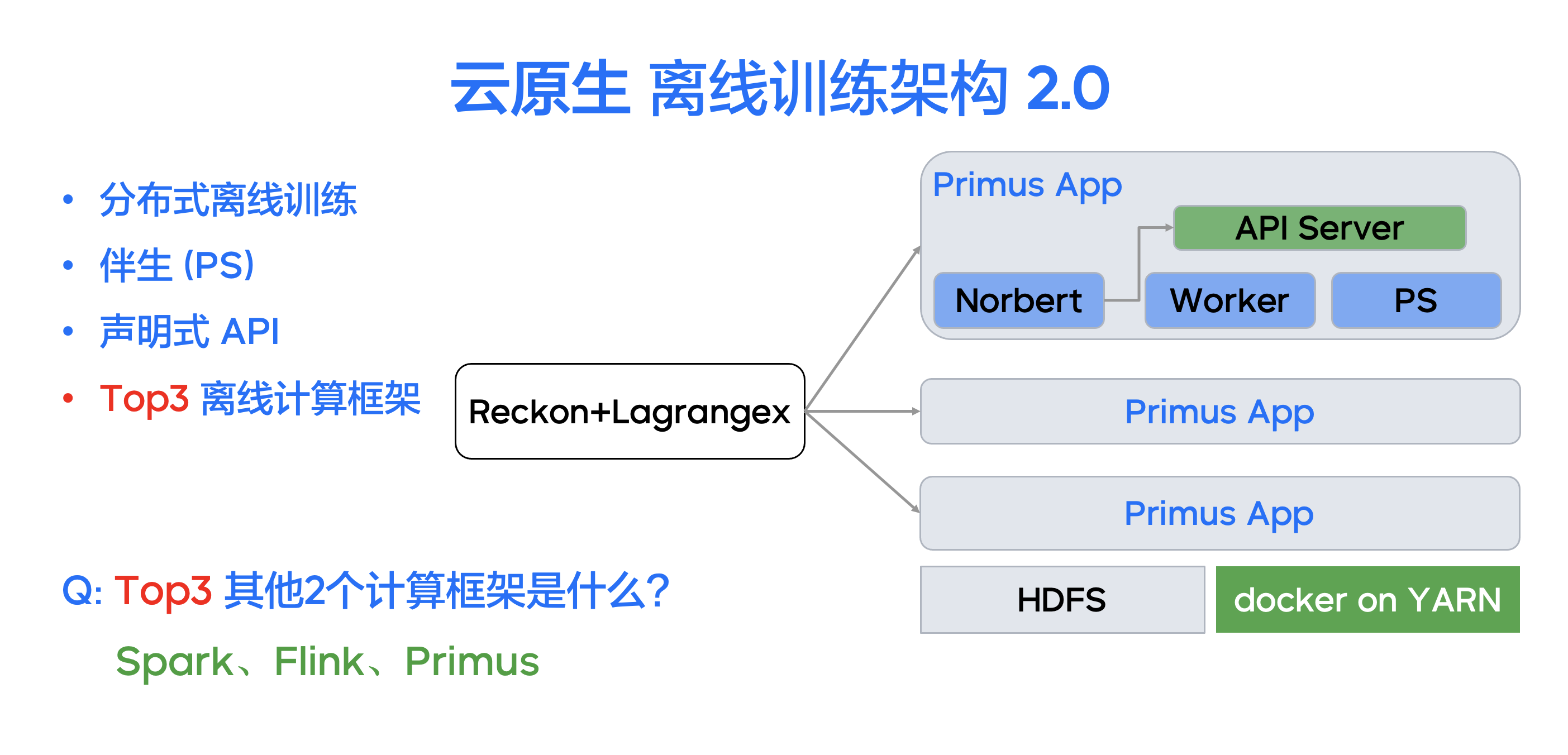
离线训练 2.0 增加了独占式的 API Server ,用于提供云原生分布式调度能力:
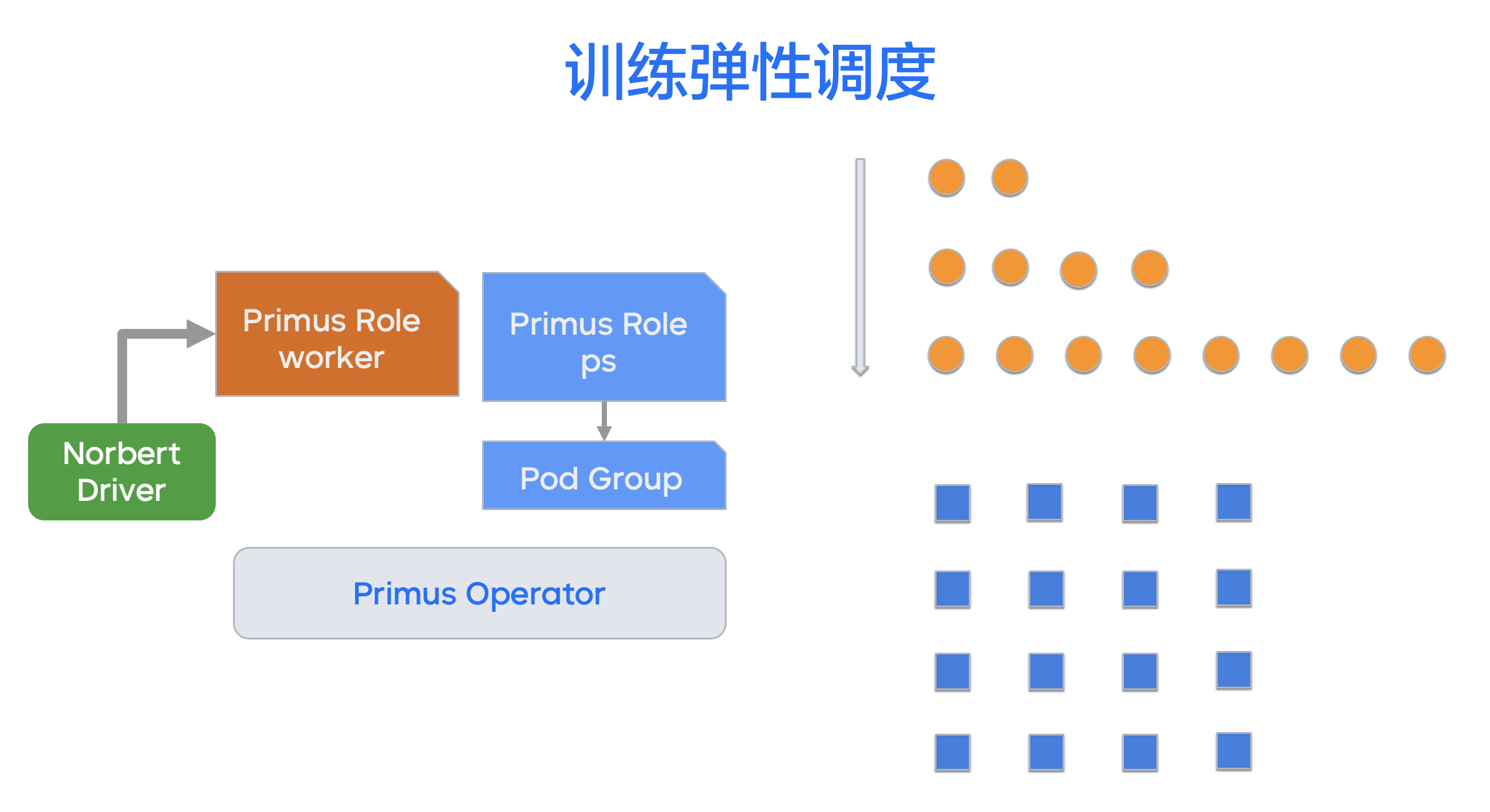
- 伴生式训练管理 Norbert Driver:将每个核心调度中枢的作业都配备对应的调度大脑,通过声明式的 API Server 控制每个调度的拓扑——Worker 角色和 PS 角色。
- 声明式 API Server:在每个离线训练 Job 中,都内建了一个独占式的 API Server。Norbert 训练管理 Driver 大脑通过声明式 API Service,发布控制训练拓扑、动态添加数据源、动态创建角色等训练需求;Primus 框架 Watch 并响应声明,完成重新申请容器、重新规划角色、重新构建 Task 等具体工作。
- 伴生式 Parameter Server:声明式 API Server 创建的伴生 PS 角色,实现每套训练作业专属自己的 Prameter Server,能够支持 PS Shard Failover、自动 PS 分片 ReHash、PS 资源弹性扩缩容等能力,彻底解决了服务化 PS 和训练 Worker 的资源匹配难题。
基于云原生训练的 2.0 架构,字节跳动离线训练的作业规模从 2020 年至 2022 年,实现了从 150 万核到 400 万核的突破,并且与 Flink 、 Spark 一起成为公司离线 YARN 集群的 TOP 计算框架。
云原生离线训练 3.0
云原生训练 2.0 资源部署在字节跳动深度定制的离线调度 YARN 集群中。为进一步实现离线在线资源并池、离线与在线训练统一,云原生离线训练 3.0 基于 Operator 架构增加了对 Kubernetes 运行环境的支持,实现了 YARN+Kubernetes 的云原生多 Runtime 训练。
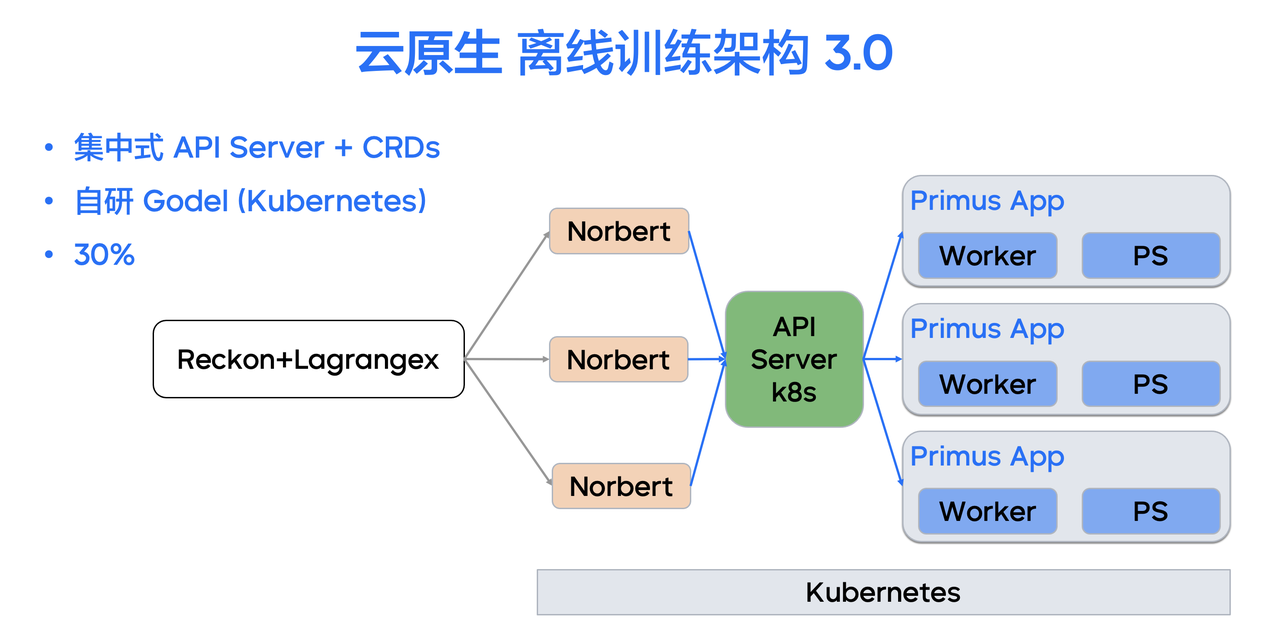
当内部大量资源从 YARN 迁移到 Kubernetes 后,系统不再为每个作业都产生一个 API Server 而是复用 Kubernetes 集群的全局 API Server,由 Norbert Driver 向全局 API Server 发布训练需求声明。
3.0 阶段整个离线训练的框架拓扑可以达到每天 10000 Job 的量级,单最大作业数 4000 个,每天 400 万 vCore 的总量。框架同时支持 YARN Runtime 与 K8s Runtime 等多种Runtime,目前已经有约 160 万核的离线训练作业部署在 Kubernetes 集群上(占总训练量的40%)。
云原生离线训练-弹性调度
字节跳动云原生离线训练包含了两个重要的组成部分——弹性调度和数据编排。
弹性计算调度简述
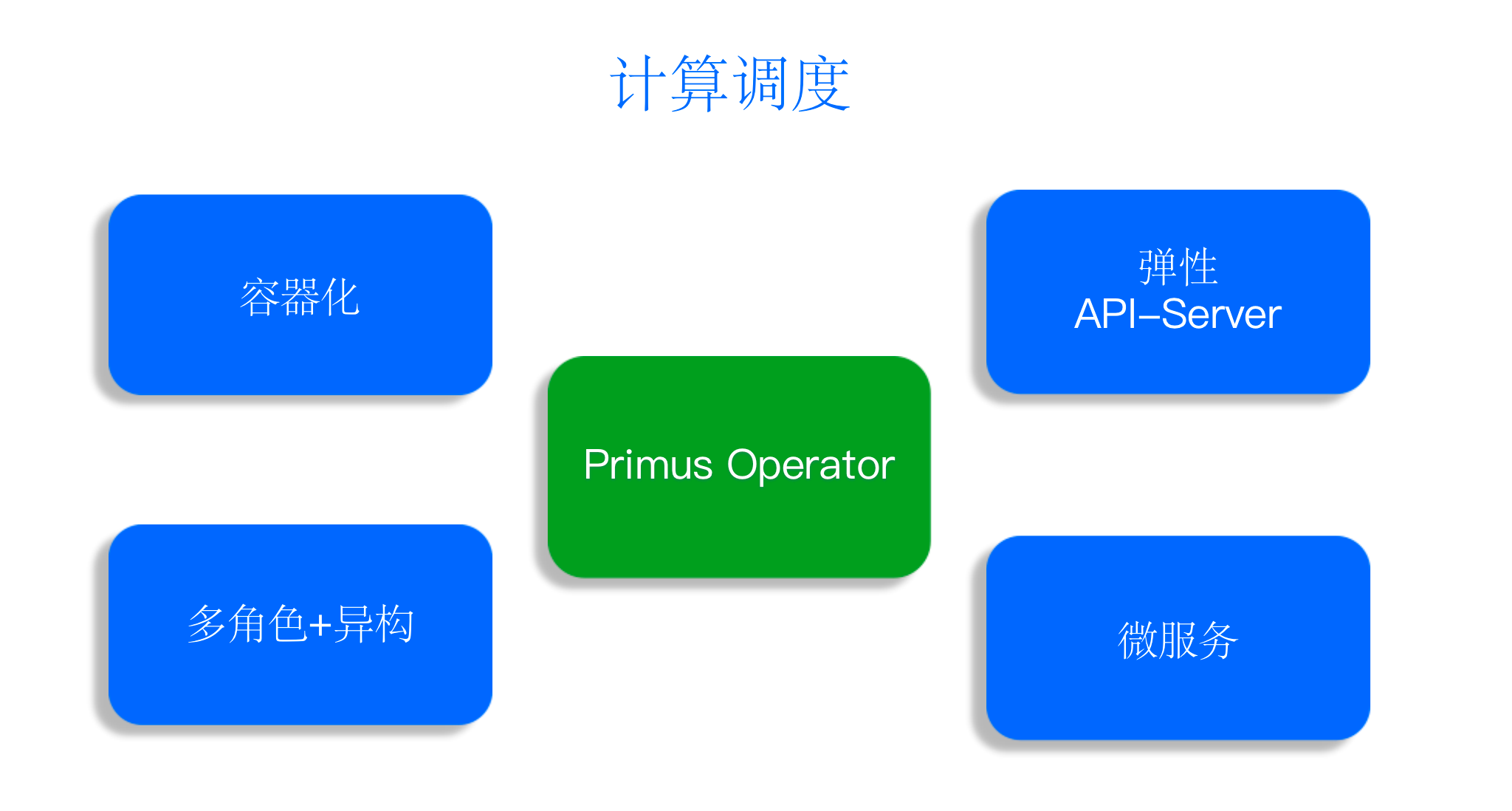
云原生的计算调度体系是通过字节自研的 Primus Operator 打造实现的,具有以下四个特点:
- 容器化:在 Kubernetes 和 YARN 上大规模践行容器化带来的隔离和环境准备方面的优势;
- 弹性 API-Server:通过自研的 API Server 在 Kubernetes 上复用 API Server 的形式实现弹性作业调度的能力;
- 多角色+异构:不仅能调动 CPU 还能调动有状态的 GPU,实现多角色异构架构的能力;
- 微服务:实现调度 Operator 及神经中枢 Norbert 微服务之间的通讯互联。
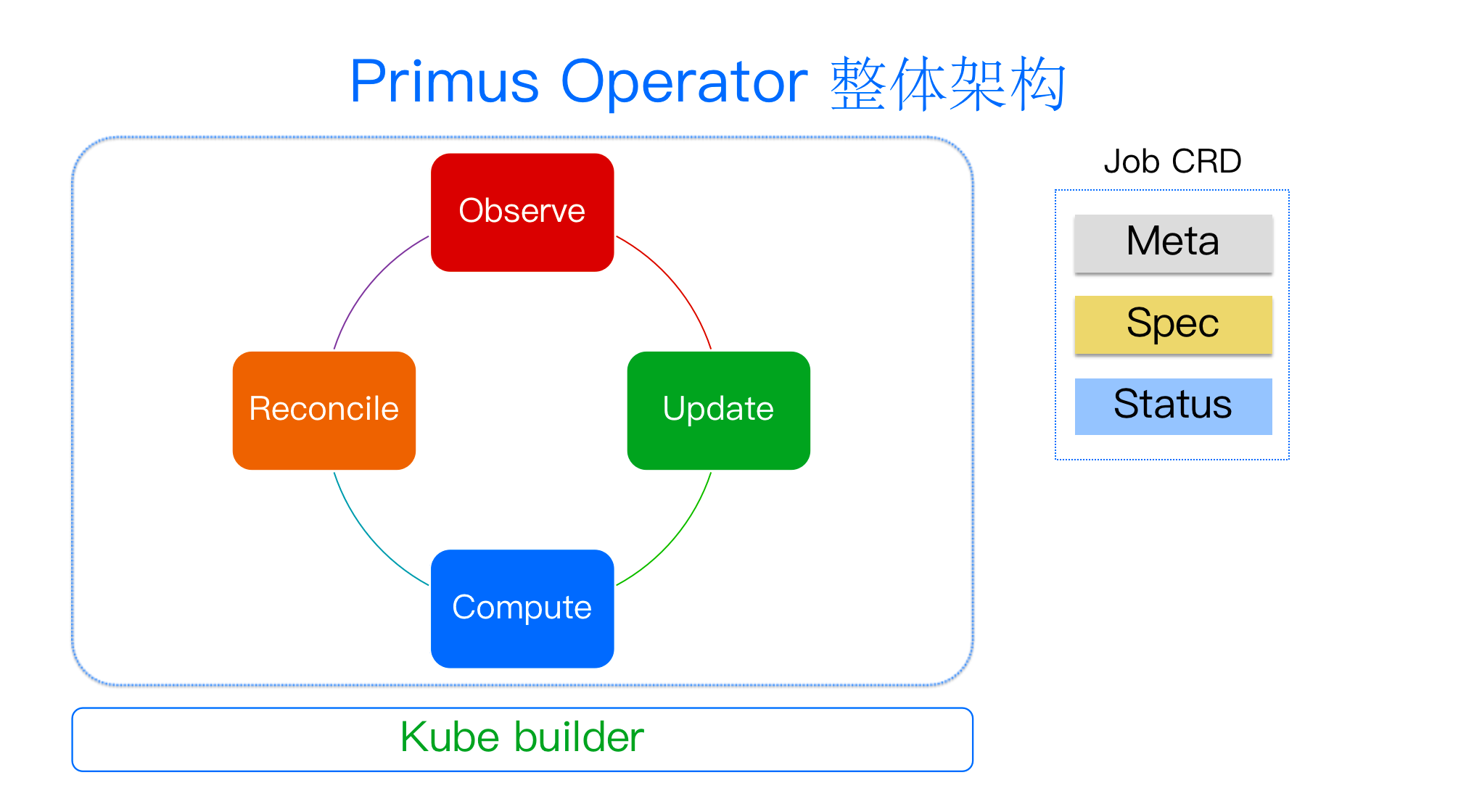
Primus Operator 总体基于开源 Cookie Builder 架构,拥有四个流转状态:首先观察整个 Job 的状态,然后将状态 Update 到 Job CRD 的 Status 内,再去查看用户/作业需求方的作业拓扑期望,计算需要申请的 POD 资源,最后在 Reconcile 时实现第二步 Update 结果和第三步 Compute 期望值之间的协调,从而完成整个状态的流转。
弹性计算调度架构
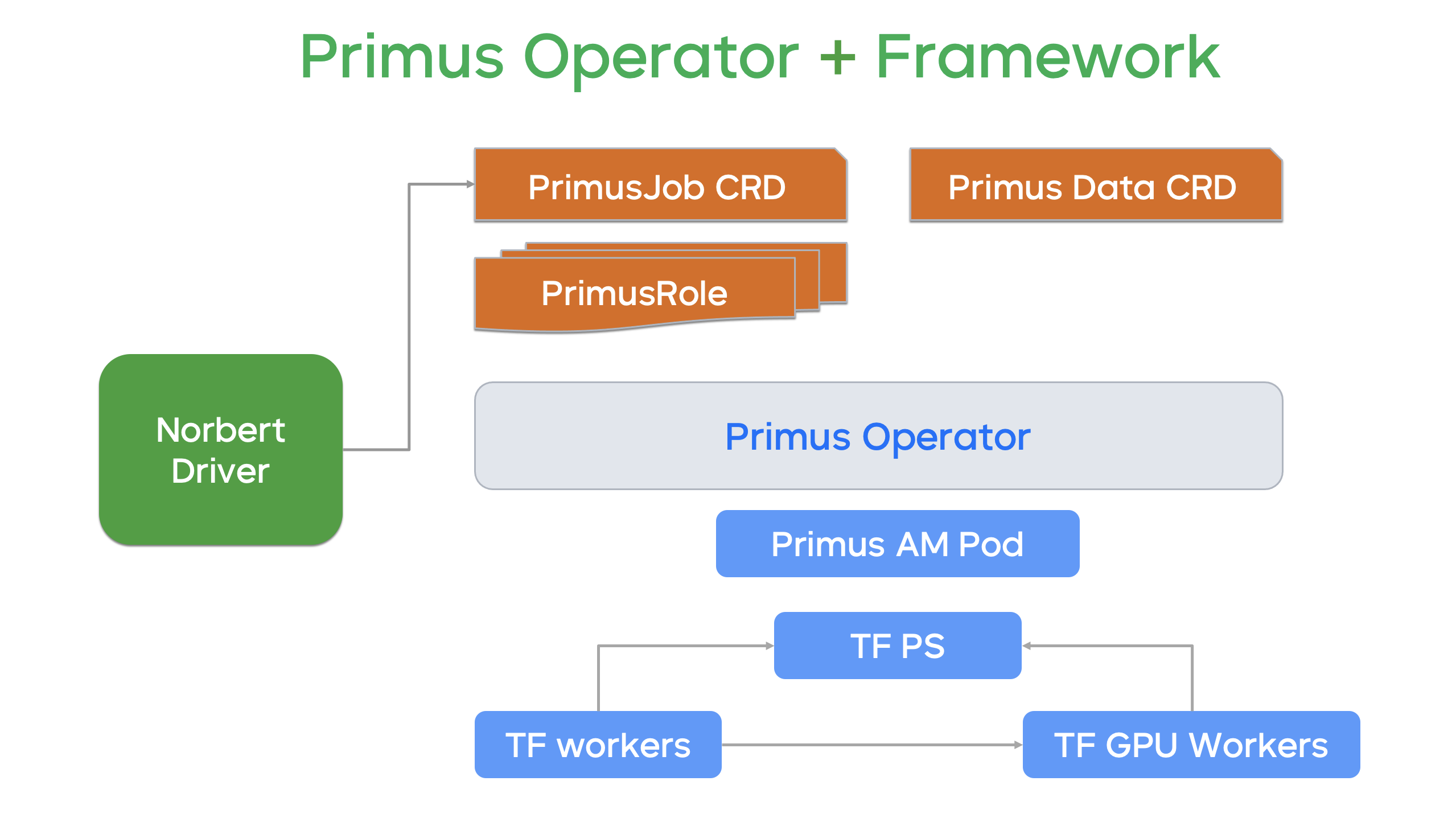
每个 Job CRD 都有 Spec 和 Status 两个部分,为了实现多角色调度,我们进一步打造了 CRD 家族。除了上文提到的 Job CRD,每个 Job 会关联若干个 PrimusRole CRD。同时针对数据部分,我们抽象了 PrimusData CRD。在 PrimusRole CRD 中,每一个角色都对应一个 Role 的 CRD。所有 Primus Job 的拓扑最终被协调出来的结果,就是在 Kubernetes 或者 YARN 中的一个作业框架(如上图下方)。
我们可以看到,TensorFlow 和 PS Worker 等相关的作业都被创建出来,同时每一个 Job 都有自己的总控中枢,即我们基于 Java 写的 Primus AM Pod。这个中枢主要负责协调整个过程、记录训练进度、提供 UI 展示、记录历史过程。基于这样一个体系,我们完成了 Primus Job 的创建。
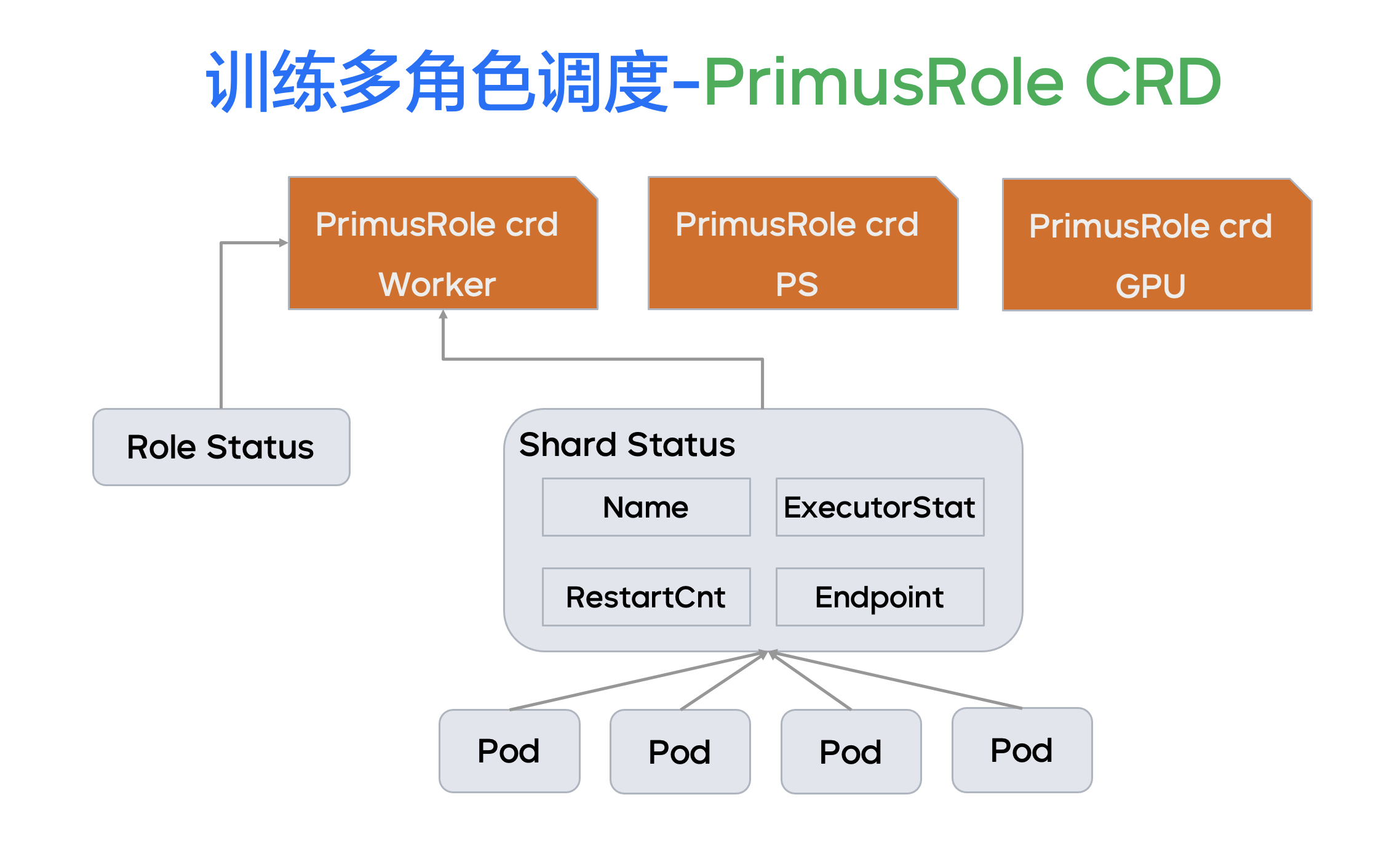
Primus Job 创建成功后,当某一个副本失败时,我们就可以通过调度大脑获取到当前副本的信息,每个角色对应的若干副本,多个角色就组成了整个弹性调度的拓扑。
下面来看弹性调度策略到底有多弹性?我们为了弹性调度都解决了哪些问题?

针对原生的 TensorFlow,我们将其分为自研的 Dynamic 策略和针对原生 TensorFlow 的刚性策略:
- 原生的 Dynamic 策略指角色可以动态地互相服务,可以在任何时刻重启角色,不要求所有角色重启之后才能开始训练;
- 刚性策略指对于原生的 TensorFlow 需要支持 Work 和 PS 服务的互相发现,所以基于这种策略,在所有角色都申请到资源后统一发送启动命令,实现 IP 加端口的相互传递。
后面我们引入了 Order 策略,以弹性的方式申请 Worker 角色,大大减少等待的周期,避免了在等待过程中造成的资源浪费。
弹性计算调度应用
应用1:训练 SlowStart 优化模型训练
针对 Worker 无状态的 Sailor 角色,我们采用弹性声明,通过不断修改 API Server 控制角色内的副本数进行训练。
在开始阶段,我们以两个副本的方式进行慢速训练,使模型快速找到局部最优状态。
模型趋于稳定后,我们再不断地扩展模型 Worker 的数量,实现大吞吐的模型训练,从而提高模式训练的速度。
应用2:Gang 性多角色调度支持
针对有状态的 Parameter Server 的角色,我们引入了刚性的申请策略:
- 在 YARN 集群上,通过修改 YARN 调度器实现了 GangScheduler,支持对 PS 拓扑的资源 Gang 性申请与释放;
- 在 Kubernetes 集群上,通过自研的 Pod Group 实现了 PS 角色的精细化资源管理,同时支持了调度打散、最小 Gang 性数量、调度亲和与反亲和策略等复杂场景的 PS 调度需求。
应用3:超大规模的在离线混部训练
- 混部 Smart Resource: 弹性调度不仅控制角色数量的多少,并且可以控制角色的规格,从而提升集群利用率,比起通过声明式的 API 动态修改角色的规格,Smart Resource 将混部资源的利用率从20%提升到了70%;
- 潮汐/反潮汐策略: 资源利用存在高峰和低谷,针对这一情形,我们应用了面向 API Server 的弹性调度机制——在在线业务低峰时,我们有资源用于训练,于是我们就拉起更多角色,提高训练效率;在在线业务的晚高峰时,我们又会把训练资源缩容到0,把离线训练的机器学习暂时挂起,出让资源去支援在线业务,如抖音、头条的推荐,但此时 Job 还是正在运行的。借此,我们达到了更好地节省资源和开支、提高资源集群利用率的目的。
云原生离线训练-数据编排
在离线模型训练中,训练样本数据管理、读取、加工等对模型训练起到了至关重要的作用。
样本数据在字节跳动内部不同场景下存放在不同的系统中——有存储在 HDFS 中的文件类样本资源,也有存在 Kafka 里的流式训练样本资源,还有团队自研的 Feature Store 样本资源。
云原生离线训练框架(Primus)同时覆盖多种数据源的编排,支持不同数据源在天、小时、分钟级的编排策略;能够实现上面提到的三个训练资源中的交叉组合、过滤、打散、对齐等丰富数据编排能力。
同时,在元数据编排过程中,训练框架有新数据的感知和增量编排能力。Primus通过持续扫描 HDFS 和 Feature Store 的新增数据进行模型更新,保证训练效果能够匹配用户最新行为。
多数据源训练元数据编排
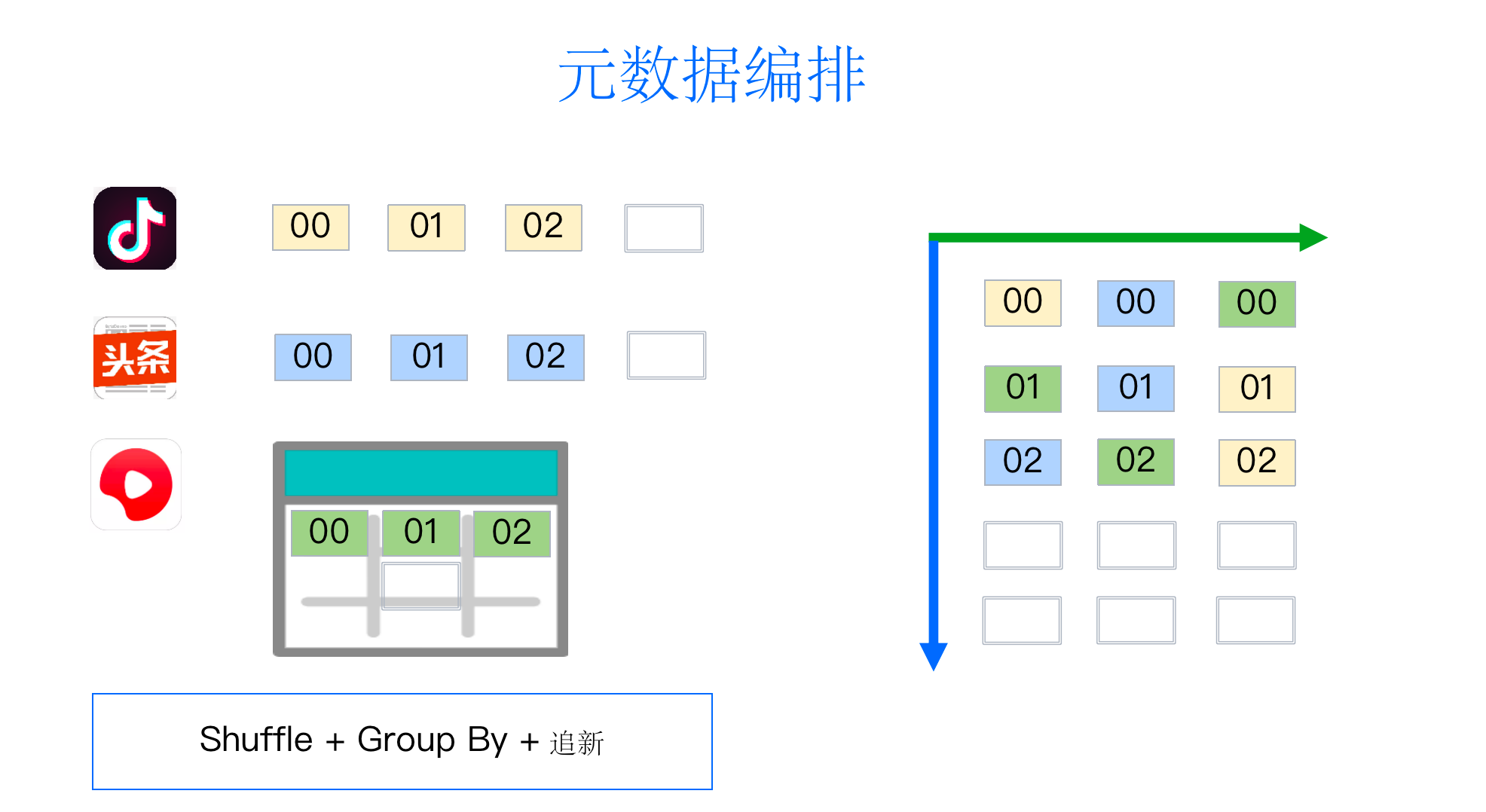
在广告等 CVR 转化模型中,天然地需要对同一用户不同 APP 上的行为数据进行建模并预测。
字节跳动的算法工程师依托云原生离线训练的数据编排能力,对抖音、头条和西瓜业务的三个数据源进行了建模训练,每个数据源分别按 00 小时、01 小时、02 小时进行存储,同时在头条和西瓜中每个小时都进行一次聚合,最终达到在 00 小时分别消费了头条、西瓜和抖音的一个数据,而在第 01 小时通过多个数据源的重新排列,避免了模型编排的趋向性,在第 02 小时进一步进行数据源打散。
这个例子充分展示了我们在 Partition 内 Shuffle,按小时 Group By,以及持续追新的能力。
训练样本元数据管理
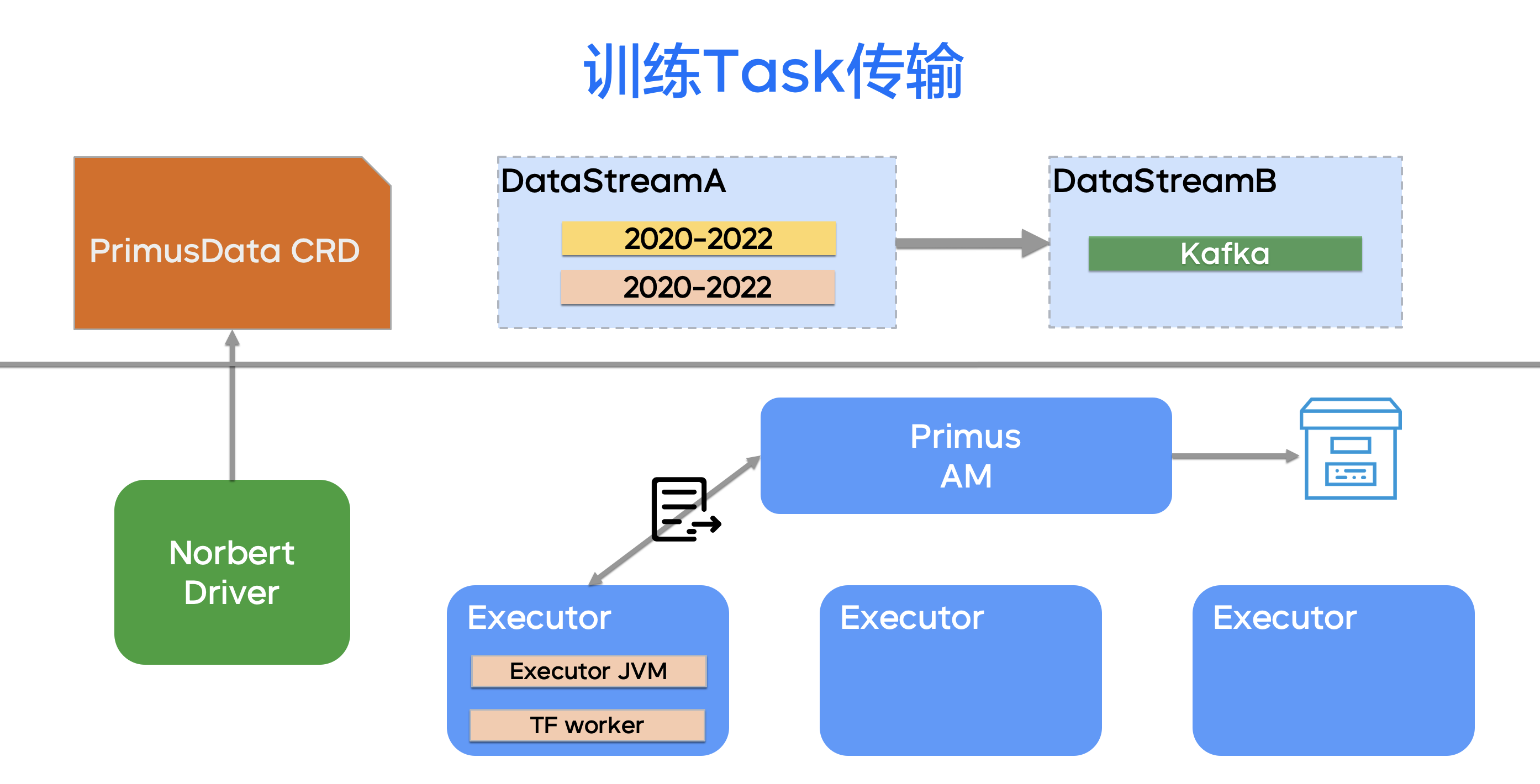
在样本元数据分发阶段,我们将多个元数据组成了 DataStreamA,在流式阶段叫 DataStreamB,这是一个多阶段训练的过程。这两个 DataStream 都组成了同一个 PrimusData CRD。
- DataStream 里的若干个 DataSource 被按天、按小时聚合之后,会通过 Primus AM 实现文件的切分,切分的力度是按天、按小时聚合之后的原始 HDFS 路径或者 Feature Store 目录。切分的结果是若干个 Split 通过心跳的方式下发 Task 到 Executor。
- 随着心跳,我们还会每时每刻回发当前训练中 Task 的消费进度,以方便 FellOver 的时候,我们能够从断点当中继续消费来进行训练。同时,训练的进度被 Primus AM 记录到 HDFS 中,并且持久化,以方便整个 Application 挂掉之后,我们可以从 HDFS 的训练状态当中得到恢复。
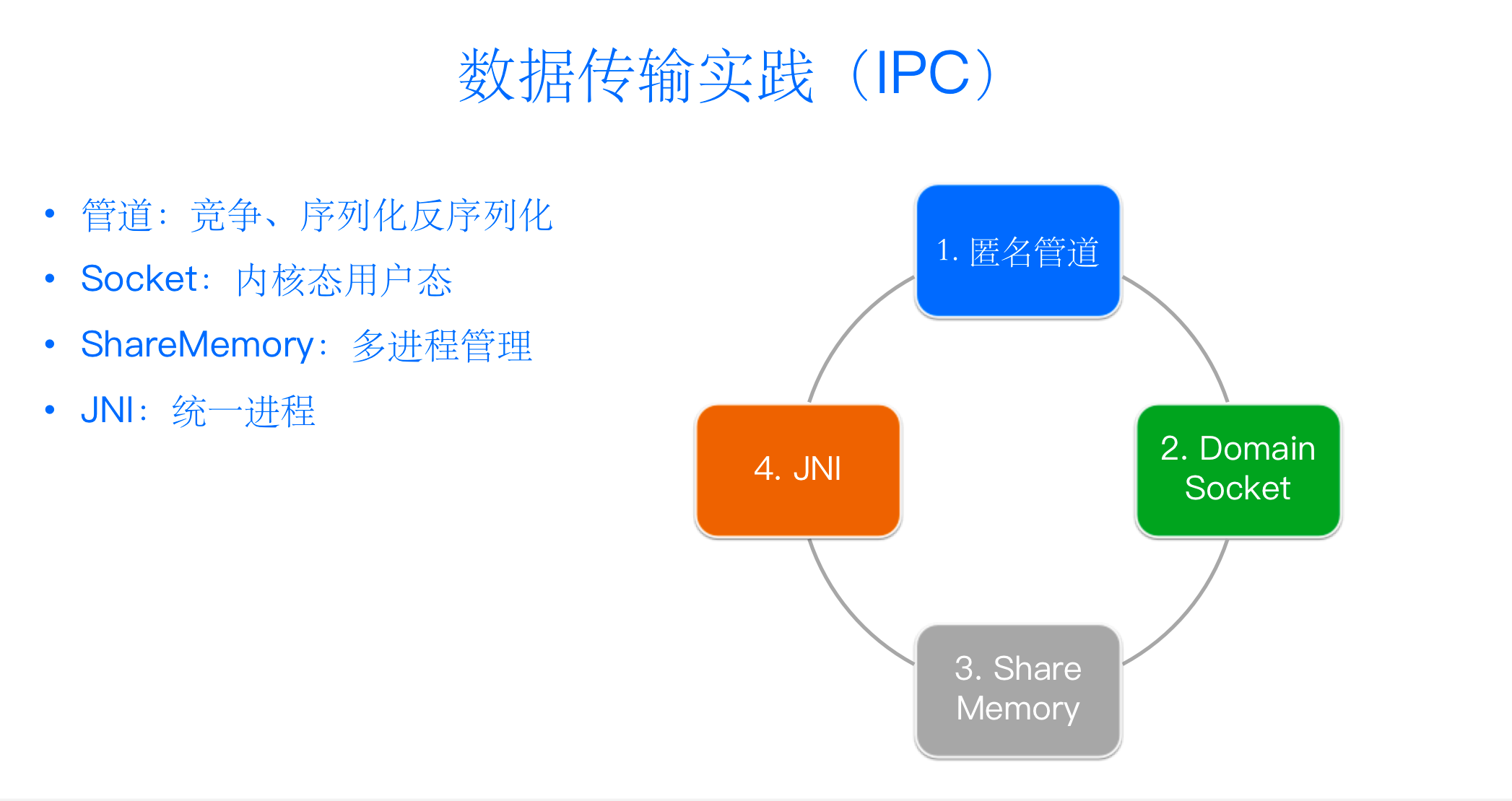
跨进程数据传输实践
- 基于匿名管道的数据传输: Executor 里有两个进程,一个是 TensorFlow Worker,用于从管道里读取我们通过 HDFS 解析之后的样本数据;另一个是 Executor JVM 数据进程,进行 HDFS Client 读取后,将序列化的样本通过 Linux 匿名管道传输给 TensorFlow Worker 进程。
在实践过程中,我们发现匿名管道天然存在两个问题:跨进程通讯和多个 Producer 竞争抢锁,由此也就增加了从用户态到内核态拷贝的开销和资源竞争的问题。
- 高级数据传输方式: 如 Domain Socket,我们采用 Producer 和 Worker 通过两个 TCP Socket 传输的方式,避免了多个 Producer 的管道竞争,但这样依然会存在内核带的拷贝以及序列化和反序列化的开销。随后,我们引入了跨进程之间 Share Memory 机制,做到了多进程管理。最后我们采用 JNI 统一进程机制合并两个进程,实现了样本读取、加工、传输全流程 Lib 化,彻底解决了跨进程之间的 IPC 开销。
案例与最新实践
上文阐述了我们在数据编排和计算调度方面的积累与沉淀,下面介绍我们将这两部分组合起来,同时结合业务的需求,在实践中进行运用的重要案例。
从服务化 PS 到 云原生 全伴生 PS
在 1.0 阶段,我们没有将 PS 纳入到云原生中,而是采用了服务化的 PS,这种方式存在如下弊端:
- 需要同机房撮合
- 资源利用率低
- 运维与部署难度大
- 隔离性差(网络、内存带宽、CPU)
于是我们就引入了云原生化的 PS on YARN / K8s SavePoint,即伴生 Parameter Server 训练机制,这一演进同时也伴随着我们的作业规模从 150 万核到 400 万核的增长。我们在这一阶段实现了如下功能:
- PS 拓扑刚性调度:在 YARN 和 Kubernetes 上都实现了 PS 刚性申请和刚性调度;
- 服务发现 ( consul -> 自研)、健康检查:通过自研的声明式 API Server 实现了服务发现,同时实现了 Parameter Server 的健康检查、定时检查以及故障恢复机制;
- 单作业 + 容器化部署:基于容器化的方式隔离不同的 Parameter Server,避免它们 CPU 利用之间的相互干扰;
- PS 进程 Numa 隔离:Numa Bind:避免 CPU 跨 Numa 访问内存带来的性能退化;
- PS SavePoint 机制:定时记录 Parameter Server 目前整个拓扑中最新的模型状态;同时我们为数据也设置了 SavePoint 机制,将两个检查点进行对齐和同时恢复,从而实现伴生 Primus Server 训练的异常恢复;
- 全链路 Incremental Checkpoint:不止 Parameter Server 可以增量 Checkpoint,训练 Worker 也可以增量 Checkpoint,这就意味着在任何时刻,当一台 Primus Server 发生故障之后,它只需用增量的方式去恢复这一个单点即可;
- PS Smart Resource 机制:不断地压缩 Parameter Server 声明规格和它的使用规格之间的 Gap,提高集群的利用率。
PrimusFlow 训练数据实时预处理
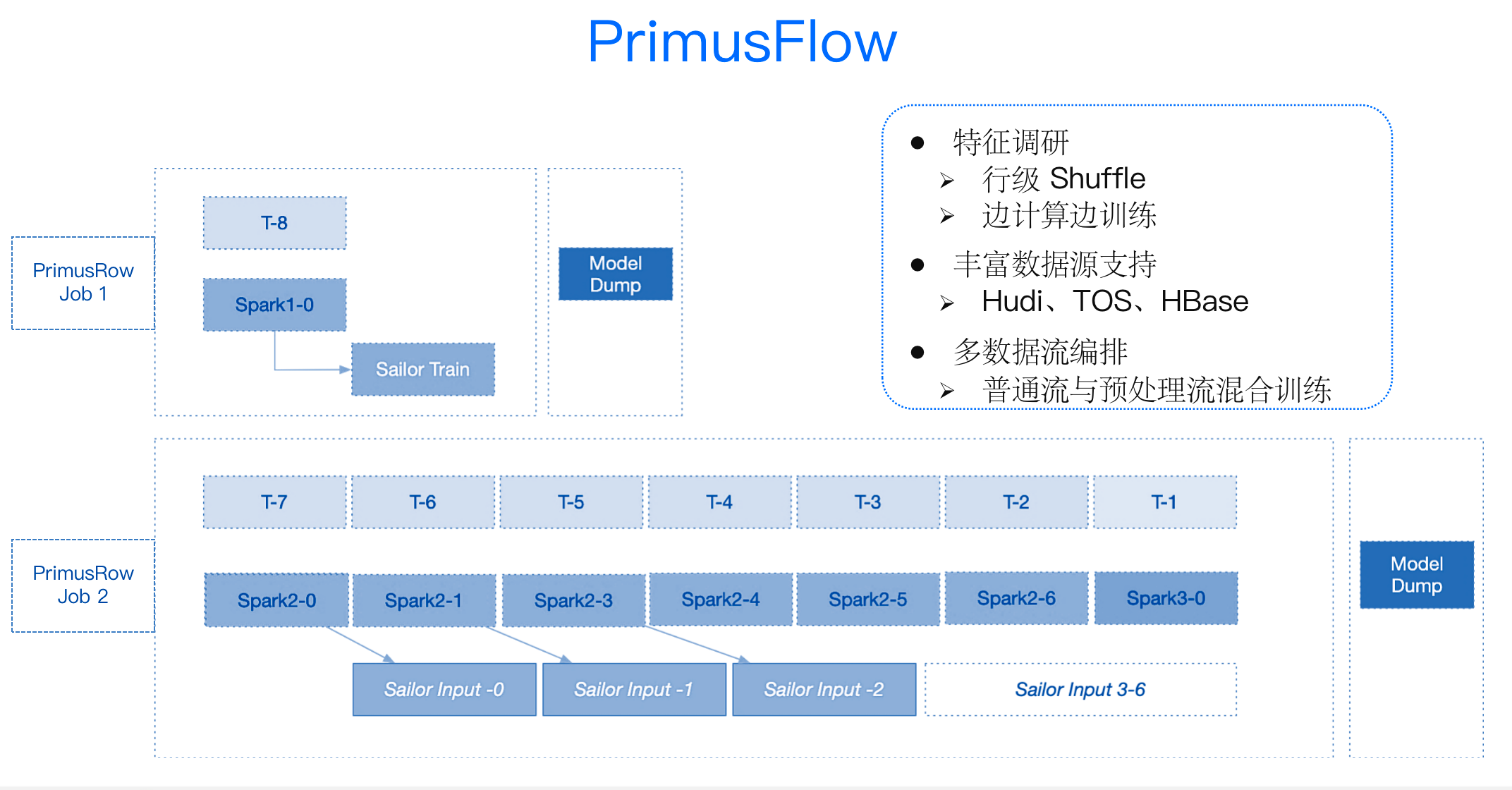
在模型的调研中一般会面临的问题是:一个等待和两个浪费——即 Spark 预处理的等待、模型训练过程中 Spark 计算的开销和存储的开销。
为此,我们引入了伴生数据预处理的模型训练机制——PrimusFlow。一方面,它可以支持丰富的数据源,任何一个被 Spark 预处理的数据源,都可以被 PrimusFlow 机制处理,我们通过 Spark 读取,Load 中间状态进行训练。另外,PrimusFlow 支持更丰富的调研模式,支持行级 Shuffle,我们可以进行数据预处理,按行或按某个用户 ID 进行加工处理,以此来提升模型训练效果。
此外,我们采用多数据流编排,先对 Spark 进行预处理,在下一个阶段用上一个 Spark 预处理的结果进行模型训练,同时在这一阶段并行进行第二个单元的 Spark 预处理,由此真正实现了无需等待的单元调度模式。
通过 PrimusFlow 机制,加上行级 Shuffle 的能力,我们在非常多的场景中都取得了模型效果提升 10% 以上的收益,并且在国外很多场景进行了落地。通过上述方式,我们解决了一个等待和两个浪费的问题。
训练批流一体架构
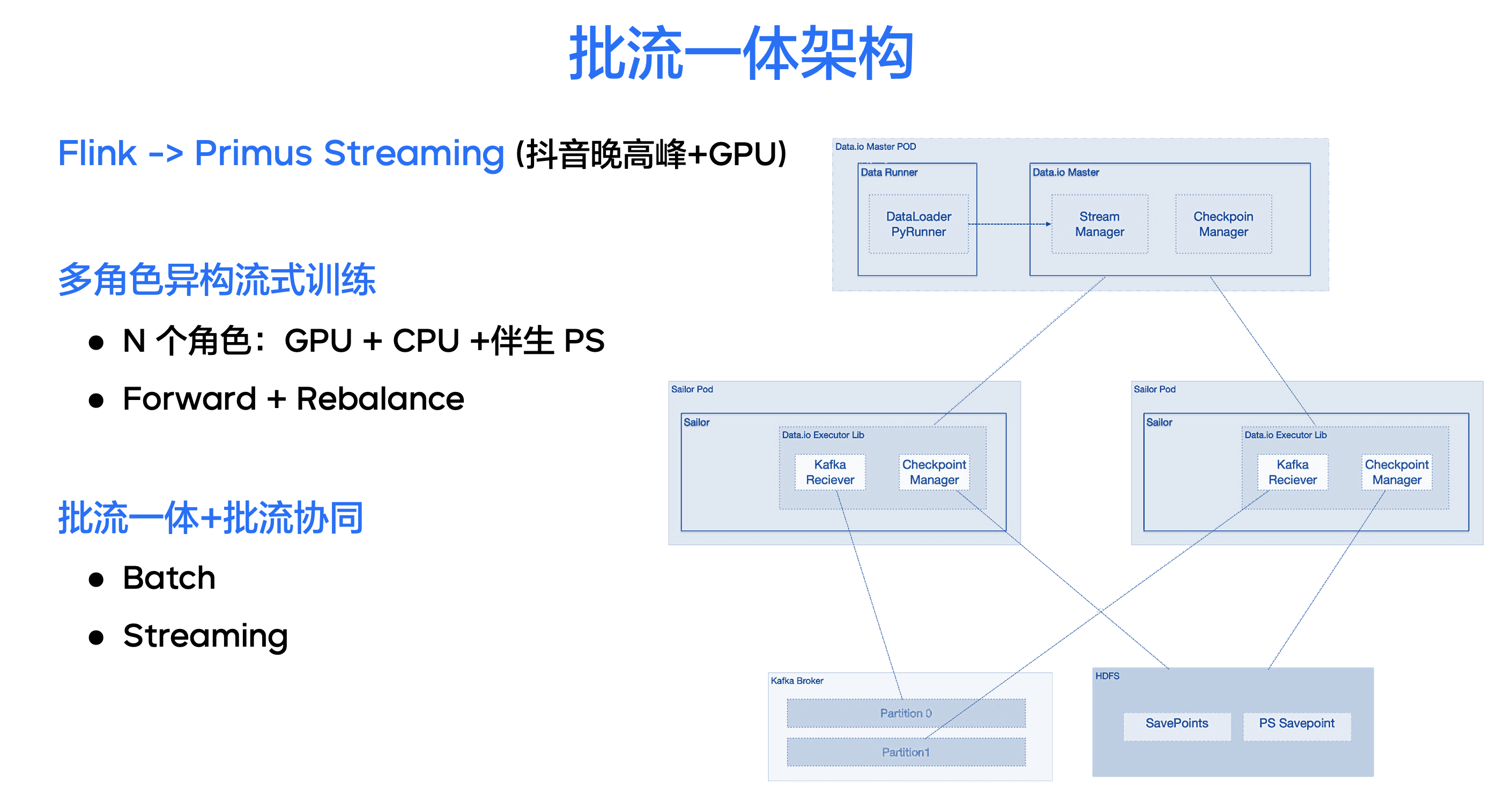
在实践过程中,我们发现批式处理框架也有流式消费的能力。目前的模型建模,一方面是烧脑建模,另一方面是烧卡建模。离线训练在不断地烧卡,同时流式训练过程中也需要烧卡,这主要是因为现有的 Flink 流式训练消费已经无法满足晚高峰时抖音推荐里复杂模型需要的训练能力,因此就需要增加算力,引入 GPU 资源。但 Flink 并不支持异构角色的 Task Manager,而 Primus 天然就是一个异构多角色的训练框架。
基于上述需求,我们在 Primus 中加入了流式训练的能力,打造了多角色异构的流式训练框架,同时支持 GPU 调度、伴生的 API Server 及故障恢复,同时我们实现了 All to All 的 Shuffle 能力,即引入 Rebalance 机制提高流式训练的能力。
此外,因为 Primus 框架本身就是批流协同的框架,既能够支持多角色 GPU 的批训练,也能够支持多角色异构的流训练,在离线训练完毕之后,能够直接切换到流式训练阶段去复用同一个 Partition Server,我们以此实现了流批协同和流批一体的目的。
Primus Native 样本数据传输 Library
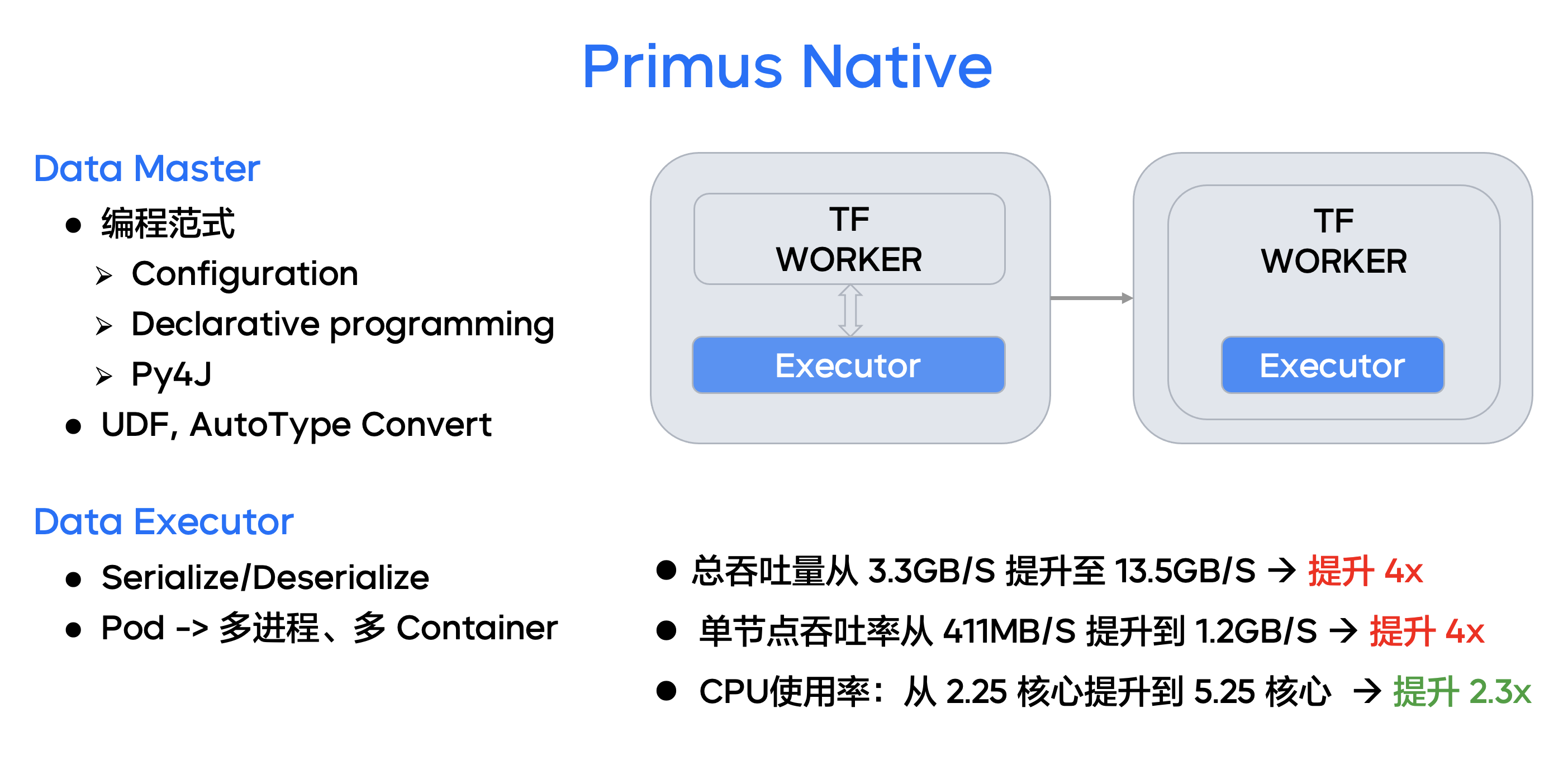
Primus Native 系统是针对字节跳动深度学习的数据子系统增强,分别在 Data Master 部分和 Data Executor 部分进行了云原生改造,发展为更加灵活、更加高效的深度学习数据引擎。
元数据 Meta Manager 编排部分: 我们不仅引入了声明式 API,也引入了 Python for Java 的 Gateway 架构,这个架构支撑起了 Primus Native 的数据声明体系。相比于声明式 API 的数据定义方法,Python Gateway 架构在灵活性+扩展性方面更有优势:
- 用户可以更加灵活的利用 Primus Native Python UDF 灵活控制样本按文件时间排列、按特定字段排列等高度自由的样本文件编排策略;
- 实现了 Python 数据和 Java 数据的灵活转换,训练器可以更好地获取当前任务编排和任务消费样本的详细信息,灵活地进行训练效果评估、抽样等操作。
训练 Worker 读取部分: 我们引入了 SO 化的数据传输机制,合并两个进程到一个训练进程内部,彻底免除了序列化和反序列化的开销、用户态到内核态的数据拷贝,也节省了云原生环境下单容器内多进程的维护难度。
通过上述优化,针对一个标准推荐训练任务:
- 总吞吐量从 3.3GB/s 提升至 13.5GB/s,提升了4倍;
- 单节点吞吐率从 411MB/s 提升到 1.2GB/s,提升了4倍;
- CPU 使用率从 2.25 核心提升到 5.25 核心,提升了2.3倍。
总结
综上所述,我们在本文中阐述了字节跳动离线训练发展的三个阶段,以及云原生离线训练中非常重要的两个部分——计算调度和数据编排,最后结合前两部分分享了字节跳动在实践中沉淀的重要实践案例。
|








- 上一条: 从100w核到450w核:字节跳动超大规模云原生离线训练实践 2022-12-29
- 下一条: 没有了
- PaddleBox:百度基于GPU的超大规模离散DNN模型训练解决方案 2022-11-01
- 字节跳动 YARN 云原生化演进实践 2022-11-17
- 深度学习中的分布式训练 2021-08-03
- 字节跳动开源 Go HTTP 框架 Hertz 设计实践 2022-06-22
- 阿里巴巴超大规模 Kubernetes 基础设施运维体系揭秘 2021-12-31