万字避坑指南!C++的缺陷与思考(上)


导语 | 本文主要总结了本人在C++开发过程中对一些奇怪、复杂的语法的理解和思考,同时作为C++开发的避坑指南。

前言
C++是一门古老的语言,但仍然在不间断更新中,不断引用新特性。但与此同时C++又甩不掉巨大的历史包袱,并且C++的设计初衷和理念造成了C++异常复杂,还出现了很多不合理的“缺陷”。本文主要有3个目的:
-
总结一些C++晦涩难懂的语法现象,解释其背后原因,作为防踩坑之用。
-
和一些其他的编程语言进行比较,列举它们的优劣。
-
发表一些我自己作为C++程序员的看法和感受。

来自C语言的历史包袱
C++有一个很大的历史包袱,就是C语言。C语言诞生时间很早,并且它是为了编写OS而诞生的,语法更加底层。有人说,C并不是针对程序员友好的语言,而是针对编译期友好的语言。有些场景在C语言本身可能并没有什么不合理,但放到C++当中会“爆炸”,或者说,会迅速变成一种“缺陷”,让人异常费解。
C++在演变过程中一直在吸收其他语言的优势,不断提供新的语法、工具来进行优化。但为了兼容性(不仅仅是语法的兼容,还有一些设计理念的兼容),还是会留下很多坑。
(一)数组
数组本身其实没有什么问题,这种语法也非常常用,主要是表示连续一组相同的数据构成的集合。但数组类型在待遇上却和其他类型(比如说结构体)非常不一样。
-
数组的复制
我们知道,结构体类型是可以很轻松的复制的,比如说:
struct St {
int m1;
double m2;
};
void demo() {
St st1;
St st2 = st1; // OK
St st3;
st1 = st3; // OK
}
但数组却并不可以,比如:
int arr1[5];
int arr2[5] = arr1; // ERR
明明这里arr2和arr1同为int[5]类型,但是并不支持复制。照理说,数组应当比结构体更加适合复制场景,因为需求是很明确的,就是元素按位复制。
-
数组类型传参
由于数组不可以复制,导致了数组同样不支持传参,因此我们只能采用“首地址+长度”的方式来传递数组:
void f1(int *arr, size_t size) {}
void demo() {
int arr[5];
f1(arr, 5);
}
而为了方便程序员进行这种方式的传参,C又做了额外的2件事:
-
提供一种隐式类型转换,支持将数组类型转换为首元素指针类型(比如说这里arr是int[5]类型,传参时自动转换为int*类型)
-
函数参数的语法糖,如果在函数参数写数组类型,那么会自动转换成元素指针类型,比如说下面这几种写法都完全等价:
void f(int *arr);
void f(int arr[]);
void f(int arr[5]);
void f(int arr[100]);
所以这里非常容易误导人的就在这个语法糖中,无论中括号里写多少,或者不写,这个值都是会被忽略的,要想知道数组的边界,你就必须要通过额外的参数来传递。
但通过参数传递这是一种软约束,你无法保证调用者传的就是数组元素个数,这里的危害详见后面“指针偏移”的章节。
-
分析和思考
之所以C的数组会出现这种奇怪现象,我猜测,作者考虑的是数组的实际使用场景,是经常会进行切段截取的,也就是说,一个数组类型并不总是完全整体使用,我们可能更多时候用的是其中的一段。举个简单的例子,如果数组是整体复制、传递的话,做数组排序递归的时候会不会很尴尬?首先,排序函数的参数难以书写,因为要指定数组个数,我们总不能针对于1,2,3,4,5,6,...元素个数的数组都分别写一个排序函数吧?其次,如果取子数组就会复制出一个新数组的话,也就不能对原数组进行排序了。
所以综合考虑,干脆这里就不支持复制,强迫程序员使用指针+长度这种方式来操作数组,反而更加符合数组的实际使用场景。
当然了,在C++中有了引用语法,我们还是可以把数组类型进行传递的,比
如:
void f1(int (&arr)[5]); // 必须传int[5]类型
void demo() {
int arr1[5];
int arr2[8];
f1(arr1); // OK
f1(arr2); // ERR
}
但绝大多数的场景似乎都不会这样去用。一些新兴语言(比如说Go)就注意到了这一点,因此将其进行了区分。在Go语言中,区分了“数组”和“切片”的概念,数组就是长度固定的,整体来传递;而切片则类似于首地址+长度的方式传递(只不过没有单独用参数,而是用len函数来获取)
func f1(arr [5]int) {
}
func f2(arr []int) {
}
上面例子里,f1就必须传递长度是5的数组类型,而f2则可以传递任意长度的切片类型。
而C++其实也注意到了这一点,但由于兼容问题,它只能通过STL提供容器的方式来解决,std::array就是定长数组,而std::vector就是变长数组,跟上述Go语言中的数组和切片的概念是基本类似的。这也是C++中更加推荐使用vector而不是C风格数组的原因。

类型说明符
(一)类型不是从左向右说明
C/C++中的类型说明符其实设计得很不合理,除了最简单的变量定义:
int a; // 定义一个int类型的变量a
上面这个还是很清晰明了的,但稍微复杂一点的,就比较奇怪了:
int arr[5]; // 定义一个int[5]类型的变量arr
arr明明是int[5]类型,但是这里的int和[5]却并没有写到一起,如果这个还不算很容易造成迷惑的话,那来看看下面的:
int *a1[5]; // 定义了一个数组
int (*a2)[5]; // 定义了一个指针
a1是int *[5]类型,表示a1是个数组,有5个元素,每个元素都是指针类型的。
a2是int (*)[5]类型,是一个指针,指针指向了一个int[5]类型的数组。
这里离谱的就在这个int (*)[5]类型上,也就是说,“指向int[5]类型的指针”并不是int[5]*,而是int (*)[5],类型说明符是从里往外描述的,而不是从左往右。
(二)类型说明符同时承担了动作语义
这里的另一个问题就是,C/C++并没有把“定义变量”和“变量的类型”这两件事分开,而是用类型说明符来同时承担了。也就是说,“定义一个int类型变量”这件事中,int这一个关键字不仅表示“int类型”,还表示了“定义变量”这个意义。这件事放在定义变量这件事上可能还不算明显,但放到定义函数上就不一样了:
int f1();
上面这个例子中,int和()共同表示了“定义函数”这个意义。也就是说,看到int这个关键字,并不一定是表示定义变量,还有可能是定义函数,定义函数时int表示了函数的返回值的类型。
正是由于C/C++中,类型说明符具有多重含义,才造成一些复杂语法简直让人崩溃,比如说定义高阶函数:
// 输入一个函数,输出这个函数的导函数
double (*DC(double (*)(double)))(double);
DC是一个函数,它有一个参数,是double (*)(double)类型的函数指针,它的返回值是一个double (*)(double)类型的函数指针。但从直观性上来说,上面的写法完全毫无可读性,如果没有那一行注释,相信大家很难看得出这个语法到底是在做什么。
C++引入了返回值右置的语法,从一定程度上可以解决这个问题:
auto f1() -> int;
auto DC(auto (*)(double) -> double) -> auto (*)(double) -> double;
但用auto作为占位符仍然还是有些突兀和晦涩的。
(三)将类型符和动作语义分离的语言
我们来看一看其他语言是如何弥补这个缺陷的,最简单的做法就是把“类型”和“动作”这两件事分开,用不同的关键字来表示。Go语言:
// 定义变量
var a1 int
var a2 []int
var a3 *int
var a4 []*int // 元素为指针的数组
var a5 *[]int // 数组的指针
// 定义函数
func f1() {
}
func f2() int {
return 0
}
// 高阶函数
func DC(f func(float64)float64) func(float64)float64 {
}
Swift语言:
// 定义变量
var a1: Int
var a2: [Int]
// 定义函数
func f1() {
}
func f2() -> Int {
return 0
}
// 高阶函数
func DC(f: (Double, Double)->Double) -> (Double, Double)->Double {
}
JavaScript语言:
// 定义变量
var a1 = 0
var a2 = [1, 2, 3]
// 定义函数
function f1() {}
function f2() {
return 0
}
// 高阶函数
function DC(f) {
return function(x) {
//...
}
}
(四)指针偏移
指针的偏移运算让指针操作有了较大的自由度,但同时也会引入越界问题
int arr[5];
int *p1 = arr + 5;
*p1 = 10// 越界
int a = 0;
int *p2 = &a;
a[1] = 10; // 越界
换句话说,指针的偏移是完全随意的,静态检测永远不会去判断当前指针的位置是否合法。这个与之前章节提到的数组传参的问题结合起来,会更加容易发生并且更加不容易发现:
void f(int *arr, size_t size) {}
void demo() {
int arr[5];
f(arr, 6); // 可能导致越界
}
因为参数中的值和数组的实际长度并没有要求强一致。
(五)其他语言的指针
在其他语言中,有的语言(例如java、C#)直接取消了指针的相关语法,但由此就必须引入“值类型”和“引用类型”的概念。例如在java中,存在“实”和“名”的概念:
public static void Demo() {
int[] arr = new int[10];
int[] arr2 = arr; // “名”的复制,浅复制
int[] arr3 = Arrays.copyOf(arr, arr.length); // 用库方法进行深复制
}
本质上来说,这个“名”就是栈空间上的一个指针,而“实”则是堆空间中的实际数据。如果取消指针概念的话,就要强行区分哪些类型是“值类型”,会完全复制,哪些是“引用类型”,只会浅复制。
C#中的结构体和类的概念恰好如此,结构体是值类型,整体复制,而类是引用类型,要用库函数来复制。
而还有一些语言保留了指针的概念(例如Go、Swift),但仅仅用于明确指向和引用的含义,并不提供指针偏移运算,来防止出现越界问题。例如go中:
func Demo() {
var a int
var p *int
p = &a // OK
r1 := *p // 直接解指针是OK的
r2 := *(p + 1) // ERR,指针不可以偏移
}
swift中虽然仍然支持指针,但非常弱化了它的概念,从语法本身就能看出,不到迫不得已并不推荐使用:
func f1(_ ptr: UnsafeMutablePointer<Int>) {
ptr.pointee += 1 // 给指针所指向的值加1
}
func demo() {
var a: Int = 5
f1(&a)
}
OC中的指针更加特殊和“奇葩”,首先,OC完全保留了C中的指针用法,而额外扩展的“类”类型则不允许出现在栈中,也就是说,所有对象都强制放在堆中,栈上只保留指针对其引用。虽然OC中的指针仍然是C指针,但由于操作对象的“奇葩”语法,倒是并不需要太担心指针偏移的问题
void demo() {
NSObject *obj = [[NSObject alloc] init];
// 例如调用obj的description方法
NSString *desc = [obj description];
// 指针仍可偏移,但几乎不会有人这样来写:
[(obj+1) description]; // 也会越界
}
(六)隐式类型转换
隐式类型转换在一些场景下会让程序更加简洁,降低代码编写难度。比如说下面这些场景:
double a = 5; // int->double
int b = a * a; // double->int
int c = '5' - '0'; // char->int
但是有的时候隐式类型转化却会引发很奇怪的问题,比如说:
#define ARR_SIZE(arr) (sizeof(arr) / sizeof(arr[0]))
void f1() {
int arr[5];
size_t size = ARR_SIZE(arr); // OK
}
void f2(int arr[]) {
size_t size = ARR_SIZE(arr); // WRONG
}
结合之前所说,函数参数中的数组其实是数组首元素指针的语法糖,所以f2中的arr其实是int *类型,这时候再对其进行sizeof运算,结果是指针的大小,而并非数组的大小。如果程序员不能意识到这里发生了int [N]->int *的隐式类型转换,那么就可能出错。还有一些隐式类型转换也很离谱,比如说:
int a = 5;
int b = a > 2; // 可能原本想写a / 2,把/写成了>
这里发生的隐式转换是bool->int,同样可能不符合预期。关于布尔类型详见后面章节。C中的这些隐式转换可能影响并不算大,但拓展到C++中就可能有爆炸性的影响,详见后面“隐式构造”和“多态转换”的相关章节。
(七)赋值语句的返回值
C/C++的赋值语句自带返回值,这一定算得上一大缺陷,在C中赋值语句返回值,在C++中赋值语句返回左值引用。
这件事造成的最大影响就在=和==这两个符号上,比如:
int a1, a2;
bool b = a1 = a2;
这里原本想写b=a1==a2,但是错把==写成了=,但编译是可以完全通过的,因为a1=a2本身返回了a1的引用,再触发一次隐式类型转换,把bool转化为int(这里详见后面非布尔类型的布尔意义章节)。
更有可能的是写在if表达式中:
if (a = 1) {
}
可以看到,a=1执行后a的值变为1,返回的a的值就是1,所以这里的if变成了恒为真。
C++为了兼容这一特性,又不得不要求自定义类型要定义赋值函数
class Test {
public:
Test &operator =(const Test &); // 拷贝赋值函数
Test &operator =(Test &&); // 移动赋值函数
Test &operator =(int a); // 其他的赋值函数
};
这里赋值函数的返回值强制要求定义为当前类型的左值引用,一来会让人觉得有些无厘头,记不住这里的写法,二来在发生继承关系的时候非常容易忘记处理父类的赋值。
class Base {
public:
Base &operator =(const Base &);
};
class Ch : public Base {
public:
Ch &opeartor =(const Ch &ch) {
this->Base::operator =(ch);
// 或者写成 *static_cast<Base *>(this) = ch;
// ...
return *this;
}
};
(八)其他语言的赋值语句
古老一些的C系扩展语言基本还是保留了赋值语句的返回值(例如java、OC),但一些新兴语言(例如Go、Swift)则是直接取消了赋值语句的返回值,比如说在swift中:
let a = 5
var b: Int
var c: Int
c = (b = a) // ERR
b=a会返回Void,所以再赋值给c时会报错
(九)非布尔类型的布尔意义
在原始C当中,其实并没有“布尔”类型,所有表示是非都是用int来做的。所以,int类型就赋予了布尔意义,0表示false,非0都表示true,由此也诞生了很多“野路子”的编程技巧:
int *p;
if (!p) {} // 指针→bool
while (1) {} // int→bool
int n;
while (~scanf("%d", &n)) {} // int→bool
所有表示判断逻辑的语法,都可以用非布尔类型的值传入,这样的写法其实是很反人类直觉的,更严重的问题就是与true常量比较的问题
int judge = 2; // 用了int表示了判断逻辑
if (judge == true) {} // 但这里的条件其实是false,因为true会转为1,2 == 1是false
正是由于非布尔类型具有了布尔意义,才会造成一些非常反直觉的事情,比如说:
true + true != true
!!2 == 1
(2 == true) == false
(十)其他语言的布尔类型
基本上除了C++和一些弱类型脚本语言(比如js)以外,其他语言都取消了非布尔类型的布尔意义,要想转换为布尔值,一定要通过布尔运算才可以,例如在Go中:
func Demo() {
a := 1 // int类型
if (a) { // ERR,if表达式要求布尔类型
}
if (a != 0) { // OK,通过逻辑运算得到布尔类型
}
}
这样其实更符合直觉,也可以一定程度上避免出现写成类似于if (a = 1)出现的问题。C++中正是由于“赋值语句有返回值”和“非布尔类型有布尔意义”同时生效,才会在这里出现问题。
(十一)解指针类型
关于C/C++到底是强类型语言还是弱类型语言,业界一直争论不休。有人认为,变量的类型从定义后就不能改变,并且每个变量都有固定的类型,所以C/C++应该是强类型语言。
但有人持相反意见,是因为这个类型,仅仅是“表面上”不可变,但其实是可变的,比如说看下面例程:
int a = 300;
uint8_t *p = reinterpret_cast<uint8_t *>(&a);
*p = 1; // 这里其实就是把a变成了uint8_t类型
根源就在于,指针的解类型是可以改变的,原本int类型的变量,我们只要把它的首地址保存下来,然后按照另一种类型来解,那么就可以做到“改变a的类型”的目的。
这也就意味着,指针类型是不安全的,因为你不一定能保证现在解指针的类型和指针指向数据的真实类型是匹配的。
还有更野一点的操作,比如:
struct S1 {
short a, b;
};
struct S2 {
int a;
};
void demo() {
S2 s2;
S1 *p = reinterpret_cast<S1 *>(&s2);
p->a = 2;
p->b = 1;
std::cout << s2.a; // 猜猜这里会输出多少?
}
这里的指针类型问题和前面章节提到的指针偏移问题,综合起来就是说C/C++的指针操作的自由度过高,提升了语言的灵活度,同时也增加了其复杂度。
(十二)后置自增/自减
如果仅仅在C的角度上,后置自增/自减语法并没有带来太多的副作用,有时候在程序中作为一些小技巧反而可以让程序更加精简,比如说:
void AttrCnt() {
static int count = 0;
std::cout << count++ << std::endl;
}
但这个特性继承到C++后问题就会被放大,比如说下面的例子:
for (auto iter = ve.begin(); iter != ve.end(); iter++) {
}
这段代码看似特别正常,但仔细想想,iter作为一个对象类型,如果后置++,一定会发生复制。后置++原本的目的就是在表达式的位置先返回原值,表达式执行完后再进行自增。但如果放在类类型来说,就必须要临时保存一份原本的值。例如:
class Element {
public:
// 前置++
Element &operator ++() {
ele++;
return *this;
}
// 后置++
Element operator ++(int) {
// 为了最终返回原值,所以必需保存一份快照用于返回
Element tmp = *this;
ele++;
return tmp;
}
private:
int ele;
};
这也从侧面解释了,为什么前置++要求返回引用,而后置++则是返回非引用,因为这里需要复制一份快照用于返回。
那么,写在for循环中的后置++就会平白无故发生一次复制,又因为返回值没有接收,再被析构。
C++保留的++和--的语义,也是因为它和+=1或-=1语义并不完全等价。我们可以用顺序迭代器来解释。对于顺序迭代器(比如说链表的迭代器),++表示取下一个节点,--表示取上一个节点。而+n或者-n则表示偏移了,这种语义更适合随机访问(所以说随机迭代器支持+=和-=,但顺序迭代器只支持++和--)。
(十三)其他语言的自增/自减
其他语言的做法基本分两种,一种就是保留自增/自减语法,但不再提供返回值,也就不用区分前置和后置,例如Go:
a := 3
a++ // OK
b := a++ // ERR,自增语句没有返回值
另一种就是干脆删除自增/自减语法,只提供普通的操作赋值语句,例如Swift:
var a = 3
a++ // ERR,没有这种语法
a += 1 // OK,只能用这种方式自增

类型长度
这里说的类型长度指的是相同类型在不同环境下长度不一致的情况,下面总结表格:
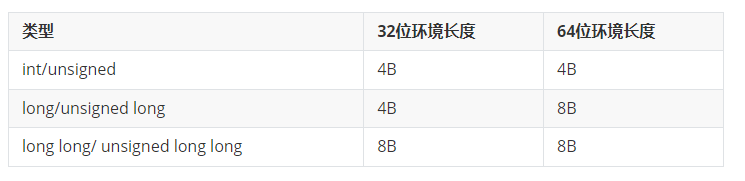
由于这里出现了32位和64位环境下长度不一致的情况,C语言特意提供了stdint.h头文件(C++中在cstddef中引用),定义了定长类型,例如int64_t在32位环境下其实是long long,而在64位环境下其实是long。
但这里的问题点在于:
-
并没有定长格式符
例如uint64_t在32位环境下对应的格式符是%llu,但是在64位环境下对应的格式符是%lu。有一种折中的解决办法是自定义一个宏:
#if(sizeof(void*) == 8)
#define u64 "%lu"
#else
#define u64 "%llu"
#endif
void demo() {
uint64_t a;
printf("a="u64, a);
}
但这样会让字符串字面量从中间断开,非常不直观。
-
类型不一致
例如在64位环境下,long和long long都是64位长,但编译器会识别为不同类型,在一些类型推导的场景会出现和预期不一致的情况,例如:
template <typename T>
void func(T t) {}
template <>
void func<int64_t>(int64_t t) {}
void demo() {
long long a;
func(a); // 会匹配通用模板,而匹配不到特例
}
上述例子表明,func<int64_t>和func<long long>是不同实例,尽管在64位环境下long和long long真的看不出什么区别,但是编译器就是会识别成不同类型。

格式化字符串
格式化字符串算是非常经典的C的产物,不仅是C++,非常多的语言都是支持这种格式符的,例如java、Go、python等等。
但C++中的格式化字符串可以说完全就是C的那一套,根本没有任何扩展。换句话说,除了基本数据类型和0结尾的字符串以外,其他任何类型都没有用于匹配的格式符。
例如,对于结构体类型、数组、元组类型等等,都没法匹配到格式符:
struct Point {
double x, y;
};
void Demo() {
// 打印Point
Point p {1, 2.5};
printf("(%lf,%lf)", p.x, p.y); // 无法直接打印p
// 打印数组
int arr[] = {1, 2, 3};
for (int i = 0; i < 3; i++) {
printf("%d, ", arr[i]); // 无法直接打印整个数组
}
// 打印元组
std::tuple tu(1, 2.5, "abc");
printf("(%d,%lf,%s)", std::get<0>(tu), std::get<1>(tu), std::get<2>(tu)); // 无法直接打印整个元组
}
对于这些组合类型,我们就不得不手动去访问内部成员,或者用循环访问,非常不方便。
针对于字符串,还会有一个严重的潜在问题,比如:
std::string str = "abc";
str.push_back('\0');
str.append("abc");
char buf[32];
sprintf(buf, "str=%s", str.c_str());
由于str中出现了'\0',如果用%s格式符来匹配的话,会在0的位置截断,也就是说buf其实只获取到了str中的第一个abc,第二个abc就被丢失了。
其他语言中的格式符
而一些其他语言则是扩展了格式符功能用于解决上述问题,例如OC引入了%@格式符,用于调用对象的description方法来拼接字符串:
@interface Point2D : NSObject
@property double x;
@property double y;
- (NSString *)description;
@end
@implementation Point2D
- (NSString *)description {
return [[NSString alloc] initWithFormat:@"(%lf, %lf)", self.x, self.y];
}
@end
void Demo() {
Point2D *p = [[Point2D alloc] init];
[p setX:1];
[p setY:2.5];
NSLog(@"p=%@", p); // 会调用p的description方法来获取字符串,用于匹配%@
}
而Go语言引入了更加方便的%v格式符,可以用来匹配任意类型,用它的默认方式打印
type Test struct {
m1 int
m2 float32
}
func Demo() {
a1 := 5
a2 := 2.6
a3 := []int{1, 2, 3}
a4 := "123abc"
a5 := Test{2, 1.5}
fmt.Printf("a1=%v, a2=%v, a3=%v, a4=%v, a5=%v\n", a1, a2, a3, a4, a5)
}
Python则是用%s作为万能格式符来使用:
def Demo():
a1 = 5
a2 = 2.5
a3 = "abc123"
a4 = [1, 2, 3]
print("%s, %s, %s, %s"%(a1, a2, a3, a4)) #这里没有特殊格式要求时都可以用%s来匹配

枚举
枚举类型原本是用于解决固定范围取值的类型表示,但由于在C语言中被定义为了整型类型的一种语法糖,导致枚举类型的使用上出现了一些问题。
-
无法前置声明
枚举类型无法先声明后定义,例如下面这段代码会编译报错:
enum Season;
struct Data {
Season se; // ERR
};
enum Season {
Spring,
Summer,
Autumn,
Winter
};
主要是因为enum类型是动态选择基础类型的,比如这里只有4个取值,那么可能会选取int16_t,而如果定义的取值范围比较大,或者中间出现大枚举值的成员,那么可能会选取int32_t或者int64_t。也就是说,枚举类型如果没定义完,编译期是不知道它的长度的,因此就没法前置声明。
C++中允许指定枚举的基础类型,制定后可以前置声明:
enum Season : int;
struct Data {
Season se; // OK
};
enum Season : int {
Spring,
Summer,
Autumn,
Winter
};
但如果你是在调别人写的库的时候,人家的枚举没有指定基础类型的话,那你也没辙了,就是不能前置声明。
-
无法确认枚举值的范围
也就是说,我没有办法判断某个值是不是合法的枚举值:
enum Season {
Spring,
Summer,
Autumn,
Winter
};
void Demo() {
Season s = static_cast<Season>(5); // 不会报错
}
-
枚举值可以相同
enum Test {
Ele1 = 10,
Ele2,
Ele3 = 10
};
void Demo() {
bool judge = (Ele1 == Ele3); // true
}
-
C风格的枚举还存在“成员名称全局有效”和“可以隐式转换为整型”的缺陷
但因为C++提供了enum class风格的枚举类型,解决了这两个问题,因此这里不再额外讨论。
(一)宏
宏这个东西,完全就是针对编译器友好的,编译器非常方便地在宏的指导下,替换源代码中的内容。但这个玩意对程序员(尤其是阅读代码的人)来说是极其不友好的,由于是预处理指令,因此任何的静态检测均无法生效。一个经典的例子就是:
#define MUL(x, y) x * y
void Demo() {
int a = MUL(1 + 2, 3 + 4); // 11
}
因为宏就是简单粗暴地替换而已,并没有任何逻辑判断在里面。
宏因为它很“好用”,所以非常容易被滥用,下面列举了一些宏滥用的情况供参考:
-
用宏来定义类成员
#define DEFAULT_MEM \
public: \
int GetX() {return x_;} \
private: \
int x_;
class Test {
DEFAULT_MEM;
public:
void method();
};
这种用法相当于屏蔽了内部实现,对阅读者非常不友好,与此同时加不加DEFAULT_MEM是一种软约束,实际开发时极容易出错。
再比如这种的:
#define SINGLE_INST(class_name) \
public: \
static class_name &GetInstance() { \
static class_name instance; \
return instance; \
} \
class_name(const class_name&) = delete; \
class_name &operator =(const class_name &) = delete; \
private: \
class_name();
class Test {
SINGLE_INST(Test)
};
这位同学,我理解你是想封装一下单例的实现,但咱是不是可以考虑一下更好的方式?(比如用模板)
-
用宏来屏蔽参数
#define strcpy_s(dst, dst_buf_size, src) strcpy(dst, src)
这位同学,咱要是真想写一个安全版本的函数,咱就好好去判断dst_buf_size如何?
-
用宏来拼接函数处理
#define COPY_IF_EXSITS(dst, src, field) \
do { \
if (src.has_##field()) { \
dst.set_##field(dst.field()); \
} \
} while (false)
void Demo() {
Pb1 pb1;
Pb2 pb2;
COPY_IF_EXSITS(pb2, pb1, f1);
COPY_IF_EXSITS(pb2, pb1, f2);
}
这种用宏来做函数名的拼接看似方便,但最容易出的问题就是类型不一致,加入pb1和pb2中虽然都有f1这个字段,但类型不一样,那么这样用就可能造成类型转换。试想pb1.f1是uint64_t类型,而pb2.f1是uint32_t类型,这样做是不是有可能造成数据的截断呢?
-
用宏来改变语法风格
#define IF(con) if (con) {
#define END_IF }
#define ELIF(con) } else if (con) {
#define ELSE } else {
void Demo() {
int a;
IF(a > 0)
Process1();
ELIF(a < -3)
Process2();
ELSE
Process3();
}
这位同学你到底是写python写惯了不适应C语法呢,还是说你为了让代码扫描工具扫不出来你的圈复杂度才出此下策的呢~~
(二)共合体
共合体的所有成员共用内存空间,也就是说它们的首地址相同。在很多人眼中,共合体仅仅在“多选一”的场景下才会使用,例如:
union QueryKey {
int id;
char name[16];
};
int Query(const QueryKey &key);
上例中用于查找某个数据的key,可以通过id查找,也可以通过name,但只能二选一。
这种场景确实可以使用共合体来节省空间,但缺点在于,共合体的本质就是同一个数据的不同解类型,换句话说,程序是不知道当前的数据是什么类型的,共合体的成员访问完全可以用更换解指针类型的方式来处理,例如:
union Un {
int m1;
unsigned char m2;
};
void Demo() {
Un un;
un.m1 = 888;
std::cout << un.m2 << std::endl;
// 等价于
int n1 = 888;
std::cout << *reinterpret_cast<unsigned char *>(&n1) << std::endl;
}
共合体只不过把有可能需要的解类型提前写出来罢了。所以说,共合体并不是用来“多选一”的,笔者认为这是大家曲解的用法。毕竟真正要做到“多选一”,你就得知道当前选的是哪一个,例如:
struct QueryKey {
union {
int id;
char name[16];
} key;
enum {
kCaseId,
kCaseName
} key_case;
};
用过google protobuf的读者一定很熟悉上面的写法,这个就是proto中oneof语法的实现方式。
在C++17中提供了std::variant,正是为了解决“多选一”问题存在的,它其实并不是为了代替共合体,因为共合体原本就不是为了这种需求的,把共合体用做“多选一”实在是有点“屈才”了。
更加贴合共合体本意的用法,是我最早是在阅读处理网络报文的代码中看到的,例如某种协议的报文有如下规定(例子仅供参考):
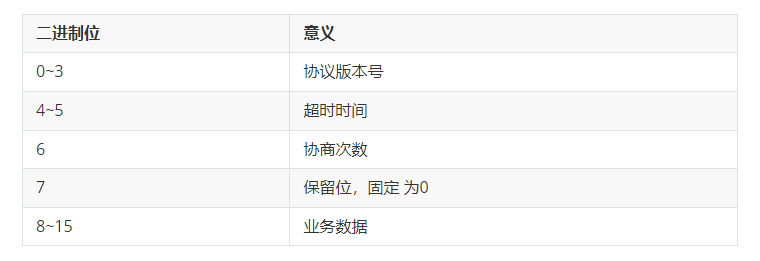
这里能看出来,整个报文有2字节,一般的处理时,我们可能只需要关注这个报文的这2个字节值是多少(比如说用十六进制表示),而在排错的时候,才会关注报文中每一位的含义,因此,“整体数据”和“内部数据”就成为了这段报文的两种获取方式,这种场景下非常适合用共合体:
union Pack {
uint16_t data; // 直接操作报文数据
struct {
unsigned version : 4;
unsigned timeout : 2;
unsigned retry_times : 1;
unsigned block : 1;
uint8_t bus_data;
} part; // 操作报文内部数据
};
void Demo() {
// 例如有一个从网络获取到的报文
Pack pack;
GetPackFromNetwork(pack);
// 打印一下报文的值
std::printf("%X", pack.data);
// 更改一下业务数据
pack.part.bus_data = 0xFF;
// 把报文内容扔到处理流中
DataFlow() << pack.data;
}
因此,这里的需求就是“用两种方式来访问同一份数据”,才是完全符合共合体定义的用法。
共合体应该是C语言的特色了,其他任何高级语言都没有类似的语法,主要还是因为C语言更加面相底层,C++仅仅是继承了C的语法而已。

const引用
(一)先说说const
先来吐槽一件事,就是C/C++中const这个关键字,这个名字起的非常非常不好!为什么这样说呢?const是constant的缩写,翻译成中文就是“常量”,但其实在C/C++中,const并不是表示“常量”的意思。
我们先来明确一件事,什么是“常量”,什么是“变量”?常量其实就是衡量,比如说1就是常量,它永远都是这个值。再比如'A'就是个常量,同样,它永远都是和它ASCII码对应的值。“变量”其实是指存储在内存当中的数据,起了一个名字罢了。如果我们用汇编,则不存在“变量”的概念,而是直接编写内存地址:
mov ax, 05FAh
mov ds, ax
mov al, ds:[3Fh]
但是这个05FA:3F地址太突兀了,也很难记,另一个缺点就是,内存地址如果固定了,进程加载时动态分配内存的操作空间会下降(尽管可以通过相对内存的方式,但程序员仍需要管理偏移地址),所以在略高级一点的语言中,都会让程序员有个更方便的工具来管理内存,最简单的方法就是给内存地址起个名字,然后编译器来负责翻译成相对地址。
int a; // 其实就是让编译器帮忙找4字节的连续内存,并且起了个名字叫a
所以“变量”其实指“内存变量”,它一定拥有一个内存地址,和可变不可变没啥关系。
因此,C语言中const用于修饰的一定是“变量”,来控制这个变量不可变而已。用const修饰的变量,其实应当说是一种“只读变量”,这跟“常量”根本挨不上。
这就是笔者吐槽这个const关键字的原因,你叫个read_only之类的不是就没有歧义了么?
C#就引入了readonly关键字来表示“只读变量”,而const则更像是给常量取了个别名(可以类比为C++中的宏定义,或者constexpr,后面章节会详细介绍constexpr):
const int pi = 3.14159; // 常量的别名
readonly int[] arr = new int[]{1, 2, 3}; // 只读变量
(二)左右值
C++由于保留了C当中的const关键字,但更希望表达其“不可变”的含义,因此着重在“左右值”的方向上进行了区分。左右值的概念来源于赋值表达式:
var = val; // 赋值表达式
赋值表达式的左边表示即将改变的变量,右边表示从什么地方获取这个值。因此,很自然地,右值不会改变,而左值会改变。那么在这个定义下,“常量”自然是只能做右值,因为常量仅仅有“值”,并没有“存储”或者“地址”的概念。而对于变量而言,“只读变量”也只能做右值,原因很简单,因为它是“只读”的。
虽然常量和只读变量是不同的含义,但它们都是用来“读取值”的,也就是用来做右值的,所以,C++引入了“const引用”的概念来统一这两点。 所谓const引用包含了2个方面的含义:
-
作为只读变量的引用(指针的语法糖)
-
作为只读变量
换言之,const引用可能是引用,也可能只是个普通变量,如何理解呢?请看例程:
void Demo() {
const int a = 5; // a是一个只读变量
const int &r1 = a; // r1是a的引用,所以r1是引用
const int &r2 = 8; // 8是一个常量,因此r2并不是引用,而是一个只读变量
}
也就是说,当用一个const引用来接收一个变量的时候,这时的引用是真正的引用,其实在r1内部保存了a的地址,当我们操作r的时候,会通过解指针的语法来访问到a
const int a = 5;
const int &r1 = a;
std::cout << r1;
// 等价于
const int *p1 = &a; // 引用初始化其实是指针的语法糖
std::cout << *p1; // 使用引用其实是解指针的语法糖
但与此同时,const引用还可以接收常量,这时,由于常量根本不是变量,自然也不会有内存地址,也就不可能转换成上面那种指针的语法糖。那怎么办?这时,就只能去重新定义一个变量来保存这个常量的值了,所以这时的const引用,其实根本不是引用,就是一个普通的只读变量。
const int &r1 = 8;
// 等价于
const int c1 = 8; // r1其实就是个独立的变量,而并不是谁的引用
(三)思考
const引用的这种设计,更多考虑的是语义上的,而不是实现上的。如果我们理解了const引用,那么也就不难理解为什么会有“将亡值”和“隐式构造”的问题了,因为搭配const引用,可以实现语义上的统一,但代价就是同一语法可能会做不同的事,会令人有疑惑甚至对人有误导。
在后面“右值引用”和“因式构造”的章节会继续详细介绍它们和const引用的联动,以及可能出现的问题。

右值引用与移动语义
C++11的右值引用语法的引入,其实也完全是针对于底层实现的,而不是针对于上层的语义友好。换句话说,右值引用是为了优化性能的,而并不是让程序变得更易读的。
(一)右值引用
右值引用跟const引用类似,仍然是同一语法不同意义,并且右值引用的定义强依赖“右值”的定义。根据上一节对“左右值”的定义,我们知道,左右值来源于赋值语句,常量只能做右值,而变量做右值时仅会读取,不会修改。按照这个定义来理解,“右值引用”就是对“右值”的引用了,而右值可能是常量,也可能是变量,那么右值引用自然也是分两种情况来不同处理:
-
右值引用绑定一个常量
-
右值引用绑定一个变量
我们先来看右值引用绑定常量的情况:
int &&r1 = 5; // 右值引用绑定常量
和const引用一样,常量没有地址,没有存储位置,只有值,因此,要把这个值保存下来的话,同样得按照“新定义变量”的形式,因此,当右值引用绑定常量时,相当于定义了一个普通变量:
int &&r1 = 5;
// 等价于
int v1 = 5; // r1就是个普通的int变量而已,并不是引用
所以这时的右值引用并不是谁的引用,而是一个普普通通的变量。
我们再来看看右值引用绑定变量的情况: 这里的关键问题在于,什么样的变量适合用右值引用绑定? 如果对于普通的变量,C++不允许用右值引用来绑定,但这是为什么呢?
int a = 3;
int &&r = a; // ERR,为什么不允许右值引用绑定普通变量?
我们按照上面对左右值的分析,当一个变量做右值时,该变量只读,不会被修改,那么,“引用”这个变量自然是想让引用成为这个变量的替身,而如果我们希望这里做的事情是“当通过这个引用来操作实体的时候,实体不能被改变”的话,使用const引用就已经可以达成目的了,没必要引入一个新的语法。
所以,右值引用并不是为了让引用的对象只能做右值(这其实是const引用做的事情),相反,右值引用本身是可以做左值的。这就是右值引用最迷惑人的地方,也是笔者认为“右值引用”这个名字取得迷惑人的地方。
右值引用到底是想解决什么问题呢?请看下面示例:
struct Test { // 随便写一个结构体,大家可以脑补这个里面有很多复杂的成员
int a, b;
};
Test GetAnObj() { // 一个函数,返回一个结构体类型
Test t {1, 2}; // 大家可以脑补这里面做了一些复杂的操作
return t; // 最终返回了这个对象
}
void Demo() {
Test t1 = GetAnObj();
}
我们忽略编译器的优化问题,只分析C++语言本身。在GetAnObj函数内部,t是一个局部变量,局部变量的生命周期是从创建到当前代码块结束,也就是说,当GetAnObj函数结束时,这个t一定会被释放掉。
既然这个局部变量会被释放掉,那么函数如何返回呢?这就涉及了“值赋值”的问题,假如t是一个整数,那么函数返回的时候容易理解,就是返回它的值。具体来说,就是把这个值推到寄存器中,在跳转会调用方代码的时候,再把寄存器中的值读出来:
int f1() {
int t = 5;
return t;
}
翻译成汇编就是:
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], 5 ; 这里[rbp-4]就是局部变量t
mov eax, DWORD PTR [rbp-4] ; 把t的值放到eax里,作为返回值
pop rbp
ret
之所以能这样返回,主要就是eax放得下t的值。但如果t是结构体的话,一个eax寄存器自然是放不下了,那怎么返回?(这里汇编代码比较长,而且跟编译器的优化参数强相关,就不放代码了,有兴趣的读者可以自己汇编看结果。)简单来说,因为寄存器放不下整个数据,这个数据就只能放到内存中,作为一个临时区域,然后在寄存器里放一个临时区域的内存地址。等函数返回结束以后,再把这个临时区域释放掉。
那么我们再回来看这段代码:
struct Test {
int a, b;
};
Test GetAnObj() {
Test t {1, 2};
return t; // 首先开辟一片临时空间,把t复制过去,再把临时空间的地址写入寄存器
} // 代码块结束,局部变量t被释放
void Demo() {
Test t1 = GetAnObj(); // 读取寄存器中的地址,找到临时空间,再把临时空间的数据复制给t1
// 函数调用结束,临时空间释放
}
那么整个过程发生了2次复制和2次释放,如果我们按照程序的实际行为来改写一下代码,那么其实应该是这样的:
struct Test {
int a, b;
};
void GetAnObj(Test *tmp) { // tmp要指向临时空间
Test t{1, 2};
*tmp = t; // 把t复制给临时空间
} // 代码块结束,局部变量t被释放
void Demo() {
Test *tmp = (Test *)malloc(sizeof(Test)); // 临时空间
GetAnObj(tmp); // 让函数处理临时空间的数据
Test t1 = *tmp; // 把临时空间的数据复制给这里的局部变量t1
free(tmp); // 释放临时空间
}
如果我真的把代码写成这样,相信一定会被各位前辈骂死,质疑我为啥不直接用出参。的确,用出参是可以解决这种多次无意义复制的问题,所以C++11以前并没有要去从语法层面来解决,但这样做就会让代码不得不“面相底层实现”来编程。C++11引入的右值引用,就是希望从“语法层面”解决这种问题。
试想,这片非常短命的临时空间,究竟是否有必要存在?既然这片空间是用来返回的,返回完就会被释放,那我何必还要单独再搞个变量来接收,如果这片临时空间可以持续使用的话,不就可以减少一次复制吗?于是,“右值引用”的概念被引入。
struct Test {
int a, b;
};
Test GetAnObj() {
Test t {1, 2};
return t; // t会复制给临时空间
}
void Demo() {
Test &&t1 = GetAnObj(); // 我设法引用这篇临时空间,并且让他不要立刻释放
// 临时空间被t1引用了,并不会立刻释放
} // 等代码块结束,t1被释放了,才让临时空间释放
所以,右值引用的目的是为了延长临时变量的生命周期,如果我们把函数返回的临时空间中的对象视为“临时对象”的话,正常情况下,当函数调用结束以后,临时对象就会被释放,所以我们管这个短命的对象叫做“将亡对象”,简单粗暴理解为“马上就要挂了的对象”,它的使命就是让外部的t1复制一下,然后它就死了,所以这时候你对他做什么操作都是没意义的,他就是让人来复制的,自然就是个只读的值了,所以才被归结为“右值”。我们为了让它不要死那么快,而给它延长了生命周期,因此使用了右值引用。所以,右值引用是不是应该叫“续命引用”更加合适呢~
当用右值引用捕获一个将亡对象的时候,对象的生命周期从“将亡”变成了“与右值引用共存亡”,这就是右值引用的根本意义,这时的右值引用就是“将亡对象的引用”,又因为这时的将亡对象已经不再“将亡”了,那它既然不再“将亡”,我们再对它进行操作(改变成员的值)自然就是有意义的啦,所以,这里的右值引用其实就等价于一个普通的引用而已。既然就是个普通的引用,而且没用const修饰,自然,可以做左值咯。右值引用做左值的时候,其实就是它所指对象做左值而已。不过又因为普通引用并不会影响原本对象的生命周期,但右值引用会,因此,右值引用更像是一个普通的变量,但我们要知道,它本质上还是引用(底层是指针实现的)。
总结来说就是,右值引用绑定常量时相当于“给一个常量提供了生命周期”,这时的“右值引用”并不是谁的引用,而是相当于一个普通变量;而右值引用绑定将亡对象时,相当于“给将亡对象延长了生命周期”,这时的“右值引用”并不是“右值的引用”,而是“对需要续命的对象”的引用,生命周期变为了右值引用本身的生命周期(或者理解为“接管”了这个引用的对象,成为了一个普通的变量)。
(二)const引用绑定将亡对象
需要知道的是,const引用也是可以绑定将亡对象的,正如上文所说,既然将亡对象定义为了“右值”,也就是只读不可变的,那么自然就符合const引用的语义。
// 省略Test的定义,见上节
void Demo() {
const Test &t1 = GetAnObj(); // OK
}
这样看来,const引用同样可以让将亡对象延长生命周期,但其实这里的出发点并不同,const引用更倾向于“引用一个不可变的量”,既然这里的将亡对象是一个“不可变的值”,那么,我就可以用const引用来保存“这个值”,或者这里的“值”也可以理解为这个对象的“快照”。所以,当一个const引用绑定一个将亡值时,const引用相当于这个对象的“快照”,但背后还是间接地延长了它的生命周期,但只不过是不可变的。
(三)移动语义
在解释移动语义之前,我们先来看这样一个例子:
class Buffer final {
public:
Buffer(size_t size);
Buffer(const Buffer &ob);
~Buffer();
int &at(size_t index);
private:
size_t buf_size_;
int *buf_;
};
Buffer::Buffer(size_t size) : buf_size_(size), buf_(malloc(sizeof(int) * size)) {}
Buffer::Buffer(const Buffer &ob) :buf_size_(ob.buf_size_),
buf_(malloc(sizeof(int) * ob.buf_size_)) {
memcpy(buf_, ob.buf_, ob.buf_size_);
}
Buffer::~Buffer() {
if (buf_ != nullptr) {
free(buf_);
}
}
int &Buffer::at(size_t index) {
return buf_[index];
}
void ProcessBuf(Buffer buf) {
buf.at(2) = 100; // 对buf做一些操作
}
void Demo() {
ProcessBuf(Buffer{16}); // 创建一个16个int的buffer
}
上面这段代码定义了一个非常简单的缓冲区处理类,ProcessBuf函数想做的事是传进来一个buffer,然后对这个buffer做一些修改的操作,最后可能把这个buffer输出出去之类的(代码中没有体现,但是一般业务肯定会有)。
如果像上面这样写,会出现什么问题?不难发现在于ProcessBuf的参数,这里会发生复制。由于我们在Buffer类中定义了拷贝构造函数来实现深复制,那么任何传入的buffer都会在这里进行一次拷贝构造(深复制)。再观察Demo中调用,仅仅是传了一个临时对象而已。临时对象本身也是将亡对象,复制给buf后,就会被释放,也就是说,我们进行了一次无意义的深复制。 有人可能会说,那这里参数用引用能不能解决问题?比如这样:
void ProcessBuf(Buffer &buf) {
buf.at(2) = 100;
}
void Demo() {
ProcessBuf(Buffer{16}); // ERR,普通引用不可接收将亡对象
}
所以这里需要我们注意的是,C++当中,并不只有在显式调用=的时候才会赋值,在函数传参的时候仍然由赋值语义(也就是实参赋值给形参)。所以上面就相当于:
Buffer &buf = Buffer{16}; // ERR
所以自然不合法。那,用const引用可以吗?由于const引用可以接收将亡对象,那自然可以用于传参,但ProcessBuf函数中却对对象进行了修改操作,所以const引用不能满足要求:
void ProcessBuf(const Buffer &buf) {
buf.at(2) = 100; // 但是这里会报错
}
void Demo() {
ProcessBuf(Buffer{16}); // 这里确实OK了
}
正如上一节描述,const引用倾向于表达“保存快照”的意义,因此,虽然这个对象仍然是放在内存中的,但const引用并不希望它发生改变(否则就不叫快照了),因此,这里最合适的,仍然是右值引用:
void ProcessBuf(Buffer &&buf) {
buf.at(2) = 100; // 右值引用完成绑定后,相当于普通引用,所以这里操作OK
}
void Demo() {
ProcessBuf(Buffer{16}); // 用右值引用绑定将亡对象,OK
}
我们再来看下面的场景:
void Demo() {
Buffer buf1{16};
// 对buf进行一些操作
buf1.at(2) = 50;
// 再把buf传给ProcessBuf
ProcessBuf(buf1); // ERR,相当于Buffer &&buf= buf1;右值引用绑定非将亡对象
}
因为右值引用是要来绑定将亡对象的,但这里的buf1是Demo函数的局部变量,并不是将亡的,所以右值引用不能接受。但如果我有这样的需求,就是说buf1我不打算用了,我想把它的控制权交给ProcessBuf函数中的buf,相当于,我主动让buf1提前“亡”,是否可以强制把它弄成将亡对象呢?STL提供了std::move函数来完成这件事,“期望强制把一个对象变成将亡对象”:
void Demo() {
Buffer buf1{16};
// 对buf进行一些操作
buf1.at(2) = 50;
// 再把buf传给ProcessBuf
ProcessBuf(std::move(buf1)); // OK,强制让buf1将亡,那么右值引用就可以接收
} // 但如果读者尝试的话,在这里会出ERROR
std::move的本意是提前让一个对象“将亡”,然后把控制权“移交”给右值引用,所以才叫「move」,也就是“移动语义”。但很可惜,C++并不能真正让一个对象提前“亡”,所以这里的“移动”仅仅是“语义”上的,并不是实际的。如果我们看一下std::move的实现就知道了:
template <typename T>
constexpr std::remove_reference_t<T> &&move(T &&ref) noexcept {
return static_cast<std::remove_reference_t<T> &&>(ref);
}
如果这里参数中的&&符号让你懵了的话,可以参考后面“引用折叠”的内容,如果对其他乱七八糟的语法还是没整明白的话,没关系,我来简化一下:
template <typename T>
T &&move(T &ref) {
return static_cast<T &&>(ref);
}
哈?就这么简单?是的!真的就这么简单,这个std::move不是什么多高大上的处理,就是简单把普通引用给强制转换成了右值引用,就这么简单。
所以,我上线才说“C++并不能真正让一个对象提前亡”,这里的std::move就是跟编译器玩了一个文字游戏罢了。
所以,C++的移动语义仅仅是在语义上,在使用时必须要注意,一旦将一个对象move给了一个右值引用,那么不可以再操作原本的对象,但这种约束是一种软约束,操作了也并不会有报错,但是就可能会出现奇怪的问题。
(四)移动构造、移动赋值
有了右值引用和移动语义,C++还引入了移动构造和移动赋值,这里简单来解释一下:
void Demo() {
Buffer buf1{16};
Buffer buf2(std::move(buf1)); // 把buf1强制“亡”,但用它的“遗体”构造新的buf2
Buffer buf3{8};
buf3 = std::move(buf2); // 把buf2强制“亡”,把“遗体”转交个buf3,buf3原本的东西不要了
}
为了解决用一个将亡对象来构造/赋值另一个对象的情况,引入了移动构造和移动赋值函数,既然是用一个将亡对象,那么参数自然是右值引用来接收了。
class Buffer final {
public:
Buffer(size_t size);
Buffer(const Buffer &ob);
Buffer(Buffer &&ob); // 移动构造函数
~Buffer();
Buffer &operator =(Buffer &&ob); // 移动赋值函数
int &at(size_t index);
private:
size_t buf_size_;
int *buf_;
};
这里主要考虑的问题是,既然是用将亡对象来构造新对象,那么我们应当尽可能多得利用将亡对象的“遗体”,在将亡对象中有一个buf_指针,指向了一片堆空间,那这片堆空间就可以直接利用起来,而不用再复制一份了,因此,移动构造和移动赋值应该这样实现:
Buffer::Buffer(Buffer &&ob) : buf_size_(ob.buf_size_), // 基本类型数据,只能简单拷贝了
buf_(ob.buf_) { // 直接把ob中指向的堆空间接管过来
// 为了防止ob中的空间被重复释放,将其置空
ob.buf_ = nullptr;
}
Buffer &Buffer::operator =(Buffer &&ob) {
// 先把自己原来持有的空间释放掉
if (buf_ != nullptr) {
free(buf_);
}
// 然后继承ob的buf_
buf_ = ob.buf_;
// 为了防止ob中的空间被重复释放,将其置空
ob.buf_ = nullptr;
}
细心的读者应该能发现,所谓的“移动构造/赋值”,其实就是一个“浅复制”而已。当出现移动语义的时候,我们想象中是“把旧对象里的东西 移动 到新对象中”,但其实没法做到这种移动,只能是“把旧对象引用的东西转为新对象来引用”,本质就是一次浅复制。

引用折叠
引用折叠指的是在模板参数以及auto类型推导时遇到多重引用时进行的映射关系,我们先从最简单的例子来说:
template <typename T>
void f(T &t) {
}
void Demo() {
int a = 3;
f<int>(a);
f<int &>(a);
f<int &&>(a);
}
当T实例化为int时,函数变成了:
void f(int &t);
但如果T实例化为int&和int &&时呢?难道是这样吗?
void f(int & &t);
void f(int && &t);
我们发现,这种情况下编译并没有出错,T本身带引用时,再跟参数后面的引用符结合,也是可以正常通过编译的。这就是所谓的引用折叠,简单理解为“两个引用撞一起了,以谁为准”的问题。引用折叠满足下面规律:
左值引用短路右值引用
简单来说就是,除非是两个右值引用遇到一起,会推导出右值引用以外,其他情况都会推导出左值引用,所以是左值引用优先。
& + & -> &
& + && -> &
&& + & -> &
&& + && -> &&
(一)auto &&
这种规律同样同样适用于auto &&,当auto &&遇到左值时会推导出左值引用,遇到右值时才会推导出右值引用:
auto &&r1 = 5; // 绑定常量,推导出int &&
int a;
auto &&r2 = a; // 绑定变量,推导出int &
int &&b = 1;
auto &&r3 = b; // 右值引用一旦绑定,则相当于普通变量,所以绑定变量,推导出int &
由于&比&&优先级高,因此auto &一定推出左值引用,如果用auto &绑定常量或将亡对象则会报错:
auto &r1 = 5; // ERR,左值引用不能绑定常量
auto &r2 = GetAnObj(); // ERR,左值引用不能绑定将亡对象
int &&b = 1;
auto &r3 = b; // OK,左值引用可以绑定右值引用(因为右值引用一旦绑定后,相当于左值)
auto &r4 = r3; // OK,左值引用可以绑定左值引用(相当于绑定r4的引用源)
(二)右值引用传递时失去右性
前面的章节笔者频繁强调一个概念:右值引用一旦绑定,则相当于普通的引用(左值)。
这也就意味着,“右值”性质无法传递,请看例子:
void f1(int &&t1) {}
void f2(int &&t2) {
f1(t2); // 注意这里
}
void Demo() {
f2(5);
}
在Demo函数中调用f2,f2的参数是int &&,用来绑定常量5没问题,但是,在f2函数内,t2是一个右值引用,而右值引用一旦绑定,则相当于左值,因此,不能再用右值引用去接收。所以f2内部调f1的过程会报错。这就是所谓“右值引用传递时会失去右性”。
那么如何保持右性呢?很无奈,只能层层转换:
void f1(int &&t1) {}
void f2(int &&t2) {
f1(std::move(t2)); // 保证右性
}
void Demo() {
f2(5);
}
但我们来考虑另一个场景,在模板函数中这件事会怎么样?
template <typename T>
void f1(T &&t1) {}
template <typename T>
void f2(T &&t2) {
f1<T>(t2);
}
void Demo() {
f2<int &&>(5); // 传右值
int a;
f2<int &>(a); // 传左值
}
由于f1和f2都是模板,因此,传入左值和传入右值的可能性都要有的,我们没法在f2中再强制std::move了,因为这样做会让左值变成右值传递下去,我们希望的是保持其左右性 但如果不这样做,当我向f2传递右值时,右性无法传递下去,也就是t2是int &&类型,但是传递给f1的时候,t1变成了int &类型,这时t1是t2的引用(就是左值引用绑定右值引用的场景),并不是我们想要的。那怎么解决,如何让这种左右性质传递下去呢?就要用到模板元编程来完成了:
template <typename T>
T &forward(T &t) {
return t; // 如果传左值,那么直接传出
}
template <typename T>
T &&forward(T &&t) {
return std::move(t); // 如果传右值,那么保持右值性质传出
}
template <typename T>
void f1(T &&t1) {}
template <typename T>
void f2(T &&t2) {
f1(forward<T>(t2));
}
void Demo() {
f2<int &&>(5); // 传右值
int a;
f2<int &>(a); // 传左值
}
上面展示的是std::forward的一个示例型的代码,便于读者理解,实际实现要稍微复杂一点。思路就是,根据传入的参数来判断,如果是左值引用就直接传出,如果是右值引用就std::move变成右值再传出,保证其左右性。std::forward又被称为“完美转发”,意义就在于传递引用时能保持其左右性。
(三)auto推导策略
C++11提供了auto来自动推导类型,很大程度上提升了代码的直观性,例如:
std::unordered_map<std::string, std::vector<int>> data_map;
// 不用auto
std::unordered_map<std::string, std::vector<int>>::iterator iter = data_map.begin();
// 使用auto推导
auto iter = data_map.begin();
但auto的推导仍然引入了不少奇怪的问题。首先,auto关键字仅仅是用来代替“类型符”的,它并没有改变“C++类型说明符具有多重意义”这件事,在前面“类型说明符”的章节我曾介绍过,C++中,类型说明符除了表示“类型”以外,还承担了“定义动作”的任务,auto可以视为一种带有类型推导的类型说明符,其本质仍然是类型说明符,所以,它同样承担了定义动作的任务,例如:
auto a = 5; // auto承担了“定义变量”的任务
但auto却不可以和[]组合定义数组,比如:
auto arr[] = {1, 2, 3}; // ERR
在定义函数上,更加有趣,在C++14以前,并不支持用auto推导函数返回值类型,但是却支持返回值后置语法,所以在这种场景下,auto仅仅是一个占位符而已,它既不表示类型,也不表示定义动作,仅仅就是为了结构完整占位而已:
auto func() -> int; // () -> int表示定义函数,int表示函数返回值类型
到了C++14才支持了返回值类型自动推导,但并不支持自动生成多种类型的返回值:
auto func(int cmd) {
if (cmd > 0) {
return 5; // 用5推导返回值为int
}
return std::string("123"); // ERR,返回值已经推导为int了,不能多类型返回
}
-
auto的语义
同样还是出自这句话“auto是用来代替类型说明符的”,因此auto在语义上也更加倾向于“用它代替类型说明符”这种行为,尤其是它和引用、指针类型结合时,这种特性更加明显:
int a = 5;
const int k = 9;
int &r = a;
auto b = a; // auto->int
auto c = 4; // auto->int
auto d = k; // auto->int
auto e = r; // auto->int
我们看到,无论用普通变量、只读变量、引用、常量去初始化auto变量时,auto都只会推导其类型,而不会带有左右性、只读性这些内容。 所以,auto的类型推导,并不是“推导某个表达式的类型”,而是“推导当前位置合适的类型”,或者可以理解为“这里最简单可以是什么类型”。比如说上面auto c = 4这里,auto可以推导为int,int &&,const int,const int &,const int &&,而auto选择的是里面最简单的那一种。
auto还可以跟指针符、引用符结合,而这种时候它还是满足上面“最简单”的这种原则,并且此时指的是“auto本身最简单”,举例来说:
int a = 5;
auto p1 = &a; // auto->int *
auto *p2 = &a; // auto->int
auto &r1 = a; // auto->int
auto *p3 = &p2; // auto->int *
auto p4 = &p2; // auto-> int **
p1和p2都是指针,但auto都是用最简原则来推导的,p2这里因为我们已经显式写了一个*了,所以auto只会推导出int,因此p2最终类型仍然是int *而不会变成int **。同样的道理在p3和p4上也成立。 在一些将“类型”和“动作”语义分离的语言中,就完全不会有auto的这种困扰,它们可以用“省略类型符”来表示“自动类型推导”的语义,而起“定义”语义的关键字得以保留而不受影响,例如在swift中:
var a = 5 // Int
let b = 5.6 // 只读Double
let c: Double = 8 // 显式指定类型
在Go中也是类似的:
var a = 2.5 // var表示“定义变量”动作,自动推导a的类型为float64
b := 5 // 自动推导类型为int,:=符号表示了“定义动作”语义
const c = 7 // const表示“定义只读变量”动作,自动推导c类型为int
var d float32 = 9 // 显式指定类型
-
auto引用
在前面“引用折叠”的章节曾经提到过auto &&的推导原则,有可能会推导出左值引用来,所以auto &&并不是要“定义一个右值引用”,而是“定义一个保持左右性的引用”,也就是说,绑定一个左值时会推导出左值引用,绑定一个右值时会推导出右值引用。
int a = 5;
int &r1 = a;
int &&r2 = 4;
auto &&y1 = a; // int &
auto &&y2 = r1; // int &
auto &&y3 = r2; // int &(注意右值引用本身是左值)
auto &&y4 = 3; // int &&
auto &&y5 = std::move(r1); // int &&
更详细的内容可以参考前面“引用折叠”的章节。
-
C语言曾经的auto
我相信大家现在看到auto都第一印象是C++当中的“自动类型推导”,但其实auto并不是C++11引入的新关键在,在原始C语言中就有这一关键字的。 在原始C中,auto表示“自动变量位置”,与之对应的是register。在之前“const引用”章节中笔者曾经提到,“变量就是内存变量”,但其实在原始C中,除了内存变量以外,还有一种变量叫做“寄存器变量”,也就是直接将这个数据放到CPU的寄存器中。也就是说,编译器可以控制这个变量的位置,如果更加需要读写速度,那么放到寄存器中更合适,因此auto表示让编译器自动决定放内存中,还是放寄存器中。而register修饰的则表示人工指定放在寄存器中。至于没有关键字修饰的,则表示希望放到内存中。
int a; // 内存变量
register int b; // 寄存器变量
auto int c; // 由编译器自动决定放在哪里
需要注意的是,寄存器变量不能取址。这个很好理解,因为只有内存才有地址(地址本来指的就是内存地址),寄存器是没有的。因此,auto修饰的变量如果被取址了,那么一定会放在内存中:
auto int a; // 有可能放在内存中,也有可能放在寄存器中
auto int b;
int *p = &b; // 这里b被取址了,因此b一定只能放在内存中
register int c;
int *p2 = &c; // ERR,对寄存器变量取址,会报错
然而在C++中,几乎不会人工来控制变量的存放位置了,毕竟C++更加上层一些,这样超底层的语法就被摒弃了(C++11取消了register关键字,而auto关键字也失去其本意,变为了“自动类型推导”的占位符)。而关于变量的存储位置则是全权交给了编译器,也就是说我们可以理解为,在C++11以后,所有的变量都是自动变量,存储位置由编译器决定。
注:点赞过30,下周五出下篇,快点赞收藏起来~
推荐阅读
|








- 上一条: 深度解析KubeEdge EdgeMesh 高可用架构 2022-11-22
- 下一条: 万字避坑指南!C++的缺陷与思考(上) 2022-11-23
- 熬夜整理的c/c++万字总结(一),值得收藏! 2021-08-02
- 熬夜整理的c/c++万字总结(三),值得收藏! 2021-08-03
- 熬夜整理的c/c++万字总结(二),值得收藏! 2021-08-03
- 【万字干货】OpenMetric与时序数据库存储模型分析 2021-09-14
- 万字总结Keras深度学习中文文本分类 2022-01-13


