DDL 毫秒级同步,Light Schema Change 的设计与实现|新版本揭秘

作者介绍:
刘常良:Apache Doris Contributor,SelectDB 存储层研发工程师。
吴迪:Apache Doris Committer,SelectDB 生态研发工程师。
在 OLAP 的业务场景中,Schema Change 是一个相对常见的业务需求,当上游数据源维度发生变化时,通常需要将数仓中的表结构进行相应的变更。相对于业界其他 OLAP 数据库,Apache Doris 对于 Schema Change 的支持非常友好,可支持 Online Schema Change,进行加减列或修改列类型时无须停服,保证了系统的高可用和业务的平稳运转。但在部分场景下,Schema Change 也存在一定的瓶颈,例如:在面对大数据量宽表场景下, Schema Change 执行效率相对较低、耗费时间较长;另外基于 Flink 和 Doris 构建实时数仓时,因 Schema Change 是异步作业,一旦上游表发生维度变化,需要自己维护 Schema Change 的执行状态,并在完成后重启 Flink Job,无法做到自动化变更,冗长复杂的操作流程无疑增加了许多开发和运维的成本,且可能会带来消费数据的积压。
基于此,Apache Doris 将在 1.2.0 版本推出新功能 Light Schema Change ,我们将通过本文为大家揭秘 Light Schema Change 的设计与实现,并分享其如何提升表结构变更的执行效率、以及如何在 Flink + Doris 实时数仓场景中实现 DDL 操作的自动同步。
需求背景
在正式介绍之前,需要认识一下 Apache Doris 1.2.0 版本之前支持的 3 种 Schema Change 方式,均是异步作业,分别为:
- Hard Linked Schema Change: 无需转换数据,直接完成。新摄入的数据都按照新的Schema处理,对于旧数据,新加列的值直接用对应数据类型的默认值填充。例如加列操作
ALTER TABLE site_visit ADD COLUMN click bigint SUM default '0'; - Hard Sort Schema Change: 改变了列的排序方式,需对数据进行重新排序。例如删除排序列中的一列, 字段重排序
ALTER TABLE site_visit DROP COLUMN city; - Hard Direct Schema Change: 重刷全量数据,成本最高。当修改列的类型,稀疏索引中加一列时需要按照这种方法进行
ALTER TABLE site_visit MODIFY COLUMN username varchar(64);
而值得注意的是,1.2.0 版本新增的 Light Schema Change 新特性正是 替换了 加减列操作的 Hard Linked Schema Change 流程 。 在了解 Light Schema Change 的优势之前,我们需要先知道 Hard Linked Schema Change 的技术原理。
Hard Linked Schema Change 在作用于加减 Value 列时,当接收到加减 Value 列的 DDL,Doris FE(下文简称 FE)会发起一个异步的作业,并立刻返回。作业主要做以下事情:
- 创建新的 Tablet。
- 等待已经开始的导入完成。
- 将当前已有的数据文件 Hard Link 到新 Tablet 对应的数据目录下。
在使用过程中,我们发现 Hard Linked Schema Change 存在几个明显的问题:
- 当集群规模和表数据量达到一定数量时,Hard Linked Schema Change 等待时间就会明显增加。
- 在 Hard Linked Schema Change 过程中,如果有导入任务,为保证 Schema Change 的事务性,会对新/旧 Tablet 进行双写,Schema Change 则需要等待导入任务完成之后才可以进行。在遇到这种情况时,用户往往只有 2 个选择:一个是等待 Schema Change 完成再进行导入;一个是接受双写的代价。而这两种选择对用户都不太友好。
- Hard Linked Schema Change 无法处理 Delete Predicate。如果用户在 Schema Change 之前调用过 Delete 语句,Doris 不会立刻删除数据,而是记一个Rowset,并把 Delete Predicate 和此 Rowset 进行关联;如果在做 Hard Linked Schema Change 过程中,发现 Delete Predicate,则会转化为 Sort/Direct Schema Change,对数据进行重写。
Light Schema Change 的设计与实现
相较于 Hard Linked Schema Change 的作业流程,Apache Doris 1.2.0 新版本的 Light Schema Change 的实现原理就要简单的多,只需要在加减 Value 列的时候,对 FE 中表的元数据进行修改并持久化。在设计过程中,需要考虑到以下实现细节:
解决 Schema 不一致问题
由于 Light Schema Change 只修改了 FE 的元数据,没有同步给 BE,而 BE 对读写操作依赖于自身的 Schema,这时候就会出现 Schema 不一致的问题。为了解决此问题,我们对 BE 读写流程进行了修改。主要包含以下方面:
- 读取数据的时候下发 Schema 。Schema 每一列都有相应的 Unique ID,该 Unique ID 由 BE 的每个 Tablet 负责产生和赋值,但对于所有的 Tablet,其 Schema 列的 Unique ID 都是一致的,因此将此过程移在 FE 上去实现。FE 在生成查询计划时,会把最新的 Schema 附在其中,并一起发给 BE,BE 会拿最新的 Schema 读取数据,以此来解决读过程中 Schema 的不一致。
- 将 Schema 持久化到 Rowset 的元数据中。FE 在发起导入任务的时候,会把最新的 Schema 一起下发给 BE,BE 会根据最新的 Schema 对数据进行写入并与 Rowset 绑定,将该 Schema 持久化到 Rowset 的元数据之中,实现了 Rowset 数据的自解析,解决了写过程中 Schema 的不一致 。
- 在进行 Compaction 的时候,选取需要进行 Compaction 的 Rowset 中最新的 Schema,作为Compaction 之后 Rowset 所对应的 Schema,以此来解决拥有不同 Schema 的 Rowset 合并问题。
全局 Schema Cache
由于 Rowset 的元数据一直存储在内存中,如果每个 RowsetMeta 都存储一份 Schema,会对内存造成较大的压力。为了解决这个问题,实现了一个全局的 Schema Cache 管理相同的 Schema,这样就算有成千上万个 Rowset,只要 Schema 相同,内存中只会存在一份 Schema。
支持物化视图
Light Schema Change 也实现了对物化视图的支持。对读写流程修改之后,物化视图也可以正常读写。同时,如果要删除的列在物化视图中是 Value 列,则会与主表一起触发 Light Schema Change;如果主表的 Value 列是物化视图中的 Key 列,则需要发起异步任务,对物化视图进行 Sort/Direct Schema Change。
解决数据重写问题
由于 Delete Predicate 绑定了 Rowset,且每个 Rowset 都绑定了Schema,当 Delete Predicate 所涉及的列被删除后,可以通过寻找到对应的 Rowset,Merge 该列的信息进当前的 Schema 中,这样对 Delete Predicate 之前的数据也可以正常过滤。解决了数据中有 Delete Predicate 需要重写数据的问题。
以上就是 Light Schema Change 功能实现过程中对 Doris 进行的修改,在使用的时候只需在建表的时候指定参数即可打开 Light Schema Change 功能,如下所示:
CREATE TABLE IF NOT EXISTS `customer` (
`c_custkey` int(11) NOT NULL COMMENT "",
`c_name` varchar(26) NOT NULL COMMENT "",
`c_address` varchar(41) NOT NULL COMMENT "",
`c_city` varchar(11) NOT NULL COMMENT "",
`c_nation` varchar(16) NOT NULL COMMENT "",
`c_region` varchar(13) NOT NULL COMMENT "",
`c_phone` varchar(16) NOT NULL COMMENT "",
`c_mktsegment` varchar(11) NOT NULL COMMENT ""
)
DUPLICATE KEY(`c_custkey`)
DISTRIBUTED BY HASH(`c_custkey`) BUCKETS 32
PROPERTIES (
"replication_num" = "1",
"light_schema_change" = "true"
);
性能对比
为进一步体验 Light Schema Change 的执行效率,我们在 1 FE 1 BE 的集群上对加减列操作分别在有导入任务时和无导入任务时进行了对比。硬件配置为 16C 64G,数据均在 SSD 盘,使用了TPC-H SF100 的 lineitem 表,数据量约74G,具体测试对比如下:
无导入任务时
加列:
- Hard Link Schema Change: 耗时 1s 310ms。

- Light Schema Change: 耗时 7ms
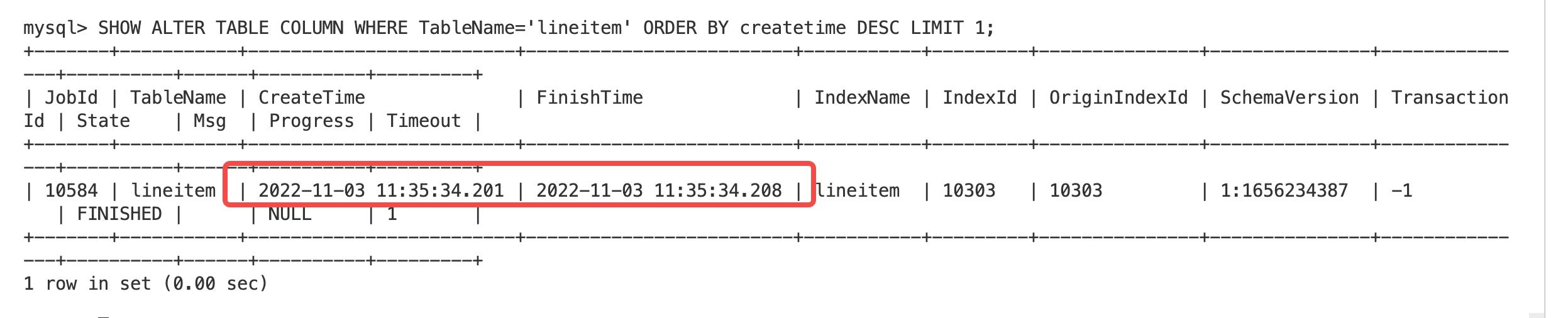
减列:
- Hard Link Schema Change: 耗时 1s 438ms

- Light Schema Change: 耗时 3ms
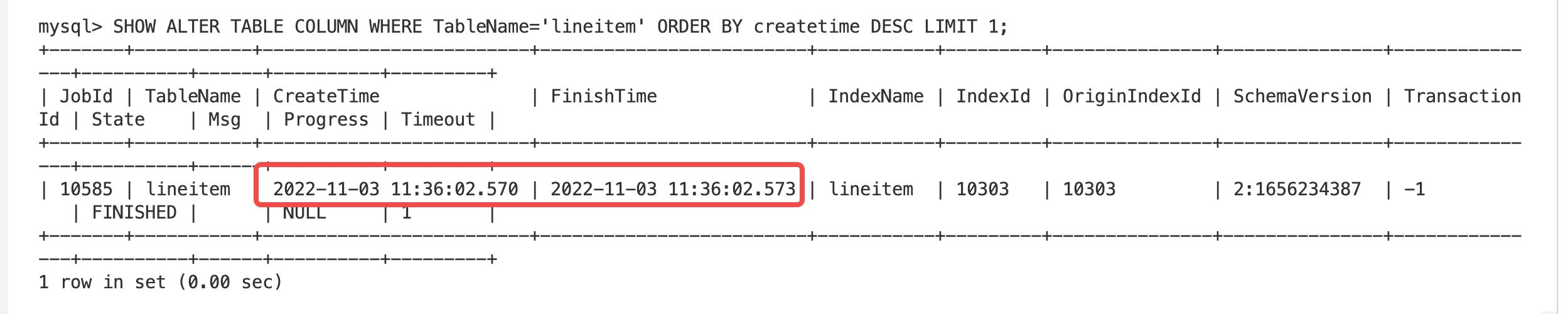
由上面测试可以看出,Light Schema Change 加减列速度远快于 Hard Link Schema Change,并且随着 BE 节点和表数据量的增多,Hard Link Schema Change 的耗时是远高于 Light Schema Change 的,原因是 Light Schema Change 只需要和 FE Master 进行交互,并可以实现同步返回。
有导入任务时
加列
- Hard Link Schema Change: 耗时 13 mins


Light Schema Change: 耗时 3 ms
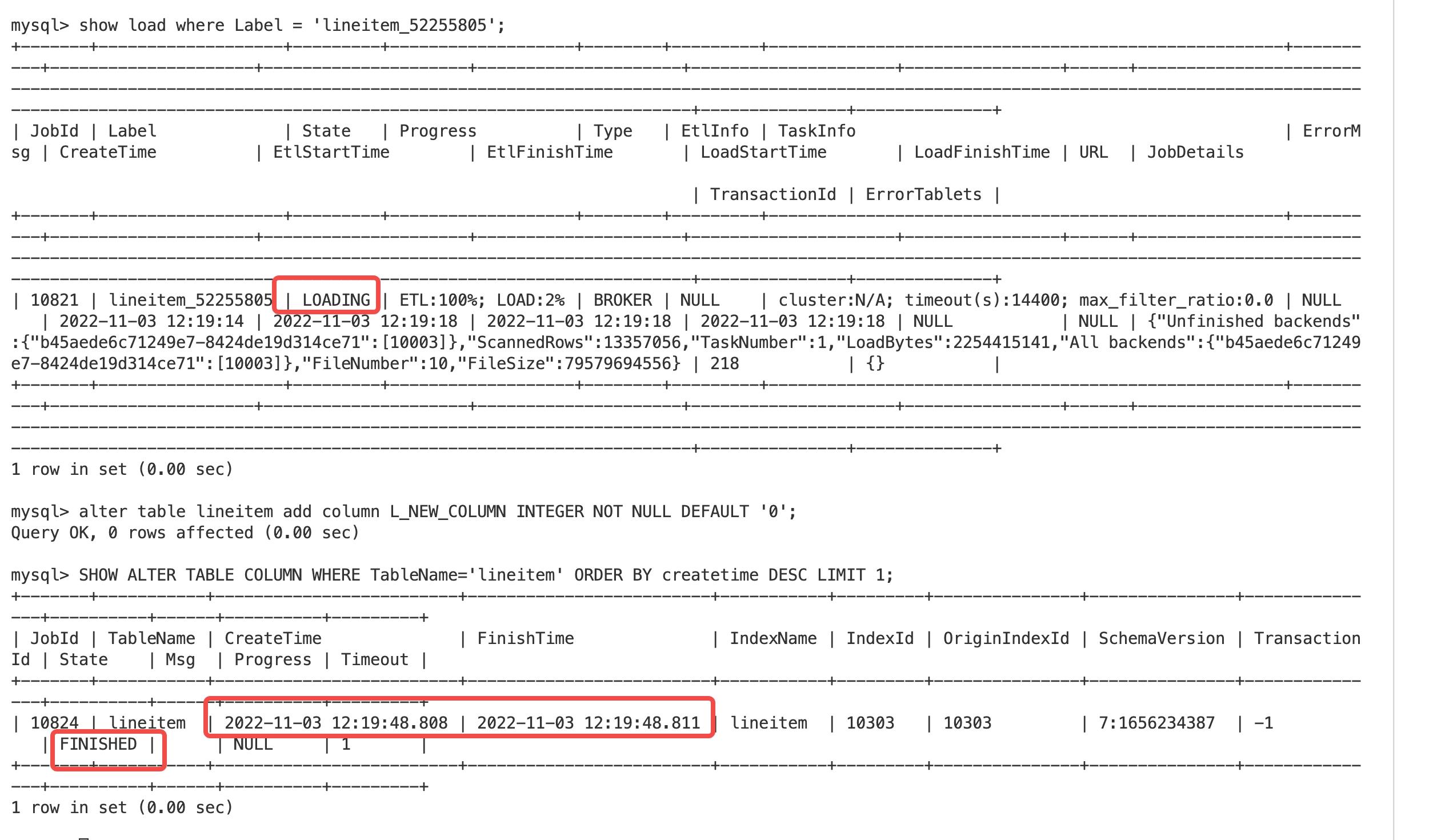
从上面测试可以看出,同样的加列行为,如果有导入任务,Hard Link Schema Change 需要等待导入的完成,才可以做 Schema Change,而 Light Schema Change 无需等待毫秒内即可完成导入。
欢迎读者尝试上手做一下有导入任务时的减列对比测试,也可以做一下在 Schema Change 过程中进行导入的情况下,两种 Schema Change 的速度对比。
Flink 结合 Light Schema Change 实现 DDL 同步
之前在基于 Apache Doris 和 Apache Flink 构建实时数仓时,当上游数据源发生表结构变更时,Doris 在同步 DDL 操作时主要有以下痛点:
- 在发起 Schema Change 后为了避免双写对集群产生的压力,通常会选择阻塞上游数据,在等待 Schema Change 操作执行完成后再解除阻塞,这个时候如果遇到一些数据量特别大的表时,往往会造成 Flink 上游数据积压;
- 需要自己处理解析 SQL 语句、发起 Schema Change 及维护执行状态等操作
- 修改 Schema 后,需要同步修改 Flink 中 Schema 相关的参数并重启 Job
而在 1.2.0 新版本实现 Light Schema Change 后,DDL 的同步就变得非常简易。利用 Flink CDC 的 DataStream API,可获取到上游业务数据库的 DDL 变更记录,在 Doris 对应数据表中开启 Light Schema Change,即可实现 DDL 自动同步。核心步骤如下:
- 在 CDC Source 中开启 DDL 变更同步;
- 在 Doris Sink 中对上游数据进行判断,识别 DDL 操作(add/drop column)并解析;
- 对 Table 进行校验,判断是否可以进行 Light Schema Change 操作;
- 对 Table 发起 Schema Change 操作。
Light Schema Change 可以保证 DDL 在毫秒级执行完成,避免了双写以及阻塞数据的问题;
同时 Flink Doris Connector 封装了序列化类 JsonDebeziumSchemaSerializer,在作业启动的时候,只需指定序列化方式即可,无需关心 Schema Change 的底层逻辑,以及无需重启Job。
总结
通过 Light Schema Change ,使得 Apache Doris 在面对上游数据表维度变化时,可以更加快速稳定实现表结构同步,保证系统的高效且平稳运转,具体体现在:
- 执行效率提升明显,且存在导入任务时效率提升更为显著。Light Schema Change 无需对 Tablet 双写,无需等待导入任务完成。在相同集群下,相较于过去版本,Schema Change 效率从数秒或数分钟提升至数毫秒,极大幅度提升了执行效率。
- 作业流程更加简单,加减列只需修改 FE 元数据,不需要与 BE 进行交互,实现同步返回,避免较长等待时间,以及因异步长时间执行而可能导致的误操作行为,提升了系统容错性和稳健性。
- Flink CDC 结合 Light Schema Change 快速实时同步 DDL ,有效解决了双写以及阻塞数据等问题,避免了增删列需要修改程序且需要停服重启的操作,实现 DDL 毫秒级快速同步,进一步提升了实时数仓数据处理和分析链路的时效性与便捷性。
Apache Doris 1.2.0 版本即将发布,如果想体验最新特性欢迎大家扫码加入下方社群中,如有任何问题/建议可通过下方论坛进行反馈,社区专家将帮助你更快定位和解决问题。
|








- 上一条: 被老板忽悠入局后,我如何在三年内让产品「起死回生」? 2022-11-11
- 下一条: 用StarRocks开发,这个新玩家要跑通数据分析最后一公里 2022-11-11
- MySQL DDL执行方式-Online DDL介绍 2022-09-22
- ChunJun支持异构数据源DDL转换与自动执行 丨DTMO 02期回顾(内含课程回放+课件) 2022-05-06
- 基于开源流批一体数据同步引擎ChunJun数据还原—DDL解析模块的实战分享 2022-06-30
- 分布式数据库DDL的编译与执行 2022-05-30
- Change Buffer 只适用于非唯一索引页?错 2022-05-26

